Learning Object Categories from Google's Image Search
Rob Fergus1, Li Fei-Fei2, Pietro Perona2, Andrew Zisserman1
1 - Dept. of Engineering Science, Parks Road, Oxford, OX1 3PJ, U.K.
2 - Dept .of Electrical Engineering, California Institute of Technology, MS 136-93, Pasadena, CA 91125, USA.
Overview
The Internet contains billions of images but current methods for searching amongst them rely entirely on text cues such as the file name or surrounding HTML text. If we had robust object recognition models, we could use these to search the visual content of the images directly. A stumbling block to building object recognition models is that large numbers of images are required to set the parameters of the classifier.
This work looks at using Object Recognition and the Internet in a reciprocal manner. We propose models that can learn directly from the output of image search engines, such as Google's Image Search, bypassing the need to manually collect large quantities of training data. These models can then be used to refine the quality of the image search, or to search through other sources of images. The system is a black box which is given the name of a category and outputs an object model.
We evaluate two different types of object model. The first is a Constellation Model, explained in more detail here. The second is a bag-of-words type model, an extension of standard probabilistic latent semantic analysis (pLSA). We test our algorithms on a variety of datasets, comparing to algorithms trained on manually gathered sets of images.
The Challenge
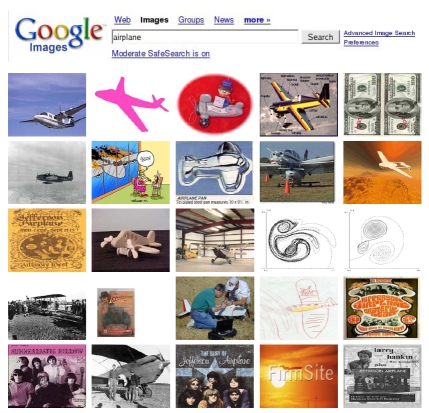
The performance of the existing image search engines is poor since they rely entirely on non-visual cues. Below is a typical page of images returned by Google's Image Search when querying for the word "airplane". Note the large portion of visually unrelated images. If our algorithms are to be trained directly from such data, they must be capable of ignoring such images. Additionally, those images containing airplanes exhibit huge variation.
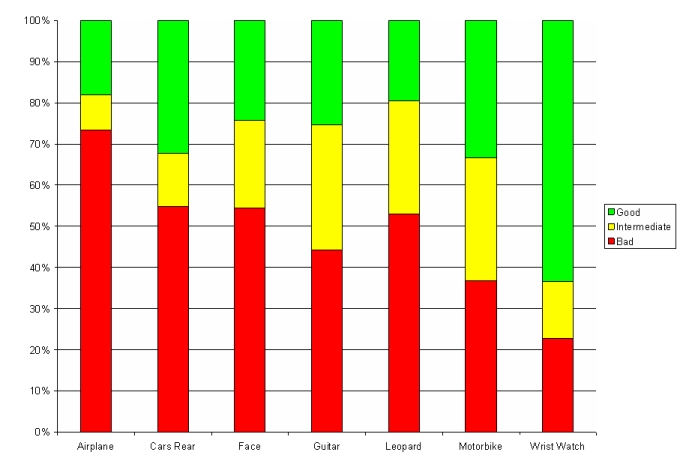
Since object recognition models have many parameters, they require lots of training images, much more than just one page of images from Google's Image Search. To quantify the performance of Google, we collected all the images returned (typically 500-700) for seven different query words and got someone (who knew nothing about our experiments) to label the images into one of three different states: Good (a good example of the query word); Junk (visually unrelated) and Intermediate (some visual relation, e.g. a cartoon of the object). The bar chart below gives a breakdown of the seven queries (Airplane, Car Rear, Face, Guitar, Leopard, Motorbike, Wrist Watch). From the chart, it is clear that we can only rely on around 20% of the images being nice examples from which we can hope to train our classifier.
If we hope to train a classifier automatically, the learning environment is not a friendly one: we have data highly contaminated with outliers, huge intra-class variability, pose variation and so on.
Two Different Algorithms
We trained two different models on the Google data.
- The Constellation Model. Link
- A variant of pLSA incorporating spatial information. Link
Improving the Quality of Google's Image Search
An obvious test of the models is to use them to re-rank the images returned by Google. If they have learnt the visual appearance of the object, the recall-precision curves should be significantly improved. Below we show the results of the Constellation Model and the three types of bag-of-words models, comparing the raw Google ranking. We plot the precision at 15% recall (corresponding to a couple of web -pages' worth of images) for the seven different classes.
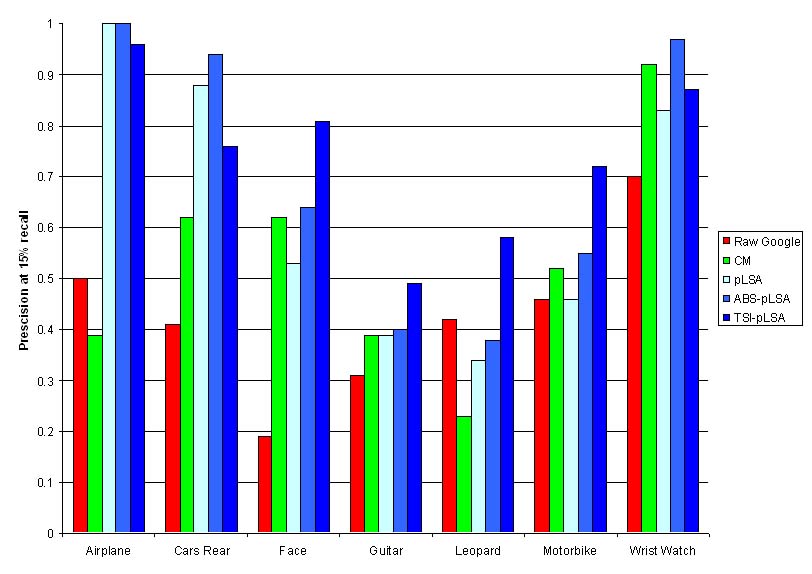
It is clear that the pLSA-based methods distinctly improve on the raw Google performance. The Constellation model improves search performance, but not very dramatically (making it worse in one case). Out of the pLSA-based methods, it is debatable which is better, the ABS-pLSA or the TSI-pLSA.
Wider Deployment of the Learnt Models
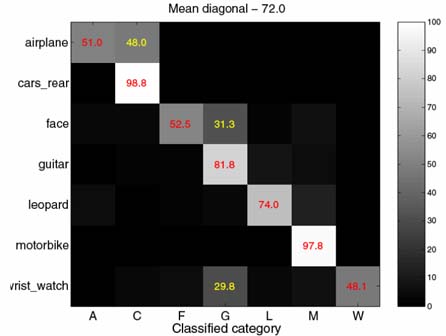
A more challenging test of the generalization power of the models is to test them on completely different data. For this purpose, we use some of the Caltech datasets. These are hand gathered images of the same classes for which we have trained models from Google. Below is a confusion table, with the rows showing the true image class and the columns showing the classified class. Perfect would be a diagonal row of 100%'s. While some classes score highly (cars rear and motorbikes), some classes do show some confusion (faces).
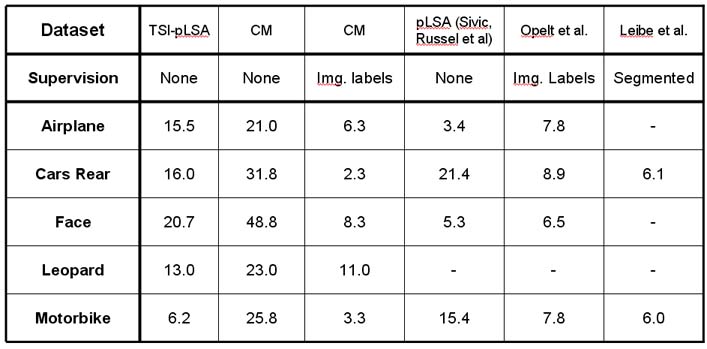
In the table below, we summarize the performance of the Google trained models against other methods which were trained on hand gathered images. The numbers represent the equal error rate (a lower number is better). The Constellation Model performance is very weak, but the TSI-pLSA performance performs reasonably compared with other methods, despite having no supervision in training.
Conclusions
We have proposed the idea of training using just the objects name, bootstrapping with an Internet image search engine. The training sets are extremely noisy yet, for the most part, the results are close to existing methods requiring hand gathered collections of images. This was achieved by improving state-of-the-art pLSA models with spatial information. The Constellation Model approaches proved less effective in this domain - while it was able to improve the quality of Google's image search, it did not generalize well to other datasets.
There are many open issues: the choice of features; better centroid proposals; the use of fixed background densities to assist learning; how to pick the most informative topics; the number of topics to use; the introduction of more sophisticated LDA models using priors etc.
Acknowledgements
Financial support was provided by: EC Project CogViSys; UK EPSRC; Caltech CNSE and the NSF. This work was supported in part by the IST Programme of the European Community, under the PASCAL Network of Excellence, IST-2002-506778. This publication only reflects the authors’ views. Thanks to Rebecca Hoath and Veronica Robles for image labeling. We are indebted to Josef Sivic for his considerable help with many aspects of the work.
Datasets
The Google datasets used in the ICCV 2005 paper are available here. The Caltech datasets used in the same paper are available here.
Links
- Visual Geometry Group, University of Oxford, UK.
- Vision Group, California Institute of Technology.
References
Learning Object Categories from Google's Image Search. Fergus, R. , Fei-Fei L. , Perona, P. and Zisserman, A. Proc. of the 10th Inter. Conf. on Computer Vision, ICCV 2005. [PDF]
A Visual Category Filter for Google Images. Fergus, R. , Perona, P. and Zisserman, A. Proc. of the 8th European Conf. on Computer Vision, ECCV 2004. [PDF]