New York
University
Computer
Science Department
Courant
Institute of Mathematical Sciences
Session 5:
Programming Java Threads, Part 1
Course Title: Extreme Java Course Number: g22.3033-007
Instructor: Jean-Claude Franchitti Session: 5
Introduction
Programming Java
threads isn't nearly as easy (or as platform-independent) as most books would
have you believe. Java programs other than simple console-based applications
are multithreaded, whether you like it or not. The problem is that the Abstract
Windowing Toolkit (AWT) processes operating system (OS) events on its own
thread, so your listener methods actually run on the AWT thread. These same
listener methods typically access objects that are also accessed from the main
thread. It may be tempting, at this point, to bury your head in the sand and
pretend you don't have to worry about threading issues, but you can't usually
get away with it. And, unfortunately, virtually none of the books on Java
addresses threading issues in sufficient depth. (For a list of helpful books on
the topic, see "References")
This handout discusses the things you need to know
to program threads. It assumes you understand the language-level support for
threads (the synchronized keyword, how monitors work,
the wait() and notify() methods, and so on) and
focuses on the legion of problems that arise when you try to use these language
features.
Platform dependence
Unfortunately, Java's
promise of platform independence falls flat on its face in the threads arena.
Though it's possible to write a platform-independent multithreaded Java
program, you have to do it with your eyes open. This isn't really Java's fault;
it's almost impossible to write a truly platform-independent threading system.
(Doug Schmidt's ACE [Adaptive Communication Environment] framework is a good,
though complex, attempt. See "References" for a link to his program.)
So, before we can talk about hard-core Java-programming, we have to discuss the
difficulties introduced by the platforms on which the Java virtual machine
(JVM) might run.
Atomic energy
The first OS-level concept that's important to
understand is atomicity. An atomic operation cannot be interrupted by
another thread. Java does define at least a few atomic operations. In
particular, assignment to variables of any type except long or double is atomic. You don't have
to worry about a thread preempting a method in the middle of the assignment. In
practice, this means that you never have to synchronize a method that does
nothing but return the value of (or assign a value to) a boolean or int instance variable.
Similarly, a method that did a lot of computation using only local variables
and arguments, and which assigned the results of that computation to an
instance variable as the last thing it did, would not have to be synchronized.
For example:
class
some_class
{
int some_field;
void f( some_class arg ) // deliberately not synchronized
{
// Do lots of stuff here that uses local variables
// and method arguments, but does not access
// any fields of the class (or call any methods
// that access any fields of the class).
// ...
some_field = new_value; // do this last.
}
}
On the other hand, when executing x=++y or x+=y, you could be preempted
after the increment but before the assignment. To get atomicity in this
situation, you'll need to use the keyword synchronized.
All this is important because the overhead of
synchronization can be nontrivial, and can vary from OS to OS. The following
program demonstrates the problem. Each loop repetitively calls a method that
performs the same operations, but one of the methods (locking()) is synchronized and the
other (not_locking()) isn't. As part of an older
experiment using the JDK "performance-pack" VM running under Windows
NT, the program reported a 1.2-second difference in runtime between the two
loops, or about 1.2 microseconds per call. This difference may not seem like
much, but it represent a 7.25-percent increase in calling time. Of course, the
percentage increase falls off as the method does more work, but a significant
number of methods -- in my programs, at least -- are only a few lines of code.
import
java.util.*;
class synch
{
synchronized
int locking (int a, int b){return a + b;}
int not_locking (int a, int b){return a + b;}
private static final int ITERATIONS = 1000000;
static public void main(String[] args)
{
synch tester = new synch();
double start = new Date().getTime();
for(long i =
ITERATIONS; --i >= 0 ;)
tester.locking(0,0);
double
end = new Date().getTime();
double locking_time = end - start;
start = new Date().getTime();
for(long i =
ITERATIONS; --i >= 0 ;)
tester.not_locking(0,0);
end =
new Date().getTime();
double not_locking_time = end - start;
double time_in_synchronization = locking_time - not_locking_time;
System.out.println( "Time lost to synchronization (millis.): "
+ time_in_synchronization );
System.out.println( "Locking overhead per call: "
+ (time_in_synchronization / ITERATIONS) );
System.out.println(
not_locking_time/locking_time * 100.0 + "% increase" );
}
}
Though the HotSpot VM is supposed to address the
synchronization-overhead problem, HotSpot isn't a freebee -- you have to buy
it. Unless you license and ship HotSpot with your app, there's no telling what
VM will be on the target platform, and of course you want as little as possible
of the execution speed of your program to be dependent on the VM that's
executing it. Even if deadlock problems didn't exist, the notion that you
should "synchronize everything" is just plain wrong-headed.
Concurrency versus parallelism
The next OS-related
issue (and the main problem when it comes to writing platform-independent Java)
has to do with the notions of concurrency and parallelism.
Concurrent multithreading systems give the appearance of several tasks
executing at once, but these tasks are actually split up into chunks that share
the processor with chunks from other tasks. The following figure illustrates
the issues. In parallel systems, two tasks are actually performed
simultaneously. Parallelism requires a multiple-CPU system.
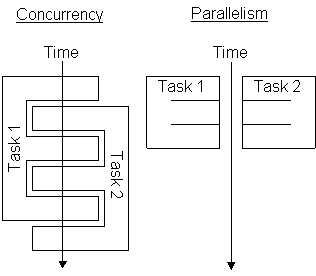
Unless you're spending a lot of time blocked,
waiting for I/O operations to complete, a program that uses multiple concurrent
threads will often run slower than an equivalent single-threaded program,
although it will often be better organized than the equivalent single-thread
version. A program that uses multiple threads running in parallel on multiple
processors will run much faster.
Though Java permits threading to be implemented
entirely in the VM, at least in theory, this approach would preclude any
parallelism in your application. If no operating-system-level threads were
used, the OS would look at the VM instance as a single-threaded application,
which would most likely be scheduled to a single processor. The net result
would be that no two Java threads running under the same VM instance would ever
run in parallel, even if you had multiple CPUs and your VM was the only active
process. Two instances of the VM running separate applications could run in
parallel, of course, but I want to do better than that. To get parallelism, the
VM must map Java threads through to OS threads; so, you can't afford
to ignore the differences between the various threading models if platform
independence is important.
Get your priorities straight
We will demonstrate the ways the issues just
discussed can impact your programs by comparing two operating systems: Solaris
and Windows NT/2000.
Java, in theory at least, provides ten priority
levels for threads. (If two or more threads are both waiting to run, the one
with the highest priority level will execute.) In Solaris, which supports 231
priority levels, this is no problem (though Solaris priorities can be tricky to
use -- more on this in a moment). NT, on the other hand, has seven priority
levels available, and these have to be mapped into Java's ten. This mapping is
undefined, so lots of possibilities present themselves. (For example, Java
priority levels 1 and 2 might both map to NT priority level 1, and Java
priority levels 8, 9, and 10 might all map to NT level 7.)
NT's paucity of priority levels is a problem if you
want to use priority to control scheduling. Things are made even more
complicated by the fact that priority levels aren't fixed. NT provides a
mechanism called priority boosting, which you can turn off with a C
system call, but not from Java. When priority boosting is enabled, NT boosts a
thread's priority by an indeterminate amount for an indeterminate amount of
time every time it executes certain I/O-related system calls. In practice, this
means that a thread's priority level could be higher than you think because
that thread happened to perform an I/O operation at an awkward time.
The point of the priority boosting is to prevent
threads that are doing background processing from impacting the apparent
responsiveness of UI-heavy tasks. Other operating systems have
more-sophisticated algorithms that typically lower the priority of background
processes. The downside of this scheme, particularly when implemented on a
per-thread rather than a per-process level, is that it's very difficult to use
priority to determine when a particular thread will run.
It gets worse.
In Solaris, as is the case in all Unix systems,
processes have priority as well as threads. The threads of high-priority processes
can't be interrupted by the threads of low-priority processes. Moreover, the
priority level of a given process can be limited by a system administrator so
that a user process won't interrupt critical OS processes. NT supports none of
this. An NT process is just an address space. It has no priority per se, and is
not scheduled. The system schedules threads; then, if a given thread is running
under a process that isn't in memory, the process is swapped in. NT thread
priorities fall into various "priority classes," that are distributed
across a continuum of actual priorities. The system looks like this:
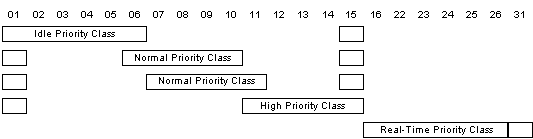
Windows NT's priority
architecture
The columns are actual priority levels, only 22 of
which must be shared by all applications. (The others are used by NT itself.)
The rows are priority classes. The threads running in a process pegged at the
idle priority class are running at levels 1 through 6 and 15, depending on
their assigned logical priority level. The threads of a process pegged as
normal priority class will run at levels 1, 6 through 10, or 15 if the process
doesn't have the input focus. If it does have the input focus, the threads run
at levels 1, 7 through 11, or 15. This means that a high-priority thread of an
idle priority class process can preempt a low-priority thread of a normal
priority class process, but only if that process is running in the background.
Notice that a process running in the "high" priority class only has
six priority levels available to it. The other classes have seven.
NT provides no way to limit the priority class of a
process. Any thread on any process on the machine can take over control of the
box at any time by boosting its own priority class; there is no defense against
this.
The technical term used to describe NT's priority is
unholy mess. In practice, priority is virtually worthless under NT.
So what's a programmer to do? Between NT's limited
number of priority levels and it's uncontrollable priority boosting, there's no
absolutely safe way for a Java program to use priority levels for scheduling.
One workable compromise is to restrict yourself to Thread.MAX_PRIORITY, Thread.MIN_PRIORITY, and Thread.NORM_PRIORITY when you call setPriority(). This restriction at least
avoids the 10-levels-mapped-to-7-levels problem. Supposedly you could use the os.name system property to detect
NT, and then call a native method to turn off priority boosting, but that won't
work if your app is running under Internet Explorer unless you also use Sun's
VM plug-in. (Microsoft's VM used a nonstandard native-method implementation.)
In any event, to avoid the use of native methods, you can avoid the problem as
much as possible by putting most threads at NORM_PRIORITY and using scheduling
mechanisms other than priority.
Cooperate!
There are typically
two threading models supported by operating systems: cooperative and
preemptive.
The cooperative multithreading model
In a cooperative system, a thread retains
control of its processor until it decides to give it up (which might be never).
The various threads have to cooperate with each other or all but one of the
threads will be "starved" (meaning, never given a chance to run).
Scheduling in most cooperative systems is done strictly by priority level. When
the current thread gives up control, the highest-priority waiting thread gets
control. (An exception to this rule was Windows 3.x, which used a cooperative
model but didn’t have much of a scheduler. The window that has the focus gets
control.)
The main advantage of cooperative multithreading is
that it's very fast and has a very low overhead. For example, a context
swap -- a transfer of control from one thread to another -- can be
performed entirely by a user-mode subroutine library without entering the OS
kernel. (In Windows NT/2000, which is something of a worst-case, entering the
kernel wastes 600 machine cycles. A user-mode context swap in a cooperative
system does little more than a C setjump/longjump call would do.) You can
have thousands of threads in your applications significantly impacting
performance. Since you don't lose control involuntarily in cooperative systems,
you don't have to worry about synchronization either. That is, you never have
to worry about an atomic operation being interrupted. The main disadvantage of the
cooperative model is that it's very difficult to program cooperative systems.
Lengthy operations have to be manually divided into smaller chunks, which often
must interact in complex ways.
The preemptive multithreading model
The alternative to a cooperative model is a preemptive
one, where some sort of timer is used by the operating system itself to cause a
context swap. The interval between timer ticks is called a time slice.
Preemptive systems are less efficient than cooperative ones because the thread
management must be done by the operating-system kernel, but they're easier to
program (with the exception of synchronization issues) and tend to be more
reliable since starvation is less of a problem. The most important advantage to
preemptive systems is parallelism. Since cooperative threads are scheduled by a
user-level subroutine library, not by the OS, the best you can get with a
cooperative model is concurrency. To get parallelism, the OS must do the
scheduling. Of course, four threads running in parallel will run much faster
than the same four threads running concurrently.
Some operating systems (e.g., Windows 3.1) only
support cooperative multithreading. Others, like NT/2000, support only
preemptive threading. (You can simulate cooperative threading in NT with a
user-mode library like the "fiber" library, but fibers aren't fully
integrated into the OS.) Solaris provides the best (or worst) of all worlds by
supporting both cooperative and preemptive models in the same program.
Mapping kernel threads to user processes
The final OS issue has
to do with the way in which kernel-level threads are mapped into user-mode
processes. NT uses a one-to-one model, illustrated in the following picture.
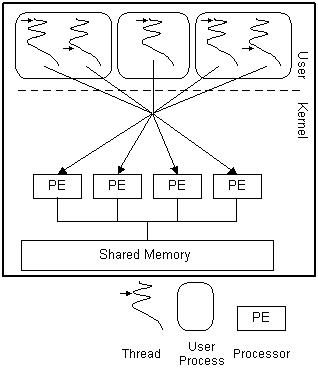
NT user-mode threads effectively are kernel
threads. They are mapped by the OS directly onto a processor and they are
always preemptive. All thread manipulation and synchronization are done via
kernel calls (with a 600-machine-cycle overhead for every call). This is a
straightforward model, but is neither flexible nor efficient.
The Solaris model, pictured below, is more
interesting. Solaris adds to the notion of a thread, the notion of a lightweight
process (LWP). The LWP is a schedulable unit on which one or more threads
can run. Parallel processing is done on the LWP level. Normally, LWPs reside in
a pool, and they are assigned to particular processors as necessary. An LWP can
be "bound" to a specific processor if it's doing something
particularly time critical, however, thereby preventing other LWPs from using
that processor.
Up at the user level, you have a system of
cooperative, or "green," threads. In a simple situation, a process
will have one LWP shared by all the green threads. The threads must yield
control to each other voluntarily, but the single LWP the threads share can be
preempted by an LWP in another process. This way the processes are preemptive
with respect to each other (and can execute in parallel), but the threads
within the process are cooperative (and execute concurrently).
A process isn't limited to a single LWP, however.
The green threads can share a pool of LWPs in a single process. The green
threads can be attached (or "bound") to an LWP in two ways:
1.
The
programmer explicitly "binds" one or more threads to a specific LWP.
In this case, the threads sharing a LWP must cooperate with each other, but
they can preempt (or be preempted by) threads bound to a different LWP. If
every green thread was bound to a single LWP, you'd have an NT-style preemptive
system.
2.
The
threads are bound to green threads by the user-mode scheduler. This is
something of a worst case from a programming point of view because you can't
assume a cooperative or a preemptive environment. You may have to yield to
other threads if there's only one LWP in the pool, but you might also be
preempted.
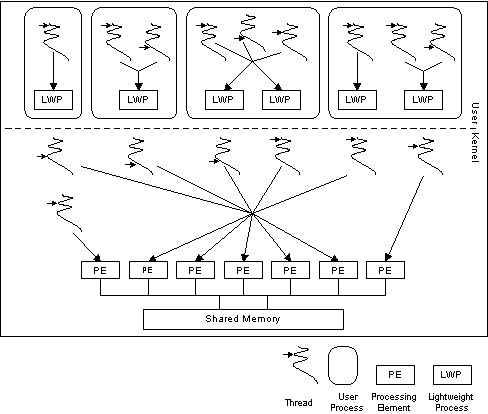
This threading model gives you an enormous amount of
flexibility. You can choose between an extremely fast (but strictly concurrent)
cooperative system, a slower (but parallel) preemptive system, or any
combination of the two.
So why does this matter to a Java programmer? The
main issue is that the choice of threading model is entirely up to the VM --
you have no control. For example, early versions of the Solaris VM were
strictly cooperative. Java threads were all green threads sharing a single LWP.
The current version of the Solaris VM, however, uses several LWPs. Similarly,
the NT/2000 VMs don't have the equivalent of green threads, so they're always
preemptive. In order to write platform-independent code, you must make two
seemingly contradictory assumptions:
1.
You
can be preempted by another thread at any time. You must use the synchronized keyword carefully to assure
that non-atomic operations work correctly.
2.
You
will never be preempted unless you give up control. You must occasionally
perform some operation that will give control to other threads so they can have
a chance to run. Use yield() and sleep() in appropriate places (or
make blocking I/O calls). For example, you might want to consider calling yield() every one hundred
iterations or so of a long loop, or voluntarily going to sleep for a few
milliseconds every so often to give lower-priority threads a chance to run. (yield() will yield control only to
threads running at your priority level or higher).
Green vs. Native Threads are a VM implementation
issue. Green threads are all within the JVM, while the JVM runs on it's own
single thread as far as the host machine is concerned. All scheduling is
handled by the VM. Native threads are mapped into the native thread systems of
the OS the JVM is running on. This means different things with different OS's
but can be generalized as above. Native threads will therefeore allow you to
use the SMP support of the OS (if it's available).
When implementing threads -- no matter how you are
implementing them -- the goal is to have multiple flows of execution going in
the same address space. The question is who performs the switching between the
threads. The answer is either:
1) The kernel controls it,
or
2) It's controlled in user
space.
Native threads use #1 or #2, whatever the OS at hand finds fit to offer, and green threads are an implementation of #2. That's basically all you can say - native threads don't necessarily pre-empt, and it is unwise to make assumptions anyway.
For development, use green threads (cooperative
multithreading tends to expose thread programming errors, like forgetting to
yield(), very quickly). For deployment, see what's best. Native threads may use
SMP capabilities better, and native threads when they're preemptive will
probably be better at controlling CPU-bound threads. For the average Java
app/service, where most work is I/O bound (GUI, network), green threads should
be slightly faster because they are adapted at what Java's needs and its
cooperative thread switching is typically faster (setjmp()/longjmp() call) than
preemptive switching (which will probably invoke a syscall).
Whatever the JVM, you *have* to assume that on the Java level, you'll need to explicitely implement threads to deal with a cooperative scheduling setup. You can assume that in a loop, any I/O call will yield (so you don't need to implement a server accept() loop, for example), but otherwise think about what your code is doing and try to make it sleep() or yield() as often as is reasonable.
You can specify the use of “green threads” instead of “native threads” with the command that runs the JVM:
java -green
...
or
set it in the environment:
export
THREADS_FLAG=green
java ...
Wrapping it up
So, those are the main OS-level issues you must
consider when you're writing a Java program. Since you can make no assumptions
about your operating environment, you have to program for the worst case. For
example, you have to assume you can be preempted at any time, so you must use synchronized appropriately, but you must
also assume that you will never be preempted, so you must also use yield(), sleep(), or occasionally blocking
I/O calls to permit other threads to run. You can't assume priority levels 1
and 2 are different. They might not be after NT has mapped Java's 10 levels
into its 7 levels. You can't assume that a priority level 2 thread will always
be higher priority than one that runs at level 1.
Here is a suggested roadmap for thread-related
programming problems and solutions:
1.
Deadlock,
starvation, and nested-monitor lockout
2.
Roll-your-own
mutexes and a deadlock-handling lock manager
3.
Counting
semaphores, condition variables, and singletons
4.
Event
notification in a multithreaded environment (the mysteries of the AWTEventMulticaster)
5.
Reader/writer
locks
6.
Timers
7.
Synchronous-dispatching:
multithreading without threads
8.
Implementing
the active-object pattern
References
·
For
a great in-depth look at multithreading in general and the implementation of
multithreading both in and with Java in particular, this one's a must. It's
required reading if you're using threads heavily: Doug Lea, Concurrent
Programming in Java: Design Principles and Patterns (Addison Wesley, 1997):
http://java.sun.com/docs/books/cp/
·
For
an intro-level book on Java threading that is less technical but more readable
than Lea's effort, see: Scott Oaks and Henry Wong, Java Threads
(O'Reilly, 1997):
http://www.oreilly.com/catalog/jthreads/
·
This
book is good for those looking into the general subject of multithreading, but
doesn't have a Java slant: Bill Lewis and Daniel J. Berg, Threads Primer: A
Guide to Multithreaded Programming (Prentice Hall/SunSoft Press, ISBN
0-13-443698-9).
·
Doug
Schmidt's ACE framework is a good, though complex, attempt at a truly
platform-independent threading system:
http://www.cs.wustl.edu/~schmidt/
·
More
on green/native threads:
http://www.cs.csbsju.edu/~jgramke/sgijavadocs/native_threads.html
http://www.javaworld.com/javaworld/javaqa/1999-07/04-qa-jvmthreads.html