Handed out Monday, April 5, 2010
Due Friday, April 23, 2010, 11:59 PM
Use Git to commit your Lab 5 source, fetch the latest version of the course repository, and then create a local branch called lab6 based on our lab6 branch, origin/lab6:
mig% cd ~/CS372H/lab mig% add git mig% git commit -am 'my solution to lab5' Created commit 734fab7: my solution to lab5 4 files changed, 42 insertions(+), 9 deletions(-) mig% git pull Already up-to-date. mig% git checkout -b lab6 origin/lab6 Branch lab6 set up to track remote branch refs/remotes/origin/lab6. Switched to a new branch "lab6" mig% git merge lab5 Merge made by recursive. fs/fs.c | 42 +++++++++++++++++++ 1 files changed, 42 insertions(+), 0 deletions(-) mig%
The network card driver, however, will not be enough to get your OS hooked up to the Internet. In the lab6 code, we have provided you with a network stack and a network server. Explore the contents of the new net/ directory, as well as the new files in kern/.
In addition to writing the driver, you will need to create a system call interface to give access to your driver. You will implement missing network server code to transfer packets between the network stack and your driver. You will also tie everything together by finishing a web server. With the new web server you will be able to serve files from your file system.
Much of the kernel device driver code you will have to write yourself from scratch. There are no skeleton files and no system call interfaces written in stone. For this reason, we recommend that you read the entire assignment write up before starting any individual exercises.
As before, you will need to do all of the regular exercises described in the lab and at least one challenge problem. Additionally, you will need to write up brief answers to the questions posed in the lab and a short (e.g., one or two paragraph) description of what you did to solve your chosen challenge problem. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called answers-lab6.txt (plain text) or answers-lab6.html (HTML format) in the top level of your lab directory before handing in your work.
Late policy.When you are ready to hand in your lab code and write-up, create a file called slack.txt noting how many slack hours you have used both for this assignment and in total. (This is to help us agree on the number that you have used.) Then run make turnin in the lab directory. This will first do a make clean to clean out any .o files and executables, and then create a tar file called lab6-handin.tar.gz with the entire contents of your lab directory and submit it via the CS turnin utility. If you submit multiple times, we will take the latest submission and count slack hours accordingly.
We will be using QEMU's user mode network stack, which requires no administrative privileges to run. QEMU's documentation has more about user-net here.
A quick reference for using QEMU (and GDB) for debugging is here
The network card can be enabled as follows:
mig% qemu -hda obj/kern/kernel.img -hdb obj/fs/fs.img -serial mon:stdio -net user -net nic,model=i82559er
User-net can be viewed like a NAT that sits between JOS and the Internet; therefore, while JOS itself can make connections to the Internet, nothing outside of QEMU (including the computer running QEMU) can directly connect to servers running in JOS. QEMU's NAT runs on the 10.0.2.0 subnet: QEMU will assign JOS the IP address 10.0.2.15 by default and provide a router for the virtual network at IP 10.0.2.2. The network server needs to know these defaults, so they are defined in net/ns.h.
JOS's 10.0.2.15 address has no meaning outside the virtual network running inside QEMU, so we can't simply connect to servers running inside JOS. To fix this, we will ask QEMU to run a server listening on some port on your development machine that simply connects through to some port on JOS and shuttles data back and forth between your development machine's network and the virtual network running inside QEMU. We do this using QEMU's -redir option, for example:
qemu -hda obj/kern/kernel.img -hdb obj/fs/fs.img -serial mon:stdio -net user -net nic,model=i82559er -redir tcp:4242::7
This tells QEMU to listen on port 4242 and to forward connections to JOS's port 7. After this, executing nc localhost 4242 (or telnet localhost 4242) will connect to the server running on port 7 inside JOS.
In this lab, you will run JOS services on ports 7 and 80. The provided Makefile takes care of forwarding these two ports for you. To avoid collisions on shared lab machines, it will generate the local ports based on your user id. Thus, the easiest way to connect to these two ports is to run make nc-7 or make nc-80 (there are similar telnet- rules). You can also run make which-ports to print out the ports being used.
It is very helpful to examine any packets sent to or received from the host machine. However, since the details of user-net do not allow easy access to the packet flow, our version of QEMU provides a mechanism that dumps every packet that passes through user-net into a file. The file is stored using the pcap format. This popular packet capture file format allows you to use either tcpdump or wireshark to examine both the packet flow and packet structure. You can run QEMU with packet dumping using make qemu QEMUEXTRA="-pcap slirp.cap". More generally, in this lab, note the following convenience: make qemu runs QEMU for you with all of the network options that you need (you may wish to add QEMUEXTRA). You might also find make qemu-nox handy; this rule runs QEMU in the current terminal so avoids a separate graphics terminal.
To read the captured packets in ASCII use tcpdump like this:
tcpdump -nnxr slirp.cap
Wireshark is a graphical version of tcpdump, and is also installed on the CS machines.
Note that the -pcap option is only available in our version of QEMU.
We are very lucky to be using emulated hardware. Since the E100 is running in software, the emulated E100 can report to us, in a user readable format, its internal state and any problems it encounters. Normally, such a luxury would not be available to a driver developer writing with bare metal. To turn on E100 debug information use make qemu QEMUEXTRA="-debug-e100". While you can only have one QEMUEXTRA value, you can add more arguments between the double quotes.
Once the E100 debug command line option is set, the emulated E100 will print debug messages to the terminal where you launched QEMU. It will print lines like this:
EE100 eepro100_write1 addr=Command/Status+1 val=0x20 EE100 disable_interrupt interrupt disable
Note that the -debug-e100 option is only available in our version of QEMU.
You can take debugging using software emulated hardware one step further. If you are ever stuck and do not understand why the driver is not understanding your commands or is reporting cryptic messages, you can look at the emulated hardware source code for hints. The source for the E100 emulated hardware is in the QEMU tarball.
If you are running QEMU on your own machine you need to apply three new patches.
Writing a network stack from scratch is hard work. Instead, we will be using lwIP, an open source lightweight TCP/IP protocol suite that among many things includes a network stack. You can find more information on lwIP here. In this assignment, as far as we are concerned, lwIP is a black box that implements a BSD socket interface and has a packet input port and packet output port.
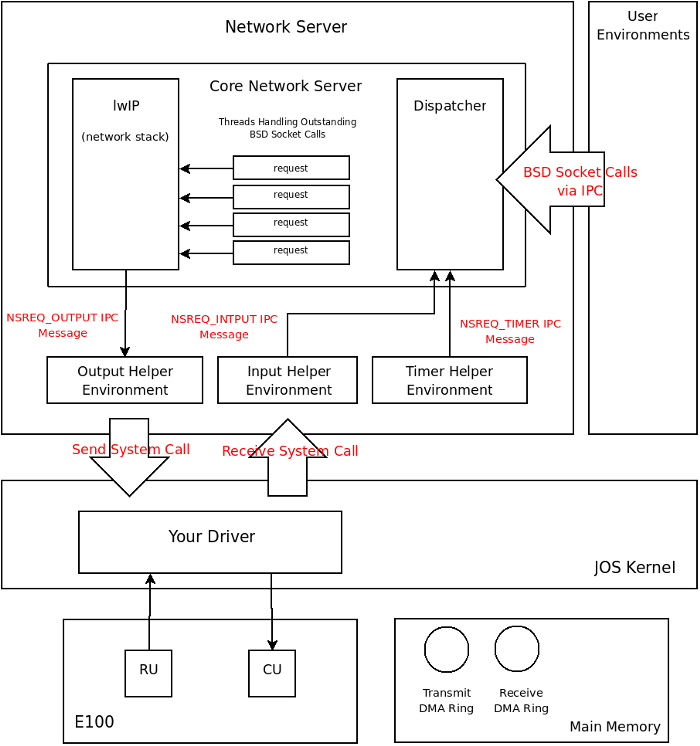
What we call the network server is actually a combination of four environments, they are:
The following diagram shows the different environments and their relationships. The diagram shows the entire system including the device driver which will be covered later.
The core network server environment is composed of the socket call dispatcher
and lwIP itself. The socket call dispatcher works exactly like the file server.
User environments use stubs (found in lib/nsipc.c) to send IPC
messages to the core network environment. If you look at
lib/nsipc.c you will see that we use the same trick as in the file
server to name the core network server: we start the network server right after
the file server thereby forcing the ns to have an envid of 2.
For each user environment IPC, the dispatcher calls the appropriate BSD socket
interface function provided by lwIP on behalf of the user. The file server
interface required that we implement a file descriptor to keep track of file
state; lwIP implements this facility for us. The subset of BSD socket calls
that our network server provides can be found in inc/lib.h. Take careful note that
closing a socket descriptor is done by closesocket and not simply
close (this is due to having a separate file and socket descriptor).
Even though it may seem that the IPC dispatchers of the file server and network
server act the same, there is a key difference. BSD socket calls like
accept and recv can block indefinitely. If the
dispatcher were to let lwIP execute one of these blocking calls, the dispatcher
would also block, in which case there could be only one outstanding network call
at a time for the whole system. Since this is unacceptable, the network
server uses user-level threading to avoid blocking the entire server
environment. For every incoming IPC message, the dispatcher creates a
thread and processes the request in the newly created thread. If the thread
blocks, then only that thread is put to sleep while other threads have a chance
to run. (Note that the threading is implemented inside lwIP.)
In addition to the core network environment there are three helper environments. We describe them below.
Not only does the dispatcher accept messages from user
applications, it also accepts messages from the timer environment.
The timer
environment periodically sends messages of type NSREQ_TIMER to the
core network server notifying it that a timer has expired. The timer's messages
from this thread are used by lwIP to implement TCP timeouts.
Unfortunately, your kernel does not have a notion of time; we need to add it. There is currently a clock interrupt that is generated by the hardware every 10ms. On every clock interrupt we can increment a variable to indicate that time has advanced by 10ms. This is implemented in kern/time.c, but is not yet fully integrated into your kernel.
Exercise 1.
Add a call to time_tick for every clock interrupt in
kern/trap.c. Implement sys_time_msec and add it
to syscall in kern/syscall.c so that user space has
access to the time.
Run the user/testtime.c user environment to test your time code. You
should see the environment count down from 10 in 1 second intervals.
You may have to comment out ENV_CREATE(net_ns) because
that environment will panic at this point in the lab. Don't forget to
uncomment it when you're done.
When servicing user environment socket calls, lwIP will generate packets for
the network card to transmit. LwIP will send each packet to be transmitted to
the output helper environment using the NSREQ_OUTPUT IPC message
with the packet attached in the page argument of the IPC message. The output
environment is responsible for accepting
these messages and forwarding the packet on to the device driver via the
system call interface that you will soon create.
The attached page holds a struct jif_pkt structure (defined in
inc/ns.h).
struct jif_pkt {
int jp_len;
char jp_data[0];
};
The first 4 bytes of the page, jp_len, represent the length of the
packet. All subsequent bytes in the page are dedicated to the packet contents.
Using a zero-length array like jp_data at the end of a
struct is a common C trick (some would say abomination) for
representing buffers without pre-determined lengths. Since C doesn't
do array bounds checking, as long as you ensure there's enough unused
memory following the struct, you can use jp_data as if it
were an array of any size.
In addition to the timer helper environment, the input helper environment also
sends messages to the core network server. Packets received by the network card
need to be injected into lwIP. For every packet received by the device driver,
the input environment pulls the packet out of kernel space (using kernel
system call(s) that you will implement) and sends the packet to the core
server environment using the NSREQ_INPUT IPC message.
The core network server expects all IPC input messages to have a page
attached with a struct jif_pkt structure filled in.
The packet input functionality is separated from the core network environment
because JOS makes it hard to simultaneously accept IPC messages and poll or wait
for a packet from the device driver. We do not have a select
system call in JOS that would allow environments to monitor multiple input
sources to identify which input is ready to be processed. (In other
words, the purpose of the output and input helper environments is to
make network card events look like IPCs.)
If you take a look at net/input.c and net/output.c you will see that both need to be implemented. This is mainly because the implementation depends on your system call interface. You will write the code for the two helper environments after you implement the driver and system call interface.
Writing a driver requires knowing in depth the hardware and the interface presented to the software. Understanding the hardware is easiest when the manufacturer provides manuals. Luckily for us, Intel has provided a very good set of manuals for the 82559ER, and you will have to get very well acquainted with them.
Exercise 2. Browse the Intel 82559 page and look at these two documents:
Do not worry about the details in your first pass. It is more important to read this assignment write-up first to get a high level picture of how the Intel chip is organized and what is needed to create a device driver.
When you do read the open source developer manual in depth, glance over Section 4 to learn about the PCI interface, but pay very close attention to Section 6 as it deals with the Software Interface. In fact, most everything you need is in Section 6. (Parts of Section 8 may also be useful, depending on how you are structuring your code.) Use the datasheet solely as a reference if you find the developer manual vague.
The acronyms in both documents can get overwhelming. Consult the glossary at the end of this lab assignment for some help.
The E100 is a PCI device, which means it plugs into the PCI bus on the motherboard. The PCI bus has address, data, and interrupt lines, and allows the CPU to communicate with PCI devices and PCI devices to read and write memory. A PCI device needs to be discovered and initialized before it can be used. Discovery is the process of walking the PCI bus looking for attached devices. Initialization is the process of allocating I/O and memory space as well as negotiating the IRQ line for the device to use.
We have provided you with PCI code in kern/pci.c.
To perform PCI initialization during boot, the PCI code walks the PCI
bus looking for devices. When it finds
a device, it read its vendor ID and device ID and uses these two values as a key
to search the pci_attach_vendor array. The array is composed of
struct pci_driver entries like this:
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
If there is an entry in the array that matches the vendor ID and device ID, the corresponding attach function is called to trigger device initialization. (Devices can also be identified by class, which is what the other driver table in kern/pci.c is for.)
The attach function is passed a PCI function to initialize. A PCI card can expose multiple functions, though the E100 exposes only one. Here is how we represent a PCI function in JOS:
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
The above structure corresponds to some of the entries found in Table
1 of Section 4 in the
developer manual. Specifically, the last three entries of
struct pci_func are of interest to us.
The reg_base array holds the negotiated values for the
memory or I/O addresses mapped to the device,
reg_size holds how many addresses (bytes or I/O ports)
have been allocated to each corresponding entry in
reg_base, and irq_line contains the IRQ line
the kernel needs to listen on to receive interrupts from the devices. The 6
entries in the reg_base array correspond to byte offsets 0x10 -
0x24 in Table 1 in the developer manual. Make sure you understand which entries
in reg_base and reg_size are valid for the
E100 and what the valid entries mean. (Note that Intel messed up the
headings for this section, so the details on these entries are in
section 4.1.10.)
When the attach function of a device is called, the
device has been found but not yet enabled. This means that the PCI code has
not yet allocated resources to the device, such as address space and
an IRQ line, and, thus, the last three elements of the struct
pci_func structure are not yet filled in. The attach function should call
pci_func_enable to enable the device, negotiate
resources, and fill in these last three fields with the results of
resource negotiation. Because the driver will need these addresses in
order to communicate with the device, the attach function should
record the results of negotiation for future
reference.
Exercise 3.
Implement an attach function to initialize the 82559ER. Add an entry to the
pci_attach_vendor array in kern/pci.c to trigger
your function if a matching PCI device is found. The vendor ID and device ID for
the 82559ER can be found in Section 4 of the developer manual. You
should also see these listed when JOS scans the PCI bus while booting.
After enabling the E100 device, your attach function should record the IRQ line and base I/O port assigned to the device so you'll be able to communicate with the E100.
We have provided the kern/e100.c and kern/e100.h files for you so that you do not need to mess with the make system. You may still need to include the e100.h file in other places in the kernel.
Make sure that your attach function is called when running QEMU and that you get a valid I/O port base before continuing. I/O port numbers are 16 bits, so they should be between 0 and 0xffff.
Many devices need to be reset to a consistent state before use. The 82559ER fortunately executes a hardware reset every time the computer boots up. If no other driver modifies the state of the 82559ER, it will be in a consistent state and ready for use as soon as the PCI bus allocates it resources. In our case, learning how to reset the 82559ER is a great way to get started with the 82559ER Software Interface and an easy way to check that you are using the PCI bus allocated resources correctly. Section 6.2 in the developer manual talks about reseting the card.
The E100 can be controlled by either memory mapped I/O or dedicated
I/O ports. We advise that you use I/O ports and the inb and
outb family of instructions to communicate with the E100. Using
memory mapped I/O requires thinking about what happens if the compiler or the
CPU reorders memory operations.
The 82559ER is controlled through the Control/Status Registers (CSR). The CSR is described in Section 6.3 in the developer manual. The CSR is a 64 byte long data structure that can be accessed by reading or writing ports starting from the base address given to the device by the PCI bus, which you found in the previous exercise. You will be working exclusively with the first 12 bytes of this structure. The System Control Block (SCB) is the name for the first 8 bytes of the CSR. The SCB is used to control and get status about the device. The next 4 bytes in the CSR are called PORT and are used to reset the chip.
Reading and writing to the CSR is simple. For example, to read the low 8 bits of
the SCB status word, you can use inb(base + 0x0). To read the high 8
bits, you can use inb(base + 0x1). To write a 0xd
into the SCB command word, you can use outw(base + 0x2, 0xd). To
write 0xdeadbeef into the SCB general pointer use
outl(base + 0x4, 0xdeadbeef). The type of command used is very
important. inb is used to read a byte, inw to read 2
bytes and inl to read 4 bytes.
Furthermore, a field's width is just as important as its address.
Unlike reading from memory, reading, say, a word from an I/O port is
not the same as reading two consecutive bytes. If you use the
wrong in instruction for a field, QEMU will crash with a
rather non-intuitive error like "feature is missing in this emulation:
unknown word read".
How do you know if you are successfully writing something to the device? That is where the QEMU -debug-e100 command line flag helps. Every time there is a write or read to a register in the CSR, the QEMU emulated E100 will print a message to the console. Look for these messages and make sure they correspond to what you are doing.
There are a couple of places where the 82559ER docs specify that a driver must
delay for a certain amount of time before continuing. An example delay function
can be found in kern/console.c. Each inb of port
0x84 takes about 1.25us; four of them, therefore, takes 5us.
Exercise 4. Add code to your attach function to reset the 82559ER. If you set the -debug-e100 flag, QEMU should tell you if the reset was successful. It will print something like this after JOS starts scanning the PCI bus:
EE100 nic_reset 0xacea498There will also be a few nic_reset's before JOS starts; those are the BIOS itself resetting the device.
Then 82559ER is divided into two halves: the Command Unit (CU) and the Receive Unit (RU). The CU and RU are described in Section 6.5 of the developer manual. The CU and RU are processors on the 82559ER that work independently of each other. The CU is responsible for executing control commands sent by the driver. For example, a driver can send a command to the CU to configure the device or a command to transmit a packet. The RU's job is to receive packets. The driver communicates with the CU and RU processors through the CSR and a pair of DMA rings (described in Section 6.4). DMA stands for Direct Memory Access, a general term referring to I/O devices reading and writing data in main memory.
A DMA ring is a set of buffers allocated in main memory and chained together by pointers. This ring is usually a circular singly-linked list where the pointers are physical addresses of the next buffer in the ring. The pointers need to be physical addresses because a DMA ring is created to be used by the device and a device on the PCI bus does not have access to the CPU's MMU to translate virtual addresses into physical addresses.
The 82559ER uses DMA rings to allow the driver to specify multiple packet buffers for the 82559ER to use. For example, a receive DMA ring allows the RU access to multiple receive packet buffers. The 82559ER has limited internal memory and can only buffer a few packets in its local memory. During periods of bursty traffic if the CPU cannot service the E100 interrupts promptly, a device without a DMA ring would be forced to drop packets. The 82559ER, on the other hand, can move incoming packets out of its limited local memory and into the DMA ring in the much larger main memory. The 82559ER uses DMA processors to move incoming packets onto the receive DMA ring without waiting for the driver's approval. If the CPU is too busy to handle the E100 interrupts, the received packets will be waiting in the DMA ring when the CPU has time to run the driver.
On the transmit side, the driver can place multiple packets into the transmit DMA ring and instruct the CU to send them all one after the other without interrupting the CPU (thereby reducing the overhead of sending packets by limiting interrupt overhead). Just like the RU, the CU also has very limited local memory and it would not be possible to give the CU more than two or three packets. The main memory transmit DMA ring gives the CU access to as many packet buffers as the designer of the driver wants.
The DMA rings also offer the driver a convenient way of moving data to and from the device. Instead of using inb/outb operations to move blocks of data manually to and from the device (and wasting CPU cycles to do so), the CU and RU use DMA processors built into the 82559ER to read and write packets in the main memory DMA rings. The 82559ER accesses main memory concurrently with the CPU. While you are reading the documentation you should think about what mechanisms the 82559ER design provides to help your driver avoid races while using the DMA rings.
The internal organization of a driver can take on many forms and depends on many factors. The NIC's Software Interface, performance requirements, ease of programing, etc. all play a role in dictating the organization of the driver. We will present one possible driver layout concentrating on simplicity and ease of understanding.
Packets sent to the E100 driver by user-level environments need to be stored until they can be transmitted. Packets received by the E100 also need to be stored in the kernel until a user environment is ready to pull them out. This means that the E100 driver needs two queues to store incoming and outgoing packets.
We can use the two E100 DMA rings as queues for each respective packet type. Packets to be transmitted can be copied into the next available slot in the transmit DMA ring where they can reside until the CU transmits them. Received packets are already placed onto the receive DMA ring and can remain there until the user calls into the kernel to pull them out. This device driver requires only two system calls: send packet and receive packet.
A system call to send a packet can be simply implemented by copying the user provided data into the DMA ring and notifying the E100 that there is a packet ready to be transmitted. Similarly, a receive packet system call can be implemented by copying a packet out of the receive DMA ring and into a buffer that can be given to the user environment. Since there is no mechanism to alert the user-level environment that packets are available in the receive DMA ring, the user environment must periodically call the receive packet system call to empty the receive DMA to make room for new packets. This design is a form of polling.
There are a few corner cases left to think about. First, the easy ones. What if there are no more empty slots in the transmit DMA ring when the user calls the packet send system call? This problem would arise if the user application is sending more data than the E100 can transmit. We can pause the environment to allow the card to catch up, but we won't. The reason is that pausing the user environment would mean blocking the network server, causing subtle deadlock situations (that we would rather not deal with) among the helper environments, user environments, and the core network server. Instead we will simply drop the packet. Next, what if the receive DMA ring is full and the E100 receives a packet? The E100 will buffer a couple of packets in its local memory and will start dropping incoming packets beyond that. The problem is either that the user-level environment is not polling frequently enough or else that the E100 is receiving more data than the CPU can process. You needn't worry too much about this situation, as most applications are built to tolerate lost packets.
Finally, there is a harder corner case (harder in the sense that we must handle it): what if the user calls the receive system call and there are no packets in the receive DMA ring? There are two possible solutions. We can build a convention into the receive packet system call to return a "try again" error asking the user environment to re-execute the system call at a later time. This would put a burden on the calling environment to calculate what is meant by a "later time." A second approach is to suspend the calling environment until there are packets in the receive queue to process. This tactic is very similar to the IPC receive system call. Just like in the IPC case, since we have only one kernel stack, as soon as we leave the kernel the state on the stack will be lost. We need to set a flag indicating that an environment has been suspended due to receive queue underflow and record the system call arguments. If this approach is used, the E100 must be instructed to generate receive interrupts and the driver must handle them by checking and resuming the environment blocked waiting for a packet. The mechanism you use to solve this problem is up to you.
Your driver must construct a DMA ring in main memory in order to tell the 82559ER where to find the packets you wish to send. Section 6.4 describes the precise format of the DMA ring.
A control DMA ring is composed of buffers called Command Blocks (CB). A generic CB looks like this:
+--------------+--------------+ | CONTROL | STATUS | +--------------+--------------+ | LINK | +--------------+--------------+ | COMMAND SPECIFIC DATA | +--------------+--------------+
The control bits indicate what type of command the driver is sending to the 82559ER. After the 82559ER processes the command, it modifies the status bits to indicate that the command is complete and whether it succeeded. The 32-bit link word points to the next CB in the control DMA ring; link is a physical pointer. The data following the link word is variable in size and depends on the CB's control bits. The DMA ring of CBs is called a Command Block List (CBL) in Intel speak.
To illustrate how a CBL can be structured we look at how a series of Transmit Command Blocks (TCB) can fill a command DMA ring of size 3. TCBs are CBs that hold packets that the driver wants the E100 to transmit. Individual TCBs look like this:
+--------------+--------------+ | CONTROL | STATUS | +--------------+--------------+ | LINK | +--------------+--------------+ | TBD ARRAY ADDR | +--------------+--------------+ |TBD COUNT|THRS|TCB BYTE COUNT| +--------------+--------------+ | DATA | +--------------+--------------+
The TCB specific data follows the generic CB header. These fields are covered in detail in Section 6.4.2.5. The TBD ARRAY ADDR is a physical pointer to an array. This pointer is used only in extended transmit mode. Only the simple mode will be described here; if you want to learn more about the extended mode, consult the developer manual. In simple mode, the TBD ARRAY ADDR is set to 0xFFFFFFFF (defined as null pointer for the 82559ER). TCB BYTE COUNT is the size in bytes of the data following the TCB (denoted as DATA in the above diagram). THRS, the transmit threshold, should be set to 0xE0. TBD count is the number of entries in the TBD array and should be set to 0.
Below is a ring of three CBs with TCBs filling in individual CBs.
+---------------------------------------------------------------------------------------------------------------+ | | +->+--------------+--------------+ +--->+--------------+--------------+ +--->+--------------+--------------+ | | CONTROL | STATUS | | | CONTROL | STATUS | | | CONTROL | STATUS | | +--------------+--------------+ | +--------------+--------------+ | +--------------+--------------+ | | LINK -------|--+ | LINK -------|--+ | LINK -------|--+ +--------------+--------------+ +--------------+--------------+ +--------------+--------------+ | 0xFFFFFFFF | | 0xFFFFFFFF | | 0xFFFFFFFF | +--------------+--------------+ +--------------+--------------+ +--------------+--------------+ | 0 |THRS| SIZE | | 0 |THRS| SIZE | | 0 |THRS| SIZE | / +--------------+--------------+ +--------------+--------------+ +--------------+--------------+ S | | | | | | I | PACKET | | PACKET | | PACKET | Z | DATA | | DATA | | DATA | E | | | | | | \ +--------------+--------------+ +--------------+--------------+ +--------------+--------------+
Here we can see that each CB's link pointer points to the next CB in the ring. These pointers are physical. The bytes that constitute the packet follow the TCB contiguously in memory. TCB BYTE COUNT is set to SIZE the size of each packet.
We recommend that you initialize the CBL to be constant in size and pre-allocate each CB in the CBL. The main reason for this is E100 address caching (read the developer manual to find out more). If you pre-allocate all your CBs, then you must size each CB so that there is enough room to fit the largest CB type. The largest CB type will be a TCB with a data section sized to the largest Ethernet packet: 1518 bytes. Union types may prove useful if you have more than one CB type. The links in the generic CB header should all be filled in prior to starting the CU (again, because of E100 address caching).
The DMA ring works as follows: After creating a DMA ring, the device driver tells the CU where to find the ring by sending the CU the physical address of the first buffer in the ring. Each buffer in this ring starts with a CB header. The CU examines the CB by accessing the buffer in main memory directly. If the CB does not contain any commands, the CU goes into suspend mode waiting to be reactivated. The CU caches the physical address of the CB it stopped at in a local register. When restarted, the CU will use this cached physical address to access the DMA ring. It is therefore critical that the links in the DMA ring are rarely (if at all) changed.
When the driver wants to transmit a packet, it places the packet into the next available buffer in the ring and restarts the 82559ER's CU. The CU examines the CB it had previously stopped at (the physical address cached in its local register). If the CB is valid and the command is to transmit a packet, the CU reads the packet from main memory into an internal buffer. Once the packet is in the card's buffer, it can transmit it over the wire. When the packet is sent, the CU can set the CB status bits to indicate success and mark the buffer in the ring as empty. The CU then follows the link pointer to the next buffer in the ring and repeats the above process until it encounters a buffer with the suspend bit set in the control entry of the CB.
You'll find it convenient to use C structs to describe the
E100's CBs. However, while C lays out struct fields in memory in
order, it also inserts padding between the fields to ensure that each
element is aligned to an address that is some multiple of its own
size. The E100's CBs are generally aligned so this is not a problem,
but if you do encounter alignment problems, look into GCC's "packed"
attribute.
Here is how a CB header can be represented as a C structure:
struct cb {
uint16_t status;
uint16_t cmd;
uint32_t link;
}
How does this correspond to the 82559ER documentation, which says that
STATUS is in bits 15:0 and the command is in bits 31:16? The 82559ER
is little-endian, which means the low-order bytes of a
32-bit word come first in memory. That is, bits 15:0 come first in
memory, so putting status first in the struct works out.
Fortunately, the x86 is also little-endian, so numbers stored in these
fields will be read back by the 82559ER in the appropriate byte order.
The compiler may optimize repeated reads of a variable into a single load into a register. For example:
struct cb *cb = SOME_ADDRESS;
while ((cb->status & READY) == 0) {
// wait
}
The programmer
expects the READY bit of the status element to change once the
E100 is done with the CB. The compiler, however, may copy cb->status
into a register and look only at the register in the while loop.
This problem can be overcome using the volatile
keyword. volatile tells the compiler to
always load a variable or field's contents from main memory. Changing
the struct cb as follows will prevent this bug:
struct cb {
volatile uint16_t status;
uint16_t cmd;
uint32_t link;
}
Exercise 5. Construct a control DMA ring for the CU to use. You do not need to worry about configuring the device because the default settings are fine. You also do not need to worry about setting up the device MAC address because the emulated E100 has one already configured.
Now that you can control the CU, you need to create a system call to transmit packets.
Exercise 6. Create a system call for transmitting packets. The interface is up to you. As described in the Device Driver Organization section, the send system call should add the packet to the transmit DMA ring and restart the CU if it is idle or suspended. To free up space on the transmit DMA ring, you should take this opportunity to reclaim any buffers which have been marked as transmitted by the E100.
Now would be a good time to test your packet transmit code. Try transmitting a few packets (probably more than the number of slots in your control DMA ring), either directly from the kernel or using your new syscall from userspace. Use the -pcap argument (see above) to capture the packets and make sure they contain the data you expect them to.
Now that you have a system call interface to the transmit side of your device
driver, it's time to send packets. The output helper environment's goal is to
accept NSREQ_OUTPUT IPC messages from the core network server and
send the packets accompanying these IPC message to the network device driver
using the system call you added above. The NSREQ_OUTPUT
IPC's are sent by the low_level_output function in
net/lwip/jos/jif/jif.c, which glues the lwIP stack to JOS's
network system. Each IPC will include a page consisting of a
struct jif_pkt.
Be aware of the interaction between the device driver, the output environment, and the core network server when there is no more space in the device driver's transmit queue. The core network server sends packets to the output environment using IPC. If the output environment is suspended due to a send packet system call because the driver has no more buffer space for new packets, the core network server will block waiting for the output server to accept the IPC call.
Exercise 7. Implement net/output.c.
If all the above code works, you should be able to see the network server send an ARP request. Use the -pcap QEMU option to dump the packets to a capture file and analyze the file to find the ARP request. Passing the -debug-e100 flag to qemu, you should see the E100 emulator spit out log messages similar to the ones below (you may not get exactly the same message, but make sure they make sense):
EE100 eepro100_cu_command val=0x20 (cu start), status=0x8000, command=0x4004, link=0x040b9000 EE100 eepro100_cu_command transmit, TBD array address 0xffffffff, TCB byte count 0x00e0, TBD count 0 EE100 eepro100_cu_command TBD (simplified mode): buffer address 0x040ba010, size 0x00e0
Question
A second DMA ring is used to receive packets from the 82559ER. Each buffer in the receive DMA ring is called a Receive Frame Descriptor (RFD). The entire receive DMA ring is called a Receive Frame Area (RFA). The RFD is similar in structure to the TCB. The RFD is composed of a header followed by a contiguous region of memory that can hold an entire maximum length packet (1518 bytes when dealing with Ethernet). Consult the developer manual for details.
Upon capturing a packets in its local cache, the 82559ER DMAs the data out into one of these buffers and marks the buffer as valid. It then raises an interrupt to tell the driver that there is a new packet in the receive DMA ring. This means that, depending on your device driver structure, you may need to write code to handle these interrupts.
If you do use interrupts, note that, once an interrupt is asserted, it
will remain asserted
until the driver clears the interrupt. In your interrupt handler make sure to
clear the interrupt handled as soon as you handle it. If you don't, after
returning from your interrupt handler, the CPU will jump back into it again.
In addition to clearing the interrupts on the E100 card, interrupts also need to
be cleared on the PIC. Use irq_eoi declared in
kern/picirq.h to do so.
Exercise 8. Construct a receive DMA ring and start the RU. If you use interrupts, make sure that 82559ER generated interrupts are routed to your driver and are handled.
Just like the transmit side, you will also need to write a system call to let user environments receive packets.
Exercise 9. Create a system call for receiving packets. As described in the Device Driver Organization section, the system call will pull a packet off the receive DMA ring, mark the DMA buffer as empty (so that the E100 can reuse it) and pass the packet to the calling user environment.
The Device Driver Organization section described a device driver that relied on
polling to clear the receive DMA ring. In the network server input environment
you will need to poll the device driver, using your receive system call, for
received packets. You will also need to pass each packet to the core network
server environment using the NSREQ_INPUT IPC message.
Exercise 10. Implement net/input.c.
To test your networking code, we have provided a daemon called echosrv that sets up an echo server running on port 7 that will echo back anything sent over a TCP connection. Use echosrv and make nc-7 to test your complete driver. Every time the emulated E100 receives a packet, qemu with the -debug-e100 flag should print something like the following message to the console:
EE100 nic_receive 0xab13498 received frame for me, len=42 EE100 nic_receive command 0x0000, link 0x040ba000, addr 0xffffffff, size 1518
At this point, you should be able to score 85/100 on make grade.
Question
Challenge! Read about the EEPROM in the developers manual and write the code to load the E100's MAC address out of the EEPROM. Write a system call to pass the MAC address to lwIP and modify lwIP to use this new MAC address.
Challenge! Find out what a zero copy driver means and modify your E100 driver and system call interface to be zero copy.
The receive side flexible mode is not documented in the Developer Manual. Here is a brief overview of how it works. Looking at Figure 25 in the Developer Manual, the reserved DWORD at offset 08h should point to a Receive Buffer Descriptor (RBD).
+--------------+--------------+ | RESERVED |EOF|F| COUNT | +--------------+--------------+ | LINK | +--------------+--------------+ | BUFFER LINK | +--------------+--------------+ | RESERVED | SIZE | +--------------+--------------+ |
|
Note that the receive side flexible mode is different from the transmit side flexible mode. The transmit side uses an array of TBDs while the receive side relies on a linked list of RBDs. If you look at Figure 8 in the Developer Manual you will see exactly how to setup a RFA using flexible mode.
In fact, you are creating two DMA rings in flexible mode. One DMA ring is composed of the RFDs and a second one is composed of RBDs. The card actually stores two independent pointers, one into the RFD ring and one into the RBD ring. The logic behind this is that RFDs can be sized small so that an average packet fills the buffer described by one RFD but a large packet still can be received by spanning multiple RBDs. This means for one RFD the card may use multiple RBDs. Your driver must track which RFDs and which RBDs are used up.
The easiest way to use this mode is to create a one to one mapping between RFDs and RBDs. This is done by sizing the buffer described by the RBD to hold a maximum packet. This way the card cannot use up multiple RBDs for each received packet. To create the RFA you can link the RBDs in one ring and the RBDs in another ring. Then you can add a link from each RFD to its own RBD (the linking must be ordered so that if you were to place the RFD ring on top of the RBD ring, none of the links from RFD to RBD will cross each other; think of a cylinder). A picture explains this better:
+----------------------+
| |
| +---+ +---+ +---+ |
+->|RFD|->|RFD|->|RFD|-+
+---+ +---+ +---+
| | |
v v v
+---+ +---+ +---+
+->|RBD|->|RBD|->|RBD|-+
| +---+ +---+ +---+ |
| | | | |
| v v v |
| +---+ +---+ +---+ |
| |BUF| |BUF| |BUF| |
| +---+ +---+ +---+ |
| |
+----------------------+
Both the RBD COUNT and RFD ACTUAL COUNT are filled in by the device. The RFD ACTUAL COUNT is the total size of the packet. The RBD COUNT is the portion of the packet in that particular RBD. In the one-to-one RFA, RBD COUNT and RBD ACTUAL COUNT will be the same.
Challenge! Take the zero copy concept all the way into lwIP.
The extended TCB format shines when it is used to collect pieces of a packet scattered throughout memory. The E100's extended TCB can accept many different pointers to small buffers and as the E100 is sending the packet it will fill its internal cache sequentially reading in each data buffer at a time. The net result is that individual packet pieces never need to be joined together in one contiguous memory region.
A typical packet is composed of many headers. The user sends data to be transmitted to lwIP in one buffer. The TCP layer wants to add a TCP header, the IP layer an IP header and the MAC layer an Ethernet header. Even though there are many parts to a packet, right now the parts need to be joined together so that the device driver can send the final packet.
There are many approaches to resolving the multiple header problem so as to avoid buffer reallocations and needless data copies. A large buffer can be preallocated to have room for all possible headers. The buffer is filled from the end so that as the buffer flows through the different network layers, there will always be room at the head of the buffer for headers. This might be a problem because TCP and IP headers can be variable in size and having large buffers can waste memory.
Another approach is to give to the driver the many different packet pieces and have the driver take care of joining them together. The E100 driver can use the TCB extended mode to do exactly this. Change the driver to accept packet composed of many buffers and use the TCB extended format to transmit the packet without copying the data. You will need to figure out how to get lwIP to stop merging the packet pieces as it does right now.
Challenge! Augment your system call interface to service more than one user environment. This will prove useful if there are multiple network stacks (and multiple network servers) each with their own IP address running in user mode. The receive system call will need to decide to which environment it needs to forward each incoming packet.
Note that the current interface cannot tell the difference between two packets and if multiple environments call the packet receive system call, each respective environment will get a subset of the incoming packets and that subset may include packets that are not destined to the calling environment.
Sections 2.2 and 3 in this Exokernel paper have an in-depth explanation of the problem and a method of addressing it in a kernel like JOS. Use the paper to help you get a grip on the problem, chances are you do not need a solution as complex as presented in the paper.
CB Command Block CBL Command Block List CSR Control/Status Registers CU Command Unit RFA Receive Frame Area RFD Receive Frame Descriptor RU Receive Unit SCB System Control Block TCB Transmit Command Block
A web server in its simplest form sends the contents of a file to the requesting client. We have provided skeleton code for a very simple web server in user/httpd.c. The skeleton code deals with incoming connections and parses the headers.
Exercise 11.
The web server is missing the code that deals with sending the
contents of a file back to the client. Finish the web server by
implementing send_file and send_data.
Once you've finished the web server, you should test it. Set up JOS to run user/httpd. Then, from another machine, point your favorite browser at http://host:port/index.html, where host is the name of the computer running QEMU and port is the port number reported for the web server by make which-ports. (The line you care about is the line that says which port is forwarding to port 80. Recall that JOS thinks it's running the Web server on port 80, and meanwhile QEMU is forwarding some other port on the real machine to JOS's port 80. QEMU does this the way that all NATs do: by rewriting the destination port field in packets.) You should see a web page served by the HTTP server running inside JOS.
Challenge! Add a simple chat server to JOS, where multiple people can connect to the server and anything that any user types is transmitted to the other users. To do this, you will have to find a way to communicate with multiple sockets at once and to send and receive on the same socket at the same time. There are multiple ways to go about this. lwIP provides a MSG_DONTWAIT flag for recv (see lwip_recvfrom in net/lwip/api/sockets.c), so you could constantly loop through all open sockets, polling them for data. This is obviously wasteful. A more efficient approach is to start separate environments for each connection and to use IPC to coordinate them. Conveniently, lwIP socket numbers are global (not per-environment), so, for example, an environment can send on another environment's socket simply by knowing its fd number.
Question
This completes the lab. Turn it in using make turnin.