Module #5
In this module, we will discuss more in depth the string object and it's capabilities, along with the properties of iterable objects. In addition we'll learn about how we can take advantage of "slicing" to simplify access to specific iterable objects.
String Basics
As you know, a string is what we usually refer to as text. More specifically a string is what we call an "object" which in its simplest form is a set of data and the "methods" associated with that data. The characters are the data associated with that string. A "method" is just fancy word for a function associated with a specific type of object.
my_name = "Andrew Case" my_name = "Andrew I. Case"Here is a graphical example that demonstrates the updated reference:
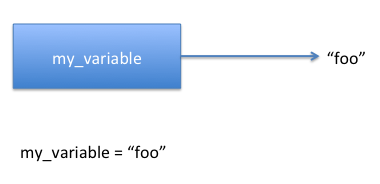
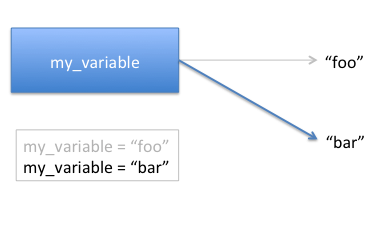
This difference may seem irrelevant now but it becomes relevant when we talk about string methods that seem like they would change the text of a string, but instead only return a new string with different text.
Characters
A character (or "chr" as Python refers to them) is either a single letter (alpha), number (numeric), symbol, or a special control character (e.g. \n for new lines). Many control characters are not able to be printed to the screen, but are usually inputable via the keyboard in some way (e.g. "ctrl", "backspace", or "new line" for example). Although we claim that we store characters, computers really only store and work with numbers. To get around this limitation, we have an encoding or one-to-one mapping that matches each character up to a specific numerical value. A "plain-text" file (source code for example) is a file that is comprised of text that is encoded using the ASCII (short for "American Standard Code for Information Interchange") encoding scheme (or a slight derivative of it). Below is a table that shows each printable character along with its encoded numerical equivalent:
- special control characters
- alphanumeric printable characters
- non-alphanumeric printable characters
|
|
We can take any character and convert it to its numerical equivalent using the built-in ord() (short for "ordinal value of") function. The ord() function takes one parameter which is the character we want to get the ordinal value of and it returns the character for that numerical value. Here's an example from the Python Shell:
>>> ord('A')
65
>>> ord('a')
97
If you compare these numbers to the ASCII chart above, you'll see that the value "65" is an encoded value for the upper case letter "A". And "97" is the encoded value for the lower case letter "a".
We can also do the reverse and take any ASCII numerical value and convert it into its character equivalent using the built-in chr() function. The chr() function takes the numerical value you want to convert as its only argument and it returns the character for that numerical value. Here's an example from the Python Shell:
>>> chr(90) 'Z' >>> chr(122) 'z'
String indexing
Because strings are just a series of characters, we can find each character individually using what's called an "index". Given a string called "my_string" which stores "Paddington" the corresponding index for each character is as follows:
| index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| my_string = | P | a | d | d | i | n | g | t | o | n |
So the first character is the '0' index and then each character after it increments that index by one. We can gain access to characters individually using square brackets to specify a specific character index using the form str[index]. Here's an example where we're accessing the first three characters (indices 0, 1, and 2) and building a new string by concatenating those three characters:
>>> my_string = "Paddington" >>> new_string = my_string[0] + my_string[1] + my_string[2] >>> print(new_string) Pad
Python also allows you to use negative indices which allow you to index characters starting from the end of a string. So each character in a string actually has two indices associated with them (a positive and a negative index):
| index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| my_string = | P | a | d | d | i | n | g | t | o | n |
| negative index: | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
If you wanted to access characters starting from the end, you can use negative indices the same way as positive indices. Here is an example of creating a new string comprised of the last three characters concatenated in reverse order:
>>> my_string = "Paddington" >>> new_string = my_string[-1] + my_string[-2] + my_string[-3] >>> print(new_string) not
Getting the length of a string
Python has a built-in function called len() that can be used with various data types to get the length of that data. This length function can be used to return the number of characters in a string. Its syntax is len(str) and it returns the number of characters in the "str" string past to it. Here is an example:
>>> str = "Paddington is my cat"
>>> string_length = len(str)
>>> print('The string "' + str + '" is', string_length, 'characters long.')
The string "Paddington is my cat" is 20 characters long.
len(str) function can be used with any type of sequence object (you'll learn about other sequence types like "lists" and "dictionaries" in another learning module).
Sample program: the following example shows a simple way of indexing through a string and then printing the ASCII value for each character. It then does it by iterating through the string in reverse. Once you understand the code, try updating the code that that it only prints the values for every other character.
String Methods
When using built-in functions, the data you are working with is passed as a parameter to the function such as len(str). When working with objects (strings are objects in Python) we mentioned that they store data along with extra functions that work with that data. We call functions that are part of an object type a "method." To call a method, we access it using the object itself. For example, if working on a string, we call a method using the form str.method(...) where str is the string variable or literal and method is the name of the method you're calling. In this module, we will explain many of the methods related to strings and how to use them. There are many more methods that are beyond the scope of this document. For a full hist of Python string methods, you can visit the Python Documentation or run help(str) on the Python Shell.
str and substr are the string variables or literals that you are working with.
Boolean Checks
There are several methods that can tell us information about a string using boolean responses. Here a few important methods:
str.isalpha() returns True if str is all alphabet characters; otherwise False.
Examples of usage from a Python Shell:
>>> dog_name = "Anna" >>> dog_name.isalpha() True >>> "Anna is my dog".isalpha() # spaces are not in the alphabet False
str.isnumeric() returns True if str is all numeric characters; otherwise False.
Example:
>>> dog_age = "14" >>> dog_age.isnumeric() True >>> dog_age = "fourteen" >>> dog_age.isnumeric() False
str.isalnum() returns True if str is all alphabet or numeric characters; otherwise False.
Example:
>>> cat = "Paddington" >>> cat.isalnum() True >>> cat= "P@ddington" >>> cat.isalnum() False
str.isspace() returns True if str is all space characters; otherwise False.
Example:
>>> text = " " >>> text.isspace() True >>> text = " text with spaces " >>> text.isspace() False
Working with substrings
A substring is a string that is a subset (contained inside) of another string. For example, given the string "my cat's name is paddington", both of the strings "cat" and "paddington" are substrings of the original string. A The following methods deal with with finding and counting substrings.
str.find(substr) returns the index of the first occurring substr in str.
str.count(substr) returns the number of occurrences of substr in str.
Sample Program: example usage of the count() and find() methods. Once you understand the code, update it so that the search string is inputted from the user instead and then test it using different strings.
Note: If you are only trying to determine if a substring exists inside of a string, you can use the in keyword which will return a boolean value of True or False. Here's an example:
if (substr in str):
print(substr + " is in " + str)
else:
print(substr + " is NOT in " + str)
Modifying Strings
There are many methods that allow us to create new string objects that are based on the string being accessed.
str.find(substr) returns the index of the first occurring substr in str.
str.lower() returns a copy of str with all the characters converted to lowercase.
str.upper() returns a copy of str with all the characters converted to uppercase.
str.capitalize() returns a copy of str with the first character in uppercase.
str.replace(oldsubstr, newsubstr[,count]) returns a new copy of str with all occurrences of oldsubstr replaced by newsubstr. If the optional argument count is given, only the first count occurrences are replaced.
Sample Program: example usage of the count() and find() methods. Once you understand the code, update it so that the search string is inputted from the user instead and then test it using different strings.
Sequences and Iterables
In Python, a "sequence" is an object that has a series of ordered items. An "iterable" is an object that is capable of returning its members one at a time. All sequences are iterables and therefore because a string is a sequence of characters, a string is also iterable. Being iterable means that we can use it whenever we want to iterate over that object.
Sample Program: Looping through each character of a string:
More interestingly, lets say we want to take a message from the user and encode that message using the ASCII table:
Sample Program: Converting a string to ASCII values:
Slicing
Slicing is a technique used to select a series of items from a sequence. Slicing works in a similar fashion to indexing. Using indexing, you can select one item from a sequence of items:
>>> my_string = "supercalifragilisticexpialidocious" >>> my_string[0] 's'
Often though we will want to access a subset of a sequence. Slicing allows us to select a series of items from a sequence in one easy statement. The basic form for slicing is seq[start:end] where seq is a sequence data type such as a string, start is the starting index of items to obtain, and end is the ending index (exclusively) of the items to obtain. Here's an example:
>>> my_string = "supercalifragilisticexpialidocious" >>> my_string[0:5] 'super'
You also have the option of specifying a step size for the iteration of characters (just like with the
range() function) in the form seq[start:end:step_size]. So you can use code like the following:
>>> my_string = "supercalifragilisticexpialidocious"
>>> my_string[0:5:2]
'spr'
Any or all of the parameters (start, end, step_size) can be omitted and a
default value will be used in its place. The default starting value is index 0. The default end index is the length of the sequence. The default step size is 1.
Sample Program: Try to predict the results of the following examples before you run it.
Input: this string Output: git it
Click the "Run" button below to test your program. You can download the solution to this problem by clicking here.
Quiz
Now that you've completed this module, please visit our NYU Classes site and take the corresponding quiz for this module. These quizzes are worth 5% of your total grade and are a great way to test your Python skills! You may also use the following scratch space to test out any code you want.