Final Report
1.0 Introduction
Goal
Most DBMS vendors provide SQL extensions for dealing with ordered data (e.g., time series). Some DBMS vendors in particular implement the SQL:1999 standard features called SQL/OLAP Amendment. Those features support windowed table functions, grouped table functions, aggregate functions, etc. We are specifically interested in the use of order-based predicates and functions in the queries. The goal of our study is to evaluate how well such order-based queries do both in terms of readability and efficiency of their execution plans.
See here for all the necessary data and scripts to re-run the experiments. (Maybe I should put all data and scripts somewhere online later and put the link here)
Method
Kaippallimalil J. Jacob and Dennis Shasha proposed the FinTime benchmark, which modeled the practical uses of time-series databases in financial applications. Their model comprises two databases: Ticks, which involves non-periodic, sparse financial data; and Market, which involves periodic, dense financial data. For detailed information, see http://www.cs.nyu.edu/cs/faculty/shasha/fintime.html.
The two database models and queries against them have been used for the evaluation.
Procedure
The following figure shows the procedures used to implement the experiments.
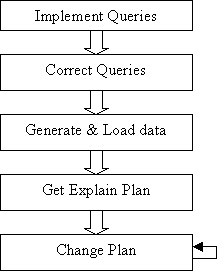
Implement queries: implement queries, proposed in the FinTime benchmark, in SQL and its extension.
Correct queries: check queries with the data, which is manually.
Generate & load data: generate data with the program from http://www.cs.nyu.edu/cs/faculty/shasha/fintime.d/gen.html. See Appendix for the parameters. Then load data into the database.
Get explain plan: get throughput-based explain plan based on original schemas, which are set up after tables are created. See http://otn.oracle.com/docs/products/oracle9i/doc_library/901_doc/server.901/a87503/ex_plan.htm for using explain plan in Oracle 9i.
Change plan: change explain plan through changing schema.
Environment
P4 1.6GHz, 768MB
Window XP
Oracle 9i
SQL, PL/SQL
Contributions
While the SQL extensions allow a large set of queries to be answered, at least two problems may arise. First, the DBMS do not always optimize those queries in the best possible way. Second, those extensions often compromise queries readability. In this document we identify some situations in which those problems arise.
This document is organized as follows. In each section, explain plans follow SQL query, then comments on explain plans and SQL query.
2.0 Tick Database
In the FinTime benchmark, Tick database includes two tables, trades and baseinfo. TableSEC100, which will be seen in the queries below, includes a specified set of securities.
2.1 Query 1
Get all ticks for a specified set of 100 securities for a specified three-hour time period on a specified trade date.
SQL
SELECT *
FROM trades tr, sec100 t
WHERE tr.id=t.id
AND EXTRACT(hour from tr.timestamp) BETWEEN 9 AND 12
AND tr.tradedate=TO_DATE('01-May-2002')
Explain plan
Before original schema is changed
7 SELECT STATEMENT
69 TABLE ACCESS BY INDEX ROWID TRADES
7 NESTED LOOPS
2 INDEX FULL SCAN SYS_C002719_1
69 INDEX RANGE SCAN PK_SEQNO
The plan above shows execution of a SELECT statement.
1. PK_SEQNO is used in index range scan
2. Table Sec100 is full scanned
3. Two tables are joined through NESTED LOOPS
4. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. The SELECT statement returns rows satisfying the WHERE clause conditions.
After original schema is changed by adding index on ID
7 SELECT STATEMENT
69 TABLE ACCESS BY INDEX ROWID TRADES
7 NESTED LOOPS
2 INDEX FULL SCAN SYS_C002719_1
69 INDEX RANGE SCAN INDEX_ID
The plan above shows execution of a SELECT statement.
1. INDEX_ID is used in index range scan
2. Table Sec100 is full scanned
3. Two tables are joined through NESTED LOOPS
4. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. The SELECT statement returns rows satisfying the WHERE clause conditions.
Comments:
The difference between the two plans is that different indexes are used in the index range scan of table TRADES.
Apparently, using INDEX_ID is the perfect solution for this query.
In both plans, table Sec100, which has much less rows, was chosen to be the outer of the nested loops. This way can improve performance of the query greatly. Thus the second explain plan is very good.
2.2 Query 2
Determine the volume-weighted price of a security considering only the ticks in a specified three-hour interval
SQL
SELECT id,
SUM(tradeprice*tradesize)/SUM(tradesize) wprice
FROM trades
WHERE id='Security_0'
AND EXTRACT(hour from
timestamp) BETWEEN 9 AND 12
AND tradedate=TO_DATE('01-May-2002')
Explain plan
Before original schema is changed
1 SELECT STATEMENT
1 SORT AGGREGATE
3 TABLE ACCESS BY INDEX ROWID TRADES
3 INDEX RANGE SCAN PK_SEQNO
The plan above shows execution of a SELECT statement.
1. PK_SEQNO is used in index range scan
2. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
3. Sum function is implemented by sort aggregate.
4. The SELECT statement returns aggregated result.
After original schema is changed by adding index on trades.id
1 SELECT STATEMENT
1 SORT AGGREGATE
3 TABLE ACCESS BY INDEX ROWID TRADES
3 INDEX RANGE SCAN INDEX_ID
The plan above shows execution of a SELECT statement.
1. INDEX_ID is used in index range scan
2. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
3. Sum function is implemented by sort aggregate.
4. The SELECT statement returns aggregated result.
Comments:
After tuned, the system chose INDEX_ID instead of PK_SEQNO for index range scan, which is the better solution for the query. But the explain plan does not use any order-based predicate.
2.3 Query 3
Determine the top 10 percentage losers for the specified date on the specified exchanges sorted by percentage loss. The loss is calculated as a percentage of the last trade price of the previous day.
SQL
SELECT *
FROM (SELECT id, per_loser,
RANK() OVER (ORDER BY per_loser ASC) loser_rank
FROM (SELECT t.id,
(t.mtp-y.mtp)/y.mtp per_loser
FROM
(SELECT id,
MIN(tradeprice) KEEP ( DENSE_RANK
LAST ORDER BY (timestamp) ) mtp
FROM trades
WHERE
tradedate=TO_DATE('1-May-2002')
AND tradeprice IS NOT NULL
GROUP BY
id) t,
(SELECT
id,
MIN(tradeprice) KEEP ( DENSE_RANK
LAST ORDER BY (timestamp) ) mtp
FROM trades
WHERE
tradedate=(SELECT MAX(tradedate)
FROM trades
WHERE tradedate <
TO_DATE('1-May-2002'))
AND tradeprice IS NOT NULL
GROUP BY id) y
WHERE
t.id=y.id)
WHERE per_loser<0)
WHERE loser_rank<=10
Explain plan
Before original schema is changed
1 SELECT STATEMENT
1 VIEW
1 WINDOW SORT PUSHED RANK
1 HASH JOIN
20 VIEW
20 SORT GROUP BY
13157 TABLE ACCESS FULL TRADES
20 VIEW
20 SORT GROUP BY
13157 TABLE ACCESS FULL TRADES
1 SORT
AGGREGATE
27511 TABLE ACCESS FULL TRADES
The plan above shows execution of a SELECT statement.
1. Table trades is full scanned
2. Max(tradedate) is determined by Sort Aggregate on the result of step 1
3. Table Trades is scanned with all conditions in WHERE clause is evaluated.
4. Analytical function results are given in a view for yesterday’s result after SORT GROUP BY.
5. Similarly, another view for today’s price is given.
6. Two views are joined by Hash Join
7. Results of step 6 are sorted by WINDOW SORT PUSHED RANK.
8. A view of ranked list is created.
9. The SELECT statement returns the result which rank = 1.
After original schema is changed by adding index on trades.date
1 SELECT STATEMENT
1 VIEW
1 WINDOW SORT PUSHED
RANK
1 HASH JOIN
20 VIEW
20 SORT GROUP
BY
13157 TABLE ACCESS BY INDEX ROWID TRADES
13157 INDEX RANGE SCAN INDEX_DATE
20 VIEW
20 SORT GROUP BY
13157 TABLE ACCESS BY INDEX ROWID
TRADES
13157 INDEX RANGE SCAN INDEX_DATE
1 SORT AGGREGATE
27511 FIRST ROW
27511 INDEX RANGE SCAN (MIN/MAX)
The plan above shows execution of a SELECT statement.
1. (MIN/MAX) is used in index range scan.
2. Only the first row of step 1 result is retrieved. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
3. Max(tradedate) is determined by Sort Aggregate on the result of step 2.
4. INDEX_DATE is used in index range scan.
5. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
6. Analytical function results are given in a view for yesterday’s result through SORT GROUP BY.
7. Similarly, another view for today’s price is given.
8. Two views in previous steps are joined through Hash Join
9. Results of step 8 are sorted by Widow sort pushed rank
10. A view of ranked list is created.
11. The SELECT statement returns the result which rank = 1.
Comments:
This query is kind of difficulty to read as the OVER clause can only be used in the SELECT, but can’t be used in the FROM, GROUP BY, etc. Also the RANK function cannot be used in the form of RANK(FUNCTION(…)). Therefore, whenever we want to make a restriction of its results we have to nest queries.
There are two differences between the two plans.
· Table trades is full accessed in the first plan, while index range scan in the second plan.
· Table trades is full accessed in the first plan for Max(tradedate), while index range scan and FIRST ROW are used in the second plan.
HASH JOIN, window sort pushed rank and index range scan make the second plan good. But in the tuned plan, using only one of step 2 or 3 would improves performance since tradedate is the only field involved.
2.4 Query 4
Determine the top 10 most active stocks for a specified date sorted by cumulative trade volume by considering all trades
SQL
SELECT *
FROM (SELECT id, vol,
RANK() OVER ( ORDER BY vol DESC ) as vol_rank
FROM (SELECT id,
SUM(tradesize) as vol
FROM trades
WHERE
tradedate = TO_DATE('1-MAY-2002')
GROUP BY id
))
WHERE vol_rank<=10
Explain plan
Before original schema is changed
20 SELECT STATEMENT
20 VIEW
20 WINDOW SORT PUSHED RANK
20 SORT GROUP BY
27511 TABLE ACCESS FULL TRADES
The plan above shows execution of a SELECT statement.
1. Table Trades is accessed with all conditions in WHERE clause evaluated.
2. (ID, vol) is generated after Sort group by.
3. A view of ranked list is created after Widow sort pushed rank
4. The SELECT statement returns the result where rank>=10.
After original schema is changed by adding index on trades.date
20 SELECT STATEMENT
20 VIEW
20 WINDOW SORT PUSHED
RANK
20 SORT GROUP BY
27511
TABLE ACCESS BY INDEX ROWID TRADES
27511
INDEX RANGE SCAN INDEX_DATE
The plan above shows execution of a SELECT statement.
1. INDEX_ID is used in index range scan
2. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
3. (ID, vol) is generated after Sort group by.
4. A view of ranked list is created after Widow sort pushed rank
5. The SELECT statement returns the result where rank>=10.
Comments:
SQL is readable, but complicate as the OVER clause can only be accepted in the SELECT and the form of OVER(SUM(…)) or RANK(SUM(…)) is not acceptable.
The difference between the two plans is that table trades is full accessed in the first plan, while index-range scanned in the second plan.
Window sort pushed rank and index range scan make the second plan good.
2.5 Query 5
Find the most active stocks in the "COMPUTER" industry (use SIC code)
SQL
SELECT *
FROM (SELECT id, vol, RANK() OVER ( ORDER BY vol
DESC) AS vol_rank
FROM (SELECT
trades.id, SUM(trades.tradesize) AS vol
FROM trades, baseinfo
WHERE
tradedate = TO_DATE('1-MAY-2002')
AND
trades.id=baseinfo.id
AND
baseinfo.sic='COMPUTER'
GROUP BY trades.id))
WHERE vol_rank<=1
Explain plan
Before original schema is changed
20 SELECT STATEMENT
20 VIEW
20 WINDOW SORT PUSHED RANK
20 SORT GROUP BY
2889 HASH JOIN
2 TABLE ACCESS FULL BASEINFO
27511 TABLE ACCESS FULL TRADES
The plan above shows execution of a SELECT statement.
1. Table Trades is accessed with all conditions in WHERE clause evaluated
2. Table Baseinfo is accessed with all conditions in WHERE clause evaluated
3. The two tables above are joined via HASH JOIN
4. (ID, vol) is generated after Sort group by.
5. A view of ranked vol is created after Widow sort pushed rank
6. The SELECT statement returns the result where rank<=1.
After original schema is changed by adding index on trades.id
20 SELECT STATEMENT
20 VIEW
20 WINDOW SORT PUSHED RANK
20 SORT GROUP BY
27511 TABLE ACCESS BY INDEX ROWID TRADES
2889 NESTED LOOPS
2 TABLE
ACCESS FULL BASEINFO
27511 INDEX RANGE SCAN INDEX_ID
The plan above shows execution of a SELECT statement.
1. Table BaseInfo is full scanned
2. INDEX_ID is used in index range scan
3. The two tables are joined via NESTED LOOPS
4. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. (ID, vol) is generated after Sort group by.
6. A view of ranked vol is created after Widow sort pushed rank
7. The SELECT statement returns the result where rank<=1.
Comments:
SQL is readable, but complicate as the OVER clause can only be accepted in the SELECT and the form of OVER(SUM(…)) or RANK(SUM(…)) is not acceptable.
The difference between the two plans is how to join table BASEINFO and TRADES.
Window sort pushed rank and index range scan make the second plan good.
2.6 Query 6
Find the 10 stocks with the highest percentage spreads. Spread is the difference between the last ask-price and the last bid-price. Percentage spread is calculated as a percentage of the mid-point price (average of ask and bid price).
SQL
SELECT *
FROM (SELECT id, per, RANK() OVER ( ORDER BY per
DESC) AS per_rank
FROM (SELECT a.id,
(ap-bp)*2/(ap+bp) AS per
FROM
(SELECT id,
MIN(bidprice) KEEP (DENSE_RANK LAST
ORDER BY timestamp) as bp
FROM
trades
WHERE
tradedate=TO_DATE('01-MAY-2002')
AND bidprice IS NOT NULL
GROUP
BY id) a,
(SELECT id,
MIN(askprice) KEEP (DENSE_RANK LAST
ORDER BY timestamp) AS ap
FROM trades
WHERE tradedate=TO_DATE('01-MAY-2002')
AND askprice IS NOT NULL
GROUP BY id) b
WHERE a.id=b.id ))
WHERE per_rank<=10
Explain plan
Before original schema is changed
20 SELECT STATEMENT
20 VIEW
20 WINDOW SORT PUSHED RANK
20 HASH JOIN
20 VIEW
20 SORT GROUP BY
6813 TABLE ACCESS FULL TRADES
20 VIEW
20 SORT GROUP BY
6813
TABLE ACCESS FULL TRADES
The plan above shows execution of a SELECT statement.
1. Table Trades is accessed with all conditions in WHERE clause evaluated.
2. A view including (ID, MIN(askprice)) is created after Sort group by.
3. Table Trades is accessed with all conditions in WHERE clause evaluated.
4. A view including (ID, MIN(bidprice)) is created after Sort group by.
5. The two views from step 2 and 4 are joined via HASH JOIN
6. A view of ranked list is created after Widow sort pushed rank
7. The SELECT statement returns the result where rank<=10.
After original schema is changed by adding index on trades.date
20 SELECT STATEMENT
20 VIEW
20 WINDOW SORT PUSHED RANK
20 HASH JOIN
20 VIEW
20 SORT GROUP BY
6813
TABLE ACCESS BY INDEX ROWID TRADES
6813 INDEX RANGE SCAN INDEX_DATE
20 VIEW
20 SORT GROUP BY
7541
TABLE ACCESS BY INDEX ROWID TRADES
7541 INDEX RANGE SCAN
INDEX_DATE
The plan above shows execution of a SELECT statement.
1. INDEX_ID is used in index range scan.
2. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
3. A view including (ID, MIN(askprice)) is created after Sort group by.
4. INDEX_ID is used in index range scan
5. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
6. A view including (ID, MIN(bidprice)) is created after Sort group by.
7. The two views from step 3 and 6 are joined via HASH JOIN
8. A view of ranked list is created after Widow sort pushed rank
9. The SELECT statement returns the result where rank<=10.
Comments:
SQL query is readable, but complex.
The difference between the two plans is that table trades is full accessed in the first plan, while index range scan is used in the second plan.
WINDOW SORT PUSHED RANK, HASH JOIN, INDEX RANGE SCAN make the second plan good.
This query was somewhat hard to express and generated a rather complex SQL. The plan was then complex too. Now, suppose we were to use SQL/PL instead of SQL. Table Trades could be accessed only once instead of twice.
3.0 Historic Database
In the FinTime benchmark, Historic database includes four tables, stock splits, dividends, market data and baseinfo. TableSEC10, which will be seen in the queries below, includes a specified set of securities.
3.1 Query 1
Get the closing price of a set of 10 stocks for a 10-year period and group into weekly, monthly and yearly aggregates. For each aggregate period determine the low, high and average closing price value. The output should be sorted by id and trade date
SQL
SELECT MData.id,
TRUNC(tradedate,'W') AS week,
TRUNC(tradedate,'MM') AS mon,
TRUNC(tradedate,'YY') AS year,
MAX(closeprice) AS max_price,
MID(closeprice) AS min_price,
AVG(closeprice) AS avg_price
FROM MData, sec10
WHERE tradedate BETWEEN
TO_DATE('January 11, 1992', 'Month dd,
YYYY', 'NLS_DATE_LANGUAGE=
American')
AND TO_DATE('May 8, 2002', 'Month dd,
YYYY',
'NLS_DATE_LANGUAGE= American')
AND MData.id=sec10.id
GROUPD BY MData.id,
ROLLUP(TRUNC(tradedate,'YY'),
TRUNC(tradedate,'MM'),
TRUNC(tradedate,'W'))
ORDER BY MData.id
Explain plan
Before original schema is changed
4 SELECT STATEMENT
4 SORT GROUP BY ROLLUP
30 TABLE ACCESS BY
INDEX ROWID MDATA
4 NESTED LOOPS
2 TABLE ACCESS
FULL SEC10
30 INDEX RANGE
SCAN PK_MDATA
The plan above shows execution of a SELECT statement.
1. Table SEC10 is full scanned
2. PK_MDATA is used in index range scan
3. The two tables are joined via NESTED LOOPS
4. The table TRADES is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. Results of step 4 are sorted and analyzed by SORT GROUP BY ROLLUP
6. The SELECT statement results are returned.
After original schema is changed by adding index on mdata.id
4 SELECT STATEMENT
4 SORT GROUP BY ROLLUP
30 TABLE ACCESS BY
INDEX ROWID MDATA
4 NESTED LOOPS
2 TABLE ACCESS
FULL SEC10
30 INDEX RANGE
SCAN INDEX_MDATAID
The plan above shows execution of a SELECT statement.
1. Table SEC10 is full scanned
2. INDEX_MDATAID is used in index range scan
3. The two tables are joined via NESTED LOOPS
4. The table mdata is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. Results of step 4 are sorted and analyzed by SORT GROUP BY ROLLUP
6. The SELECT statement results are returned.
Comments:
The SQL query is not simple, but the rollup makes it easier to read.
The difference between the two plans is that two different indexes are used for the index range scan in MDATA. As PK_MDATA includes ID and date, these two plans are same.
The plans are good by using ROLLUP.
3.2 Query 2
Adjust all prices and volumes (prices are multiplied by the split factor and volumes are divided by the split factor) for a set of 1000 stocks to reflect the split events during a specified 300 day period, assuming that events occur before the first trade of the split date. These are called split-adjusted prices and volumes.
SQL
SELECT
b.HIGHPRICE/PRDSPLIT(b.id,b.tradedate) h_price,
b.LOWPRICE/PRDSPLIT(b.id,b.tradedate) l_price,
b.CLOSEPRICE/PRDSPLIT(b.id,b.tradedate) c_price,
b.OPENPRICE/PRDSPLIT(b.id,b.tradedate) o_price,
b.Volume*PRDSPLIT(b.id,b.tradedate)
vol
FROM MData AS b
WHERE b.tradedate BETWEEN
TO_DATE('March 11, 2002', 'Month dd, YYYY',
'NLS_DATE_LANGUAGE= American')
AND TO_DATE('January 11, 2003', 'Month dd,
YYYY',
'NLS_DATE_LANGUAGE= American')
User-defined function: PRDSPLIT
CREATE FUNCTION
PRDSPLIT(sid IN VARCHAR2,sd IN DATE)
RETURN NUMBER IS
factors float;
Cursor c1 is
SELECT sfactor
FROM splits
WHERE splits.id=sid and splits.splitdate>sd;
BEGIN
factors
:= 1.0;
For
factor IN c1 LOOP
factors := factor.sfactor * factors;
END
LOOP;
return(factors);
END PRDSPLIT;
Explain plan
Before original schema is changed
3575 SELECT STATEMENT
3575 TABLE ACCESS FULL MDATA
After original schema is changed by adding index on mdata.date
3575 SELECT STATEMENT
3575
TABLE ACCESS BY INDEX ROWID MDATA
3575 INDEX RANGE SCAN INDEX_DATE
Comments:
SQL query is simple by using user-defined function PRDSPLIT. But as it is not a standard function, the readability is decreased. Furthermore the performance of PRDSPLIT is not good because lots of calculation is redundant.
If Oracle provides PRODUCT as an aggregate function, the SQL query would be the following.
SELECT b.HIGHPRICE/PRODUCT()
h_price,
b.LOWPRICE/ PRODUCT() l_price,
b.CLOSEPRICE/ PRODUCT () c_price,
b.OPENPRICE/ PRODUCT () o_price,
b.Volume* PRODUCT() vol
FROM MData AS b
WHERE b.tradedate BETWEEN
TO_DATE('March 11, 2002', 'Month dd, YYYY',
'NLS_DATE_LANGUAGE= American')
AND TO_DATE('January 11, 2003', 'Month dd,
YYYY',
'NLS_DATE_LANGUAGE= American')
GROUP BY id, tradedate
Explain plan is only for SQL part, not those inside of PRDSPLIT. Its complexity is hidden in the UDF.
3.3 Query 3
For each stock in a specified list of 1000 stocks, find the differences between the daily high and daily low on the day of each split event during a specified period.
SQL
SELECT m.id,
highprice-lowprice AS d_price, m.tradedate
FROM mdata m, splits s, sec10 ss
WHERE ss.id=m.id
AND m.id=s.id
AND m.tradedate=s.splitdate
AND m.tradedate BETWEEN TO_DATE('January 11,2002', 'Month
dd,
YYYY', 'NLS_DATE_LANGUAGE= American')
AND TO_DATE('January 11, 2004', 'Month dd,
YYYY',
'NLS_DATE_LANGUAGE= American')
ORDRE BY m.id
Explain plan
Before original schema is changed
70 SELECT STATEMENT
70 SORT ORDER BY
70 HASH JOIN
2 TABLE ACCESS
FULL SEC10
8792
TABLE ACCESS BY INDEX ROWID MDATA
704 NESTED LOOPS
25 INDEX FAST
FULL SCAN PK_SPLITS
8792 INDEX RANGE SCAN PK_MDATA
The plan above shows execution of a SELECT statement.
1. PK_SPLITS is used to full scan table splits
2. PK_MDATA is used in index range scan
3. The two tables splits and mdata are joined via NESTED LOOPS
4. The table mdata is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. Table sec10 is full scanned
6. Results from step 4 and 5 are joined via HASH JOIN
7. Joined results are sorted by SORT ORDER BY
8. The SELECT statement results are returned.
After original schema is changed by adding index on mdata.id
70 SELECT STATEMENT
70 SORT ORDER BY
70 NESTED LOOPS
879 NESTED LOOPS
2 TABLE ACCESS
FULL SEC10
8792
TABLE ACCESS BY INDEX ROWID MDATA
8792 INDEX RANGE SCAN INDEX_MDATAID
8792 INDEX UNIQUE SCAN PK_SPLITS
The plan above shows execution of a SELECT statement.
1. INDEX_MDATAID is used in index range scan
2. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
3. Table SEC10 is full scanned
4. The two tables above are joined via NESTED LOOPS
5. The result of step 4 as the outer of NESTED LOOPS and table SPLITS as the inner are joined. PK_SPLITS of SPLITS is used in INDEX UNIQUE SCAN.
6. Joined results are sorted by SORT ORDER BY
7. The SELECT statement results are returned.
Comments:
SQL query is simple.
The difference between the two plans is that nested loops and hash join are applied in the first plan, while two nested loops in the second plan.
INDEX FAST FULL SCAN makes the first plan good. In the second plan, as all three tables in the query have indexes on the ID, using two nested loops in the second plan shows promising performance. Also INDEX UNIQUE SCAN can give benefits to the performance. Consequently the second plan is very good. But the query does not use any order-based predicate or function.
3.4 Query 4
Calculate the value of the S&P500 and Russell 2000 index for a specified day using unadjusted prices and the index composition of the 2 indexes (see appendix for spec) on the specified day
SQL
Not implemented yet as the testing data can’t satisfy with the definitions of the two indexes.
3.5 Query 5
Find the 21-day and 5-day moving average price for a specified list of 1000 stocks during a 6-month period. (Use split adjusted prices)
SQL
SELECT m.id,
tradedate,
AVG(closeprice/PRDSPLIT(m.id, tradedate))
OVER (PARTITION BY m.id ORDER BY m.id, m.tradedate
ROWS 20 PRECEDING) AS avg_21,
AVG(closeprice)
OVER (PARTITION BY m.id ORDER BY m.id, m.tradedate ROWS
4
PRECEDING) AS avg_5
FROM mdata m, sec10 s
WHERE m.id = s.id
AND m.tradedate BETWEEN TO_DATE('June 01, 2002', 'Month dd,
YYYY',
'NLS_DATE_LANGUAGE= American')
AND TO_DATE('January 01,
2003', 'Month dd,
YYYY', 'NLS_DATE_LANGUAGE=
American')
Explain plan
Before original schema is changed
306 SELECT STATEMENT
306 WINDOW SORT
3062
TABLE ACCESS BY INDEX ROWID MDATA
306 NESTED LOOPS
2 TABLE ACCESS
FULL SEC10
3062 INDEX RANGE SCAN PK_MDATA
The plan above shows execution of a SELECT statement.
1. Table SEC10 is full scanned
2. PK_MDATA is used in index range scan
3. The two tables are joined via NESTED LOOPS.
4. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. Join results are analyzed by WINDOW SORT
6. The SELECT statement results are returned.
After original schema is changed by adding index on mdata.id
306 SELECT STATEMENT
306 WINDOW SORT
3062
TABLE ACCESS BY INDEX ROWID MDATA
306 NESTED LOOPS
2 TABLE ACCESS
FULL SEC10
3062 INDEX RANGE SCAN INDEX_MDATAID
The plan above shows execution of a SELECT statement.
1. Table SEC10 is full scanned
2. INDEX_MDATAID is used in index range scan
3. The two tables are joined via NESTED LOOPS.
4. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. Join results are analyzed by WINDOW SORT
6. The SELECT statement results are returned.
After table Mdata is physically organized through the index on mdata.id and Mdata.tradedate.
306 SELECT STATEMENT
306 WINDOW SORT
306 NESTED LOOPS
3062
INDEX FAST FULL SCAN PK_MDATA
2 INDEX RANGE SCAN
INDEX_SECID
The plan above shows execution of a SELECT statement.
1. INDEX_SECID is used in index range scan
2. PK_MDATA is used in index fast full scan
3. The two tables are joined via NESTED LOOPS.
4. Join results are analyzed by WINDOW SORT
5. The SELECT statement results are returned.
Comments:
SQL query is simple by using analytical function and UDF.
The difference between the first two plans is that two different indexes are used for the index range scan in MDATA. As PK_MDATA includes ID and date, these two plans are same.
In the third plan above, the index organized Mdata did not save WINDOW sort.
3.6 Query 6
(Based on the previous query) Find the points (specific days) when the 5-month moving average intersects the 21-day moving average for these stocks. The output is to be sorted by id and date.
SQL
CREATE TABLE temp6
AS SELECT m.id,
tradedate,
AVG(closeprice)
OVER (PARTITION BY m.id ORDER BY m.id,
m.tradedate
ROWS 20 PRECEDING) AS avg_21,
AVG(closeprice)
OVER (PARTITION BY m.id ORDER BY m.id,
m.tradedate
ROWS 4 PRECEDING) AS avg_5
FROM mdata m, sec10 s
WHERE m.id = s.id
AND m.tradedate BETWEEN TO_DATE('June 01, 2002',
'Month
dd, YYYY',
'NLS_DATE_LANGUAGE=
American')
AND TO_DATE('January 01, 2003',
'Month dd, YYYY',
'NLS_DATE_LANGUAGE= American')
SELECT id, tradedate
FROM (SELECT id AS id,
tradedate, avg_5-avg_21 AS diff,
LAG(avg_5-avg_21) OVER (PARTITION BY id ORDER
BY id,
tradedate) AS pre_diff
FROM temp6)
WHERE pre_diff*diff<=0
AND NOT (pre_diff=0 and diff=0)
ORDER BY id, tradedate
Explain plan
Before original schema is changed
306 CREATE TABLE STATEMENT
LOAD AS SELECT
306 WINDOW SORT
3062 TABLE ACCESS BY INDEX ROWID MDATA
306 NESTED LOOPS
2 TABLE ACCESS FULL SEC10
3062
INDEX RANGE SCAN PK_MDATA
204 SELECT STATEMENT
204 VIEW
204 WINDOW SORT
204 TABLE ACCESS FULL TEMP6
After original schema is changed by adding index on mdata.id
306 CREATE TABLE STATEMENT
LOAD AS SELECT
306 WINDOW SORT
3062
TABLE ACCESS BY INDEX ROWID MDATA
306 NESTED LOOPS
2 TABLE ACCESS
FULL SEC10
3062
INDEX RANGE SCAN INDEX_MDATAID
204 SELECT STATEMENT
204 VIEW
204 WINDOW SORT
204 TABLE ACCESS FULL TEMP6
Comments:
SQL is very complex, but readable.
The first partsof its two plans is the same as those in 3.5. The second parts are quite easy to be understood.
3.7 Query 7
Determine the value of $100,000 now if 1 year ago it was invested equally in 10 specified stocks (i.e. allocation for each stock is $10,000). The trading strategy is: When the 20-day moving average crosses over the 5-month moving average the complete allocation for that stock is invested and when the 20-day moving average crosses below the 5-month moving average the entire position is sold. The trades happen on the closing price of the trading day.
SQL
1. Create table temp7(id,
tradedate, avg_price_21_day, avg_price_5_mon)
CREATE TABLE temp7
AS SELECT m.id, tradedate,
AVG(closeprice) OVER (PARTITION BY m.id
ORDER BY m.id,
m.tradedate ROWS 20
PRECEDING)
AS avg_21,
AVG(closeprice) OVER (PARTITION BY m.id
ORDER BY m.id,
m.tradedate ROWS 160
PRECEDING)
AS avg_5
FROM
mdata m, sec10 s
WHERE
m.id = s.id
AND m.tradedate BETWEEN TO_DATE('June 01, 2002',
'Month dd, YYYY',
'NLS_DATE_LANGUAGE= American')
AND TO_DATE('June 01, 2003',
'Month dd,
YYYY',
'NLS_DATE_LANGUAGE= American')
2. Create table temp71(id,
tradedate, diff, td2, diff2)
id: stock id
tradedate: buying date
diff: difference between the two average prices on the buying
day.
Td2: selling date
Diff2: difference between the two average
prices on the selling day.
CREATE TABLE temp71
AS SELECT *
FROM (SELECT id, tradedate, diff,
LEAD(tradedate)
OVER (PARTITION BY id ORDER BY
id, tradedate) td2,
LEAD(diff) over
(PARTITION BY id ORDER BY id,
tradedate) diff2
FROM (SELECT id,
tradedate, avg_21-avg_5 as diff,
LAG(avg_21-avg_5) OVER (PARTITION BY ID
ORDER BY id, tradedate)
AS pre_diff
FROM
temp7)
WHERE pre_diff*diff<=0
AND NOT (pre_diff=0 and diff=0))
WHERE diff>0
3. If in the end of the
month the stock is held, set the end of month as the selling date
UPDATE temp71
SET td2=TO_DATE('June 01,
2003', 'Month dd, YYYY',
'NLS_DATE_LANGUAGE=
American')
WHERE td2 IS Null
4.
Calculating every stock and sum the total.
SELECT SUM(Q7(id)*10000)
AS total
FROM sec10
User-defined function
CREATE FUNCTION Q7(iid IN
VARCHAR2)
RETURN
NUMBER IS
factors
float;
Cursor
c1 is
SELECT
M1.closeprice cp1, M2.closeprice cp2
FROM MData
M1, MData M2, temp71 t
WHERE M1.id=iid and M2.id=iid and t.id=iid
and
t.tradedate=M1.tradedate
and
t.td2=M2.tradedate;
BEGIN
factors := 1.0;
For factor IN c1 LOOP
factors := factors/factor.cp1*factor.cp2;
END LOOP;
return(factors);
END Q7;
Comments:
SQL is complicate and difficult to be read. Thus no explain plan is listed.
3.8 Query 8
Find the pair-wise
coefficients of correlation in a set of 10 securities for a 2- year
period. Sort the securities by the coefficient of correlation, indicating the
pair of securities corresponding to that row. [Note: coefficient of correlation
defined in appendix of FinTime benchmark]
SQL
SELECT m.id, m1.id,
CORR(m.closeprice, m1.closeprice) AS corr
FROM mdata m, mdata m1, sec10 a, sec10 b
WHERE m.id=a.id
and m1.id=b.id
and a.id>b.id
and m.tradedate=m1.tradedate
and m.tradedate BETWEEN
TO_DATE('January 11, 2002', 'Month dd,
YYYY', 'NLS_DATE_LANGUAGE= American')
AND
TO_DATE('January 11, 2004', 'Month dd,
YYYY', 'NLS_DATE_LANGUAGE=
American')
GROUP BY m.id, m1.id
Explain plan
Before original schema is changed
3 SELECT STATEMENT
3 SORT GROUP BY
5 HASH JOIN
2 TABLE ACCESS
FULL SEC10
901 HASH JOIN
879 HASH JOIN
2 TABLE ACCESS FULL SEC10
8792 TABLE ACCESS FULL MDATA
8792 TABLE ACCESS FULL MDATA
The plan above shows execution of a SELECT statement.
1. SEC10 is full scanned
2. MDATA is full scanned
3. The two scanned tables in step 1 and 2 are joined via HASH JOIN
4. MDATA is full scanned
5. The results of step 3 and 4 are joined via HASH JOIN
6. SEC10 is full scanned
7. The results of step 5 and 6 are joined via HASH JOIN
8. Joined results are analyzed by SORT GROUP BY
9. The SELECT statement results are returned.
After original schema is changed by adding INDEX_MDATE and INDEX_MDATAID
3 SELECT STATEMENT
3 SORT GROUP BY
5 HASH JOIN
2 TABLE ACCESS
FULL SEC10
901 HASH JOIN
8792
TABLE ACCESS BY INDEX ROWID MDATA
879 NESTED
LOOPS
2 TABLE ACCESS FULL SEC10
8792
INDEX RANGE SCAN
INDEX_MDATAID
8792
TABLE ACCESS BY INDEX ROWID MDATA
8792 INDEX RANGE SCAN INDEX_MDATE
The plan above shows execution of a SELECT statement.
1. Table SEC10 is full scanned
2. INDEX_MDATAID is used in index range scan
3. The two tables are joined via NESTED LOOPS
4. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
5. INDEX_MDATE is used in index range scan
6. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
7. The results of step 3 and 6 are joined via HASH JOIN
8. SEC10 is full scanned
9. The results of step 7 and 8 are joined via HASH JOIN
10. Joined results are analyzed by SORT GROUP BY
11. The SELECT statement results are returned.
Comments:
SQL query is simple by using CORR function.
The difference between the two plans is that after adding two indexes, one nested loops, which improves performance by index range scan, replaces one hash join. Another solution is that using two nested loops based on four ids index, then hash-join them together. The trades-off is that INDEX_MDATE cannot be applied. Still the second plan is good plan.
3.9 Query 9
Determine the yearly dividends and annual yield (dividends/average closing price) for the past 3 years for all the stocks in the Russell 2000 index that did not split during that period. Use unadjusted prices since there were no splits to adjust for
SQL
SELECT mdata.id,
TRUNC(tradedate, 'yyyy') AS year,
SUM(divamt)/AVG(closeprice)
FROM mdata, divid
WHERE mdata.id=divid.id
AND mdata.tradedate>=TO_DATE('January 01, 1999', 'Month
dd, YYYY',
'NLS_DATE_LANGUAGE= American')
AND TRUNC(tradedate,'yyyy')=TRUNC(xdivdate,'yyyy')
AND
mdata.id NOT IN (SELECT splits.id
FROM splits
WHERE mdata.id=splits.id
AND
TRUNC(tradedate,'yyyy')=
TRUNC(splitdate,'yyyy') )
GROUP BY mdata.id, TRUNC(tradedate, 'yyyy')
Explain plan
Before original schema is changed
1 SELECT STATEMENT
1 SORT GROUP BY
1 NESTED LOOPS ANTI
1 NESTED LOOPS
1 TABLE ACCESS FULL DIVID
80000
TABLE ACCESS BY INDEX ROWID MDATA
80000
INDEX RANGE SCAN PK_MDATA
315 INDEX RANGE SCAN PK_SPLITS
The plan above shows execution of a SELECT statement.
1. Table DIVID is full scanned
2. PK_MDATA is used in index range scan
3. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
4. The results of step 1 and 3 are joined via NESTED LOOPS
5. PK_SPLITS is used in index range scan
6. The results of step 4 and 5 are joined via NESTED LOOPS
7. Joined results are analyzed by SORT GROUP BY
8. The SELECT statement results are returned.
After original schema is changed by adding INDEX_MDATAID
1 SELECT STATEMENT
1 SORT GROUP BY
1 NESTED LOOPS ANTI
1 NESTED LOOPS
1 TABLE ACCESS
FULL DIVID
80000
TABLE ACCESS BY INDEX ROWID MDATA
80000
INDEX RANGE SCAN INDEX_MDATAID
315 INDEX RANGE SCAN PK_SPLITS
The plan above shows execution of a SELECT statement.
1. Table DIVID is full scanned
2. INDEX_MDATAID is used in index range scan
3. The table MDATA is accessed via ROWID. ROWIDs are obtained from the index in the previous step for keys that meet the WHERE clause criteria. When the table is accessed, any additional WHERE clause conditions that could not be evaluated during the range scan are also evaluated.
4. The results of step 1 and 3 are joined via NESTED LOOPS
5. PK_SPLITS is used in index range scan
6. The results of step 4 and 5 are joined via NESTED LOOPS
7. Joined results are analyzed by SORT GROUP BY
8. The SELECT statement results are returned.
Comments:
SQL query is readable but not simple as one of three tables involved is in a correlated sub-query. But, order exploration is not the cause of the complexity here.
The difference between the two plans is that different indexes are used in index range scan.
In the second plan, the two nested loops benefit from two indexes and can provide good performance for the query. Thus the second plan is quite good.
4.0 Conclusions
Oracle 9i SQL/OLAP implementation provides aggregate and analytical functions that ultimately make possible to express most of FinTime queries. In some cases, readability was good. For example, in 3.1 query, ROLLUP function makes the query very simple and readable (although rollup is not part of the OLAP amendment); in queries 3.5 and 3.6, the windowed version of the avg function , made it possible to implementing the two queries.
In other cases, missing functionality or restricted syntax made queries less than easy to express. In query 3.2, user-defined function has to be implemented because a prd aggregate function is missing. Similarly in query 3.7. In queries 2.3 – 2.6, where nesting has to happen because of restrictions on the use of OVER clause and Rank function.
Most of time the optimizer works well with changing schema. For example, in query 2.1, it picked up the right index after adding a new index. But it does not work well with compounded index, which is consisted of more than one field. For example in query 3.1, optimizer did not utilize the compounded index, PK_MDATA.
In all explain plans above we studied, there is no use of any order-based predicate, even when the query works on index-organized tables. For example, in query 3.5, Index-organized table did not save sort in the explain plan.
Appendix
histgen 20 2000
/*20 scale 2000 days*/
20 scale means 20 stocks involved in the data
2000 days means 2000 days’ activities of involved stocks
tickgen n 20 t 20 d 30
/*20 scale 20 ticks 30 days*/
20 scale means 20 stocks involved in the data
20 per ticks mean 20 ticks every second
30 days means 30 days’ activities of involved stocks