V22.0436: Computer Architecture
2011-12 Fall
Allan Gottlieb
Tuesdays and Thursdays 3:30-4:45
Room 202 Ciww
Start Lecture #1
Chapter 0: Administrivia
I start at Chapter 0 so that when we get to chapter 1, the
numbering will agree with the text.
0.1: Contact Information
- <my-last-name> AT nyu DOT edu (best method)
- http://cs.nyu.edu/~gottlieb
- 715 Broadway, Room 712
- 212 998 3344
0.2: Course Web Page
There is a web site for the course.
You can find it from my home page listed above.
- You can also find these lecture notes on the course home page.
Please let me know if you can't find it.
- The notes are updated as bugs are found or improvements made.
- I will also produce a separate page for each lecture after the
lecture is given.
These individual pages might not get updated as quickly or
reliably as the large page.
0.3: Textbook
The course text is Hennessy and Patterson,
Computer Organization and Design: The Hardware/Software Interface,
4th edition, which I will refer to as 4e.
- Available in the bookstore.
- The main body of the book assumes you have had a full course
in logic design.
- I do NOT make that strong an assumption.
I just assume you had 201.
- We will start with appendix C, which is a logic design review.
However since 201 is a prerequisite, we will go rather quickly
over that part.
- Most of the figures in these notes are based on figures from
the course textbook.
Although I have personally redrawn all the figures (except for a
two pictures on carry lookahead adders), the following copyright
notice (from Morgan Kaufman / Elsevier) probably applies.
All figures from Computer Organization and Design: The
Hardware/Software Approach, Fourth Edition, by David Patterson
and John Hennessy, are copyrighted material (copyright 2009 by
Elsevier inc inc. all rights reserved).
Figures may be reproduced only for classroom or personal
educational use in conjunction with the book and only when the
above copyright line is included. They may not be otherwise
reproduced, distributed, or incorporated into other works
without the prior written consent of the publisher.
0.4: Computer Accounts and Mailman Mailing List
- You are entitled to a computer account, please get yours asap if
you don't already have one.
- Sign up for the course mailman mailing list
here.
- If you want to send mail just to me, use the address given
above, not not the mailing list.
- Questions on the labs should go to the mailing list.
You may answer questions posed on the list as well.
Note that replies are sent to the list.
- I will respond to all questions; if another student has answered the
question before I get to it, I will confirm if the answer given is
correct.
- Please use proper mailing list etiquette.
- Send plain text messages rather than (or at least in
addition to) html.
- Use the Reply command to contribute to the current thread,
but NOT to start another topic.
- If quoting a previous message, trim off irrelevant parts.
- Use a descriptive Subject: field when starting a new topic.
- Do not use one message to ask two unrelated questions.
- Do NOT make the mistake of sending your completed lab
assignment to the mailing list.
This is not a joke; several students have made this mistake in
past semesters.
0.5: Grades
Your grade will be a function of your midterm, final exam,
and laboratory
assignments (see below).
I am not yet sure of the exact weightings, but it will be
approximately 30% midterm, 30% labs, 40% final exam.
0.6: The Upper Left Board
I use the upper left board for lab/homework assignments and
announcements.
I should never erase that board.
If you see me start to erase an announcement, please let me know.
I try very hard to remember to write all announcements on the upper
left board and I am normally successful.
If, during class, you see that I have forgotten to record something,
please let me know.
HOWEVER, if I forgot and no one reminds me, the
assignment has still been given.
0.7: Homeworks and Labs
I make a distinction between homeworks and labs.
Labs are
- Required.
- Due several lectures later (date given on assignment).
- Graded and form part of your final grade.
- Penalized for lateness.
(added for 2009-10 spring:
The penalty is 1 point per day up to 30 days; then 2 points per day).
- Most often are computer programs you must write.
Homeworks are
- Optional.
- Due the beginning of the Next lecture.
- Not accepted late.
- Mostly from the book.
- Collected and returned.
- Able to help, but not hurt, your grade.
0.7.1: Homework Numbering
Homeworks are numbered by the class in which they are assigned.
So any homework given today is homework #1.
Even if I do not give homework today, the homework assigned next
class will be homework #2.
Unless I explicitly state otherwise, all homeworks assignments can
be found in the class notes.
So the homework present in the notes for lecture #n is homework #n
(even if I inadvertently forgot to write it to the upper left
board).
0.7.2: Doing Labs on non-NYU Systems
You may solve lab assignments on any system you wish, but ...
- You are responsible for any non-nyu machine.
I extend deadlines if the nyu machines are down, not if yours
are.
- Be sure test your assignments to the nyu
systems.
In an ideal world, a program written in a high level language
like Java, C, or C++ that works on your system would also work
on the NYU system used by the grader.
Sadly this ideal is not always achieved despite marketing
claims to the contrary.
So, although you may develop you lab on any system,
you must ensure that it runs on the nyu system assigned to the
course.
- If somehow your assignment is misplaced by me and/or a grader,
we need a to have a copy ON AN NYU SYSTEM
that can be used to verify the date the lab was completed.
- When you complete a lab and have it on an nyu system, email the
lab to the grader and copy yourself on that message.
Please use one of the following two methods of mailing the lab.
- Send the mail from your CIMS account.
(Not all students have a CIMS acct[)
- Use the
request receipt
feature from home.nyu.edu
or mail.nyu.edu and select the when delivered
option.
- Keep the copy until you have received your grade on the
assignment.
I realize that I am being paranoid about this.
It is rare for labs to get misplaced, but they sometimes do and I
really don't want to be in the middle of an
I sent it ... I never received it
debate.
Thank you.
0.7.3: Obtaining Help with the Labs
Good methods for obtaining help include
- Asking me during office hours (see web page for my hours).
- Asking the mailing list.
- Asking another student, but ...
Your lab must be your own.
That is, each student must submit a unique lab.
Naturally, simply changing comments, variable names, etc. does
not produce a unique lab.
0.7.4: Computer Language Used for Labs
You may write your lab in Java, C, or C++.
Other languages may be possible, but please ask in advance.
I need to ensure that the TA is comfortable with the language.
0.8: A Grade of Incomplete
The rules for incompletes and grade changes are set by the school
and not the department or individual faculty member.
The rules set by CAS can be found in
http://cas.nyu.edu/object/bulletin0608.ug.academicpolicies.html
state:
The grade of I (Incomplete) is a temporary grade that
indicates that the student has, for good reason, not
completed all of the course work but that there is the
possibility that the student will eventually pass the
course when all of the requirements have been completed.
A student must ask the instructor for a grade of I,
present documented evidence of illness or the equivalent,
and clarify the remaining course requirements with the
instructor.
The incomplete grade is not awarded automatically. It is
not used when there is no possibility that the student
will eventually pass the course. If the course work is
not completed after the statutory time for making up
incompletes has elapsed, the temporary grade of I shall
become an F and will be computed in the student's grade
point average.
All work missed in the fall term must be made up by the end of the
following spring term.
All work missed in the spring term or in a summer session must be
made up by the end of the following fall term.
Students who are out
of attendance in the semester following the one in which the course
was taken have one year to complete the work.
Students should contact the College Advising Center for an Extension
of Incomplete Form, which must be approved by the
instructor.
Extensions of these time limits are rarely granted.
Once a final (i.e., non-incomplete) grade has been submitted by the
instructor and recorded on the transcript, the final grade cannot be
changed by turning in additional course work.
0.9: Academic Integrity Policy
The CS policy on academic integrity, which applies to all graduate
courses in the department, can be found
here
.
Appendix B: Logic Design
Remark: Appendix B is on the CD that comes with
the book, but is not in the book
itself.
If anyone does not have convenient access to a printer,
please let me know and I will print a black and white copy for you.
The pdf on the CD is in color so downloading it to your computer for
viewing in color is probably a good idea.
If you have a color printer that is not terribly slow, you might
want to print it in color—that's what I did.
Homework: Read B1
B.2: Gates, Truth Tables and Logic Equations
Homework: Read B2
The word digital, when used in digital logic
or
digital computer
means discrete.
That is, the electrical values (i.e., voltages) of the signals in a
circuit are treated as a non-negative integers (normally just 0 and
1).
The alternative is analog, where the electrical values are
treated as real numbers.
To summarize, we will use only two voltages: high and low.
A signal at the high voltage is referred to as 1
or true or set or asserted.
A signal at the low voltage is referred to as 0
or false or unset or deasserted.

The assumption that at any time all signals are either 1 or 0 hides
a great deal of engineering.
- A full engineering design must make sure not to sample the
signal when not in one of these two states.
- Sometimes it is just a matter of waiting long enough
(determines the clock rate, i.e., how many megahertz).
- Other times it is worse and you must avoid glitches.
- Oscilloscope traces are shown on the right.
The vertical axis is voltage, the horizontal axis is time.
- Square wave—the ideal.
This is how we think of circuits.
- (Poorly drawn) Sine wave.
- Actual wave.
- Non-zero rise times and fall times.
- Overshoots and undershoots.
- Glitches.
Since this is not an engineering course, we will ignore these
issues and assume square waves.
In English digital implies 10 (based on digit, i.e. finger),
but not in computers.
Indeed, the word Bit is short for Binary digIT and binary means
base 2 not 10.
0 and 1 are called complements of each other as are true and false
(also asserted/deasserted; also set/unset)
A logic block can be thought of as a black box that takes signals in
and produces signals out.
There are two kinds of blocks
- Combinational (or combinatorial)
- Does NOT have memory elements.
- Is simpler than circuits with memory since the outputs are a
function of the inputs.
That is, if the same inputs are presented on
Monday and Tuesday, the same outputs will result.
- Sequential
- Contains memory.
- The current value in the memory is called the state of the
block.
- The output depends on the input AND the state.
We are doing combinational blocks now. Will do sequential blocks
later (in a few lectures).
Truth Tables
Since combinatorial logic has no memory, it is simply a
(mathematical) function from its inputs to its outputs.
A common way to represent the function is using a
Truth Table.
A Truth Table has a column for each input and a
column for each output.
It has one row for each possible set of input values.
So, if there are A inputs, there are 2A rows.
In each of these rows the output columns have the output for that
input.
How many possible truth tables are there?
1-input, 1-output Truth Tables
Let's start with a really simple truth table, one corresponding to a
logic block with one input and one output.
How many different truth tables are there for a
one input one output
logic block?
There are two columns (1 + 1) and two rows (21).
Hence the truth table looks like the one on the right with the
question marks filled in.
1-input, 1-output Truth Table
| In | Out |
|---|
| |
| 0 | ? |
| 1 | ? |
Since there are two question marks and each one can have one of two
values there are just 22=4 possible truth tables.
- The constant function 1, which has output 1 (i.e., true) for either
input value.
- The constant function 0.
- The identity function, i.e., the function whose output equals
its input.
This logic block is sometimes called a buffer.
- An inverter.
This function has output the opposite of the input.
We will see pictures for the last two possibilities very soon.
2-input, 1-output Truth Table
| In1 | In2 | Out |
|---|
|
|
|
| 0 | 0 | ? |
| 0 | 1 | ? |
| 1 | 0 | ? |
| 1 | 1 | ? |
2-input, 1-output Truth Tables
Three columns (2+1) and 4 rows (22).
How many are there?
It is just the number ways can you fill in the
output entries, i.e. the question marks.
There are 4 output entries
so the answer is 24=16.
Larger Truth Tables
How about 2 in and 8 out?
- 10 cols.
- 22=4 rows.
- 4*8=32 question marks.
- 232 (about 4 billion) possibilities.
3 in and 8 out?
- 11 cols.
- 23=8 rows.
- 28*8=264 possibilities.
n in and k out?
- n+k cols.
- 2n rows.
- 2k*2n possibilities.
This gets big real fast!
Boolean algebra
We use a notation that looks like algebra to express logic functions and
expressions involving them.
The notation is called Boolean algebra in honor of
George Boole.
A Boolean value is a 1 or a 0.
A Boolean variable takes on Boolean values.
A Boolean function takes in boolean variables and
produces boolean values.
Four Boolean function are especially common.
- The (inclusive) OR Boolean function of two variables.
Draw its truth table on the board.
This is written + (e.g. X+Y where X and Y are Boolean variables)
and often called the logical sum.
(Three out of four output values in the truth table look
like the sum.)
- AND.
Draw its truth table on the board.
And is often called the logical product and written
as a centered dot (like the normal product in regular algebra).
I will offen write it as a period in these notes.
As in regular algebra, when all the logical variables are just one
character long, we indicate the product by juxtaposition, that
is, AB represents the product of A and B when it is clear that
it does not represent the two character symbol AB.
All four truth table values look like a product.
- NOT.
Draw its truth table on the board.
This is a unary operator (i.e., it has one argument, not two as
above; functions with two inputs are called binary operators).
Written A with a bar over it.
I will use ' instead of a bar as it is easier for me to input in
html.
- Exclusive OR (XOR).
Draw its truth table on the board.
Written as ⊕, a + with a circle around it.
True if exactly one input is true.
In particular, remember that TRUE ⊕ TRUE = FALSE.
Homework: Draw the truth table of the Boolean
function of 3 boolean variables that is true if and only
if exactly 1 of the three variables is true.
Some manipulation laws
Remember this is Boolean Algebra.
- Identity (recall that I use . for and):
- A+0 = 0+A = A
- A.1 = 1.A = A
- Inverse (recall that I use ' for not):
- A+A' = A'+A = 1
- A.A' = A'.A = 0
- The name inverse law is somewhat funny since you
Add the inverse and get the identity
for Product or Multiply by
the inverse and get the identity
for Sum.
- Commutative Laws:
- A+B = B+A
- A.B = B.A
- Due to the commutative laws, we see that both the identity and
inverse laws contained redundancy.
For example from A+0 = A and the commutative law we get that
0+A = A without stating the latter explicitly.
- Associative Laws:
- A+(B+C) = (A+B)+C
- A.(B.C)=(A.B).C
- Due to the associative law we can write A.B.C without
parentheses since either order of evaluation gives the same
answer.
Similarly we can write A+B+C without parentheses.
- Distributive Laws:
- A(B+C)=AB+AC
- A+BC=(A+B)(A+C)
- Note that, unlike the situation for ordinary
algebra, both distributive laws are valid.
- Note also that like the situation for
ordinary algebra, multiplication has higher precedence than
addition if no parentheses are used.
- DeMorgan's Laws:
- (A+B)' = A'B' (NOT has the highest precedence
- (AB)' = A'+B'
How does one prove these laws??
- Simple (but long).
Write the truth tables for each side and see that the outputs
are the same.
Actually you write just one truth table with columns for all the
inputs and for the outputs of both sides.
You often write columns for intermediate outputs as well, but
that is only a convenience.
The key is that you have a column for the final value of the LHS
(left hand side) and a column for the final value of the RHS and
that these two columns have identical results.
- Prove the first distributive law on the board. The following
columns are required: the inputs A, B, C; the LHS A(B+C); and
the RHS AB+AC.
Beginners like us would also use columns for the intermediate
results B+C, AB, and AC.
Homework: Prove the second distributive law.
Homework: Prove DeMorgan's laws.
Let's do (on the board) the example on pages B-6 and B-7.
Consider a logic function with three inputs A, B, and C; and three
outputs D, E, and F defined as follows: D is true if
at least one input is true, E
if exactly two are true, and F if all three are
true.
(Note that by if
we mean if and only if
.
- Construct the truth table.
This is straightforward; simply fill in the 24 entries by
looking at the definitions of D, E, and F.
- Produce logic equations for D, E, and F.
This can be done in two ways.
- Examine the column of the truth table for a given output
and write one term for each entry that is a 1.
This method requires constructing the truth table and might
be called the method of perspiration.
-
Look at the definition of D, E, and F and just
figure it out
.
This might be called the method of inspiration.
For D and F it is fairly clear.
E requires some cleverness: the key idea is that
exactly two are true
is the same as
(at least) two are true AND it is not the case that all
three are true
.
So we have the AND of two expressions: the first is a
three way OR and the second the negation of a three way
AND.
Start Lecture #2
The first way we solved the previous example shows
that any logic equation can be written using just
AND, OR, and NOT.
Indeed it shows more.
Each entry in the output column of the truth table corresponds to
the AND of three (because there are three
inputs) literals.
A literal is either an input variable or the negation of an input
variable.
In mathematical logic such a formula is said to be in
disjunctive normal form
because it is the disjunction
(i.e., OR) of conjunctions (i.e., ANDs).
In computer architecture disjunctive normal form is called
two levels of logic because it shows that any formula can
be computed in by passing signals through only two logic functions,
AND and then OR (assuming we are given the inputs and their
compliments).
- First compute all the ANDs.
There can be many, many of these, but they can all be computed at
once using many, many
and machines
.
- Compute the required ORs of the ANDs computed in step 1.
With DM (DeMorgan's Laws) we can do quite a bit without resorting to
truth tables.
For example one can ...
Homework: Show that the two expressions for E in the
example above are equal.
Start to do the homework on the board.
Remark: You may ignore the references to Verilog in
the text.
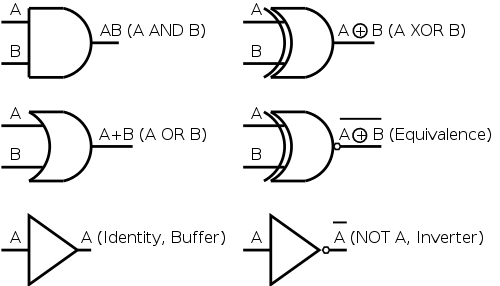
Gates
Gates implement the basic logic functions: AND OR NOT XOR
Equivalence.
When drawing the logic functions we use the standard shapes shown
to the right for the basic logic functions.
Note that none of the figures is input-output symmetric.
That is, one can tell which lines are inputs and which are
outputs without resorting to arrowheads and without
the convention that inputs are on the left.
Sometimes the figure is rotated 90 or 180 degrees.
Bubbles
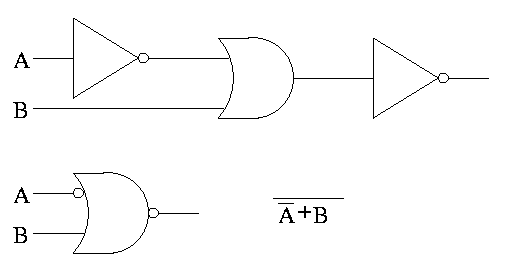
We often omit the inverters and draw the little circles at the
input or output of the other gates (AND OR).
These little circles are sometimes called bubbles.
For example, the diagram on the right shows three ways a writing
the same logic function.
This explains why the inverter is drawn as a buffer with an output
bubble.
Show why the picture for equivalence is correct.
That is, show that equivalence is the negation of XOR, i.e,
show that AB + A'B' = (A ⊕ B)'.
(A ⊕ B)' =
(A'B+AB')' =
(A'B)' (AB')' =
(A''+B') (A'+B'') =
(A + B') (A' + B) =
(A + B') A' + (A + B') B =
AA' + B'A' + AB + B'B =
0 + B'A' + AB + 0 =
AB + A'B'
Homework: B.4.
Homework: Recall the Boolean function E that is
true if and only if exactly 1 of the three variables is true.
We have already drawn the truth table.
Draw a logic diagram for E using AND OR NOT.
Draw a logic diagram for E using AND OR and bubbles.
A set of gates is called universal if these gates are
sufficient to generate all logic functions.
- We have seen that any logic function can be constructed from AND OR
NOT.
So this triple is universal.
- Are there any pairs that are universal?
Ans: Sure, A+B = (A'B')' so we can get OR from AND and NOT.
Hence the pair AND NOT is universal
Similarly, can get AND from OR and NOT and hence the pair OR NOT
is universal.
- Could there possibly be a single function that is universal all by
itself?
AND won't work as you can't get NOT from just AND
OR won't work as you can't get NOT from just OR
NOT won't work as you can't get AND from just NOT.
- But there indeed is a universal function!
In fact there two.
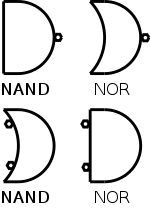
NOR (NOT OR) is true when OR is false.
Draw the truth table on the board.
NAND (NOT AND) is true when AND is false.
Draw the truth table on the board.
We can draw NAND and NOR each two ways as shown in the diagram on
the right.
The top pictures are from the definition; the bottom use DeMorgan's
laws.
Theorem
A 2-input NOR is universal and
a 2-input NAND is universal.
Proof
We will show that you can get A', A+B, and AB using just a two
input NOR.
- A' = A NOR A
- A+B = (A NOR B)' (we can use ' by above)
- AB = (A' OR B')'
Draw the truth tables showing the last three statements.
Also say why they are correct, i.e., we are at the stage
were simple identities like these don't need truth tables.
End of Proof.
Homework: Show that a 2-input NAND is universal.
If fact the above proof was overkill, it would have been enough to
show that you can get A' and A+B.
Why?
Because we already know that the pair OR,NOT is universal.
It would also have been enough to show that you can get A' and AB.
Sneaky way to see that NAND is universal.
- First show that you can get NOT from NAND as we did above.
Hence we can build inverters.
- Now imagine that you are asked to do a circuit for some function
with N inputs.
Assume you have only one output.
- Using inverters you can get 2N signals the N original and N
complemented.

- Recall that the natural sum of products form is a bunch of ANDs
feeding into one (giant) OR.

- Naturally you can add pairs of bubbles since they
cancel
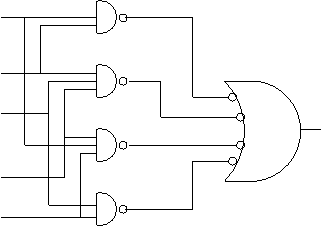
- But these are all NANDS!!
- This shows universality if you permit giant NANDs.
To complete the proof you would show that
NAND(A,B,C) can be written with just 2-input NANDs.
We have seen how to implement any logic function given its truth
table.
Indeed, the natural implementation from the truth table uses just
two levels of logic.
But that implementation might not be the simplest possible.
That is, we may have more gates than are necessary.
Trying to minimize the number of gates is
decidedly NOT trivial.
A text by Mano covers the topic of gate minimization in detail.
We will not cover it in this course.
It is mentioned and reference, but not covered in P&H.
I actually like topic but it takes a few lectures to cover well and
it not used much in practice since it is algorithmic and is done
automatically by CAD tools.
Minimization is not unique, i.e. there can be two or more minimal
forms.
Given A'BC + ABC + ABC'
Combine first two to get BC + ABC'
Combine last two to get A'BC + AB
Don't Cares (preview)
Sometimes when building a circuit, you don't care what the output
is for certain input values.
For example, that input combination might be known not to occur.
Another example occurs when, for some combination of input values, a
later part of the circuit will ignore the output of this part.
These are called don't care outputs.
Making use of don't cares can reduce the number of gates needed.
Can also have don't care inputs
when, for certain values of a subset of the inputs, the output is
already determined and you don't have to look at the remaining
inputs.
We will see a case of this very soon when we do multiplexors.
An aside on theory
Putting a circuit in disjunctive normal form (i.e. two levels of
logic) means that every path from the input to the output goes
through very few gates.
In fact only two, an OR and an AND.
Maybe we should say three since the AND can have a NOT (bubble).
Theoreticians call this number (2 or 3 in our case) the
depth of the circuit.
Se we see that every logic function can be implemented with small
depth.
But what about the width, i.e., the number of gates.
The news is bad.
The parity function takes n inputs and gives TRUE
if and only if the number of TRUE inputs is odd.
If the depth is fixed (say limited to 3), the number of gates
needed for parity is exponential in n.
B.3 Combinational Logic
Homework: Read B.3.
Generic Homework: Read sections in book
corresponding to the lectures.
Decoders (and Encoders)
Imagine you are writing a program and have 32 flags, each of which
can be either true or false.
You could declare 32 variables, one per flag.
If permitted by the programming language, you would declare each
variable to be a bit.
In a language like C, without bits, you might use a single 32-bit
int and play with shifts and masks to store the 32 flags in this one
word.
In either case, an architect would say that you have these flags
fully decoded.
That is, you can detect the value of any combination of the bits.
Now imagine that for some reason you know that, at all
times, exactly one of the flags is true and the
other are all false.
Then, instead of storing 32 bits, you could store a 5-bit integer
that specifies which of the 32 flags is true.
This is called fully encoded.
A 5-to-32
decoder converts an encoded 5-bit signal into 32
signals with exactly one signal true.
A 32-to-5
encoder does the reverse operations.
Note that the output of an encoder is defined
only if exactly one input bit is
set (recall set means true).

The diagram on the right shows a 3-to-8 decoder.
- Note the
3
with a slash, which signifies a three bit
input.
This notation represents three (1-bit) wires.
- A decoder with n input bits, produces 2^n output bits.
- View the input as
k written as an n-bit binary number
and view the output as 2^n bits with the k-th bit set and all
the other bits clear.
- Implement the 3-to-8 decoder on the board with simple gates.
- Why do we use decoders and encoders?
- The encoded form takes (MANY) fewer bits so is better for
communication.
- The decoded form is easier to work with in hardware since
there is no direct way to test if 3 wires represent a 5
(101).
You would have to test each wire.
But it easy to see if the encoded form is a five; just test
the fifth wire, out5.
Remark: Lab1 Assigned, due 17 September 2007.
Demo logisim.
Multiplexors
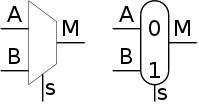
A multiplexor, often called a mux or
a selector is used to select one (output) signal
from a group of (input) signals based on the value of a group of
(select) signals.
In the 2-input mux shown on the right, the select line S is thought of
as an integer 0..1.
If the integer has value j then the jth input is sent to
the output.
Construct on the board an equivalent circuit with ANDs and ORs in
two ways:
- Construct a truth table with 8 rows (don't forget that,
despite its name, the select line is an input) and write the sum
of product form, one product for each row and a large 8-input
OR.
This is the canonical two-levels of logic solution.
- A simpler, more clever, two-levels of logic solution.
Two ANDs, one per input (not including the selector).
The selector goes to each AND, one with a bubble.
The output from the two ANDs goes to a 2-input OR.
Start Lecture #3
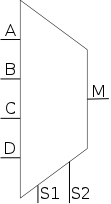
The diagram on the right shows a 4-input MUX.
Construct on the board an equivalent circuit with ANDs and ORs in
three ways:
- Construct the truth table (64 rows!) and write the sum of
products form, one product (6-input AND) for each row and
a gigantic 64-way OR.
Just start this, don't finish it.
- A simpler (more clever) two-level logic solution.
Four ANDS (one per input), each gets one of the inputs and both
select lines with appropriate bubbles.
The four outputs go into a 4-way OR.
- Construct a 2-input mux (using the clever solution).
Then construct a 4-input mux using a tree of three 2-input
muxes.
One select line is used for the two muxes at the base of the
tree, the other is used at the root.
All three of these methods generalize to a mux with 2k
input lines, and k select lines.
A 2-way mux is the hardware analogue of if-then-else.
if S=0
M=A
else
M=B
endif
A 4-way mux is an if-then-elif-elif-else
if S1=0 and S2=0
M=A
elif S1=0 and S2=1
M=B
elif S1=1 and S2=0
M=C
else -- S1=1 and S2=1
M=D
endif
Don't Cares (again)
| S | I0 | I1 | O |
|---|
|
|
| 0 | 0 | X | 0 |
| 0 | 1 | X | 1 |
| 1 | X | 0 | 0 |
| 1 | X | 1 | 1 |
Consider a 2-input mux.
If the selector is 0, the output is I0 and the value of I1 is
irrelevant.
Thus, when the selector is 0, I1 is a don't care input.
Similarly, when the selector is 1, I0 is a don't care input.
On the right we see the resulting truth table.
Recall that without using don't cares the table would have 8 rows
since there are three inputs; in this example the use of don't cares
reduced the table size by a factor of 2.
The truth table for a 4-input mux has 64 rows, but the use of don't
care inputs has a dramatic effect.
When the selector is 01 (i.e, S0 is 0 and S1 is 1), the output
equals the value of I1 and the other three I's are don't care.
A corresponding result occurs for other values of the selector.
Homework: Draw the truth table for a 4-input mux
making use of don't care inputs.
What size reduction occurred with the don't cares?
Homework:
B.13.
(I am not sure what is meant by hierarchial
;
perhaps modular
).
B.10. (Assume you have constant signals 1 and 0 as well.)
Recall that a don't care output occurs when for some input values
(i.e., rows in the truth table), we don't care what the value is for
certain outputs.
- Perhaps we know that this set of input values is impossible.
- Perhaps we know that we will
mux out
these outputs when
we have the specified inputs.
Powers of 2 NOT Required
How can one construct a 5-way mux?
Construct an 8-way mux and use it as follows.
- Connect the five input signals to the first five inputs of the
mux.
- Make sure the three select inputs never result in 5, 6, or 7.
Can do better by realizing the select lines equalling 5, 6, or 7
are don't cares and hence the 8-way can be customized and would use
fewer gates than an 8-way mux.
PLAs—Programmable Logic Arrays (and PALs)
The idea is to partially automate the algorithmic way you can
produce a circuit diagram (in the sums of product form) from a given
truth table.
Since the form of the circuit is always a bunch of ANDs feeding into
a bunch of ORs, we can manufacture
all the gates in advance
of knowing the desired logic functions and when the functions are
specified, we just need to make the necessary connections from the
ANDs to the ORs.
In essence all possible connections are configured but with
switches that can be open or closed.
| A | B | C | D | E | F |
|---|
|
|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 0 |
| 0 | 1 | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 | 1 |
The description just given is more accurate for a PAL (Programmable
Array Logic) than for a PLA, as we shall soon see.
Consider the truth table on the right, which we have seen before.
It has three inputs A, B, and C, and three outputs D, E, F.
Below the truth table we see the corresponding logic diagram in sum
of products form.
Recall how we construct this diagram from the truth table.
- The circuit is in sum of products form.
- There is a big OR for each output.
The OR has one input for each row that the output is true.
- Since there are 7 rows for which at least one output is true,
there are 7 product terms that will be used in one
or more of the ORs (in fact all seven will be used in D, but that is
special to this example).

- Each of these product terms is called a Minterm.
- So we need seven ANDs, one for each minterm.
Each AND takes a subset of A, B, C, A', B', and C' as inputs.
In fact we can say more since some subsets (e.g., A and A')
are never used.
Instead of arbitrary subsets of the 6 inputs, we choose three inputs,
either A or A', either B or B', and either C or C'.
However, we will not make use of this refinement in the next diagram.
- This collection of ANDs is called the AND
plane and the collection of ORs mentioned above is
called the OR plane.
The reason for calling them a plane will be clearer in the next
diagram.
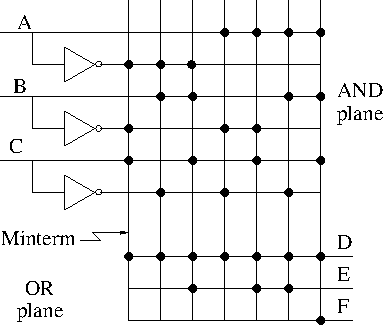
To the right, the above figure is redrawn in a more schematic style.
- This figure shows more clearly the AND plane, the OR plane, and
the minterms.
- Rather than having bubbles (i.e., custom AND gates that invert
certain inputs), we
simply invert each input once and send the inverted signal all the way
accross.
- AND gates are shown as vertical lines; ORs as horizontal.
- Note the dots used to represent connections.
- Imagine building a bunch of these but not yet specifying where the
dots go.
This would be a generic precursor to a PLA.

Finally, a PLA can be redrawn in the more abstract form shown on the
right.
Before a PLA is manufactured all the connections are specified.
That is, a PLA is specific for a given circuit.
Hence the name Programmable Logic Array is somewhat
of a misnomer since the device is not programmable by the
user.
Homework: B.11 and B.12.
PAL (Programmable Array Logic)
A PAL can be thought of as a PLA in which the final dots are made
by the user.
The manufacturer produces a sea of gates
.
The user programs it to the desired logic function by adding the
dots.
ROMs
One way to implement a mathematical function (or a java function
without side effects) is to perform a table lookup.
A ROM (Read Only Memory) is the analogous way to implement a logic
function.
- For a math function f we are given x and produce f(x).
- For a ROM with are given the address and produce the value
stored at that address.
- Normally math functions are defined for an infinite number of
values, for example f(x) = 3x for all real numbers x.
- We can't build an infinite ROM (sorry), so we are only interested
in functions defined for a finite number of values.
Today a billion is OK, but a trillion is not.
- How do we create a ROM for the function f(3)=4, f(6)=20 all other
values don't care?
Simply purchase a ROM with 4 in address 3 and 20 in address 6.
- Consider a function defined for all n-bit numbers (say n=20) and
having a k-bit output for each input.
- View an n-bit input as n 1-bit inputs.
- View a k-bit output as k 1-bit outputs.
- Since there are 2^n possible inputs and each requires a k
1-bit output, there are a total of (2^n)k bits of output,
i.e. the ROM must hold (2^n)k bits.
- Now consider a truth table with n inputs and k outputs.
The total number of output bits is again (2^n)k (2^n rows
and k output columns).
- Indeed the ROM implements a truth table, i.e. is a logic
function.
Important: A ROM does not have state.
It is another combinational circuit.
That is, it does not represent memory
.
The reason is that once a ROM is manufactured, the output depends
only on the input.
I realize this sounds wrong, but it is right.
Indeed, we will shortly see that a ROM is like a PLA.
Both are structures that can be used to implement a truth table.
The key property of combinational circuits is that the outputs
depend only on the inputs.
This property (having no state) is false for a RAM chip.
The input to a RAM, just like the input to a ROM, is an address.
The RAM responds by presenting at its outputs the value
CURRENTLY stored at that address.
Thus just knowing the input (i.e., the address) is
not sufficient for determining the output.
A PROM is a programmable ROM.
That is, you buy the ROM with nothing
in its memory and
then before it is placed in the circuit you load the
memory, and never change it.
This is like a CD-R.
An EPROM is an erasable PROM.
It costs more but if you decide to change its memory this is
possible (but is slow).
This is like a CD-RW.
Normal
EPROMs are erased by some ultraviolet light process.
But EEPROMs (electrically erasable PROMS) are
not as slow and are done electronically.
Flash is a modern EEPROM that is reasonably
fast.
All these EPROMS are erasable not writable, i.e. you can't just change
one byte to an arbitrary value.
(Some modern flash rams can nearly replace true ram and perhaps
should not be called EPROMS).
ROMs and PLAs
A ROM is similar to PLA
- Both can, in principle, implement any truth table.
- A 2Mx8 ROM can really implement any truth table with 21 inputs
(221=2M) and 8 outputs.
- It stores 2M bytes.
- In ROM-speak, it has 21 address pins and 8 data pins.
- A PLA with 21 inputs and 8 outputs might need to have 2M minterms
(AND gates).
- The number of minterms depends on the truth table itself.
- For normal truth tables with 21 inputs the number of
minterms is much less than 221.
- The PLA is manufactured with the number of minterms needed.
- Compare a PAL with a PROM.
- Both can, in principle, implement any truth table.
- Both are user programmable.
- A PROM with n inputs and k outputs can implement any truth
table with n inputs and k outputs.
- An n-input, k-output PAL that you buy does not have enough
gates for all possibilities since most truth tables with n
inputs and k outputs require far fewer than k2n
gates.
Full Truth Table
| A | B | C | D | E | F |
|---|
|
|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 1 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 | 0 |
Don't Cares (bigger example)
- Sometimes not all the input and output entries in a truth table are
needed. We indicate this with an X and it can result in a smaller
truth table.
- Input don't cares.
- The output doesn't depend on all inputs, i.e. the output has
the same value no matter what value this input has.
- We saw this when we did muxes.
- Output don't cares
- For some input values, either output is OK.
- This input combination is impossible.
- For this input combination, the given output is not used
(perhaps it is
muxed out
downstream).
Truth Table with Output Don't Cares
| A | B | C | D | E | F |
|---|
|
|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 1 | 1 | X |
| 1 | 0 | 0 | 1 | 1 | X |
| 1 | 0 | 1 | 1 | 1 | X |
| 1 | 1 | 0 | 1 | 1 | X |
| 1 | 1 | 1 | 1 | 1 | X |
The top diagram on the right is the full truth table for the
following example (from the book).
Consider a logic function with three inputs A, B, and C, and three
outputs D, E, and F.
- If A or C is true, then D is true (independent of B).
- If A or B is true, then E is true (independent of C).
- F is true if exactly one of the inputs is true, but we don't care
about the value of F if both D and E are true.
The full truth table has 7 minterms (rows with at least one nonzero
output).
The middle truth table has the output don't cares included.
Truth Table with Input and Output Don't Cares
| A | B | C | D | E | F |
|---|
|
|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 1 |
| 0 | 1 | 0 | 0 | 1 | 1 |
| X | 1 | 1 | 1 | 1 | X |
| 1 | X | X | 1 | 1 | X |
Now do the input don't cares
- B=C=1 ==> D=E=11 ==> F=X ==> A=X
- A=1 ==> D=E=11 ==> F=X ==> B=C=X
The resulting truth table is also shown on the right.
Note how much smaller it is
These don't cares are important for logic minimization.
Compare the number of gates needed for the full truth table and the
reduced truth table.
There are techniques for minimizing logic, but we will not cover
them.

Arrays of Logic Elements
Often we want to consider signals that are wider than a single bit.
An array of logic elements is used when each of the individual bits
is treated similarly.
As we will soon see, sometimes most of the bits are treated
similarly, but there are a few exceptions.
For example, a 32-bit structure might treat the lob (low order bit)
and hob differently from the others.
In such a case we would have an array 30 bits wide and two 1-bit
structures.
- A Bus is a collection of (say n) data lines
treated as a single logical (n-bit) value.
- We typically use an array of logic elements to process a bus.
For example, the above mux switches between two 32-bit buses.
- We draw a bus using thicker lines and employ the
by n
notation.
- The diagram on the right shows a 32-bit, 2-way mux and an
implementation using thirty-two 1-bit, 2-way muxes.
B.4: Using a Hardware Description Language
B.5: Constructing a Basic Arithmetic Logic Unit (ALU)
We will produce logic designs for the integer
portion of the MIPS ALU (the floating point operations are more
complicated and will not be implemented).
MIPS is a computer architecture widely used in embedded designs.
In the 80s and early 90s, it was quite popular for desktop (or
desk-side) computers.
This was the era of the killer micros
that decimated the
market for minicomputers.
(When I got my DECstation with a MIPS R3000, I think it was the
fastest integer computer at NYU for a short while.)
Much of the design (all of the beginning part) is generic.
I will point out when we are tailoring it for MIPS.
A 1-bit ALU
Our first goal will be a 1-bit wide structure that computes the
AND, OR, and SUM of two 1-bit quantities.
For the sum there is actually a third input, CarryIn, and a 2nd
output, CarryOut.
Since out basic logic toolkit already includes AND and OR gates,
our first real task is a 1-bit adder.
Half Adder
If the final goal was a 1-bit ALU, then we would not have a
CarryIn.
For a multi-bit ALU, the CarryIn for each bit is the CarryOut of the
preceding lower-order bit (e.g., the CarryIn for bit 3 is the
CarryOut from bit 2).
When we don't have a CarryIn, the structure is sometimes called
a half adder
.
Don't treat the name too seriously; it is not half of an adder.
A half adder has the following inputs and outputs.
- Two 1-bit inputs: X and Y.
- Two 1-bit outputs S (sum) and Co (carry out).
- No carry in.
Draw the truth table.
Homework: Draw the logic diagram.
Start Lecture #4
Remark: Show in class how to broadcast S (select
line) to many ANDs (used for wide muxes in 2nd lab) and assign lab
2.
Full Adder
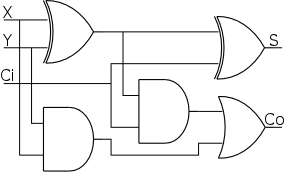
Now we include the carry-in.
- Three 1-bit inputs: X, Y and Ci.
- Two 1-bit output: S and Co.
- S =
the total number of 1s in X, Y, and Ci is odd
- Co = #1s is at least 2.
- The diagram on the right uses logic formulas for S and Co
equivalent to the definitions given above (see homework just
below).
Homework:
- Draw truth table (8 rows)
- Show S = X ⊕ Y ⊕ Ci
- Show Co = XY + (X ⊕ Y)Ci

Combining 1-bit AND, OR, and ADD
We have implemented 1-bit versions of AND (a basic gate), OR (a
basic gate), and SUM (the FA just constructed, which we henceforth
draw as shown on the right).
We now want a single structure that, given another input (the
desired operation, another one of those
control lines
), produces as output the specified operation.
There is a general principle used to produce a structure that
yields either X or Y depending on the value of operation.
- Implement a structure that always computes X.
- Implement another structure that always computes Y.
- Mux X and Y together using operation as the select
line.
This mux, with an operation select line, gives a structure
that sometimes
produces one result and sometimes
produces another.
Internally both results are always
produced.

In our case we have three possible operations so we need a three
way mux and the select line is a 2-bit wide bus.
With a 2-bit select line we can specify 4 operations, for now we are
using only three.
We show the diagram for this 1-bit ALU on the right.
The Operation
input is shown in green to distinguish it as a
control line rather than a data line.
That is, the goal is to produce two bits of result from 2 (AND, OR)
or 3 (ADD) bits of data.
The 2 bits of control tell what to do, rather than what data to do
it on.
The extra data output (CarryOut) is always produced.
Presumably if the operation was AND or OR, CarryOut is not used.
I believe the distinction between data and control will become
quite clear as we encounter more examples.
However, I wouldn't want to be challenged to give a (mathematically
precise) definition.
A 32-bit ALU
A 1-bit ALU is interesting, but we need a 32-bit ALU to implement
the MIPS 32-bit operations, acting on 32-bit data values.
For AND and OR, there is almost nothing to do; a 32-bit AND is just
32 1-bit ANDs so we can simply use an array of logic elements.
However, ADD is a little more interesting since the bits are not
quite independent:
The CarryOut of one bit becomes the CarryIn of the next.
A 32-bit Adder
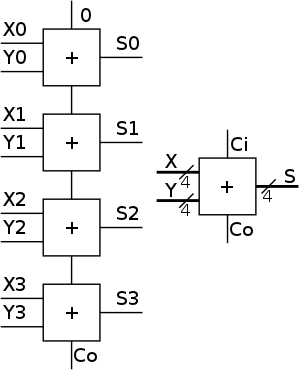
Let's start with a 4-bit adder.
- In the diagram to the near right, each box is a
1-bit full adder as above.
- The top FA is the low order bit (lob); the bottom FA is the hob.
- Note that the Carry-out of one 1-bit FA becomes the Carry-in
of the next higher order 1-Bit FA.
- Note also that you do the same thing when you add numbers.
- Further to the right we show the 4-bit adder without showing
the individual FAs.
- In this rightmost picture we have two 4-bit inputs (the
addends), one 1-bit input (the Carry-in), one 4-bit output (the
sum), and 1-bit output (the Carry-out).
- If all you ever wanted from the rightmost circuit was 4-bit
addition, you would not have a Ci.
Instead you would feed zero into the Ci of the lob as I did in
the left picture.
- But you can put two of these 4-bit adders together to get an
8-bit adder.
Simply connect the Co of one to the Ci of the second.
How about a 32-bit adder, or even an an n-bit adder?
- No problem; just use n 1-bit FAs.
- Linear (time) complexity, i.e. the time for a 64-bit add is
twice that for a 32-bit add, which itself is twice the time for
a 16-bit add.
- This adder design is called ripple carry since the carry
ripples down the circuit from the low order bit to the high
order bit.
The necessity for the carry to ripple down the circuit one bit
at a time is why the circuit has linear complexity.
- Faster (logarithmic complexity) methods exist.
Indeed we will learn one soon.
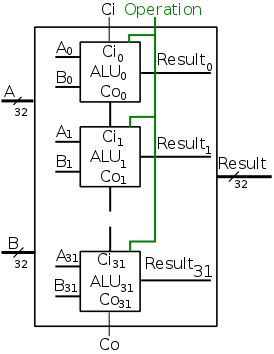
Combining 32-bit AND, OR, and ADD
To obtain a 32-bit ALU, we put together the 1-bit ALUs in a manner
similar to the way we constructed a 32-bit adder from 32 FAs.
Specifically we proceed as follows and as shown in the figure on the
right.
- Use an array of logic elements for the logic.
The individual logic element is the 1-bit ALU.
- Use buses for A, B, and Result.
Broadcast
Operation to all of the internal
1-bit ALUs.
This means wire the external Operation to the
Operation input of each of the internal 1-bit ALUs.
Facts Concerning (4-bit) Two's Complement Arithmetic
Remark
This is one place were the our treatment
must go a little out of order.
Appendix B in the book assumes you have read the chapter on computer
arithmetic; in particular it assumes that you know about two's
complement arithmetic.
I do not assume you know this material and we will cover it
later, when we do that chapter.
What I will do here is assert some facts about two's complement
arithmetic that we will use to implement the circuit for SUB.
End of Remark.
For simplicity I will be presenting 4-bit arithmetic.
We are really interested in 32-bit arithmetic, but the idea is the
same and the 4-bit examples are much shorter (and hence less likely
to contain typos).
4-bit Twos's Complement Numbers
With 4 bits, there can be only 16 numbers.
One of them is zero, 8 are negative, and 7 are positive.
The high order bit (hob) on the left is the sign bit.
The sign bit is zero for positive numbers and for the number zero;
the sign bit is one for negative numbers.
Zero is written simply 0000.
1-7 are written 0001, 0010, 0011, 0100, 0101, 0110, 0111.
That is, you set the sign bit zero and write 1-7 using the remaining
three lob's.
This last statement is also true for zero.
-1, -2, ..., -7 are written by taking the two's complement
of the corresponding positive number.
The two's complement is computed in two steps.
- Take the (ordinary) complement, i.e. turn ones to zeros and
vice versa.
This is sometimes called the one's complement.
For example, the (4-bit) one's complement of 3 is 1100.
- Add 1.
For example, the (4-bit) two's complement of 3 is 1101.
If you take the two's complement of -1, -2, ..., -7, you get back
the corresponding positive number.
Try it.
If you take the two's complement of zero you get zero.
Try it.
What about the 8th negative number?
-8 is written 1000.
But if you take its (4-bit) two's complement,
you must get the wrong number because the correct
number (+8) cannot be expressed in 4-bit two's complement notation.
Two's Complement Addition and Subtraction
Amazingly easy (if you ignore overflows).
- Add: Just use a 4-bit adder, do NOT treat the
sign bit in a special way, and discard the final carry-out.
- Sub: Take the two's complement of the subtrahend (the second
number) and add as above.
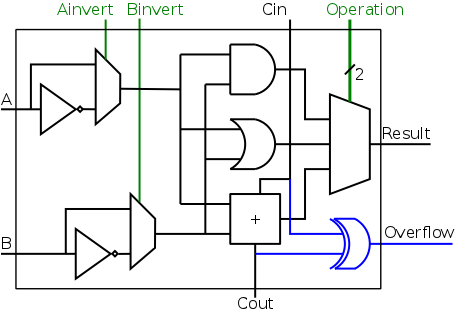
Implementing SUB (with AND, OR, and ADD)

No change is needed to our circuit above to handle two's complement
numbers for AND/OR/ADD.
That statement is not clear for ADD and will be shown true later in
the course.
We wish to augment the ALU so that we can perform subtraction as
well.
As we stated above, A-B is obtained by taking the two's complement
of B and adding.
A 1-bit implementation is drawn on the right with the new structures
in blue (I often use blue for this purpose).
The enhancement consists of
- Using an inverter to get the one's complement of B.
- Using a mux with control line (in green) Binvert to select
whether B or B' is fed to the adder.
- Using a clever trick to obtain the effect of B's two
complement when we are using B's one complement.
Namely we set Cin, the carry-in to the lob, equal to 1 instead
of 0.
This trick increases the sum by one and, as a result, calculates
A+B'+1, which is A plus the two's complement of B, which is A-B.
- So for the lob CarryIn is kinda-sorta a data line used as a
control line.
- As before, setting Operation to 00 and 01 gives AND
and OR respectively, providing we de-assert Binvert.
CarryIn is a don't care for AND and OR.
- To implement addition we use opcode 10 as before and de-assert
both Binvert and CarryIn
- To implement subtraction we again use opcode 10 but we assert
both Binvert and CarryIn

Extending to 32 Bits
A 32-bit version is simply a bunch of the 1-bit structures wired
together as shown on the right.
- The Binvert and Operation control lines are broadcast to all
of the 1-bit ALUs.
- As before Operation is 00 for AND, 01 for OR, and
10 for both ADD and SUB.
- For AND and OR de-assert BInvert.
CarryIn is a don't care.
- For addition de-assert both Binvert
and CarryIn.
- For subtraction assert both Binvert
and CarryIn.
- We could implement other functions as well.
For example, we get AB' by asserting Binvert and
setting Operation=00.
That one is not so useful, but a variant is useful and we will
implement it soon.
Tailoring the 32-bit ALU to MIPS
AND, OR, AND, and SUB are found in nearly all ALUs.
In that sense, the construction up to this point has been generic.
However, most real architectures have some extras.
For MIPS they include.
- NOR, not very special and very easy.
- Overflow handling, common but not so easy.
Set on less than
(slt), not common and not so easy.- Equality test, not very special and easy.
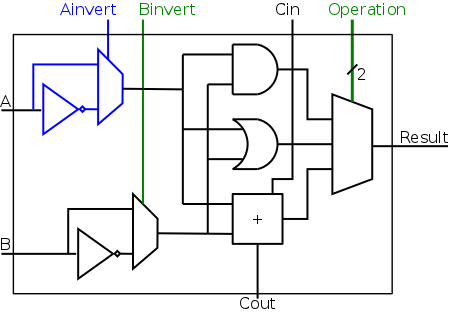
Implementing NOR
We noted above that our ALU already gives us the ability to
calculate AB', a fairly uncommon logic function.
A MIPS ALU needs NOR and, by DeMorgan's law,
A NOR B = (A + B)' = A'B'
which is rather close, we just need to invert A as well as B.
The diagram on the right shows the needed structures: an inverter
to get A', a mux to choose between A and A', and a control line for
the mux.
NOR is obtained by asserting Ainvert
and Binvert and setting Operation=00.
The other operations are done as before, with Ainvert
de-asserted.
The 32-bit version is a straightforward ...
Homework: Draw the 32-bit ALU that supports AND,
OR, ADD, SUB, and NOR.
Overflows
Remark: As with two's complement arithmetic, I
just present the bare boned facts here; they
are explained later in the course.
The facts are trivial (although the explanation is not).
Indeed there is just one fact.
- An overflow occurs for two's complement addition (which
includes subtraction) if and only if the carry-in to the sign
bit does not equal the carry out from the sign
bit.
Only the hob portion of the ALU needs to be changed.
We need to see if the carry-in is different from the carry-out, but
that is exactly XOR.
The simple modification to the hob structure is shown on the right.
Do on the board 4-bit twos complement addition of
- 1 + 1
- -1 + -1
Note that there is NO overflow despite a carry-out.
- 6 + 6
- -6 + -6
The 32-bit version is again a straightforward ...
Homework: Draw the 32-bit ALU that supports AND,
OR, ADD, SUB, and NOR and that asserts an overflow line when
appropriate.
Implementing Set on Less Than (SLT)
We are given two 32-bit, two's complement numbers A and B as input
and seek a 32-bit result that is 1 if A<B and 0 otherwise.
Note that only the lob of the result varies; the other bits are all 0.

The implementation is fairly clever as we shall see.
- We need to set the LOB of the result equal to the sign bit of
the subtraction A-B, and set the rest of the result bits to
zero.
- Idea #1.
Give the 4-way mux another (i.e., fourth) input, called LESS.
This input is brought in from outside the bit cell.
To generate slt, we make the select line to the mux equal to 11
so that the the output is the this new input.
See the diagram on the right.
- For all the bits except the LOB, the LESS input is
zero.
This is trivial to do:
Simply label a wire false or 0,
or de-asserted and connected it to the
31 Less inputs (i.e., all but the LOB).
- For the LOB we still need to figure out how to set less to the
sign of A-B.
Note that the circuit for the lob is the same
as for the other bits; the difference is in
the input to the circuit.
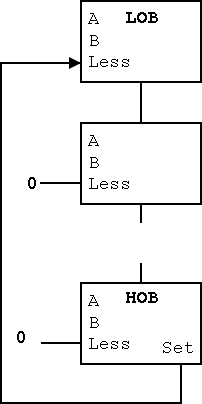
- Recall that even though we have selected input 3 from the mux,
all 4 inputs are computed.
This is IMPORTANT: an OR gate always computes
the OR of its inputs, whether you want it to or not, same for
AND, etc.
- Hence the adder is adding and if Binvert is
asserted, Ainvert is de-asserted, and CarryIn
is 1, the addition actually produces A-B.
- Idea #2.
Use the settings just mentioned so that the adder computes A-B
(and the mux throws it away).
Modify the HOB logic as follows (you could do this modification
for all bits, but just use the result from the HOB).
- Bring out the result of the adder (before
the mux).
- Take this new output from the HOB, call it SET and connect
it to the Less input in idea #1 for the LOB.
- Thus the Less for the LOB is correctly set and we
are done!
- The high level diagram of this maneuver is shown on the right.
- Why didn't I show a detailed diagram for this method?
Because this method is not used.
- Why isn't the method used?
Because it is wrong!
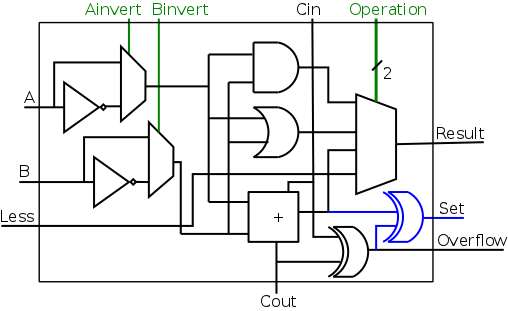
The problem with the above solution is that it ignores overflows.
Consider the following 4-bit (instead of 32-bit) example.
- Try slt on -6 and +5.
- True subtraction gives -11.
- The negative sign in -11 indicates (correctly) that -6 <
+5.
- But 4-bit subtraction gives a positive result (and
asserts overflow).
- Hence the set output of the hob is zero and we send
that to the Less input of the lob.
- Hence the circuit yields zero for slt given inputs -6 and
+5, thereby claiming that -6 is not less than 5.
The fix is to use the correct rule for less than rather than the
sometimes incorrect rule the sign bit of A-B is 1
.
Homework: figure out correct rule, i.e. a
non-pictorial version of problem B.24.
Hint: When an overflow occurs, the sign bit is definitely wrong.
The diagram on the right shows the correct calculation
of Set.
Start Lecture #5
Remark:
Lab 3 assigned.
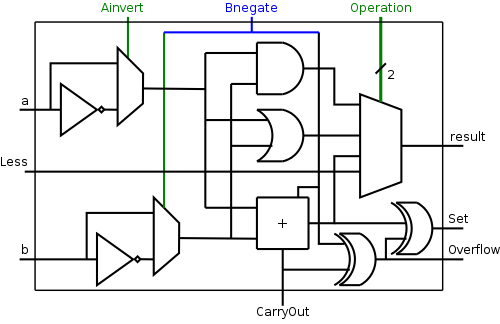
A Simple Observation
The CarryIn to the LOB and
Binvert to all the 1-bit ALUs are always
the same.
So the ALU has just one input called Bnegate, which is sent
to the appropriate inputs in the 1-bit ALUs.
The final 1-bit cell of the ALU is shown on the right.
Note that the circuit is the same for all bits;
however different bits are wired differently, i.e.,
they have different inputs and their outputs are sent to different
places.
Equality Detection
To see if A = B we simply form A-B and test if
the result is zero
- To see if all the bits are zero, is just a large NOR.
- This is conceptually trivially, but does require some wiring.
The Final Result
The final 32-bit ALU is shown below on the left.
Again note that all the bits have the same circuit.
The lob and hob have special external wiring;
the other 30 bits are wired the same.
To the right of this diagram we see the symbol used for an ALU.
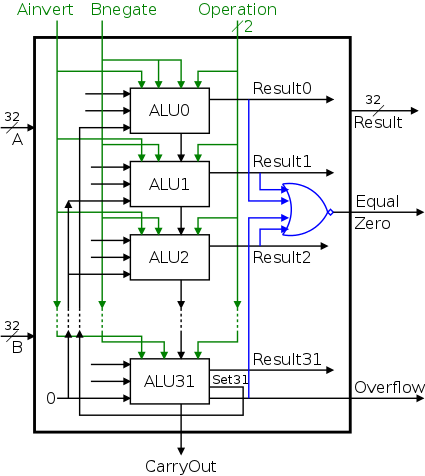
What are the control lines?
- Ainvert (1 bit)
- Bnegate (1 bit)
- OP (2 bits)
| function | 4-bit cntl | Ainv | Bneg | Oper |
| AND | 0000 | 0 | 0 | 00 |
| OR | 0001 | 0 | 0 | 01 |
| ADD | 0010 | 0 | 0 | 10 |
| SUB | 0110 | 0 | 1 | 10 |
| slt | 0111 | 0 | 1 | 11 |
| NOR | 1100 | 1 | 1 | 00 |
What functions can we perform?
- AND
- OR
- ADD
- SUB
- NOR
- slt (set on less than)
We think of the three control
lines Ainvert, Bnegate, and Operation as
forming a single 4-bit control line.
The table on the right shows what four bit value is needed for each
function.
Defining the MIPS ALU in Verilog
B.6: Faster Addition: Carry Lookahead
This adder is much faster than the ripple adder we did before,
especially for wide (i.e., many bit) addition.
Fast Carry Using Infinite
Hardware
This is a simple (theoretical) result.
- An adder is a combinatorial circuit hence it can be
constructed with two (or three if you count the bubbles) levels
of logic.
Done
- Consider 32-bit (or 64-bit, or 128-bit, or N-bit) addition, R=A+B.
- This is a logic function with 32+32+1=65 binary inputs (A, B,
and the CarryIn to the lob).
- It has 33 outputs R and the final CarryOut.
- Hence it can be expressed by a truth table having
265 rows and 65+33=98 columns.
- This is a gigantic truth table (about 3
billion trillion entries), but nonetheless finite.
- The corresponding PLA needs no more than 265
minterms feeding no more than 33 ORs.
- Since each minterm is just an AND (with some bubbles) it
is just one level of logic (or two if you count the
bubbles).
The ORs are just one level of logic, so we get a total of
two (or three).
- You could object that each minterm is the AND of a bunch
(2N+1, for N-bit addition) of inputs so perhaps shouldn't be
thought of as a single level of logic (even ignoring the
bubbles).
- The same consideration applies to the ORs, which might
have even more (22N+1) inputs.
- The above is a worst case analysis.
The actual circuit for addition is probably not quite as
bad, but still completely impractical for real 32-bit adders
- The above applied to any logic function; here are the
calculations specific for addition.
- Each of the 1-bit adders we built were fast (just a few
gate delays); the trouble was that the CarryIn to the upper
order bits took a long time to calculate.
We can calculate all the CarryIn's from the inputs a, b, and
CarryIn0 using two levels of logic.
- We use c0 for CarryIn0, c1 for
CarryIn1, c2 for CarryIn2, etc.
- c0 is an input.
- c1 = a0 b0 + a0 c0 + b0 c0
- c2 = a1 b1 + a1 c1 + b1 c1
= a1 b1 + a1 a0 b0 + a1 a0 c0 + a1 b0 c0 + b1 a0 b0
+ b1 a0 c0 + b1 b0 c0
- c3 = a2 b2 + a2 c2 + b2 c2 = ... (substitute for c2)
- etc.
Fast Carry Using the First Level of Abstraction: Propagate and Generate
At each bit position we have two input bits a and b as well as a
CarryIn input.
We now define two other bits propagate and generate
(p=ai+bi and g=aibi).
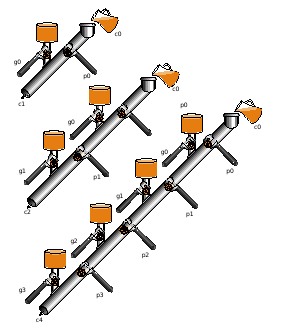
To summarize, using a subscript i to represent the bit number,
to generate a carry: gi = ai bi
to propagate a carry: pi = ai+bi
The diagram on the right, from P&H, gives a plumbing analogue for
generate and propagate.
A full size version of the diagram
is here in pdf.
The point is that liquid enters the main pipe if
either the initial CarryIn or one of the generates is true.
The water exits the pipe at the lower left (i.e.,
there is a CarryOut for this bit position) if all the propagate
valves are open from the lowest liquid entrance to the exit.
The two diagrams in these notes are from the 2e; the colors changed
between editions.
Given the generates and propagates, we can calculate all the
carries for a 4-bit addition (recall that c0=Cin is an
input) as follows (this is the formula version of the plumbing):
c1 = g0 + p0 c0
c2 = g1 + p1 c1 = g1 + p1 g0 + p1 p0 c0
c3 = g2 + p2 c2 = g2 + p2 g1 + p2 p1 g0 + p2 p1 p0 c0
c4 = g3 + p3 c3 = g3 + p3 g2 + p3 p2 g1 + p3 p2 p1 g0 + p3 p2 p1 p0 c0
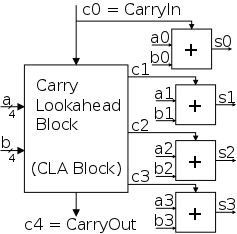
Thus we can calculate c1 ... c4 in just two additional gate delays
given the p's and g's (where we assume one gate can accept upto 5
inputs).
Since we get gi and pi after one gate delay, the total delay for
calculating all the carries is 3 (this includes c4=Carry-Out).
Each bit of the sum si can be calculated in 2 gate delays given ai,
bi, and ci.
Thus, for 4-bit addition, 5 gate delays after we are given a, b and
Carry-In, we have calculated s and Carry-Out.
We show this in the diagram on the right.
- The
Carry Lookahead Block
has inputs a, and b and the
carry-in.
The block calculates the p's and g's internally (not shown in the
diagram) and then calculates the carries, which are the outputs of
the block.
The block requires 3 gate delays.
- Each small box labeled
+
is the part of a full
adder that calculates the sum
s = ai + bi + ci.
Note that the carry-out is not calculated by
this box.
The box requires 2 gate delays.
- Note the division of labor:
One block calculates the p's, g's, and carries; other logic
calculates the sum.
Thus, for 4-bit addition, 5 gate delays after we are
given a, b and Carry-In, we have calculated s and Carry-Out using a
modest amount of realistic (no more than 5-input) logic.
How does the speed of this carry-lookahead adder CLA compare to our
original ripple-carry adder?
- We have just seen that a 4-bit CLA completes its calculation
in 5 gate delays.
- The ripple-carry adder is composed of 1-bit full adders (FAs).
- Each FA needs only two gate delays.
Our design used more, but we were aiming for clarity not speed.
It is a combinatorial circuit so of course theoretically it can
be done in 2 gate delays (assuming the bubbles are free) and the
design you get in this way is practical as well.
- But the calculation of bit i takes two gate
delays starting from when the calculation of the
previous bit is finished since bit i needs the CarryOut of bit
i-1 as its own CarryIn.
- Thus the time required for a 4-bit adder is 4*2=8 gate delays.
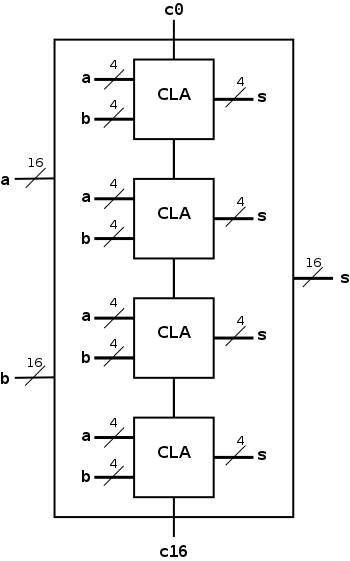
Fast Carry Using the Second Level of Abstraction
We have finished the design of a 4-bit CLA; the next goal is a
16-bit fast adder.
Let's consider, at varying levels of detail, five possibilities.
- Ripple carry.
Simple, we know it, but not fast.
- General 2 levels of logic.
Always applicable, we know it, but not practical.
- Extend the above design to 16 bits.
Possible, we could do it, but some gates have 17 inputs.
Would need a tree to reduce the input count.
- Put together four of the 4-bit CLAs.
Shown in the diagram to the right is a schematic of our 4-bit
CLA and a 16-bit adder constructed from four of them.
- As black boxes, both ripple-carry adders and
carry-lookahead adders (CLAs) look the same.
- We could simply put four CLAs together and let the
Carry-Out from one be the Carry-In of the next.
That is, we could put these CLAs together in a ripple-carry
manner to get a hybrid 16-bit adder.
- Since the Carry-Out is calculated in 3 gate delays, the
Carry-In to the high order 4-bit adder is calculated in
3*3=9 delays.
- Hence the overall Carry-Out takes time 9+3=12 and the high
order four bits of the sum take 9+5=14.
The other bits take less time.
- So this mixed 16-bit adder takes 14 gate delays compared
with 2*16=32 for a straight ripple-carry 16-bit adder.
- Note that this hybrid structure is not a
true 16-bit CLA because the 4-bit structures are ripple-carry
connected.
- Be more clever and put together the 4-bit CLAs in a
carry-lookahead manner.
One could call the result a 2-level CLA.
- We have 33 inputs a0,...,a15; b0,...b15; c0=Carry-In
- We want 17 outputs s0,...,s15; c16=c=Carry-Out
- Again we are assuming a gate can accept up to 5 inputs.
- It is important that the number of inputs per gate does not grow
with the number of bits we are adding.
- If the technology available supplies only 4-input gates (instead
of the 5-input gates we are assuming),
we would use groups of three bits rather than four.
- This will take us some time to develop and is our next goal.
Start Lecture #6
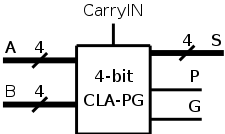
Super Propagate
and Super Generate
We start the adventure by defining super propagate
and
super generate
bits.
From these super propagates and super generates, we can calculate the
super carries, i.e. the carries for the four 4-bit adders.
- The first super carry C0, the Carry-In to the low-order 4-bit
adder, is just c0 the input Carry-In.
- The second super carry C1 is the Carry-Out of the low-order
4-bit adder (which is also the Carry-In to the 2nd 4-bit adder.
- The third super carry C2 is the Carry-Out of the second 4-bit
adder (which is also the Carry-In to the 3rd 4-bit adder.
- The forth super carry C3 is the Carry-Out of the third 4-bit
adder (which is also the Carry-In to the 4th (high-order) 4-bit
adder.
- The last super carry C4 is the Carry-out of the high-order
4-bit adder (which is also the overall Carry-out of the entire
16-bit adder).
- The corresponding logic formulas are as follows.
C1 = G0 + P0 c0
C2 = G1 + P1 C1 = G1 + P1 G0 + P1 P0 c0
C3 = G2 + P2 C2 = G2 + P2 G1 + P2 P1 G0 + P2 P1 P0 c0
C4 = G3 + P3 C3 = G3 + P3 G2 + P3 P2 G1 + P3 P2 P1 G0 + P3 P2 P1 P0 c0
But this looks terrific!
These super carries are what we need to combine four 4-bit CLAs into
a 16-bit CLA in a carry-lookhead manner.
Recall that the hybrid approach suffered because the carries from
one 4-bit CLA to the next (i.e., the super carries) were done in a
ripple carry manner.
Since it is not completely clear how to combine the pieces so far
presented to get a 16-bit, 2-level CLA, I will give a pictorial
account very soon.
Before the pictures, let's assume the pieces can be put together
and see how fast the 16-bit, 2-level CLA actually is.
Recall that we have already seen two practical 16-bit adders: A
ripple carry version taking 32 gate delays and a hybrid structure
taking 14 gate delays.
If the 2-level design isn't faster than 14 gate delays, we won't
bother with the pictures.
Remember we are assuming 5-input gates.
We use lower case p, g, and c for propagates, generates, and
carries; and use capital P, G, and C for the super- versions.
- We calculate the p's and g's (lower case) in 1 gate delay (as with
the 4-bit CLA).
- We calculate the P's one gate delay after we have the p's or
2 gate delays after we start.
- The G's are determined 2 gate delays after we have the g's and
p's.
So the G's are done 3 gate delays after we start.
- The C's are determined 2 gate delays after the P's and G's. So
the C's are done 5 gate delays after we start.
- Now the C's are sent back to the 4-bit CLAs, which have already
calculated the p's and g's.
The c's are calculated in 2 more
gate delays (7 total) and the s's 2 more after that (9 total).
Since 9<14, let the pictures begin!
- First perform minor surgery on the 4-bit CLA.
- Remove the calculation of the CarryOut, as that
calculation will be performed by a different piece of logic.
- Add logic to calculate the super propagate and super
generate bits P & G using the formulas given above.
- Label the resulting structure a 4-bit CLA-PG (not a
standard name).
- CLA-PG has 9 inputs (two 4-bit addends and a carry-in) and 6
outputs (a 4-bit sum, P, and G).
- The diagram is on the right.
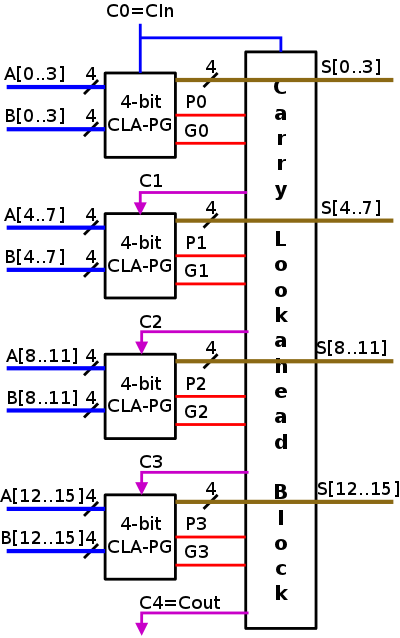
- Next put four of these 4-bit CLAs together with a Carry
Lookahead Block that calculates the C's from the P's, G's and
Cin=C0.
- The formulas for the C's are above.
- The result, which is shown on the right, is a 16-bit
(2-level) CLA!
- We will use CL Block to abbreviate Carry-Lookahead Block
(I am afraid to use CLB fearing it will be confused with
CLA).
- Note that I do not call it a 4-bit CL Block or a 16-bit CL
block.
More on this latter.
- The colors of the lines indicates when they are
calculated.
- The blue lines are inputs.
- Then the red lines are calculated.
- Then the magenta.
- Finally the brown.
- That last bullet is stated sloppily.
Gates are always calculating their
outputs from their inputs.
When we say something is calculated in k gate delays, we
mean that the outputs are correct k gate delays after the
inputs are correct.
A more accurate statement of the previous bullet would be:
- The blue lines are input, which are assumed to be
valid when we start the addition.
- The red lines are valid 3 gate delay after the blue
(actually the Ps needs only 2 gate delays, but we use
the Ps and Gs together so need to wait for the Gs).
Summary: the red lines are valid 3 gate delays after we
start
- The magenta lines are valid 2 gate delays after the
red; so they are valid 5 gate delays after the start.
- The brown lines are valid 4 gate delays after the
magenta (2 gate delays to calculate the c's—note
lower case, then two more for the Ss); so they are valid
9 gate delays after the start
- Since the magenta lines flow right to left (then down), I
drew their arrowheads.
I typically do not draw arrowheads for lines that go to the
right, go down, or go right and down.
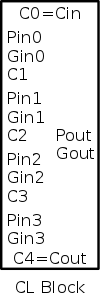
- We actually are not done with the CL Block.
Building CLAs Using the CL Block
It is time to validate the claim that all sizes of PLAs can be
build (recursively) using the CL Block.
1-bit CLA-PG
A 1-bit CLA is just a 1-bit adder.
With only one bit there is no need for any lookahead
since
there is no ripple
to try to avoid.
However, to enable us to build a 4-bit CLA from the 1-bit version,
we actually need to build what we previously called a CLA-PG.
The 1-bit CLA-PG has three inputs a, b, and cin.
It produces 4 outputs s, cout, p, and g.
We have given the logic formulas for all four outputs previously.
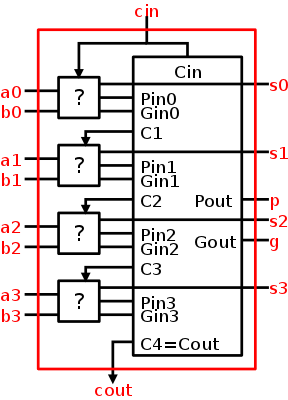
4-bit CLA-PG
A 4-bit CLA-PG is shown as the red portion in the figure to the right.
It has nine inputs: 4 a's, 4 b's, and cin and must produce seven
outputs: 4 s's, cout, p, and g (recall that the last two were
previously called the super propagate and super generate respectively).
The tall black box is our CL Block.
The question is, what must the ith ?
box do in
order for the entire (red) structure to be a 4-bit CLA-PG?
.
- The box must produce si, one bit of the desired
sum.
But this is easy since the box receives ai,
bi, and ci the carry in (c0 is cin).
- si = ai bi ci +
ai bi' ci' +
ai' bi ci' +
ai' bi' ci
- The box must produce pi and gi for the
CL Block to consume.
But that is also easy since it has as input ai and
bi.
- It looks like the ? box is just a 1-bit CLA-PG!
- Unfortunately, not quite.
The ? box is only a (large) subset of a 1-bit CLA-PG.
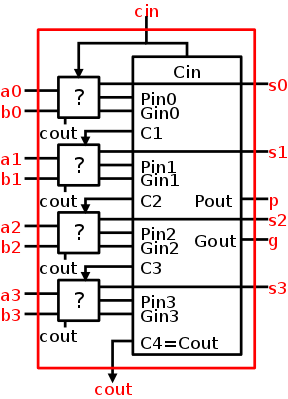
- What is missing?
- Ans.
The ? box doesn't need to produce a carry out since the larger
(4-bit) CLA-PG contains a Cl-block that produces all of them.
So, if we want to say that the 4-bit (1-level) CLA-PG is composed
of four 1-bit (0-level) CLA-PGs together with a CL Block, we must
draw the picture as on the right.
The difference is that we explicitly show that the ? box
produces cout, which is then not used.
This situation will occur for all sizes.
For example, either picture on the right for a a 4-bit
CLA-PG produces a carry out since all 4-bit full adders do so.
However, a 16-bit CLA-PG, built from four of the 4-bit units and a
CL Block, does not use the carry outs produced by the four 4-bit
units.
We have several alternatives.
- Don't mention the problem of the unused cout.
A common solution but too late for us.
- Draw the top version of the diagram (without the unused
cout's) and delcare that a CLA-PG doesn't produce a carry out.
Seems weird that a CLA-PG doesn't fully replace a full adder.
- Draw the top version of the diagram
and admit that a level k CLA-PG doesn't really use four level k-1
CLA-PG's.
- Draw the bottom version of the diagram.
- Draw the top version of the diagram, but view it as an
abbreviation of the bottom version.
This last is the alternative we will choose.
As another abbreviation, we will henceforth say CLA when we mean
CLA-PG.
Remark:
Hence the 4-bit CLA (meaning CLA-PG) is composed of
- Four 1-bit CLAs
- One CLA block
- Wires
- Nothing else
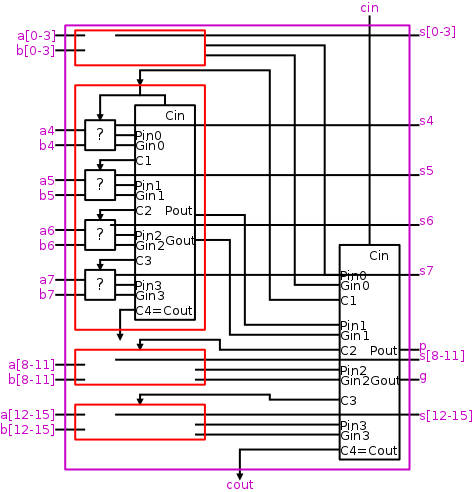
16-bit CLA-PG
Now take four of these 4-bit adders and use the
identical CL block to get a 16-bit
adder.
The picture on the right shows one 4-bit adder (the red box) in
detail.
The other three 4-bit adders are just given schematically as small
empty red boxes.
The CL block is also shown and is wired to all four 4-bit adders.
The complete (large) picture is
shown here.
Remark:
Hence the 16-bit CLA is composed of
- Four 4-bit CLAs
- One CLA block
- Wires
- Nothing else
64-bit CLA-PG
To construct a 64-bit CLA no new components are needed.
That is, the only components needed have already been constructed.
Specifically you need.
- Four magenta boxes, identical to
the one just constructed.
- One additional CL Block, identical
to the one just used to make the magenta box.
- Wires to connect these five boxes.
Remark:
Hence the 64-bit CLA (meaning CLA-PG) is composed of
- Four 16-bit CLAs
- One CLA block
- Wires
- Nothing else
When drawn (with a brown box) the 64-bit CLA-PG has 129 inputs
(64+64+1) and 67 outputs (64+1+2).
256-bit CLA-PG
- Four brown boxes, identical to
the one just constructed.
- One additional CL Block, identical
to the one just used to make the brown box.
- Wires to connect these five boxes.
Remark:
Hence the 256-bit CLA (meaning CLA-PG) is composed of
- Four 64-bit CLAs
- One CLA block
- Wires
- Nothing else
etc
Homework: How many gate delays are required for
our 64-bit CLA-PG?
How many gate delays are required for a 64-bit ripple carry adder
(constructed from 1-bit full adders)?
Summary
CLAs greatly speed up addition; the increase in speed grows with
the size of the numbers to be added.
Remark: CLAs implement n-bit
addition in O(log(n)) gate delays.
Start Lecture #7
Shifters
MIPS (and most other) processors must execute shift (and rotate)
instructions.
We could easily extend the ALU to do 1-bit shift/rotates (i.e.,
shift/rotate a 32-bit quantity by 1 bit), and then perform an n-bit
shift/rotate as n 1-bit shift/rotates.
This is not done in practice.
Instead a separate structure, called a barrel shifter is
built outside the ALU.
Remark:
Barrel shifters, like CLAs are of logarithmic complexity.
*** Big Change Coming ***
Sequential Circuits, Memory, and State
Why do we need state?
- Memory (i.e., ram not just rom or prom).
- Counters.
- Reducing gate count.
- Multiplying two n-bit numbers would require
about n2 gates if done with just
combinatorial logic (think about how you multiply n-digit
numbers.)
- With sequential logic (state), multiplication can be done
with about n gates.
- What follows is unofficial (i.e. too fast to
understand).
- Shift register holds partial sum.
- Real slick is to share this shift reg with
multiplier.
- We will do this circuit later in the course.
B.7: Clocks
Assume you have a physical OR gate.
Assume the two inputs are both zero for an hour.
At time t one input becomes 1.
The output will OSCILLATE for a while before settling on exactly 1.
We want to be sure we don't look at the answer before its ready.
This will require us to establish a clocking methodology,
i.e. an approach to determining when data is valid.
First, however, we need some ...
Terminology
Micro-, Mega-, and Friends
Nano means one billionth, i.e., 10-9.
Micro means one millionth, i.e., 10-6.
Milli means one thousandth, i.e., 10-3.
Kilo means one thousand, i.e., 103.
Mega means one million, i.e., 106.
Giga means one billion, i.e., 109.
Frequency and period
Consider the idealized waveform shown on the right.
The horizontal axis is time and the vertical axis is (say) voltage.
If the waveform repeats itself indefinitely (as the one on the
right does), it is called periodic.
The time required for one complete cycle, i.e., the
time between two equivalent points in consecutive cycles, is called
the period.

Since it is a time, period is measured in units
such as seconds, days, nanoseconds, etc.
The rate at which cycles occur is called the
frequency.
Since it is a rate at which cycles occur,
frequency is measured in units such as cycles per hour, cycles per
second, kilocycles per micro-week, etc.
The modern (and less informative) name for cycles per second is
Hertz, which is abbreviated Hz.
Prediction: At least one student will confuse frequency and periods
on the midterm or final and hence mess up a gift question.
Please, prove me wrong!.
Make absolutely sure you understand why
- A kilohertz clock is (a million times) faster
than a millihertz clock.
- A clock with a kilosecond period is (a million
times) slower than one with a millisecond period.
Edges
Look at the diagram above and note the rising edge and
the falling edge.
We will use edge-triggered logic, which means that state
changes (i.e., writes to memory) occur at a clock
edge.
For each design we choose to either
- Have all state changes occur at rising edges or
- Have all state changes occur at falling edges.
The edge on which changes occur (either the rising or falling edge)
is called the active edge.
For us, choosing which edge is active is basically a coin flip.
In real designs the choice is governed by the technology used.
Some designs permit both edges to be active.
Examples include DDR (double data rate) memory and double-pumped
register files.
This permits a portion of the design to run at effectively twice the
speed since state changes occur twice as often
Synchronous system
Now we are going to add state elements to the combinational
circuits we have been using previously.
Remember that a combinational/combinatorial circuits has its outpus
determined solely by its input, i.e. combinatorial circuits do not contain
state.

State elements include state (naturally).
- That is state elements are memory.
- State elements have clock as an input.
- These elements change state only at the active edge of the clock.
- They Always produce output, which is based on the current
state.
- All signals that are written to state elements must be valid at
the time of the active edge.
- For example, if cycle time (of the clock) is 10ns, the designer
must ensure that combinational circuit used to compute new state
values completes in 10ns.
- So state elements change at the active edge, the combinatorial circuit
stabilizes between active edges.

Combinatorial circuits can NOT contain
loops.
For example imagine an inverter with its output connected to its
input.
So if the input is false, the output becomes true.
But this output is wired to the input, which is now true.
Thus the output becomes false, which is the new input.
So the output becomes true ... .

However sequential circuits CAN and
often Do contains loops.
- Think of state elements as registers or memory.
- Can have loops like at the right.
- For example imagine the assembler instruction
add-register r1=r1+r1
The state element is register number 1 and the combinatorial
circuit is a full adder.
B.8: Memory Elements: Flip-Flops, Latches, and Registers
We will use only edge-triggered, clocked memory in our
designs as they are the simplest memory to understand.
So our current goal is to construct a 1-bit, edge-triggered, clocked
memory cell.
However, to get there we will proceed in three stages.
- We first show how to build unclocked memory.
- Then, using unclocked memory, we build
level-sensitive clocked memory.
- Finally from level-sensitive clocked memory we
build edge-triggered clocked memory.

Unclocked Memory
The only unclocked memory we will use is a so called S-R latch
(S-R stands for Set-Reset).
When we define latch
below to be a level-sensitive, clocked
memory, we will see that the S-R latch is not really a latch.
The circuit for an S-R latch is on the right.
Note the following properties.
- The S-R latch is constructed from
Cross-coupled
nor
gates.
- Consider the four possible inputs.
- We do NOT assert both S and R at the same
time (the output is not defined in this case).
- When S is asserted (i.e., S=1 and R=0):
- The latch is Set (that's why it is called S).
- Q becomes true (Q is the output of the latch).
- Q' becomes false (Q' is the complemented output).
- When R is asserted:
- The latch is Reset.
- Q becomes false.
- Q' becomes true.
- When neither one is asserted:
- The latch retains its value, i.e. Q and Q' stay as they
were.
- This last statement is the memory aspect.
Clocked Memory: Flip-flops and latches
The S-R latch defined above is UNclocked memory;
unfortunately the terminology is not perfect.
For both flip-flops and
latches the output equals the value stored in the
structure.
Both have an input and an output (and the complemented output) and a
clock input as well.
The clock determines when the internal value is set to the current
input.
For a latch, the output can change whenever the clock is asserted
(level sensitive).
For a flip-flop, changes occur only at the active edge.
D latch
The D stands for data.
Note the following properties of the D latch circuit shown on the
right.

- The left part of the circuit uses the clock;
the right part is essentially an S-R latch.
- When the clock is low, both R and S are forced low so the
outputs (Q and Q') don't change.
- When the clock is high, S=D and R=D' so the value stored is D and
Q, the output of the latch, is D.
- The output changes when input changes and the clock is
asserted, that is the latch is Level sensitive rather
than edge triggered.
The lower abbreviated diagram is how a D-latch is normally drawn.
A D latch is sometimes called a transparent latch since,
whenever the clock is high, the output equals the input (the input
passes right through the latch).
We won't use D latches in our designs, except right now to
construct our workhorse, the master-slave flip-flop, an
edge-triggered memory cell.

Note the following points illustrated by the traces to the right.
We assume the stored value was initially low.
- The output follows the input when the clock is high.
- The output remains constant when the clock is low.
D or Master-Slave Flip-flop

This structure was our goal.
It is an edge-triggered, clocked memory.
The circuit for a D flop
is on the right has the following
properties.
- The D flop is built from D latches, which are transparent.
- The flop however is NOT transparent
- Changes to the output occur only at the active edge.
- The circuit in the diagram has the falling edge as active
edge.
- Sometimes called a master-slave flip-flop, with the left latch
called the master and the right the slave.
- The substructures reuse the same letters as the main structure
but have different meaning (similar to block structured
languages in the algol style).
- The master latch is set during the time the clock is asserted.
Remember that the latch is transparent, i.e. it follows its
input when its clock is asserted.
But the second latch is ignoring its input at this time.
When the clock falls, the 2nd latch pays attention and the first
latch keeps producing whatever D was at fall-time.
- Actually D must remain constant for some time around
the active edge.
- The set-up time before the edge.
- The hold time after the edge.
- See the discussion and diagram below.

Homework:
Move the inverter to the other latch.
What has changed?
The picture on the right is for a master-slave flip-flop.
Note how much less wiggly the output is in this picture
than before with the transparent latch.
As before we are assuming the output is initially low.
The next picture shows the setup and hold times discussed above.

- It is crucial when building circuits with flip flops that D is
stable during the interval around the active edge including the
setup and hold times.
- Note that D is wild outside the critical interval, but that is
OK.
- We will not be emphasizing setup and hold requirements in this
course.
Homework:
Which code better describes a flip-flop and which a latch?
repeat {
while (clock is low) {do nothing}
Q=D
while (clock is high) {do nothing}
} until forever
or
repeat {
while (clock is high) {Q=D}
} until forever
Start Lecture #8
Registers
A register is basically just an array of D flip-flops.
For example a 32-bit register is an array of 32 D flops.
What if we don't want to write the register during a
particular cycle (i.e. at the active edge of a particular cycle)?
As shown in the diagram on the right, we introduce another input,
the write line, which is used to gate the clock
.

If the write line is high forever, the clock input to the register
is passed right along to the D flop and hence the input to the
register is stored in the D flop when the active edge occurs, which
for us the falling edge).
That is the register is written every cycle.
If the write line is low forever, the clock
to the D flop is always low so has no edges.
Thus the register is never written.
Now that we understand what happens if the write line is constant
(either always high or always low, we must ask what happens if we
change the write line (from high to low or vice versa).
We do not change the write line when the (external) clock is high
since that would cause extra edges to be passed to the D-flop.
Instead we change the write line only when the clock is low.
This, however, is not so good!
- Recall that the active edge is the falling edge.
Thus, when the clock is low, we are in the first half of the
cycle and we must have decided during this first half cycle,
whether we want to write at the end of the cycle.
That is, we have only 1/2 a cycle to decide.
- It would be better to arrange everything so that the write
line must be correct when the clock is high, i.e., during the
second half of the cycle.
Then we can use the entire cycle to decide whether to write the
register at the end of the cycle.

- Thus we can improve our register, by changing how we gate the
clock.
Instead of ANDing the clock with the write line, we OR the
clock with the complement of the write line.
In this way the write line can be changed when the
clock is high without affecting the clock to the D-flop, i.e. we
can decide whether to write the register during the second half
of the cycle.

Essentially the same affect can be achieved in another manner as
well.
Instead of having the register negate the write line, the register
specifies that the input be a don't write line, i.e.
W‾
An alternative is to use an active low write line,
i.e. have a W' (NOT W) input.
Such a register, which is depicted on the right is often call
an active low
register since it is active when its W' input
is low.

Multibit Registers
To implement a multibit register, just use multiple D flops.
- Note that the 3-bit Data input is shown both as one 3-bit line and
as three 1-bit lines.
- This dual representation is also used for the 3-bit Out line.
Register File
A register file is just a set of registers, each one numbered.

- To access a register file, you supply the register number, the
write line (asserted if a write is to be done), and, if the
write line is asserted, the data to be written.
write).
- You can read and write same register during one cycle.
You read the old value and then the written value replaces this
old value for subsequent cycles.
- Often have several read and write ports so that several
registers can be read and written during one cycle.
- We will implement 2 read ports and one write port since that
is needed for ALU ops.
This is Not adequate for superscalar (or EPIC) or any
other system where more than one operation is to be calculated
each cycle.
Reading From a Register File

To support reading a register we just need a (big) mux from the
register file to select the correct register.
- Use one big mux for each read port.
- A
big
mux means an n-input, b-bit mux, where
- n is the number of registers (32 for MIPS)
- b is the width of each register (32 for MIPS)
- As always we need ceiling(log(n)) bits for selecting which of the
n input to produce.
Writing a Register in a Register File

To support writing a register we use a decoder on the register number
to determine which
register to write.
Note that errors in the book's figure were fixed.
- The decoder is log n to n (5 to 32 for MIPS).
- The decoder outputs are numbered 0 to n-1 (NOT n).
Note also that I show the clock explicitly.
Recall that the inputs to a register are W, the write line, D the
data to write (if the write line is asserted), and the clock.
We should perform a write to register r this cycle if the write line
is asserted and the register number specified is r.
The idea is to gate the write line with the output of the decoder.
- The clock to each register is simply the clock input to the
register file.
- The data to each register is simply the write data to the
register file.
- The write line to each register is unique.
- The register number is fed to a decoder.
- The rth output of the decoder is asserted if r is the
specified register.
- Hence we wish to write register r if
- The write line to the register file is asserted
- The rth output of the decoder is asserted
- Bingo! We just need an and gate.
Start Lecture #9
Homework: B.36

SRAMS and DRAMS
- External interface is on right
- 1Mx8 means it hold 1M (million) words each 8 bits.
- Addr, D-in, and D-out are same as they were for registers.
Addr is 20 bits since 220 = 1M.
D-out is 8 bits since we have a by 8 SRAM.
- Write enable is similar to the write line (unofficial: it
is a pulse; there is no clock).
- Output enable is for the three state (tri-state) drivers
discussed just below (unofficial).
- Ignore chip enable (perfer not to have all chips enabled
for electrical reasons).
- (Sadly) we will not look inside officially.
Following is unofficial
- Conceptually, an SRAM is like a register file but we can't
use the register file implementation for a large SRAM because
there would be too many wires and the muxes would be too
big.
- We use a two stage decode.
- A 1Mx8 SRAM would need a 20-1M decoder.
- Instead the SRAM is configured internally as say thirty-two
2048x128 SRAMS.
- Pass 11 of the 20 address bits through a 11-2048
decoder and use the 2048 output wires to select the
appropriate 128-bit word from each of the sub SRAMS.
Use two of the remaining bits to select eight of the sub
SRAMS (2 bits can choose one of four 8-SRAM subsets of
the 32 sub-SRAMS).
Use the remaining 7 addr bits to select the appropriate
bit from each 128-bit word.
- Tri-state buffers (drivers) are used instead of a mux.
- I was fibbing when I said that outputs are always
either 1 or 0.
- However, we will not use tristate logic; we will use
muxes.
- DRAM uses a version of the above two stage decode.
- View the memory as an array.
- First select (and save in a
faster
memory) an
entire row.
- Then select and output only one (or a few) column(s).
- So can speed up access to elements in same row.
- SRAM and
logic
are made from similar technologies but
DRAM technology is quite different.
- So easy to merge SRAM and CPU on one chip (SRAM
cache).
- Merging DRAM and CPU is more difficult but is now being
done.
- Error Correction (Omitted)
Note: There are other kinds of
flip-flops T, J-K.
Also one could learn about excitation tables for each.
We will not cover this material (P&H doesn't either).
If interested, see Mano.
B.10: Finite State Machines (FSMs)
More precisely, we are learning about deterministic
finite state machines or deterministic finite automata (DSA).
The alternative nondeterministic finite automata (NDA) are somewhat
strange and, althought seemingly nonrealistic and of theoretical
value only, form together with DFA, what I call the
secret weapon
used in the first stage of a compiler (the
lexical analyzer).
We will do example from the one in the book (counters instead of
traffic lights).
The ideas are the same and the two generic pictures (below) apply to
both examples.
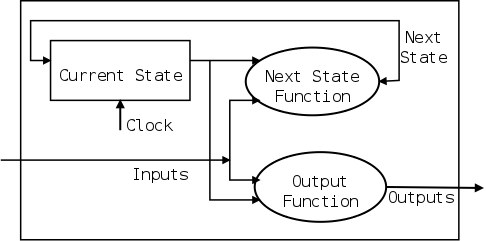

Counters

A counter counts (naturally).
- The counting is done in binary.
- The circuit increments (i.e., counts) on each clock ticks
(active edge).
- Actually it increments only on those clocks ticks when
the
increment
line is asserted.
- The state has one component, the value of the counter.
Since we are starting with a 1-bit counter, there are precisely
two states.
- There are two inputs: I and R, increment and reset.
- If reset is asserted at a clock tick, the counter is reset to
zero.
- What should we do if both R and I are
asserted?
- Probably that
shouldn't happen
.
We will accept any answer in that case (i.e., don't care).

The State Transition Diagram
- The figure shows the state transition diagram for A, the output of
a 1-bit counter.
- The circles represent states; the arcs represent transitions
from one state to another.
The label on the arc gives the condition for the transition to
apply.
For example, in state 1, if R=1, we transition to state 0.
- At each state, for each possible value of the state and inputs,
the must be a transition.
- In this implementation, if R=I=1 we choose to set A to zero.
That is, if Reset and Increment are both asserted, we do the
Reset.
The circuit diagram.

- Uses one flop and a combinatorial circuit.
- The (combinatorial) circuit is determined by the transition diagram.
- The circuit must calculate the next value of A from the current
value and I and R.
- The flop producing A is often itself called A and the D input to this
flop is then called DA.
- To fit the diagram above for FSMs, we should not draw the
overall output (A) coming from the flop (state register) but
instead from the combinational circuit (which is easy since A is
input to that circuit).
Determining the combinatorial circuit
Truth Table for the Combinatorial Circuit
| Current | | | (Next A) |
|---|
| A | I | R | DA |
|---|
|
|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 |
| x | x | 1 | 0 |
How do we determine the combinatorial circuit?
- This circuit has three inputs, I, R, and the current A.
- It has one output, DA, which is the
desired next A.
- So we draw a truth table, as before.
It is shown on the right.
- To remind us that we are using A (on this cycle) to calculate
A (on the next cycle), I labeled the A column as
current
A and added the label Next A to the DA
column.
- The table to the right was constructed directly from the truth
table.
Instead one can think about the counter and realize that
DA = R' (A ⊕ I).
A 2-bit Counter.
No new ideas are needed; just more work.
- The state diagram has 4 states 00, 01, 10, 11 and transitions from one
to another.
- The circuit diagram has 2 D-flops.
Let the top (A) flop be the high-order bit and the bottom (B) flop
the low-order bit
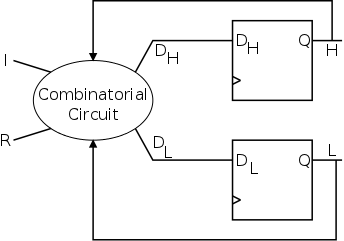

Beginning of the Truth Table for a 2-bit Counter
| Current | | |
Next |
| A | B | I | R |
DA | DB |
|
|
| x | x | x |
1 | 0 | 0 |
| 0 | 0 | 1 |
0 | 0 | 1 |
To determine the combinatorial circuit we could precede as before.
The beginning of the truth table is on the right.
This would work (do a few more rows on the board), but we can
instead think about how a counter works and see that.
DB = R'(B ⊕ I)
DA = R'(A ⊕ BI)
A 3-bit Counter
Homework: B.39
B.7 Timing Methodologies
Simulating Combinatorial Circuits at the Gate Level
The idea is, given a circuit diagram, write a program that behaves
the way the circuit does.
This means more than getting the same answer.
The program is to work the way the circuit does.
For each logic box, you write a procedure with the following properties.
- A parameters is defined for each input and output wire.
- A (local) variable is defined for each internal wire.
Really means a variable define for each signal. If a signal is
sent from one gate to say 3 others, you might not call all those
connections one wire, but it is one signal and is represented by
one variable
- The only operations used are AND OR XOR NOT
- In C or Java & | ^ !
- Other languages similar.
- Java is particularly well suited since it has variables and
constants of type Boolean.
- An assignment statement (with an operator) corresponds to a
gate.
For example A = B & C; would mean that there is an AND
gate with input wires B and C and output wire A.
- NO conditional assignment.
- NO if then else statements.
We know how to implement a mux using ANDs, ORs, and NOTs.
- Single assignment to each variable.
Multiple assignments would correspond to a cycle or to two outputs
connected to the same wire.
- A bus (i.e., a set of signals) is represented by an array.
- Testing
- Exhaustive possible for 1-bit cases.
- Cleverness for n-bit cases (n=32, say).
Simulating a Full Adder
Remember that a full adder has three inputs and two outputs.
Discuss FullAdder.c or perhaps
FullAdder.java.
Simulating a 4-bit Adder
This implementation uses the full adder code above.
Discuss FourBitAdder.c or perhaps
FourBitAdder.java
Chapter 1: Computer Abstractions and Technologies
Homework:
READ chapter 1.
Do 1.1 -- 1.228 (really one matching question)
Do 1.29 to 1.45 (another matching question),
1.46.
Chapter 2: Instructions: Language of the Machine
Homework:
Read sections 2.1, 2.1, and 2.3 (you need not worry about how a
compiler works, but you might want to).
2.4 Representing instructions in the Computer (MIPS)
The Register File
- We just learned how to build these.
- MIPS has 32 Registers, each 32 bits.
- Register 0 is always 0 when read, and stores to register 0 are
ignored.
MIPS Fields
The fields of a MIPS instruction are quite consistent
op rs rt rd shamt funct name of field
6 5 5 5 5 6 number of bits
- op is the opcode
- rs,rt are source operands
- rd is destination
- shamt is the shift amount
- funct is used for op=0 to distinguish alu ops
- alu is arithmetic and logic unit
- add/sub/and/or/not etc.
- We will see there are other formats (but similar to this one).
R-type Instructions (R for register)
Examples: add/sub $1,$2,$3
- R-type instructions use the format above.
- The first example given (add) has for its 6 fields
0--2--3--1--0--32
- op=0, signifying an alu op.
- funct=32 specifies add.
Funct determines the control bits to the alu.
- reg1 <— reg2 + reg3
- All three register numbers can be the same (this doubles the
value in the register).
- Do sub by just changing the funct.
- If the three register numbers are the same for subtract, the
instruction clears (i.e., sets to zero) the register.
Start Lecture #10
I-type (Immediate)
The I is for immediate.
- These instructions have an immediate third operand,
i.e., the third operand is contained in the instruction itself.
- This means the operand itself, and not just its address or register
number, is contained in the instruction.
- The format of an I-type instruction is
op rs rt operand
6 5 5 16
- The instruction specifies two registers and one immediate operand.
- rs is a source register.
- rt is sometimes a source and sometimes a destination register.
- Compare I and R types: Since there is no shamt and no funct,
the immediate field can be larger than the field for a register.
Load Word and Store Word
Examples: lw/sw $1,1000($2)
- The constant 1000 is the immediate operand.
- The effect of the lw example is that
register $1 is loaded with the contents of Mem[$2+1000].
- The effect of the sw example is that the value in register $1
is stored in Mem[$2+1000].
- These instructions transfer a word (32 bits) to/from memory.
- But the machine is byte addressable!
- Then how come the machine has load/store word instead of
load/store byte?
Ans: It has load/store byte as well, but we don't cover it
(it is not hard; if you are interested read section 2.8).
- What if the memory address is not a multiple of 4?
Ans: An error (MIPS requires aligned accesses).
- The machine representation is: 35/43 2 1 1000
RISC-like properties of the MIPS architecture.
- All instructions are the same length (32 bits).
- Field sizes of R-type and I-type correspond.
- The type (R-type, I-type, etc.) is determined by the opcode.
- rs is the register used in determining the reference to memory
for both load and store.
- These properties will prove helpful when we construct a MIPS
processor.
addi (add immediate)
Example: addi $1,$2,100
- The effect of the instruction is
$1 = $2 + 100
- Why is there no subi?
Ans: The immediate operand in addi can be negative.
2.5: Logical Operations
Shifts: sll and srl (shift left/right) logical
Examples sll/srl $8,$12,7
- These examples set register 2 to the value obtained by shifting
the contents of register 12 left/right 7 bits and setting the 7
rightmost/leftmost bits to 0.
Register 12 is not changed.
- Naturally the two register numbers can be the same.
- This is an R-type instruction, with shamt used and rs
not used.
- Why do we need both sll and srl,
i.e, why not just have one of them and use a negative
shift amt for the other?
Ans: The shamt is only 5 bits and need shifts from 0 to 31
bits.
Hence not enough bits for negative shifts.
- But why do we need shifts up to 31 bits?
Isn't a left shift by 26 bits the same as a right shift by 32-26=6
bits?
Ans: NO!, these are shifts not rotates.
- Op is 0.
- funct is 0/2 for sll/srl.
Bitwise AND and OR: and, or, andi, ori
No surprises.
- and $1,$2,$3
or $1,$2,$3
- Standard R-type instructions.
- andi $1,$2,100
ori $1,$2,100
- Standard I-type instructions.
Bitwise NOR (includes NOT): nor
MIPS includes a bitwise NOR (our ALU implemented it) implemented as
an R-type instruction.
- Example: nor $5,$7,$6 sets register 5 to the bitwise NOR of
registers 7 and 6.
- An important special case occurs when one of the source
operands is register 0 (which is always 0).
- Remember that A NOR 0 = NOT(A OR 0) = NOT(A).
So we get NOT for free by using register 0.
- Example: nor $7,$0,$3 sets register 7 to the complement
(technically the one's complement) of register 3.
2.6: Instructions for Making Decisions
beq and bne (branch (not) equal)
Examples: beq/bne $1,$2,123
- I-type
- if reg1=reg2 then go to the 124rd instruction after this one.
- if reg1!=reg2 then go to the 124rd instruction after this one.
- Why 124 not 123?
Ans: We will see that the CPU adds 4 to the program counter (for
the no branch case) and then adds (times 4) the third operand.
More significantly perhaps is that going to the 0th word after
this one is not especially useful.
- Normally one writes a label for the third operand and the
assembler calculates the offset needed.
slt (set less-then)
Example: slt $3,$8,$2
- An R-type instruction.
- Set register 3 to (if register8 < register2 then 1 else 0)
- Similar to other R-type instructions: slt reads the 2nd and 3rd
registers specified and writes the first.
slti (set less-then immediate)
Example: slt $3,$8,20
- An I-type instruction.
- Set register 3 to (if register 8 < 20 then 1 else 0).
- Similar to many other I-type instructions: slt reads the 2nd
register specified and writes the first.
blt (branch if less than)
Example: blt $5,$8,123
- I-type
- if reg5 < reg8 then go to the 124rd instruction after this one.
- *** WRONG ***
- There is no blt instruction.
- Instead use
stl $1,$5,$8
bne $1,$0,123
ble (branch if less than or equal)
Example: ble $5,$8,L (L a label to be calculated by the assembler.)
- Wrong!
- There is no
ble $5,$8,L
instruction.
- There is also no
sle $1,$5,$8
, set $1 if $5 less or equal $8.
- Note that $5 ≤ $8 is the same as NOT ($8 < $5).
- Hence we test for $8 < $5 and branch if false.
stl $1,$8,$5
beq $1,$0,L
bgt (branch if greater than)
Example bgt $5,$8,L
- Wrong!
- There is no
bgt $5,$8,L
instruction.
- There is also no
sgt $1,$5,$8
, set $1 if $5 greater than $8.
- Note that $5 > $8 is the same as $8 < $5.
- Hence we test for $8 < $5 and branch if true.
stl $1,$8,$5
bne $1,$0,L
bge (branch if greater than or equal)
Example: bge $5,$8,L
- Wrong!
- There is no
bge $5,$8,L
instruction.
- There is also no
sge $1,$5,$8
, set $1 if $5 greater or
equal $8l
- Note that $5 ≥ $8 is the same as NOT ($5 < $8)l
- Hence we test for $5 < $8 and branch if false.
stl $1,$5,$8
beq $1,$0,L
Note:
Please do not make the mistake of thinking that
stl $1,$5,$8
beq $1,$0,L
is the same as
stl $1,$8,$5
bne $1,$0,L
It is not the case that the negation of X<Y
is Y>X.
End of Note
J-type instructions (J for jump)
These have a different format, but again the opcode is the first 6
bits.
op address
6 26
The effect is to jump to the specified (immediate) address.
Note that there are no registers specified in this instruction
and that the target address is not relative to
(i.e. added to) the address of the current instruction as was done with
branches.
j (jump)
Example: j 10000
- Jump to instruction (not byte) 10000.
- Branches are PC relative, jumps are absolute.
- A J-type instruction.
- Range is 2^26 words = 2^28 bytes = 1/4 GB
But MIPS is a 32-bit machine with 32-bit address and we have
specified only 26 bits.
What about the other 6 bits?
In detail the address of the next instruction is calculated via a
multi-step process.
- The 26 bit address field is extracted from the instruction.
- This address is left shifted two bits.
The result is a 28-bit address (call it A) that is always a
multiple of 4, which makes sense since all instructions must
begin on a multiple of 4 bytes.
- The high order 4 bits are extracted from the
address of the current instruction
(not the address in the
current instruction).
Call this 4-bit quantity B.
- The address of the next instruction is formed by concatenating
B with A.
2.7: Supporting Procedures in Computer Hardware
jal (jump and link)
Example: jal 10000
- Jump to instruction 10000 and store the return address (the
address of the instruction after the jal).
- J type.
- Used for subroutine calls.
- The return address is stored in register 31.
By using a fixed register, jal avoids the need for a second
register field and hence can have 26 bits for the instruction
address (i.e., can be a J type).
jr (jump register)
Important example: jr $31
- Jump to the location in register 31.
- This is how to return from a subroutine called via a jal.
- R type, but uses only one register.
- Will it use one of the source registers or the destination
register?
Ans: This will be clear when we construct the processor.
Homework: 2.38
2.8: Communicating with People
Skipped.
MIPS Addressing for 32-bit Immediates and Addresses
How can we put a 32-bit value (say 2 billion) into register 6?
- Zero and add.
- Zero register 6 with sub $6,$6,$6
- then add 2 billion with addi $6,$6,2000000000.
- WRONG: 2 billion doesn't fit in the 16-bit immediate field
of an addi.
- Load the word
- Have the constant placed in the program text (via some
assembler directive).
- Issue lw to load the register.
- But memory accesses are slow and this uses a cache entry.
- Load shift add
- Load immediate the high order 16 bits (into the low order
bits of register 6)
- Shift register 6 left 16 bits (filling the low order with
zero)
- Add immediate the low order 16 bits to register 6.
- Watch out!
The add immediate might actually subtract!
- Load shift OR
- Load immediate the high order 16 bits (into the low order
bits of register 6)
- Shift register 6 left 16 bits (filling the low order with
zero)
- OR immediate the low order 16 bits to register 6.
- This works.
- But it uses three instructions and three words of memory.
We wish to improve this
lui (load upper immediate)
Example: lui $4,123
- Loads 123 into the upper 16 bits of register 4 and clears the
lower 16 bits of the register.
- An I-type instruction; rs is not used.
- This does the load and shift of the solution above.
- The combination lui followed by ori (OR immediate) solves our
problem.
Homework: 2.7.
Start Lecture #11
Chapter 3
Homework: Read 3.1-3-4
3.1: Introduction
I have nothing to add.
3.2: Signed and Unsigned Numbers
MIPS uses 2s complement (just like 8086)
To form the 2s complement (of 0000 1111 0000 1010 0000 0000 1111 1100)
- Take the 1s complement.
- That is, complement each bit (1111 0000 1111 0101 1111 1111
0000 0011)
- Then add 1 (1111 0000 1111 0101 1111 1111 0000 0100)
Need comparisons for signed and unsigned.
- For signed a leading 1 is smaller (negative) than a leading 0
- For unsigned a leading 1 is larger than a leading 0
Comments on Two's Complement
You could easily ask what does this funny notation have to do with
negative numbers.
Let me make a few comments.
- What does negative 1 mean?
Ans: It is the unique number that, when added to 1, gives zero.
- The binary number 1111...1111 has this property (using regular
n-bit addition and discarding the carry-out) so we do seem to
have -1 correct.
- Just as n+1 (for n≥0) is defined as the successor of n,
-(n+1) is the number that has -n as successor.
That is we need to show that
TwosComp(n+1) + 1 = TwosComp(n).
- This would follow if we could show
OnesComp(n+1) + 1 = OnesComp(n),
i.e, (n+1)' + 1 = n'.
- Let n be even, n = *0, * arbitrary.
- Write n', n+1 and (n+1)' and see that it works.
- Let n be odd, n = *01s1, where
1s just means a bunch of ones.
- Again it works.
- So for example TwosComp(6)+1=TwosComp(5) and hence
TwosComp(6)+6=zero, so it really is -6.
sltu and sltiu
Like slt and slti but the comparison is unsigned.
Homework: 3.1-3.6
3.3: Addition and subtraction
To add two (signed) numbers just add them.
That is, don't treat the sign bit special.
To subtract A-B, just take the 2s complement of B and add.
Overflows
An overflow occurs when the result of an operation cannot be
represented with the available hardware. For MIPS this means when the
result does not fit in a 32-bit word.
- We have 31 bits plus a sign bit.
- The result would definitely fit in 33 bits (32 plus sign)
- The hardware simply discards the carry out of the top (sign) bit
- This is not wrong--consider -1 + -1
11111111111111111111111111111111 (32 ones is -1)
+ 11111111111111111111111111111111
----------------------------------
111111111111111111111111111111110 Now discard the carry out
11111111111111111111111111111110 this is -2
- The bottom 31 bits are always correct.
Overflow occurs when the 32 (sign) bit is set to a value and not
the sign.
- Here are the conditions for overflow
Operation Operand A Operand B Result
A+B ≥ 0 ≥ 0 < 0
A+B < 0 < 0 ≥ 0
A-B ≥ 0 < 0 < 0
A-B < 0 ≥ 0 ≥ 0
- These conditions are the same as
Carry-In to sign position != Carry-Out from sign position.
Homework:
Prove this last statement (4.29) (for fun only, do not hand in).
addu, subu, addiu
These three instructions perform addition and subtraction the same way
as do add and sub, but do not signal overflow.
Shifter
This is a sequential circuit.
It is just a string of D-flops; the output of one is input of the next.
- Input to first is the serial input.
- Output of last is the serial output.
We want more.
- Left and right shifting (with serial input/output).
- Parallel load.
- Parallel Output.
- Don't shift every cycle.
Parallel output is just wires.
Shifter has 4 modes (left-shift, right-shift, nop, load) so
- 4-1 mux inside.
- 2 select lines are needed.
>We could modify our registers to be shifters (bigger mux),
but ...
Our shifters are slow for big shifts; barrel shifters
are
faster and kept separate from the processor registers.
Homework: A 4-bit shift register initially
contains 1101. It is shifted six times to the right with the serial
input being 101101.
What is the contents of the register after each shift.
Homework: Same register, same initial condition.
For the first 6 cycles the opcodes are left, left, right, nop, left,
right and the serial input is 101101.
The next cycle the register is loaded (in parallel) with 1011.
The final 6 cycles are the same as the first 6.
What is the contents of the register after each cycle?
3.4: Multiplication
Of course we can do this with two levels of logic since
multiplication is just a function of its inputs.
But just as with addition, would have a very big circuit and
large fan in.
Instead we use a sequential circuit that mimics the algorithm we
all learned in grade school.
Recall how to do multiplication.
- Multiplicand times multiplier gives product
- Multiply multiplicand by each digit of multiplier
- Put the result in the correct column
- Then add the partial products just produced
We will do it essentially the same way.
- We are doing binary arithmetic so each
digit
of the
multiplier is 1 or zero.
- Hence
multiplying
the mulitplicand by a digit of the
multiplier results in either
- Getting the multiplicand
- Getting zero
- Use an
if appropriate bit of multiplier is 1
stmt
- To get the
appropriate bit
- Start with the LOB of the multiplier
- Shift the multiplier right (so the next bit is the LOB)
- Putting in the correct column means putting it one column
further left than the last time.
- This is done by shifting the multiplicand left one bit each
time (even if the multiplier bit is zero).
- Instead of adding partial products at end, we keep a running sum.
- If the multiplier bit is zero, add the (shifted)
multiplicand to the running sum.
- If the bit is zero, simply skip the addition.
This results in the following algorithm
product ← 0
for i = 0 to 31
if LOB of multiplier = 1
product = product + multiplicand
shift multiplicand left 1 bit
shift multiplier right 1 bit
Do on the board 4-bit multiplication (8-bit registers) 1100 x 1101.
Since the result has (up to) 8 bits, this is often called a 4x4→8
multiply.
The First Attempt

The diagrams below are for a 32x32-->64 multiplier.
What about the control?
- Always give the ALU the ADD operation.
- Always send a 1 to the multiplicand to shift left.
- Always send a 1 to the multiplier to shift right
- Pretty boring so far but
- Send a 1 to write line in product if and only if
LOB multiplier is a 1
- I.e. send LOB to write line
- I.e. it really is pretty boring
This works!
But, when compared to the better solutions to come, our first
attempt is wasteful of resourses and hence is
- slower
- hotter (and uses less energy)
- bigger
- all these are bad
An Improved Circuit
The product register must be 64 bits since the product can contain 64
bits.
Why is multiplicand register 64 bits?
- So that we can shift it left.
- I.e., for our convenience.
By this I mean it is not required by the problem specification,
but only by the solution method chosen.
Why is ALU 64-bits?
- Because the product is 64 bits.
- But we are only adding a 32-bit quantity to the
product at any one step.
- Hmmm.
- Maybe we can just pull out the correct bits from the product.
- Would be tricky to pull out bits in the middle
because which bits to pull changes each step.
POOF!! ... as the smoke clears we see an idea.

We can solve both problems at once
- DON'T shift the multiplicand left
- Hence register is 32-bits, solving problem 1.
- Also the register need not be a shifter.
- Instead shift the product right!
- Add the high-order (HO) 32-bits of product register to the
multiplicand and place the result back into HO 32-bits
- Only do this if the current multiplier bit is one.
- Use the Carry Out of the sum as the new bit to shift in.
- The book forgot the last point but their example used numbers
too small to generate a carry
This results in the following algorithm
product <- 0
for i = 0 to 31
if LOB of multiplier = 1
(serial_in, product[32-63]) <- product[32-63] + multiplicand
shift product right 1 bit
shift multiplier right 1 bit
What about control?
- Just as boring as before.
- Send (ADD, 1, 1) to (ALU, multiplier (shift right), Product
(shift right)).
- Send LOB to Product (write).
Redo the same example on the board.

A final trick (gate bumming
, like code bumming
of 60s)
There is a waste of registers, i.e. they are not fully utilized..
- The multiplicand is fully unilized since we always need all
32 bits.
- But once we use a multiplier bit, we can toss it so we need
less and less of the multiplier as we go along.
- And the product is half unused at beginning and only
slowly ...
- POOF!!
Timeshare
the LO half of the product register
.
- In the beginning LO half contains the multiplier.
- Each step we shift right and more of the register goes to
product less to multiplier.
The algorithm changes to:
product[0-31] <- multiplier
for i = 0 to 31
if LOB of product = 1
(serial_in, product[32-63]) <- product[32-63] + multiplicand
shift product right 1 bit
Control again boring.
- Send (ADD, 1) to (ALU, Product (shift right)).
- Send LOB to Product (write).
Redo the same example on the board.
Signed Multiplication
The above was for unsigned 32-bit multiplication.
What about signed multiplication?
- Save the signs of the multiplier and multiplicand.
- Convert multiplier and multiplicand to non-neg numbers.
- Use above algorithm.
- Only use 31 steps not 32 since there are only 31 multiplier bits
(the HOB of the multiplier is the sign bit, not a bit used for
multiplying).
- Compliment product if original signs were different.
Faster Multipliers
There are (asymptotically) faster multipliers, but we are not
covering them.
3.5: Division
3.6: Floating Point
3.7: Real Stuff: Floating Point in the IA-32
Homework:
Read for your pleasure (not on exams)
3.8 Fallacies and Pitfalls
, 3.9 Conclusion
,
and 3.10 ``Historical Perspective'' (the last is on the CD).
Start Lecture #12
Chapter 5: The Processor: Datapath and Control
Homework: Start Reading Chapter 5.
5.1: Introduction
We are going to build
a basic MIPS processor.
Figure 5.1 redrawn below shows the main idea.

Note that the instruction gives the three register numbers as well
as an immediate value to be added.
- No instruction actually does all this.
- We have datapaths for all possibilities.
- Will see how we arrange for only certain datapaths to be used for
each instruction type.
- For example R type uses all three registers but not the
immediate field.
- The I type uses the immediate but only two registers.
- The memory address for a load or store is the sum of a register
and an immediate.
- The data value to be stored comes from a register.
- Why are we doing arithmetic on the program counter?
5.2 Logic Design Convention
Done in appendix B.

5.3: Building a Datapath
Let's begin doing the pieces in more detail.
We draw buses in magenta (mostly 32 bits) and control lines in
green.
Instruction Fetch
We are ignoring branches and jumps for now.
The diagram on the right shows the main loop
involving
instruction fetch (i-fetch)
- How come no write line for the PC register?
Ans: We write it every cycle.
- How come no write line for the instruction memory.
Ans: We don't write it (of course somehow it is written).
- How come no control for the ALU?
Ans: This one always adds.
- How come no clock lines.
Ans: Lazy; they should be drawn.

R-type instructions
We did the register file in appendix B.
Recall the following points made when discussing the appendix.
- The words
Read
and Write
in the diagram are
adjectives not verbs.
- The register file contains two read ports and one write port.
We mentioned in the appendix that this was to support MIPS
instructions that read two and write one register.
Now that we have covered the basic MIPs instructions, we know
that it is precisely the R-type instructions that have this
requirement.
- The 3-bit control line sent to the ALU consists of Bnegate and
Op.
- We learned that the RegWrite control line is asserted if
the
write register
is to be written.
We know that is always the case for R-type instructions.
The 32-bit bus with the instruction is divided into three 5-bit
buses for each register number (plus other wires not shown).
Homework: What would happen if the RegWrite line
had a stuck-at-0 fault (was always deasserted)?
What would happen if the RegWrite line
had a stuck-at-1 fault (was always asserted)?

Load and Store
The diagram on the right shows the structures used to implement
load word and store word (lw and sw).
lw $r,disp($s):
- Computes the effective address formed by adding the 16-bit
immediate constant
disp
(displacement) to the contents of
register $s.
- Fetches the value in data memory at this address.
- Inserts this value into register $r.
sw $r,disp($s):
- Computes the same effective address as lw $r,disp($s).
- Stores the contents of register $r into this address.
We have a 32-bit adder and more importantly have a 32-bit addend
coming from the register file.
Hence we need to extend the 16-bit immediate constant to 32 bits.
That is we must replicate the HOB of the 16-bit immediate constant
to produce an additional 16 HOBs all equal to the sign bit of the
16-bit immediate constant.
This is called sign extending the constant.
What about the control lines?
- RegWrite is deasserted for sw and asserted for lw.
- MemWrite is asserted for sw and deasserted for lw.
- We don't need memread since our memory (unlike real memory)
is the same as our registers.
- The ALU Operation is set to
add
for lw and sw.
- For now we just write down which control lines are asserted and
deasserted.
Later we will do the circuit to calculate the control
lines from the instruction word.
Homework: What would happen if the RegWrite line
had a stuck-at-0 fault (was always deasserted)?
What would happen if the RegWrite line
had a stuck-at-1 fault (was always asserted)?
What would happen if the MemWrite line
had a stuck-at-0 fault?
What would happen if the MemWrite line
had a stuck-at-1 fault?
The Diagram is Wrong (Specifically, Incomplete)
The diagram cheats a little for clarity.
- For lw we write register r (and read s).
- For sw we read register r (and read s).
- But we indicated that the same bits in the instruction always go to
the same ports in the register file.
- We are
mux deficient
.
Some of the time we want group A to go to the port; other times
we want group B to go to the port.
Solution: Always send group A toward the port; always send group
B toward the port; use a mux to choose which group goes there.
- We will put in the muxes later.

Branch on Equal (beq)
Compare two registers and branch if equal.
Recall the following from appendix B, where we built the ALU, and from
chapter 2, where we discussed beq.
- To check for equal we subtract and test for zero (our ALU does
this).
- The target of the branch instruction
beq $r,$s,disp
is the sum of
- The program counter PC after it has been
incremented, that is, the address of
the next sequential instruction.
- The 16-bit immediate constant
disp
(treated as a
signed number) left shifted 2 bits (because the constant
represents words and the address is
specified in bytes.
- The value of PC after the increment is available.
We computed it in the basic instruction fetch datapath.
- Since the immediate constant is signed it must be sign
extended.
As mentioned previously this is just replicating the HOB.
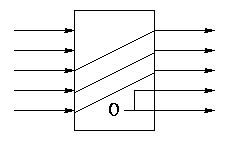
The top alu labeled add
is just an adder so does not need
any control.
The shift left 2 is not a shifter.
It simply moves wires and includes two zero wires.
We need a 32-bit version of the 5 bit version shown on the
right.
Homework: What would happen if the RegWrite line
had a stuck-at-0 fault?
What would happen if the RegWrite line had a stuck-at-1 fault?
5.4: A Simple Implementation Scheme
We will first put the pieces together and later figure out the
control lines that are needed and how to set them.
We are not now worried about speed.
We are assuming that the instruction memory and data memory are
separate.
So we are not permitting self modifying code.
We are not showing how either memory is connected to the outside
world (i.e., we are ignoring I/O).
We must use the same register file with all the pieces since when a
load changes a register, a subsequent R-type instruction must see
the change and when an R-type instruction makes a change, the lw/sw
must see it (for loading or calculating the effective address,
etc).
We could use separate ALUs for each type of instruction but we are
not worried about speed so we will use the same ALU for all
instruction types.
We do have a separate adder for incrementing the PC.
Combining R-type and lw/sw
The problem is that some inputs can come from different sources.
- For R-type instructions, both ALU operands are registers.
For I-type instructions (lw/sw) the second operand is the (sign
extended) immediate field.
- For R-type instructions, the write data comes from the ALU.
For lw it comes from the memory.
- For R-type instructions, the write register comes from field
rd, which is bits 15-11.
For sw, the write register comes from field rt, which is bits
20-16.
We will deal with the first two now by using a mux for each.
We will deal with the third shortly by (surprise) using a mux.

Including Instruction Fetch
This is quite easy.

Finally, beq
We need to have an if stmt
for PC (i.e., a mux).
You should compare this to the C-style conditional expression
exemplified by
y = (c=4) ? x+5 : z-6;

Homework:
Extend the datapath just constructed to support the addi instruction
as well as the instructions already supported.
This is essentially the datapath component of problem 5.19 from the
text.
Homework:
Extend the datapath just constructed to support a variation of the
lw instruction where the effective address is computed by adding the
contents of two registers (instead of using an immediate field).
This new instruction would be an R-type.
Continue to support all the instructions that the original datapath
supported.
This is essentially the datapath component of problem 5.22 from the
text.
Homework:
Can you support a hypothetical swap instruction that swaps the
contents of two registers using the same building blocks that we
have used to date?
Very similar to problem 5.23 from the text.
Start Lecture #13
The Control for the Datapath
We start with our last figure, which shows the data path and then
add the missing mux and show how the bits in the instruction are
divided.

We need to set the muxes.
We need to generate the four ALU cntl lines: 1-bit Anegate, 1-bit
Bnegate and 2-bit OP
AND 0 0 00
OR 0 0 01
Add 0 0 10
Sub 0 1 10
Set-LT 0 1 11
NOR 1 1 00
Homework:
What happens if we use 0 1 00 for the four ALU control lines?
What if we use 0 1 01?
What information can we use to decide on the muxes and alu cntl lines?
The instruction!
- Opcode field (6 bits).
- For R-type the funct field (6 bits).
- A total of 12 bits of information.
What must we calculate?
- The 3 ALU control lines (there really are four but we are not
supporting NOR so do not need ANegate).
- One control line for each of 4 muxes shown.
- Three for MemRead, MemWrite, and
RegWrite.
- A total of 10 or 11
So no problem, just do a truth table.
- 12 inputs so 4096 rows.
- 10 (or 11) outputs so (at least) 22 columns.
- 88K entries.
- HELP!
A Two-Stage Approach
We will let the main control (to be done later) summarize
the opcode for us.
From this summary we determine the control lines for the ALU.
Specifically, the main control will generate a 2-bit field ALUOp
ALUOp Action needed by ALU
00 Addition (for load and store)
01 Subtraction (for beq)
10 Determined by funct field (R-type instruction)
11 Not used
Start Lecture #14
MIDTERM EXAM
Start Lecture #15
Remark: Review answers for Midterm.
Controlling the ALU Given the Summary
Remark: This material is (in the 3e) in Appendix
C, section C.2.
How many entries do we have now in the truth table?
- Instead of a 6-bit opcode we have a 2-bit summary.
- We still have a 6-bit function (funct) field (needed for R-type).
- So now we have 8 inputs (2+6) and (3 or) 4 outputs.
- 256 rows, 12 columns; 3K entries.
- Certainly easy for automation ... but we will be clever.
Specifically, we will make great use of don't care
bits.
Some simplifications we can take advantage of.
| opcode | ALUOp | operation |
funct | ALU action | ALU cntl |
| LW | 00 | load word |
xxxxxx | add | 0010 |
| SW | 00 | store word |
xxxxxx | add | 0010 |
| BEQ | 01 | branch equal |
xxxxxx | subtract | 0110 |
| R-type | 10 | add |
100000 | add | 0010 |
| R-type | 10 | subtract |
100010 | subtract | 0110 |
| R-type | 10 | AND |
100100 | and | 0000 |
| R-type | 10 | OR |
100101 | or | 0001 |
| R-type | 10 | SLT |
101010 | set on less than | 0111 |
- We will not be doing NOR so
- We have only 8 MIPS instructions that use the ALU as shown
in the table on the right.
- The left bit of ALU cntl (Anegate) is not used
- The first two rows of the table above are the same.
We only need one.
- When funct is used, its two HOBs are 10 so are don't care inputs.
- ALUOp=11 impossible and hence
- 01 = X1
- 10 = 1X
Applying these simplifications yields
ALUOp | Funct || Bnegate:OP
1 0 | 5 4 3 2 1 0 || B OP
------+--------------++------------
0 0 | x x x x x x || 0 10
x 1 | x x x x x x || 1 10
1 x | x x 0 0 0 0 || 0 10
1 x | x x 0 0 1 0 || 1 10
1 x | x x 0 1 0 0 || 0 00
1 x | x x 0 1 0 1 || 0 01
1 x | x x 1 0 1 0 || 1 11
Start Lecture #16
How should we implement this?
We will do it PLA style (disjunctive normal form, 2-levels of logic).
- Produce a circuit for each of the three output bits.
- Must decide when each output bit is 1,
i.e., calculate the minterms.
- We do this one output bit at a time.
When is Bnegate (called Op2 in book) asserted?
Ans: Those rows where its bit is 1, namely rows 2, 4, and 7.
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
x 1 | x x x x x x
1 x | x x 0 0 1 0
1 x | x x 1 0 1 0
Notice that, in the 5 rows with ALUOp=1x, F1=1 is enough
to distinugish the two rows where Bnegate is asserted.
This gives
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+-------------
x 1 | x x x x x x
1 x | x x x x 1 x
Hence Bnegate is ALUOp0 + (ALUOp1 F1).
Now we apply the same technique to determine when is OP0 asserted and
begin by listing the rows where its bit is set.
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
1 x | x x 0 1 0 1
1 x | x x 1 0 1 0
Again looking at all the rows where ALUOp=1x we see
that the two rows where OP0 is asserted are characterized by
just two Function bits
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
1 x | x x x x x 1
1 x | x x 1 x x x
So OP0 is ALUOp1 F0 + ALUOp1 F3
Finally, we determine when is OP1 asserted and once again begin
by listing the rows where its bit is one.
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
0 0 | x x x x x x
x 1 | x x x x x x
1 x | x x 0 0 0 0
1 x | x x 0 0 1 0
1 x | x x 1 0 1 0
Inspection of the 5 rows with ALUOp=1x yields one F bit that
distinguishes when OP1 is asserted, namely F2=0.
Is this good luck, or well chosen funct values, or wise subset
selection by H&P?
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
0 0 | x x x x x x
x 1 | x x x x x x
1 x | x x x 0 x x

Since x 1 in the second row is really 0 1, rows 1 and 2
can be combined to give
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
0 x | x x x x x x
1 x | x x x 0 x x
Now we can use the first row to enlarge the scope of the
last row
ALUOp | Funct
1 0 | 5 4 3 2 1 0
------+------------
0 x | x x x x x x
x x | x x x 0 x x
So OP1 = NOT ALUOp1 + NOT F2
The circuit is then easy and is shown on the right.
The Main Control
Our task, illustrated in the diagram below, is to calculate 9 bits,
specifically:
- Setting the four muxes.
- Writing the registers.
- Writing the memory.
- Reading the memory (for technical reasons, would not be needed if
the memory was built from registers).
- Calculating ALUOp.

All 9 bits are determined by the opcode.
We show the logic diagram after we illustrate the operation of the
control logic.
Note that the MIPS instruction set is fairly regular.
Most of the fields we need are always in the same place in the
instruction (independent of the instruction type).
- The opcode (called Op[5-0]) is always in 31-26.
- The registers to be read are always 25-21 and 20-16 (R-type,
beq, store).
- The base register used for calculating the effective address
is always 25-21 (load store).
- The offset used for calculating the effective address is the
immediate field, which is always 15-0.
- Oops: The register to be written is sometimes 20-16 (load) and
other times 15-11 (R-type).
Hence a mux is needed
| MemRead: |
Memory delivers the value stored at the specified addr |
| MemWrite: |
Memory stores the specified value at the specified addr |
| ALUSrc: |
Second ALU operand comes from (reg-file / sign-ext-immediate) |
| RegDst: |
Number of reg to write comes from the (rt / rd) field |
| RegWrite: |
Reg-file stores the specified value in the specified register |
| PCSrc: |
New PC is Old PC+4 / Branch target |
| MemtoReg: |
Value written in reg-file comes from (alu / mem) |
We have just seen how to calculate ALUOp, the remaining 7 bits
(recall that ALUOp is 2 bits) are described in the table to the
right and their uses in controlling the datapath is shown in the
picture above.
We are interested in four opcodes.
Do a stage play
- Need
volunteers
- One for each of 4 muxes.
- One for PC reg.
- One for the register file.
- One for the instruction memory.
- One for the data memory.
- I will play the control.
- Let the PC initially be zero.
- Let each register initially contain its number (e.g. R2=2).
- Let each data memory word initially contain 100 times its address.
- Let the instruction memory contain (starting at zero).
add r9,r5,r1 r9=r5+r1 0 5 1 9 0 32
sub r9,r9,r6 0 9 6 9 0 34
beq r9,r0,-8 4 9 0 < -2 >
slt r1,r9,r0 0 9 0 1 0 42
lw r1,102(r2) 35 2 1 < 100 >
sw r9,102(r2)
- Go!
The following figures illustrate the play.
Bigger versions of the pictures are
here.
R-type Instructions




Start Lecture #17
lw Instruction





Truth Tables and the PLA
The following truth table shows the settings for the control lines
for each opcode.
This is drawn differently since the labels of what should be the
columns are long (e.g. RegWrite) and it is easier to have long
labels for rows.
| Signal | R-type | lw | sw | beq |
|---|
| Op5 | 0 | 1 | 1 | 0 |
| Op4 | 0 | 0 | 0 | 0 |
| Op3 | 0 | 0 | 1 | 0 |
| Op2 | 0 | 0 | 0 | 1 |
| Op1 | 0 | 1 | 1 | 0 |
| Op0 | 0 | 1 | 1 | 0 |
|
|
|
|
|
| RegDst | 1 | 0 | X | X |
| ALUSrc | 0 | 1 | 1 | 0 |
| MemtoReg | 0 | 1 | X | X |
| RegWrite | 1 | 1 | 0 | 0 |
| MemRead | 0 | 1 | 0 | 0 |
| MemWrite | 0 | 0 | 1 | 0 |
| Branch | 0 | 0 | 0 | 1 |
| ALUOp1 | 1 | 0 | 0 | 0 |
| ALUOp0 | 0 | 0 | 0 | 1 |
If drawn the normal way the table would look like this.
| Op5 | Op4 | Op3 | Op2 | Op1 | Op0 |
RegDst | ALUSrc | MemtoReg | RegWrite |
MemRead | MemWrite | Branch | ALUOp1 |
ALUOp0 |
|
|
| 0 | 0 | 0 | 0 | 0 | 0 |
1 | 0 | 0 | 1 | 0 | 0 |
0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 1 | 1 |
0 | 1 | 1 | 1 | 1 | 0 |
0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 1 | 1 |
X | 1 | X | 0 | 0 | 1 |
0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 |
X | 0 | X | 0 | 0 | 0 |
1 | 0 | 1 |
 Now it is straightforward to get the logic equations.
The circuit, drawn in PLA style (2-levels of logic) is shown on the
right.
Now it is straightforward to get the logic equations.
The circuit, drawn in PLA style (2-levels of logic) is shown on the
right.
Homework:
In a previous homework, you modified the datapath to support addi and
a variant of lw.
Determine the control needed for these instructions.
5.15, 5.16
Homework (part of 5.13):
Can we eliminate MemtoReg and use MemRead instead?
Homework:
Can any other control signals be eliminated?
Implementing a J-type Instruction, Unconditional Jump
Recall the jump instruction.
opcode addr
31-26 25-0
Addr is a word address; the bottom 2 bits of the PC are always 0;
and the top 4 bits of the PC are unchanged
(AFTER incrementing by 4).
This is quite easy to add and smells like a good final exam question.

What's Wrong
Some instructions are likely slower than others and we must set the
clock cycle time long enough for the slowest.
The disparity between the cycle times needed for different
instructions is quite significant when one considers implementing
more difficult instructions, like divide and floating point ops.
Actually, if we considered cache misses, which result in references
to external DRAM, the cycle time ratios exceed 100.
Possible solutions
- Variable length cycle.
How do we do it?
- Asynchronous logic
Self-timed
logic.- No clock.
Instead each signal (or group of signals) is coupled with
another signal that changes only when the first signal (or
group) is stable.
- Hard to debug.
-
Multicycle instructions.
- More complicated instructions have more cycles.
- Since only one instruction is executed at a time, can
reuse a single ALU and other resourses during different cycles.
- It is in the book right at this point but we are not
covering it now; perhaps later.
Even Faster.
- Pipeline the cycles.
- Since at one time we will have several instructions
active, each at a different cycle, the resources can't
be reused (e.g., more than one instruction might need to
do a register read/write at one
time).
- Pipelining is more complicated than the single cycle
implementation we did.
- This was the basic RISC technology on the 1980s.
- A pipelined implementation of the MIPS CPU is covered
in chapter 6.
- Multiple datapaths (superscalar).
- Issue several instructions each cycle and the hardware
figures out dependencies and only executes instructions when the
dependencies are satisfied.
- Much more logic required, but conceptually not too
difficult providing the system executes
instructions in order.
- Pretty hairy if out of order (OOO) execution
is permitted.
- Current high end processors are all OOO superscalar
(and are indeed pretty hairy).
- A very modern consideration is that performance per
transistor is going down and that it
would/might be better to have many simple processors on
a chip rather that one or a few complicated ones
- VLIW (Very Long Instruction Word)
- User (i.e., the compiler) packs several instructions
into one
superinstruction
called a very long
instruction.
- User guarentees that there are no dependencies within
a superinstruction.
- Hardware still needs multiple datapaths (indeed the
datapaths are not so different from superscalar).
- The hairy control for superscalar (especially OOO
superscalar) is not needed since the dependency checking
is done by the compiler, not the hardware.
- Was proposed and tried in 80s, but was dominated by
superscalar.
- A comeback (?) with Intel's EPIC (Explicitly Parallel
Instruction Computer) architecture.
- Called IA-64 (Intel Architecture 64-bits); the
first implementation was called Merced and now has a
funny name (Itanium).
It became available in the 1990s.
- It has other features as well (e.g. predication).
- The x86, Pentium, etc are called IA-32.
- Has not done well and appears dead/dieing.
Start Lecture #18
Chapter 4 Performance analysis
Homework:
Read Chapter 4.
4.1: Introductions
Defining Performance
Throughput measures the number of jobs
per day/second/etc that can be accomplished.
Response time measures how long an individual job
takes.
- A faster machine improves both metrics (increases throughput and
decreases response time).
- Normally anything that improves (i.e., decreases) response
time improves (i.e., increases) throughput.
- But the reverse isn't true.
For example, adding a processor likely to increase throughput
more than it decreases response time.
- We will be concerned primarily with response time.
We define Performance as 1 / Execution time.
Relative Performance
We say that machine X is n times faster than machine Y or
machine X has n times the performance of machine Y if
the execution time of a given program on X = (1/n) * the
execution time of the same program on Y.
But what program should be used for the comparison?
Various suites have been proposed; some emphasizing CPU
integer performance
, others floating point performance
,
and still others I/O performance
.
Measuring Performance
How should we measure execution time?
- CPU time.
- This includes the time waiting for memory.
- It does not include the time waiting for I/O as this
process is not running and hence using no CPU time.
- Should we include
system time
, i.e., time when the
CPU is executing the operating system
on behalf of theuser program.
- Elapsed time on an otherwise empty system.
- Elapsed time on a
normally loaded
system.
- Elapsed time on a
heavily loaded
system.
We mostly employ user-mode
CPU time, but this
does not mean the other metrics are worse.
Cycle time vs. Clock rate.
- Recall that cycle time is the length of a cycle.
- It is a unit of time.
- For modern (non-embedded) computers it is expressed
in nanoseconds, abbreviated ns,
or picoseconds, abbreviated ps.
- One nanosecond is one billionth of a second = 10-9
seconds.
- One picosecond is one trillionth of a second = 10-12
seconds.
- Other units of time are microsecond, abbreviated us, which
equals 10-6 seconds and millisecond, abbreviated ms, which
equals 10-3 seconds.
- Embedded CPUs often have their cycle times expressed in
microseconds; the time required for a single I/O (disk access)
is normally expressed in milliseconds.
- Electricity travels about 1 foot in 1ns (in normal media).
- The clock rate tells how many cycles fit into
a given time unit (normally in one second).
- So the natural unit for clock rate is cycles per second.
This used to be standard unit and was abbreviated CPS.
- However, the world has changed and the new name for the same
thing is Hertz, abbreviated Hz.
One Hertz is one cycle per second.
- For modern (non-embedded) CPUs the rate is normally expressed
in gigahertz, abbreviated GHz, which equals one billion
hertz = 109 hertz.
- For older or embedded processors the rate is normally
expressed in megahertz, abbreviated MHz, which equals
one million hertz.
What is the cycle time for a 700MHz computer?
- 700 million cycles = 1 second
- 7*108 cycles = 1 second
- 1 cycle = 1/(7*108) seconds = 10/7 *
10-9 seconds ~= 1.4ns
What is the clock rate for a machine with a 10ns cycle time?
- 1 cycle = 10ns = 10-8 seconds.
- 108 cycles = 1 second.
- Rate is 108 Hertz = 100 * 106 Hz =
100MHz = 0.1GHz.
4.2: CPU Performance and its Factors
The execution time for a given job on a given computer is
(CPU) execution time = (#CPU clock cycles required) * (cycle time)
= (#CPU clock cycles required) / (clock rate)
The number of CPU clock cycles required equals the number of
instructions executed times the average number of cycles in each
instruction.
- In our single cycle implementation, the number of cycles required
is just the number of instructions executed.
- If every instruction took 5 cycles, the number of cycles required
would be five times the number of instructions executed.
But real systems are more complicated than that!
- Some instructions take more cycles than others.
- With pipelining, several instructions are in progress at different
stages of their execution.
- With super scalar (or VLIW) many instructions are issued at once.
- Since modern superscalars (and VLIWs) are also pipelined we have
many many instructions executing at once.
Through a great many measurement, one calculates for a given machine
the average CPI (cycles per instruction).
The number of instructions required for a given program depends on
the instruction set.
For example, one x86 instruction often accomplishes more than one
MIPS instruction.
CPI is a good way to compare two implementations of the same
instruction set (i.e., the same instruction set architecture
or ISA.
IF the clock cycle is unchanged, then
the performance of a given ISA is inversely proportional to the CPI
(e.g., halving the CPI doubles the performance).
Complicated instructions take longer; either more cycles or longer cycle
time.
Older machines with complicated instructions (e.g. VAX in 80s) had
CPI>>1.
With pipelining we can have many cycles for each instruction but still
achieve a CPI of nearly 1.
Modern superscalar machines often have a CPI less than one.
Sometimes one speaks of the IPC or instructions per cycle
for
such machines.
- These machines issue (i.e., initiate) many instructions each
cycle.
- They are pipelined so the instructions don't finish for
several cycles.
- If we consider a 4-issue superscalar and assume that all
instructions require 5 (pipelined) cycles, there are up to
20=5*4 instructions in progress (often called in flight) at one
time.
Putting this together, we see that
CPU Time (in seconds) = #Instructions * CPI * Cycle_time (in seconds).
CPU Time (in ns) = #Instructions * CPI * Cycle_time (in ns).
CPU Rate (in seconds) = #Instructions * CPI / Clock_Rate (in Hz).
Do on the board the example on page 247.
Start Lecture #19
Homework:
Carefully go through and understand the example on page 247 that I
just did in class.
Homework: The next 5 problems form a set, i.e.,
the data from one applies to all the following problems.
The first three, 4.1, 4.2, and 4.3, are from the book.
Homework: If the clock rates of the machines M1
and M2 from exercise 4.1 are 1GHz and 2GHz, respectively, find the
CPI for program 1 on both machines.
Homework:
Assume the CPI for program 2 on each machine
is the same as the CPI for program 1 you calculated in the previous
problem.
What is the instruction count for program 2 on each machine?
4.3: Evaluating Performance
I have nothing to add.
4.4: Real Stuff: Two SPEC Benchmarks and the
Performance of Recent Intel Processors
4.5 Fallacies and Pitfalls
What is the MIPS rating for a computer and how useful is it?
- MIPS stands for Millions of Instructions Per Second.
- It is a unit of rate or speed (like MHz), not of time (like ns.).
- It is not the same as the MIPS computer (but the name
similarity is not a coincidence).
- The number of seconds required to execute a given (machine
language) program is
the number of instructions executed / the number executed per second.
- The number of microseconds required to execute a given program is
the number of machine language instructions executed / MIPS.
- BUT ... .
- The same program in C (or Java, or Ada, etc) might need
different number of instructions
on different computers.
For example, one VAX instruction might require 2
instructions on a power-PC and 3 instructions on a MIPS.
- The same program in C, when compiled by two different compilers
for the same computer architecture, might need to execute a
different numbers of instructions.
- Different programs may achieve different MIPS ratings on the
same architecture.
- Some programs execute more long instructions
than do other programs.
- Some programs have more cache misses and hence cause
more waiting for memory.
- Some programs inhibit full pipelining
(e.g., they may have more mis-predicted branches).
- Some programs inhibit full superscalar behavior
(e.g., they may have unhideable data dependencies).
- One can often raise the MIPS rating by adding NOPs, despite
increasing execution time.
How?
Ans. MIPS doesn't specify useful instructions and
NOPs, while perhaps useless, are nonetheless very fast.
- So, unlike MHz, MIPS is not a value that be defined for a specific
computer; it depends on other factors, e.g., language/compiler used,
problem solved, and algorithm employed.
Homework:
Carefully go through and understand the example on pages 248-249.
How about MFLOPS (Million of FLoating point OPerations per Second)?
For numerical calculations floating point operations are the
ones you are interested in; the others are overhead
(a
very rough approximation to reality).
It has similar problems to MIPS.
- The same program needs different numbers of floating point
operations on different machines (e.g., is sqrt one instruction
or several?).
- Compilers effect the MFLOPS rating.
- MFLOPS is Not as bad as MIPS since adding NOPs lowers the
MFLOPs rating.
- But you can insert unnecessary floating point ADD instructions
and this will probably raise the MFLOPS rating.
Why?
Because it will lower the percentage of overhead
(i.e.,
non-floating point) instructions.
Benchmarks are better than MIPS or MFLOPS, but still have difficulties.
- It is hard to find benchmarks that represent your future
usage.
- Compilers can be
tuned
for important benchmarks.
- Benchmarks can be chosen to favor certain architectures.
- If your processor has 256KB of cache memory and your
competitor's has 128MB, you try to find a benchmark that
frequently accesses a region of memory having size between
128MB and 256MB.
- If your 128MB cache is 2 way set associative (defined
later this semester) while your competitors 256MB cache is
direct mapped, then you build/choose a benchmark that
frequently accesses exactly two 10K arrays separated by an
exact multiple of 256KB.
4.6: Concluding Remarks
Homework:
Read this (very short) section.
Chapter 7: Memory
Homework: Read Chapter 7.
7.1: Introduction
An ideal memory is
- Big (in capacity; not physical size).
- Fast.
- Cheap.
- Impossible.
Unable to achieve the impossible ideal we use a
memory hierarchy consisting of
- Registers.
- Cache (really L1, L2, and maybe L3).
- (Central or Main) Memory.
- Disk.
- Archive (e.g. Tape).
... and try to satisfy most references in the small fast memories
near the top of the hierarchy.
There is a capacity/performance/price gap between each pair of
adjacent levels.
We will study the cache-to-memory gap.
- In modern systems there are many levels of caches so we should
study the L1-to-L2 gap, the L2-to-L3 gap, and the L3-to-memory
gap.
- Similar considerations to those we shall study apply as well
to the other gaps (e.g., memory-to-disk, where virtual memory
techniques are applied).
This last is the gap studied in OS classes such as 202/2250.
- But the terminology is often different, e.g., in architecture we
evict cache blocks or lines whereas in OS we evict pages.
- In fall 97 my OS class was studying
the same thing
at
the same time as my architecture class, but with different,
almost disjoint, terminology.
We observe empirically (and teach in OS).
- Temporal Locality: The word referenced now is likely to be
referenced again soon.
Hence it is wise to keep the currently
accessed word handy (high in the memory hierarchy) for a while.
- Spatial Locality: Words near the currently referenced
word are likely to be referenced soon.
Hence it is wise to prefetch words near the currently referenced
word and keep them handy (high in the memory hierarchy) for a
while.
A cache is a small fast memory between the
processor and the main memory.
It contains a subset of the contents of the main memory.
A Cache is organized in units of blocks.
Common block sizes are 16, 32, and 64 bytes.
This is the smallest unit we can move to/from a cache (some designs
move subblocks, but we will not discuss them).
- We view memory as organized in blocks as well.
If the block size is 16, then bytes 0-15 of memory are in block
0, bytes 16-31 are in block 1, etc.
- Transfers from memory to cache and back are one block.
- Big blocks make good use of spatial locality.
- If you remember memory management in OS, think of pages and page
frames.
- The terminology in memory management is:
Pages are
located in the big slow disk; frames are in the small fast
(main) memory.
- The terminology in caches is:
Memory blocks are
located in the big slow (main) memory; cache blocks are
located in the small fast cache.
A hit occurs when a memory reference is found in
the upper level of the memory hierarchy.
Definitions
- We will be interested in cache hits (OS courses
study page hits), when the reference is found in the cache
(OS: when found in main memory).
- A miss is a non-hit.
- The hit rate is the fraction of memory references
that are hits.
- The miss rate is 1 - hit rate, which is the
fraction of references that are misses.
- The hit time is the time required for a hit.
- The miss time is the time required for a miss.
- The miss penalty is Miss time - Hit time.
Start Lecture #20
7.2: The Basics of Caches
We start with a very simple cache organization.
One that was used on the Decstation 3100, a 1980s workstation.
- All references are for one word (not too bad).
- Cache blocks are one word long.
- This does not take advantage of spatial locality so is not
done in modern machines.
- We will soon drop this assumption.
- Each memory block can only go in one specific cache block.
- This is called a Direct Mapped organization.
- The location of the memory block in the cache (i.e., the
block number in the cache) is the memory block number modulo
the number of blocks in the cache.
- For example, if the cache contains 100 blocks, then memory
block 34452 is stored in cache block 52. Memory block 352
is also stored in cache block 52 (but not at the same time,
of course).
- In real systems the number of blocks in the cache is a
power of 2 so taking modulo is just extracting low order bits.
- Example: if the cache has 4 blocks, the location of a
block in the cache is the low order 2 bits of the block
number.
- A direct mapped cache is simple and fast, but has more
misses than
associative caches
we will study in a
little while.
>
Accessing a Cache
On the right is a pictorial example for a direct mapped cache with
4 blocks and a memory with 16 blocks.
How can we tell if a memory block is in the cache?
- We know where it will be if it is there at all.
Specifically, if memory block N is in the cache, it will be
in cache block N mod C, where C is the number of blocks in
the cache.
- But many memory blocks are assigned to that same cache block.
For example, in the diagram above all the green
blocks in memory are assigned to the one green block in the cache.
- So we need the
rest
of the address (i.e., the part lost
when we reduced the block number modulo the size of the cache)
to see if the block in the cache is the memory block of
interest.
That number is N/C, using the terminology above.
- The cache stores the rest of the address, called the
tag and we check the tag when looking for a block.
- Since C is a power of 2, the tag (N/C) is simply the high
order bits of N.
Also stored is a valid bit per cache block so that we
can tell if there is a memory block stored in this cache
block.
For example, when the system is powered on, all the cache blocks
are invalid.
| Addr(10) | Addr(2) | hit/miss | block# |
|---|
| 22 | 10110 | miss | 110 |
| 26 | 11010 | miss | 010 |
| 22 | 10110 | hit | 110 |
| 26 | 11010 | hit | 010 |
| 16 | 10000 | miss | 000 |
| 3 | 00011 | miss | 011 |
| 16 | 10000 | hit | 000 |
| 18 | 10010 | miss | 010 |
Consider the example on page 476.
- We have a tiny 8-word, direct-mapped cache with block size one
word and all memory references are for one word.
- In the table on the right, all the addresses are word
addresses.
For example the reference to 3 means the reference to word 3
(which includes bytes 12, 13, 14, and 15).
- If reference experience a miss and the cache block is valid, the
current contents of the cache block is discarded (in this example
only) and the new reference takes its place.
- Do this example on the board showing the address store in the
cache at all times

The circuitry needed for this simple cache (direct mapped, block
size 1, all references to 1 word) to determine if we have a hit or a
miss, and to return the data in case of a hit is quite easy.
We are showing a 1024 word (= 4KB) direct mapped cache with block
size = reference size = 1 word.
Make sure you understand the division of the 32 bit address into
20, 10, and 2 bits.
Calculate on the board the total number of bits in this cache.
Homework:
7.2 7.3 7.4
Processing a Read for this Simple Cache
The action required for a hit is obvious, namely return the data
found to the processor.
For a miss, the best action is fairly clear, but requires some
thought.
- Clearly we must go to central memory to fetch the requested
data since it is not available in the cache.
- The question is should we place this new data in the cache
evicting the old data (which was for
a different address, or should we keep the old
data in the cache.
- But it is clear that we want to store the new data instead of
the old.
Why?
Answer: Temporal Locality.
- What should we do with the old data.
Can we just toss it or do we need to write it back to central
memory.
Answer: It depends!
We will see shortly that the action needed on a
read miss, depends on our choice of action
for a write hit.
Handling Cache Misses
We can skip much of this section as it discusses the multicycle and
pipelined implementations of chapter 6, which we skipped.
For the single cycle processor implementation we just need to note a
few points.
- The instruction and data memory are replaced with caches.
- On cache misses one needs to fetch/store the desired
datum or instruction from/to central memory.
- This is very slow and hence our cycle time must be very
long.
- A major reason why the single cycle implementation is
not used in practice.
- The above is simplified; one could use
a
lockup-free
cache and avoid much of the problem.
Handling Writes
Processing a write for our simple cache (direct mapped with block
size = reference size = 1 word).
We have 4 possibilities: For a write hit we must choose between
Write through and Write back.
For a write miss we must choose between write-allocate and
write-no-allocate (also called store-allocate and store-no-allocate
and other names).
Write through: Write the data to
memory as well as to the cache.
Write back: Don't write to memory
now, do it later when this cache block is evicted.
The fact that an eviction must trigger a write to memory for
write-back caches explains the comment above that the write hit
policy effects the read miss policy.
Write-allocate: Allocate a slot and write the
new data into the cache (recall we have a write miss).
The handling of the eviction this allocation (probably) causes
depends on the write hit policy.
- If the cache is write through, discard the old data
(since it is in memory) and write the new data to memory (as
well as in the cache).
- If the cache is write back, the old data must now be
written back to memory, but the new data is not
written to memory.
Write-no-allocate: Leave the cache alone and
just write the new data to memory.
Write no-allocate is not normally as effective as write allocate
due to temporal locality.
The simplest policy is write-through, write-allocate.
The decstation 3100 discussed above adopted this policy and
performed the following actions for any write, hit or miss, (recall
that, for the 3100, block size = reference size = 1 word and the
cache is direct mapped).
- Index the cache using the correct LOBs (i.e., not the very
lowest order bits as these give the byte offset).
- Write the data and the tag into the cache.
- For a hit, we are overwriting the tag with itself.
- For a miss, we are performing a write allocate and, since
the cache is write-through, memory is guaranteed to be
correct so we can simply overwrite the current entry.
- Set Valid to true.
- Send request to main memory.
Although the above policy has the advantage of simplicity,
it is out of favor due to its poor performance.
- For the GCC benchmark 11% of the operations are stores.
- If we assume an infinite speed central memory (i.e., a
zero miss penalty) or a zero miss rate, the CPI is 1.2 for
some reasonable estimate of instruction speeds.
- If we assume a 10 cycle store penalty (conservative) since
we have to write main memory (recall we are using a
write-through cache), then the
CPI becomes 1.2 + 10 * 11% = 2.5, which is
half speed.
Improvement: Use a Write Buffer
- Hold a few writes at the processor while they are being
processed at memory.
- As soon as the word is written into the write buffer, the
instruction is considered complete and the next instruction can
begin.
- Hence the write penalty is eliminated as long as the word can be
written into the write buffer.
- Must stall (i.e., incur a write penalty) if the write buffer is
full.
This occurs if a bunch of writes occur in a short period.
- If the rate of writes is greater than the rate at which memory
can handle writes, you must stall eventually.
The purpose of a write-buffer (indeed of buffers in general) is to
handle short bursts.
- The Decstation 3100 (which employed the simple cache structure
just described) had a 4-word write buffer.
- Note that a read miss must check the write buffer.
Unified vs Split I and D (Instruction and Data) Caches
Given a fixed total size (in bytes) for the cache, is it better to
have two caches, one for instructions and one for data; or is it
better to have a single unified
cache?
- Unified is better because it automatically performs
load balancing
.
If the current program needs more data references than
instruction references, the cache will accommodate.
Similarly if more instruction references are needed.
- Split is better because it can do two references at once (one
instruction reference and one data reference).
- The winner is ...
split I and D (at least for L1).
- But unified has the better (i.e. higher) hit ratio.
- So hit ratio is not the ultimate measure of
good cache performance.
Start Lecture #21
Remark: Demo of tristate drivers in logisim
(controlled registers).

Improvement: Multiword Blocks
The setup we have described does not take any advantage of spatial
locality.
The idea of having a multiword block size is to bring into the cache
words near the referenced word since, by spatial locality, they are
likely to be referenced in the near future.
We continue to assume (for a while) that the cache is direct mapped
and that all references are for one word.
The terminology for byte offset
and block offset
is
inconsistent.
The byte offset gives the offset
of the byte within the word so the
offset of the word within the block should be
called the word offset, but alas it is not in both the 2e and 3e.
I don't know if this is standard (poor) terminology or a long
standing typo in both editions.
The figure to the right shows a 64KB direct mapped cache with
4-word blocks.
What addresses in memory are in the block and where in the cache
do they go?
- The word address = the byte address / number of bytes per word
= the byte address / 4
for the 4-byte words we are assuming.
- The memory block number =
the word address / number of words per block =
the byte address / number of bytes per block.
- The cache block number =
the memory block number modulo the number of blocks in the cache.
- The block offset (i.e., word offset) = the word address modulo
the number of words per block.
- The tag = the memory block number / the number of blocks in
the cache =
the word address / the number of words in the cache =
the byte address / the number of bytes in the cache
Show from the diagram how this gives the red portion for the tag
and the green portion for the index or cache block number.
Consider the cache shown in the diagram above and a reference to
word 17003.
- 17003 / 4 gives 4250 with a remainder of 3 .
- So the memory block number is 4250 and the block offset is 3.
- 4K=4096 and 4250 / 4096 gives 1 with a remainder of 154.
- So the cache block number is 154 and the tag is 1.
- Summary: Memory word 17003 resides in word 3 of cache block
154 with tag 154 set to 1.
The cache size is the size of the data portion
of the cache (normally measured in bytes).
For the caches we have see so far this is the Blocksize times the
number of entries.
For the diagram above this is 64KB.
For the simpler direct mapped caches blocksize = wordsize so the
cache size is the wordsize times the number of entries.
Let's compare the pictured cache with another one containing 64KB
of data, but with one word blocks.
- Calculate on the board the total number of bits in each cache;
this is not simply 8 times the cache size in
bytes.
- If the references are strictly sequential the pictured cache
has 75% hits; the simpler cache with one word blocks
has no hits.
How do we process read/write hits/misses for a cache with multiword
blocks?
- Read hit: As before, return the data found to the
processor.
- Read miss: As before, due to locality we discard (or write
back depending on the policy) the old line and fetch the new
line.
- Write hit: As before, write the word in the cache (and perhaps
write memory as well depending on the policy).
- Write miss: A new consideration arises.
As before we might or might not decide to replace the current
line with the referenced line and, if we do decide to replace
the line, we might or might not have to write the old line back.
The new consideration is that if we decide to replace the line
(i.e., if we are implementing store-allocate), we must remember
that we only have a new word and the unit of
cache transfer is a multiword line.
- The simplest idea is to fetch the entire old line and
overwrite the new word.
This is called write-fetch and is something
you wouldn't even consider with blocksize = reference size =
1 word.
Why?
Answer: You would be fetching the one word that you want to
replace so you would fetch and then discard the entire
fetched line.
- Why, with multiword blocks, do we fetch the whole line
including the word we are going to overwrite?
Answer.
The memory subsystem probably can't fetch just words
1,2, and 4 of the line.
- Why might we want store-allocate and
write-no-fetch?
- Ans: Because a common case is storing consecutive words:
With store-no-allocate all are misses and with
write-fetch, each store fetches the line to
overwrite another part of it.
- To implement store-allocate-no-write-fetch (SANF), we need
to keep a valid bit per word.
Homework:
7.9, 7.10, 7.12.
Why not make block size enormous?
For example, why not have the cache
be one huge block.
- NOT all access are sequential.
- With too few blocks misses go up again.
Memory Support for Wider Blocks
Recall that our processor fetches one word at a time and our memory
produces one word per request.
With a large blocksize cache the processor still requests one word
and the cache responds with one word.
However the cache requests a multiword block from memory and to date
our memory is only able to respond with a single word.
The question is, "Which pieces and buses should be narrow (one word)
and which ones should be wide (a full block)?".
The same question arises when the cache requests that the memory
store a block and the answers are the same so we will only consider
the case of reading the memory).

- Should memory be wide?
That is, should the memory have enough pins so that the entire
block is produced at once.
- Should the bus from the cache to the processor be wide?
Since the processor is only requesting a single word, a wide cache
to processor bus seems silly.
The processor would contain a mux to discard the other words (you
could imagine a buffer to store the entire block acting as a kind
of L0 cache, but this would not be so useful if the L1 cache was
fast enough).
- Assume
- 1 clock required to send the address.
This is valid since only one address is needed per access for
all designs.
- 15 clocks are required for each memory access (independent
of width).
Today the number would likely be bigger than 15, but it would
remain independent of the width
- 1 Clock is required to transfer each busload of data.
- How long does it take satisfy a read miss for the cache above and
each of the three memory/bus systems.
- The narrow design (a) takes 65 clocks: 1 address transfer, 4 memory
reads, 4 data transfers (do it on the board).
- The wide design (b) takes 17.
- The interleaved design (c) takes 20.
- Interleaving works great because in this case we are
guaranteed to have sequential accesses.
- Imagine a design between (a) and (b) with a 2-word wide
datapath.
It takes 33 cycles and is more expensive to build than (c).
Homework: 7.14
Start Lecture #22
7.3: Measuring and Improving Cache Performance
Do the following performance example on the board.
It would be an appropriate final exam question.
- Assume
- 5% I-cache misses.
- 10% D-cache misses.
- 1/3 of the instructions access data.
- The CPI = 4 if the miss penalty is 0.
A 0 miss penalty is not realistic of course.
- What is the CPI if the miss penalty is 12?
- What is the CPI if we upgrade to a double speed cpu+cache, but
keep a single speed memory (i.e., a 24 clock miss penalty)?
- How much faster is the
double speed
machine?
It would be double speed if the miss penalty were 0 or if there
was a 0% miss rate.
Homework: 7.17, 7.18.
A lower base (i.e. miss-free) CPI makes stalls appear more
expensive since waiting a fixed amount of time for the
memory corresponds to losing more instructions if the CPI
is lower.
A faster CPU (i.e., a faster clock) makes stalls appear more
expensive since waiting a fixed amount of time for the memory
corresponds to more cycles if the clock is faster (and hence more
instructions since the base CPI is the same).
Another performance example.
- Assume
- I-cache miss rate 3%.
- D-cache miss rate 5%.
- 40% of instructions reference data.
- miss penalty of 50 cycles.
- Base CPI is 2.
- What is the CPI including the misses?
- How much slower is the machine when misses are taken into account?
- Redo the above if the I-miss penalty is reduced to 10 (D-miss
still 50)
- With I-miss penalty back to 50, what is performance if CPU (and the
caches) are 100 times faster
Remark:
Larger caches have longer hit times.
Reducing Cache Misses by More Flexible Placement of Blocks
Improvement: Associative Caches
Consider the following sad story.
Jane has a cache that holds 1000 blocks and has a program that only
references 4 (memory) blocks, namely 23, 1023, 123023, and 7023.
In fact the references occur in order: 23, 1023, 123023, 7023, 23,
1023, 123023, 7023, 23, 1023, 123023, 7023, 23, 1023, 123023, 7023,
etc.
Referencing only 4 blocks and having room for 1000 in her cache,
Jane expected an extremely high hit rate for her program.
In fact, the hit rate was zero.
She was so sad, she gave up her job as webmistress, went to medical
school, and is now a brain surgeon at the mayo clinic in Rochester
MN.
So far We have studied only direct mapped caches,
i.e. those for which the location in the cache is determined by the
address.
Since there is only one possible location in the cache for any
block, to check for a hit we compare one tag with
the HOBs of the addr.
The other extreme is fully associative.
- A memory block can be placed in any cache block.
- Since any memory block can be in any cache block, the cache
index where the memory block is stored tells us nothing about
which memory block is stored there.
Hence the tag must be the entire address.
Moreover, we don't know which cache block to check so we must
check all cache blocks to see if we have a hit.
- The larger tag is a problem.
- The search is a disaster.
- It could be done sequentially (one cache block at a time),
but this is much too slow.
- We could have a comparator with each tag
and mux all the blocks to select the one that matches.
- This is too big due to both the many comparators and
the humongous mux.
- However, it is exactly what is done when implementing
translation lookaside buffers (TLBs), which are used with
demand paging.
- Are the TLB designers magicians?
Ans: No.
TLBs are small.
- An alternative is to have a table with one entry per
memory block telling if the memory block is in
the cache and if so giving the cache block number.
This is too big and too slow for caches but is exactly what is
used for demand paging (recall 202) where the memory blocks
here correspond to pages on disk and the table is called the
page table.
Set Associative Caches
Most common for caches is an intermediate configuration called
set associative or n-way associative (e.g., 4-way
associative).
The value of n is typically 2, 4, or 8.
If the cache has B blocks, we group them into B/n
sets each of size n.
Since an n-way associative cache has sets of size n blocks, it is
often called a set size n cache.
For example, you often hear of set size 4 caches.
In a set size n cache,
memory block number K is stored in set K mod the number of sets,
which equals K mod (B/n).

- In the picture on the right we are trying to store memory
block 12 in each of three caches.
- Figure 7.13 in the book, from which my figure was taken, has a
bug.
Figure 7.13 indicates that the tag for memory block 12 is 12 for
each associativity.
The figure to the right corrects this.
- The light blue represents cache blocks in which the memory
block might have been stored.
- The dark blue is the cache block in which the memory block
is stored.
- The arrows show the blocks (i.e., tags) that must be searched
to look for memory block 12. Naturally the arrows point to the
blue blocks.
The figure above shows a 2-way set associative cache.
Do the same example on the board for 4-way set associative.
Determining the Set Number and the Tag.
Recall that for the a direct-mapped cache, the cache index gives
the number of the block in the cache.
The for a set-associative cache, the cache index gives the number
of the set.
Just as the block number for a direct-mapped cache is the memory
block number mod the number of blocks in the cache, the set number
equals the (memory) block number mod the number of sets.
Just as the tag for a direct mapped cache is the memory block
number divided by the number of blocks, the tab for a
set-associative cache is the memory block number divided by the
number of sets.
Do NOT make the mistake of thinking that a set
size 2 cache has 2 sets, it has B/2 sets each of size 2.
Ask in class.
- What is another name for an 8-way associative cache having 8
blocks?
- What is another name for a 1-way set associative cache?
Why is set associativity good?
For example, why is 2-way set associativity better than direct
mapped?
- Consider referencing two arrays of size 50K that start at
location 1MB and 2MB.
- Both will contend for the same cache locations in a direct
mapped 128K cache but will fit together in any 128K n-way
associative cache with n>=2.

Locating a Block in the Cache
How do we find a memory block in a set associative cache with
block size 1 word?
- Divide the memory block number by the number of sets to get
the tag.
This portion of the address is shown in red in the diagram.
- Mod the memory block number by the number of sets to get the
tag.
This portion of the address is shown in green.
- Check all the tags in the set against the tag
of the memory block.
- If any tag matches, a hit has occurred and the
corresponding data entry contains the memory block.
- If no tag matches, a miss has occurred.
Recall that a 1-way associative cache is a direct mapped cache and
that an n-way associative cache for n the number of blocks in the
cache is a fully associative.
The advantage of increased associativity is normally an increased
hit ratio.
What are the disadvantages?
Answer: It is a slower and a little bigger due to the extra logic.
Combining Set-associativity and Multiword Blocks
This is a fairly simple merger.
- Start with the picture just above for a set-associative cache.
- The blue is now a block not just a word.
- Hence the
data
coming out of the bottom right is a
block.
- So use the word-within-block bits to choose the proper word.
- This requires the same mux as it did for direct mapped
caches (with multiword blocks).
See the description and
picture here.
- We discuss below which bits
of the memory address are used for which purpose.
Choosing Which Block to Replace
When an existing block must be replaced, which victim should we
choose?
We ask the exact same question (with different words) when we study
demand paging (remember 202!).
- The victim must be in the same set as the new block.
With direct mapped (1-way associative) caches, this determined
the victim so the question didn't arise.
- With a fully associative cache all resident blocks are
candidate victims.
This is exactly the situation for demand paging (with global
replacement policies) and is also the case for
(fully-associative) TLBs.
- Random is sometimes used, i.e. choose a random block in the
set as the victim.
- This is never done for demand paging.
- For caches, however, the number of blocks in a set is
small, so the likely difference in quality between the best
and the worst is less.
- For caches, speed is crucial so we have no time for
calculations, even for misses.
-
LRU is better, but is not easy to do quickly.
- If the cache is 2-way set associative, each set is of size
two and it is easy to find the lru block quickly.
How?
Ans: For each set keep a bit indicating which block in the set
was just referenced and the lru block is the other one.
- If the cache is 4-way set associative, each set is of size
4.
Consider these 4 blocks as two groups of 2.
Use the trick above to find the group most recently used and
pick the other group.
Also use the trick within each group and chose the block in
the group not used last.
- Sound great.
We can do lru fast for any power of two using a binary tree.
- Wrong!
The above is not LRU it is just an approximation.
Show this on the board.
Sizes
There are two notions of size.
-
The cache size is the capacity of the cache.
This means, the size of all the blocks.
In the diagram above it is the size of the blue portion.
The size of the cache in the diagram is 256 * 4 * 4B = 4KB.
- Another size is is the total number of bits
in the cache, which includes tags and valid bits.
For the diagram this is computed as follows.
- The 32 address bits contain 8 bits of index and 2 bits
giving the byte offset.
- So the tag is 22 bits (more examples just below).
- Each block contains 1 valid bit, 22 tag bits and 32 data
bits, for a total of 55 bits.
- There are 1K blocks.
- So the total size is 55Kb (kilobits).
For the diagrammed cache, what fraction of the bits are user data?
Ans: 4KB / 55Kb = 32Kb / 55Kb = 32/55.
Tag Size and Division of the Address Bits
We continue to assume a byte addressed machines with all references
to a 4-byte word.
The 2 LOBs are not used (they specify the byte within the word, but
all our references are for a complete word).
We show these two bits in dark blue.
We continue to assume 32 bit addresses so there are 230
words in the address space.
Let's review various possible cache organizations and determine for
each how large is the tag and how the various address bits are used.
We will consider four configurations each a 16KB cache.
That is the size of the data portion of the cache
is 16KB = 4 kilowords = 212 words.

Direct Mapped, Block Size 1 (Word)
- Since the blocksize is one word, there are 230 memory
blocks and all the address bits (except the blue 2 LOBs that
specify the byte within the word) are used for the memory block
number.
Specifically 30 bits are so used.
- The cache has 212 words, which is 212
blocks.
- So the low order 12 bits of the memory block number give the
index in the cache (the cache block number), shown in green.
- The remaining 18 (30-12) bits are the tag, shown in red.
Direct Mapped, Block 8
- Three bits of the address give the word within the 8-word block.
These are drawn in magenta.
- The remaining 27 HOBs of the memory address give the memory
block number.
- The cache has 212 words, which is 29
blocks.
- So the low order 9 bits of the memory block number gives the
index in the cache.
- The remaining 18 bits are the tag
4-Way Set Associative, Block Size 1
- Blocksize is 1 so there are 230 memory blocks and 30
bits are used for the memory block number.
- The cache has 212 blocks, which is 210
sets (each set has 4=22 blocks).
- So the low order 10 bits of the memory block number gives the
index in the cache.
- The remaining 20 bits are the tag.
- As the associativity grows, the tag gets bigger.
Why?
Ans: Growing associativity reduces the number of sets into which a
block can be placed.
This increases the number of memory blocks eligible to be placed
in a given set.
Hence more bits are needed to see if the desired block is there.
4-Way Set Associative, Block Size 8
- Three bits of the address give the word within the block.
- The remaining 27 HOBs of the memory address give the memory
block number.
- The cache has 212 words = 29 blocks =
27 sets.
- So the low order 7 bits of the memory block number gives the
index in the cache.
- The remaining 20 bits form the tag.
Homework: 7.46 and 7.47.
Note that 7.46 contains a typo !!
should be ||
.
Reducing the Miss Penalty Using Multilevel Caches
Improvement: Multilevel caches
Modern high end PCs and workstations all have at least two levels
of caches: A very fast, and hence not very big, first level (L1) cache
together with a larger but slower L2 cache.
When a miss occurs in L1, L2 is examined and only if a miss occurs
there is main memory referenced.
So the average miss penalty for an L1 miss is
(L2 hit rate)*(L2 time) + (L2 miss rate)*(L2 time + memory time)
We are assuming that L2 time is the same for an L2 hit or L2 miss
and that the main memory access doesn't begin until the L2 miss has
occurred.
Do the example on the board (a reasonably exam question, but a
little long since it has so many parts).
- Assume
- L1 I-cache miss rate 4%
- L1 D-cache miss rate 5%
- 40% of instructions reference data
- L2 miss rate 6%
- L2 time of 15ns
- Memory access time 100ns
- Base CPI of 2
- Clock rate 400MHz
- How many instructions per second does this machine execute?
- How many instructions per second would this machine execute if
the L2 cache were eliminated?
- How many instructions per second would this machine execute if
both caches were eliminated?
- How many instructions per second would this machine execute if
the L2 cache had a 0% miss rate (L1 as originally specified)?
- How many instructions per second would this machine execute if
both L1 caches had a 0% miss rate?
Start Lecture #23

7.4: Virtual Memory
I realize this material was covered in operating systems class
(V22.0202).
I am just reviewing it here.
The goal is to show the similarity to caching, which we just
studied.
Indeed, (the demand part of) demand paging is caching: In
demand paging the memory serves as a cache for the disk, just as in
caching the cache serves as a cache for the memory.
The names used are different and there are other differences as well.
| Cache concept | Demand paging analogue |
|---|
| Memory block | Page |
| Cache block | Page Frame (frame) |
| Blocksize | Pagesize |
| Tag | None (table lookup) |
| Word in block | Page offset |
| Valid bit | Valid bit |
| Miss | Page fault |
| Hit | Not a page fault |
| Miss rate | Page fault rate |
| Hit rate | 1 - Page fault rate |

| Cache concept | Demand paging analogue |
|---|
| Placement question | Placement question |
| Replacement question | Replacement question |
| Associativity | None (fully associative) |
- For both caching and demand paging,
the placement question is trivial since the items
are fixed size (no first-fit, best-fit, buddy, etc).
- The replacement question is not trivial.
(P&H list this under the placement question, which I believe
is in error).
Approximations to LRU are popular for both caching and demand
paging.
- The cost of a page fault vastly exceeds the cost of a cache miss
so it is worth while in paging to slow down hit processing to
lower the miss rate.
Hence demand paging is fully associative and uses a table to
locate the frame in which the page is located.

- The figures to the right are for demand paging. But they can be
interpreted for caching as well.
- The (virtual) page number is the memory block number
- The Page offset is the word-in-block
- The frame (physical page) number is the cache block number
(which is the index into the cache).
- Since demand paging uses full associativity, the tag is the
entire memory block number.
Instead of checking every cache block to see if the tags
match, a (page) table is used.
Homework: 7.32
Write Through vs. Write Back
Question: On a write hit should we write the new
value through to (memory/disk) or just keep it in
the (cache/memory) and write it back to
(memory/disk) when the (cache-line/page) is replaced?
- Write through is simpler since write back requires two operations
at a single event.
- But write-back has fewer writes to (memory/disk) since multiple
writes to the (cache-line/page) may occur before the (cache-line/page)
is evicted.
- For caching the cost of writing through to memory is probably less
than 100 cycles so with a write buffer the cost of write through is
bearable and it does simplify the situation.
- For paging the cost of writing through to disk is on the order of
1,000,000 cycles.
Since write-back has fewer writes to disk, it is used.

Translation Lookaside Buffer (TLB)
A TLB is a cache of the page table.
- It is needed because otherwise every memory reference in the
program would require two memory references, one to read the
page table and one to read the requested memory word.
- Typical TLB parameter values
- Size: hundreds of entries.
- Block size: 1 entry.
- Hit time: 1 cycle.
- Miss time: tens of cycles.
- Miss rate: Low (<= 2%).
- In the diagram on the right:
- The green path is the fastest (TLB hit).
- The red is the slowest (page fault).
- The yellow is in the middle (TLB miss, no page fault).
- Really the page table doesn't point to the disk block for
an invalid entry, but the effect is the same.

Putting it together: TLB + Cache
This is the decstation 3100
- Virtual address = 32 bits.
- Physical address = 32 bits.
- Fully associative TLB.
- Direct mapped cache.
- Cache blocksize = one word.
- Pagesize = 4KB = 2^12 bytes.
- Cache size = 16K entries = 64KB.
Actions taken
- The page number is searched in the fully associative TLB
- If a TLB hit occurs, the frame number from the TLB together
with the page offset gives the physical address.
A TLB miss causes an exception to reload the TLB from the page
table, which the figure does not show.
- The physical address is broken into a cache tag and cache
index (plus a two bit byte offset that is not used for word
references).
- If the reference is a write, just do it without checking for a
cache hit (this is possible because the cache is so simple as we
discussed previously).
- For a read, if the tag located in the cache entry specified by the
index matches the tag in the physical address, the referenced word has
been found in the cache; i.e., we had a read hit.
- For a read miss, the cache entry specified by the index is fetched
from memory and the data returned to satisfy the request.
Hit/Miss possibilities
| TLB | Page | Cache | Remarks |
|---|
| hit | hit | hit |
Possible, but page table not checked on TLB hit, data from cache |
| hit | hit | miss |
Possible, but page table not checked, cache entry loaded from
memory
|
| hit | miss | hit |
Impossible, TLB references in-memory pages |
| hit | miss | miss |
Impossible, TLB references in-memory pages |
| miss | hit | hit |
Possible, TLB entry loaded from page table, data from cache |
| miss | hit | miss |
Possible, TLB entry loaded from page table, cache entry loaded
from memory
|
| miss | miss | hit |
Impossible, cache is a subset of memory |
| miss | miss | miss |
Possible, page fault brings in page, TLB entry loaded, cache
loaded
|
Homework: 7.31, 7.33
7.5: A Common Framework for Memory Hierarchies
Question 1: Where can/should the block be placed?
This question has three parts.
- In what slot are we able to place the block.
- For a direct mapped cache, there is only one choice.
- For an n-way associative cache, there are n choices.
- For a fully associative cache, any slot is permitted.
- The n-way case includes both the direct mapped and fully
associative cases.
- For a TLB any slot is permitted. That is, a TLB is a
fully associative cache of the page table.
- For paging any slot (i.e., frame) is permitted.
That is, paging uses a fully associative mapping (via a page
table).
- For segmentation, any large enough slot (i.e., region) can
be used.
- If several possible slots are available, which one should
be used?
- I call this question the placement question.
- For caches, TLBs and paging, which use fixed size
slots, the question is trivial; any available slot is just
fine.
- For segmentation, the question is interesting and there
are several algorithms, e.g., first fit, best fit, buddy,
etc.
- If no possible slots are available, which victim should be chosen?
- I call this question the replacement
question.
- For direct mapped caches, the question is trivial. Since
the block can only go in one slot, if you need to place the
block and the only possible slot is not available, it must
bethe victim.
- For all the other cases, n-way associative caches (n>1),
TLBs paging, and segmentation, the question is interesting
and there are several algorithms, e.g., LRU, Random, Belady
min, FIFO, etc.
- See question 3, below.
Question 2: How is a block found?
| Associativity | Location method | Comparisons Required |
| Direct mapped | Index | 1 |
| Set Associative | Index the set, search among elements |
Degree of associativity |
| Full | Search all cache entries |
Number of cache blocks |
| Separate lookup table | 0 |
Typical sizes and costs
| Feature |
Typical values
for caches |
Typical values
for demand paging |
Typical values
for TLBs |
| Size | 8KB-8MB | 128MB-8GB | 128B-4KB |
| Block size | 32B-128B | 4KB-64KB | 4B-32B |
| Miss penalty in clocks | 10-100 | 1M-10M | 10-100 |
| Miss rate | .1%-10% | .000001%-.0001% | .01%-2% |
The difference in sizes and costs for demand paging vs. caching,
leads to different algorithms for finding the block.
Demand paging always uses the bottom row with a separate table (page
table) but caching never uses such a table.
- With page faults so expensive, misses must be reduced as much as
possible.
Hence full associativity is used.
- With such a large associativity (fully associative
with many slots), hardware would be prohibitively
expensive and software searching too slow.
Hence a page table is used with a TLB acting as a
cache.
- The large block size (called the page size) means that the extra table
is a small fraction of the space.
Question 3: Which block should be replaced?
This is called the replacement question and is much
studied in demand paging (remember back to 202).
- For demand paging, with miss costs so high and associativity so
large, the replacement policy is very important and some approximation
to LRU is used.
- For caching, even the miss time must be small so simple schemes
are used. For 2-way associativity, LRU is trivial. For higher
associativity (but associativity is never very high) crude
approximations to LRU may be used and sometimes even random
replacement is used.
Question 4: What happens on a write?
Write-Through
- Data written to both the cache and main memory (in general to
both levels of the hierarchy).
- Sometimes used for caching, never used for demand paging.
- Advantages
- Misses are simpler and cheaper (no copy back).
- Easier to implement, especially for block size 1, which we
did in class.
- For blocksize > 1, a write miss is more complicated since
the rest of the block now is invalid.
Fetch the rest of the block from memory (or mark those parts
invalid by extra valid bits--not covered in this course).
Homework: 7.41
Write-Back
- Data only written to the cache.
The memory has stale data, but becomes up to date when the cache
block is subsequently replaced in the cache.
- Only real choice for demand paging since writing to the lower
level of the memory hierarch (in this case disk) is so slow.
- Advantages
- Words can be written at cache speed not memory speed
- When blocksize > 1, writes to multiple words in the cache
block are only written once to memory (when the block is
replaced).
- Multiple writes to the same word in a short
period are written to memory only once.
- When blocksize > 1, the replacement can utilize a high
bandwidth transfer. That is, writing one 64-byte block is
faster than 16 writes of 4-bytes each.
Write Miss Policy (Advanced)
- For demand paging, the case is pretty clear.
Every implementation I know of allocates frame for the page miss
and fetches the page from disk.
That is it does both an allocate and a
fetch.
- For caching this is not always the case. Since there are two
optional actions there are four possibilities.
- Don't allocate and don't fetch: This is sometimes called
write around.
It is done when the data is not expected to be read before
it will be evicted.
For example, if you are writing a matrix whose size is much
larger than the cache.
- Don't allocate but do fetch: Impossible, where would you
put the fetched block?
- Do allocate, but don't fetch: Sometimes called
no-fetch-on-write.
Also called SANF (store-allocate-no-fetch).
Requires multiple valid bits per block since the
just-written word is valid but the others are not (since we
updated the tag to correspond to the just-written word).
- Do allocate and do fetch: The normal case we have been
using.
Start Lecture #24
Chapter 8: Storage, Networks, and Other Peripherals.
Introduction
Peripherals are varied; indeed they vary widely in many dimensions,
e.g., cost, physical size, purpose, capacity, transfer rate,
response time, support for random
access, connectors, and
protocol.
Consider just transfer rate for the moment.
- Some devices like keyboards and mice have tiny data rates.
- Printers, etc have moderate data rates.
- Disks and fast networks have high data rates.
- A good graphics card and monitor has a huge data rate.
The text mentions three especially important dimensions.
- Input vs. output vs. storage.
A keyboard is an input device (meaning the device produces data
that is input by the processor).
A printer is an output device (meaning ...).
A disk is a storage device (meaning it can be read, reread,
written, and rewritten.
- Used directly by a human (e.g. a monitor)?
- Transfer rate.
8.2: Disk Storage and Dependability
Devices are quite varied and their data rates vary enormously.
Show a real disk opened up and illustrate the components.
- Platter
- Surface
- Head
- Track
- Sector
- Cylinder
- Seek time
- Rotational latency
- Transfer time
Disk Access Time
The time for a disk access has five components, of which we
concentrate on the first three.
- Seek.
- Rotational latency.
- Transfer time.
- Controller overhead.
- Queuing delays.
Seek Time
Today seek times are typically 5-10ms on average
.
It takes longer to go all the way across the disk but it
does not take twice as long to go twice as far (the
head must accelerate, decelerate, and settle on the track).
How should we calculate the average?
- Add the times for all possible seeks and divide by the number
of possible seeks (of course!).
- But systems achieve average seek times much
smaller than this.
How?
- Locality of reference!
So most seeks are small.
The locality is further enhanced by disk scheduling algorithms.
- Caches (again)!
Disks have (electronic, not mechanical) caches.
Rotational Latency
Since disks have just one arm the average rotational latency is
half the time of a revolution, and is thus determined by the RPM
(revolutions per minute) of the disk.
Disks today spin at 5400-15,000 RPM; they used to all spin at 3600
RPM.
Transfer Time
You might consider the other three times all overhead since it is
the transfer time during which the data is actually being supplied.
The transfer rate is typically a few tens of MB
per second.
Given the rate, which is determined by the disk in use, the transfer
time is proportional to the length of the request.
Some manufacturers quote a much higher rate, but that is for cache
hits.
In addition to supplying data much sooner, the electronic cache can
transfer data at a higher rate than the mechanical disk.
Start Lecture #25
Remark: Lab 7, the finale, is assigned and is due
10 december 2007.
Remark: Reviewed set associative caches (which
were taught the day before thanksgiving to very few students).
Start Lecture #26
Remark: I expect the final exam to be on the 7th
floor like the midterm.
A practice final is on the web.
Remark:
Covered Tag Size and Division of Address Bits
which was
inadvertently omitted.
Controler Time
Not much to say.
It is typically small.
We will use 0ms (i.e., ignore this time).
Queuing Delays
This can be the largest component, but we will
ignore it since it is not a function of the architecture, but rather
of the load and OS.
Dependability, Reliability, and Availability
Reliability measures the length of time during
which services is continuously delivered as expected.
An example reliability measure is mean time to
failure (MTTF), which measures the average length of time that
the system is delivering service as expected.
Bigger values are better.
Another important measure is mean time to
repair (MTTR), which measures how long the system is not
delivering service as expected.
Smaller values are better.
Finally we have mean time between failures
(MTBF).
MTBF = MTTF + MTTR.
One might think that having a large MTBF is good, but that
is not necessarily correct.
Consider a system with a certain MTBF and simply have the repair
center deliberately add an extra 1 hour to the repair time and poof
the MTBF goes up by one hour!
RAID
The acronym was coined by Patterson and his students.
It stands for Redundant Array of Inexpensive Disks.
Now it is often redefined as Redundant Array of Independent Disks.
RAID comes in several flavors often called levels.
No Redundancy (RAID 0)
The base, non-RAID, case from which the others are built.
Mirroring (RAID 1)
Two disks containing the same content.
- You read from either; in particular concurrent reads of
different blocks are possible.
- You a block write to both disks, possibly concurrently.
- The storage overhead is 100%, i.e. the required storage is
doubled.
Error Detecting and Correcting Code (RAID 2)
Often called ECC (error correcting code or error
checking and correcting code).
Widely used in RAM, not used in RAID.
Bit-Interleaved Parity (RAID 3)
Normally byte-interleaved or several-byte-interleaved.
For most applications, RAID 4 is better.
Block-Interleaved Parity (RAID 4)
Striping a.k.a. Interleaving
To increase performance, rather than reliability
and availability, it is a good idea to stripe or interleave blocks
across several disks.
In this scheme block n is stored on disk n mod k, where k is the
number of disks.
The quotient n/k is called the stripe number.
For example, if there are 4 disks, stripe number 0 (the first
stripe) consists of block 0, which is stored on disk 0, block 1
stored on 1, block 2 stored on 2, and block 3 stored on 3.
Stripe 1 (like all stripes in this example) also contains 4 blocks.
The first one is block 4, which is stored on disk 0.
Striping is especially good if one is accessing full stripes in
which case all the blocks in the stripe can be read concurrently.
RAID 4
RAID 4 combines striping and parity.
In addition to the k so-called data disks used in striping, one has
a single parity disk that contains the parity of the stripe.
Consider all k data blocks in one stripe.
Extend this stripe to k+1 blocks by including the corresponding
block on the parity disk.
The block on the parity disk is calculated as the bitwise exclusive
OR of the k data blocks.
Thus a stripe contains k data blocks and one parity block, which is
the exclusive OR of the data blocks.
The great news is that any block in the stripe,
parity or data, is the exclusive OR of the other k.
This means we can survive the failure of any one disk.
For example, let k=4 and let the data blocks be A, B, C, and D.
- If the parity disk fails, we can easily recreate it since, by
definition, the parity block for this stripe is
A ⊕ B ⊕ C ⊕ D
which is the exclusive OR of the other blocks.
- If a data disk fails, we can again recreate it since, by the
commutative and associative properties of XOR,
A ⊕ B ⊕ C ⊕ the parity block =
A ⊕ B ⊕ C ⊕ (A ⊕ B ⊕ C ⊕ D)
= D
and again the missing block is the exclusive OR of the remaining
blocks.
Properties of RAID 4.
- The storage overhead is 1/k.
- ONE failure can be tolerated.
- Failure means detectable failure (disks are good at this).
- A bad disk can be recreated from the remaining disks (and
RAID controllers do this on line).
- In normal operation (i.e., all disks good), reads are not
affected by the redundancy.
In this respect RAID 4 is just like striping.
- When writing a full stripe, the system
calculates the new parity block from the new data blocks and
writes the entire stripe.
- When writing a single block, RAID 4 performs
poorly since it must read additional blocks to determine the new
parity.
- One way would be to read the remaining k-1 data blocks
and calculate the parity as usual.
- There is a better (slightly clever) way.
- If block A is to be changed to A', just read (the old) A
and the old parity P.
The new parity is
A ⊕ A' ⊕ P
- All writes require reading and writing the parity disk, which
becomes a bottleneck and motivates ...
Distributed Block-Interleaved Parity RAID 5
Rotate the disk used for parity.
Again using our 4 data-disk example, we continue to put the parity
for blocks 0-3 on disk 4 (the fifth disk) but
rotate the assignment of which disk holds the parity block of
different stripes.
In more detail.
- For the first stripe block 0 is on 0, 1 is on 1, 2 is on 2, 3
is on 3, and parity is on 4.
- For the next stripe (data blocks 4-7), we put the parity on the
fourth disk so block 4 is on disk 0, 5 is on 1,
6 is on 2, parity is on 3, and 7 is on 4.
- For the next stripe, we put the parity on
the third disk so 8 is on 0, 9 is on 1, parity
is on 2, 10 is on 3, and 11 is on 4.
- etc
Raid 1 and Raid 5 are widely used.
P + Q Redundancy (RAID 6)
Gives more than single error correction at a higher storage
overhead
.
Start Lecture #27
8.3 Networks
Skipped.
(It is on the CD.)
8.4: Buses and Other Connections between Processors, Memory, and
I/O Devices
A bus is a shared communication link, using one set of wires to
connect many subsystems.
- Sounds simple (once you have tri-state drivers) ...
- ... but it's not.
- There are very serious electrical considerations (e.g. signals
reflecting from the end of the bus).
We have ignored (and will continue to ignore) all electrical
issues.
- Getting high speed buses is state-of-the-art engineering.
Tri-state Drivers
- A output device that can either
- Drive the line to 1.
- Drive the line to 0.
- Not drive the line at all (be in a high impedance state).
- It is possible have many of these devices devices connected to
the same wire providing you are careful to be sure that all but
one are in the high-impedance mode.
- This is why a single bus can have many output devices attached
(but only one actually performing output at a given time).

Bus Basics
- Buses support bidirectional transfer, sometimes using separate
wires for each direction, sometimes not.
- Normally the processor-memory bus (a.k.a memory bus) is kept
separate from the I/O bus.
It is a fast synchronous bus (see next section)
and I/O devices can't keep up.
- Indeed the memory bus is normally custom designed (i.e., companies
design their own).
- The graphics bus is also kept separate in modern designs for
bandwidth reasons, but is an industry standard (the so called AGP
bus).
- Many I/O buses are industry standards (ISA, EISA, SCSI, PCI) and
support open architectures, where components can
be purchased from a variety of vendors.
- The processor memory bus has the highest bandwidth, the
backplane bus less and the I/O buses the least.
Clearly the (sustained) bandwidth of each I/O bus is limited by
the backplane bus.
Why?
Because all the data passing on an I/O bus must also pass on the
backplane bus.
- Bus adaptors are used as interfaces between buses.
They perform speed matching and may also perform buffering, data
width matching, and converting
between synchronous and
asynchronous buses (see next section).
Synchronous vs. Asynchronous Buses
A synchronous bus is clocked.
- One of the lines in the bus is a clock that serves as the clock
for all the devices on the bus.
- All the bus actions are done on fixed clock cycles.
For example, 4 cycles after receiving a request, the memory
delivers the first word.
- This can be handled by a simple finite state machine (FSM).
Basically, once the request is seen everything works one clock at
a time.
There are no decisions like the ones we will see for an
asynchronous bus.
- Because the protocol is so simple, it requires few gates and is
very fast.
So far so good.
- Two problems with synchronous buses.
- All the devices must run at the same speed.
- The bus must be short due to
clock skew.
- Processor to memory buses are now normally synchronous.
- The number of devices on the bus are small.
- The bus is short.
- The devices (i.e. processor and memory) are prepared to
run at the same speed.
- High speed is crucial.

An asynchronous bus is not clocked.
- Since the bus is not clocked devices of varying speeds can be on the
same bus.
- There is no problem with clock skew (since there is no clock).
- But the bus must now contain control lines to coordinate
transmission.
- Common is a handshaking protocol.
We now describe a protocol in words (below) and with a finite
state machine (on the right) for a device to obtain
data from memory.
The book uses a different form of diagram and is not as explicit
about the address.
- The device makes a request (asserts ReadReq and puts the
desired address on the data lines).
The name data lines sounds odd since it is (now) being used for
the address.
It will also be used for the data itself in this design.
Data lines should be contrasted with control lines (such as
ReadReq).
- Memory, which has been waiting, sees ReadReq, records the
address and asserts Ack.
- The device waits for the Ack; once seen, it drops the
data lines and deasserts ReadReq.
- The memory waits for the request line to drop.
Then it can drop Ack (which it knows the device has now seen).
The memory now at its leasure puts the data on the data lines
(which it knows the device is not driving) and then asserts
DataRdy.
(DataRdy has been deasserted until now).
- The device has been waiting for DataRdy.
It detects DataRdy and records the data.
It then asserts Ack indicating that the data has been read.
- The memory sees Ack and then deasserts DataRdy and releases the
data lines.
- The device seeing DataRdy low deasserts Ack ending the show.
Note that both sides are prepared for another performance.

The Buses and Networks of the Pentium 4
For a realistic example, on the right is a diagram adapted from
the 25 October 1999 issue of Microprocessor Reports on a
then brand new Intel chip set, the so called 840.
Figure 8.11 in the text shows a 2003 chipset (the date is from
http://www.karbosguide.com/books/pcarchitecture/chapter22.htm).
I deliberately kept my diagram of the 4 year older 810 so that you
can see the changes in 4 years.
If you look at 2007 PCs you will see that the speeds have again
increased.
Bus adaptors have a variety of names, e.g. host adapters, hubs,
bridges.
The memory controller hub is often call the north bridge and the I/O
controller hub is often called the south bridge.
Bus lines (i.e., wires) include those for data, function codes,
device addresses.
Data and address are considered data and the function codes are
considered control (remember our datapath for MIPS).
Address and data may be multiplexed on the same lines (i.e., first
send one then the other) or may be given separate lines.
One is cheaper (good) and the other has higher performance (also
good).
Which is which?
Ans: the multiplexed version is cheaper.
Improving Bus Performance
These improvements mostly come at the cost of increased expense and/or
complexity.
- A multiplicity of buses as in the diagrams above.
- Synchronous instead of asynchronous protocols.
Synchronous is actually simplier, but it essentially implies a
multiplicity of buses, since not all devices can operate at the
same speed.
- Wider data path: Use more wires, send more data at one time.
- Separate address and data lines: Same as above.
- Separate wires for each direction.
- Block transfers: Permit a single transaction to transfer more
than one busload of data.
Saves the time to release and acquire the bus, but the protocol
is more complex.
Obtaining bus access
- The simplest scheme is to permit only one bus
master.
- That is, on each bus only one device is permited to
initiate a bus transaction.
- The other devices are slaves that only
respond to requests.
- With a single master, there is no issue of arbitrating among
multiple requests.
- The example we just did had only one master (all requests
initiated on the left).
- One can have multiple masters with daisy
chaining of the grant line.
- Any device can assert the request line, indicating that it
wishes to use the bus.
- This is not trivial: uses
open collector drivers
.
- If no output drives the line, it will be
pulled up
to
5v, i.e., a logical true.
- If one or more outputs drive the line to 0v it will go to
0v (a logical false).
- So if a device wishes to make a request it drives the
line to 0v; if it does not wish to make a request it does
nothing.
- This is (another example of) active low logic.
The request line is asserted by driving it low.
- When the arbiter sees the request line asserted (and the
previous grantee has issued a release), the arbiter raises the
grant line.
- Note that the arbiter does not know which
device has made the request; it knows only that a request has
been made.
- The grant signal is passed from one device to another if the
first device is not requesting the bus.
Hence devices near the arbiter have priority and can starve
the ones further away.
- The device whose request is granted asserts the release line
when done.
- Simple, but not fair and not of high performance.
- Centralized parallel arbiter: Separate request lines from each
device and separate grant lines.
The arbiter decides which device should be granted the
bus.
- Distributed arbitration by self-selection: Requesting
processes identify themselves on the bus and decide individually
(and consistently) which one gets the grant.
- Distributed arbitration by collision detection: Each device
transmits whenever it wants, but detects collisions and retries.
The original ethernet uses this scheme (but modern switched
ethernets do not).
Cost Performance Tradeoffs
| Option | High performance | Low cost |
|---|
| bus width | separate addr and data lines |
multiplex addr and data lines |
| data width | wide | narrow |
| transfer size | multiple bus loads |
single bus loads |
| bus masters | multiple | single |
| clocking | synchronous | asynchronous |
Start Lecture #28
Do on the board the following example.
Given
- The memory and bus support two widths of data transfer: 4
words and 16 words.
- The bus is synchronous.
- 200MHz clock.
- 1 clock to send address.
- 1 clock to send data.
- Two clocks of
rest
between bus accesses.
- Memory access times: 4 words in 200ns; each additional 4 words
in 20ns.
- The system can overlap transferring data with reading more
data.
Find
- Sustained bandwidth and latency for reading 256 words using
4 word transfers.
- Sustained bandwidth and latency for reading 256 words using
16 word transfers.
- How many bus transactions per sec for each (a transaction
includes both address and data.
Solution with four word blocks.
- 1 clock to send addr.
- 40 clocks to read the memory.
- 2 clocks to send data.
- 2 idle clocks.
- 45 total clocks for one transaction.
- 256/4=64 transactions needed so latency is 64*45*5ns=14.4us.
- Bandwidth = 1024 bytes per 14.4us = 71.11MB/sec
- 64 transactions per 14.4us gives 4.44 megatransactions per sec.
Solution with sixteen word blocks
- 1 clock for addr.
- 40 clocks for reading first 4 words.
- 2 clocks to send.
- 2 clocks idle.
- 4 clocks to read next 4 words.
But this is free! Why?
Because it is done during the send and idle of previous
block.
- So the only memory access time we wait for is the long initial
read.
- Total = 1 + 40 + 4*(2+2) = 57 clocks.
- 256/16=16 transactions needed so latency is 57*16*5ns=4.56ms.
- This is much better than with 4 word blocks.
- 16 transactions per 4.56us = 3.51M transactions/sec.
- Bandwidth = 1024B per 4.56ms = 224.56MB/sec.
8.5: Interfacing I/O Devices to the Processor, Memory, and Operating
System
This is an I/O issue and is taught in 202.
Giving commands to I/O Devices
This is really an OS issue.
Must write/read to/from device registers, i.e. must communicate
commands to the controller.
Note that a controller normally contains a microprocessor, but
when we say the processor, we mean the central processor not the
one on the controller.
- The controler has a few registers that can be read and/or
written by the processor, similar to how the processor reads
and writes memory.
These registers are also read and written by the controller.
- Nearly every controler contains
- A data register, which is readable (by the processor)
for an input device (e.g., a simple keyboard), writable
for an output device (e.g., a simple printer), and both
readable and writable for input/output devices (e.g.,
disks).
- A control register for giving commands to the device.
- A readable status register for reporting errors and
announcing when the device is ready for the next action
(e.g., for a keyboard telling when the data register is
valid, and for a printer telling when the character to be
printed has be successfully retrieved from the data
register).
Remember the communication protocol we studied where ack
was used.
- Many controllers have more registers
Communicating with the Processor
Should we check periodically or be told when there is something
to do?
Better yet can we get someone else to do it since we are not
needed for the job?
- We get mail at home once a day.
- At some business offices mail arrives a few times per day.
- No problem checking once an hour for mail.
- If email wasn't buffered, you would have to check several
times per minute (second?, millisecond?).
- Checking email this often is too much of a burden and most of the
time when you check you find there is none so the check was wasted.
Polling
Processor continually checks the device status to see if action is
required.
- Like the mail example above.
- For a general purpose OS, one needs a timer to tell the
processor it is time to check (OS issue).
- For an embedded system (microwave) make the checking part of
the main control loop, which is guaranteed to be executed at a
minimum frequency (application software issue).
- For a keyboard or mouse, which have very low data rates, the
system can afford to have the main CPU check.
We do an example just below.
- It is a little better for slave-like output devices such as
a simple printer.
Then the processor only has to poll after a request has been
made until the request has been satisfied.
Do on the board the example on pages 676-677
- Cost of a poll is 400 clocks.
- CPU is 500MHz.
- How much of the CPU is needed to poll
- A mouse that requires 30 polls per sec?
- A floppy that sends 2 bytes at a time and achieves
50KB/sec?
- A hard disk that sends 16 bytes at a time and achieves
4MB/sec?
- For the mouse, we use 12,000 clock cycles each second sec for
polling.
The CPU runs at 500*106 cycles/sec.
So polling the mouse requires 12/500*10-3 =
2.4*10-5 of the CPU.
A very small penalty.
- The floppy delivers 25,000 (two byte) data packets per second
so we must poll at that rate not to miss one.
CPU cycles needed each second is (400)(25,000)=107.
This represents 107 / 500*106 = 2% of the
CPU.
- To keep up with the disk requires 250K polls/sec or
108 clock cycles or 20% of the CPU.
- The system need not poll the floppy and disk until the CPU had
issues a request.
But then it must keep polling until the request is satisfied.
Interrupt driven I/O
Processor is told by the device when to look.
The processor is interrupted by the device.
- Dedicated lines (i.e. wires) on the bus are assigned for
interrupts.
- When a device wants to send an interrupt it asserts the
corresponding line.
- The processor checks for interrupts after each instruction.
This requires
zero time
as it is done in parallel with
the instruction execution.
- If an interrupt is pending (i.e., if a line is asserted) the
processor (this is mostly an OS issue, covered in 202).
- Saves the PC and perhaps some registers.
- Switches to kernel (i.e., privileged) mode.
- Jumps to a location specified in the hardware (the
interrupt handler).
At this point the OS takes over.
- What if we have several different devices and want to do
different things depending on what caused the interrupt?
- Use vectored interrupts.
- Instead of jumping to a single fixed location, the
system defines a set of locations.
- The system might have several interrupt lines.
If line 1 is asserted, jump to location 100, if line 2 is
aserted jump to location 200, etc.
- Alternatively, the system could have just one line and
have the device send the addressto jump to.
- There are other issues with interrupts that are taught in
OS.
For example, what happens if an interrupt occurs while an
interrupt is being processed.
For another example, what if one interrupt is more important
than another.
These are OS issues and are not covered in this course.
- The time for processing an interrupt is typically longer
than the type for a poll.
But interrupts are not generated when the device is
idle, a big advantage.
Do on the board the example on pages 681-682.
- Same hard disk and processor as above.
- Cost of servicing an interrrupt is 500 cycles.
- The disk is active only 5% of the time.
- What percent of the processor would be used to service the
interrupts?
- Cycles/sec needed for processing interrupts while the disk
is active is 125 million.
- This represents 25% of the processor cycles available.
- But the true cost is only 1.25%, since the disk is active
only 5% of the time.
- Note that the disk is not active (i.e., actively generating
interrupts) right after the request is made.
Interrupts are not generated during the seek and rotational
latency.
They are generated only during the transfer itself.

Direct Memory Access (DMA)
The processor initiates the I/O operation then something
else
takes care of it and notifies the processor when it is
done (or if an error occurs).
- Have a DMA engine (a small processor) on the controller.
- The processor initiates the DMA by writing the command into
data registers on the controller (e.g., read sector 5, head 4,
cylinder 123 into memory location 34500).
- For commands that are longer than the size of the data
register(s), a protocol must be used to transmit the
information.
- (I/O done by the processor as in the previous methods is
called programmed I/O, PIO).
- The controller collects data from the device and then sends
it on the bus to the memory without bothering the CPU.
- So we have a multimaster bus and need some sort of
arbitration.
- Normally the I/O devices are given higher priority than
the CPU.
- Freeing the CPU from this task is good but isn't as
wonderful as it seems since the memory is busy (but cache
hits can be processed).
- A big gain is that only one bus transaction is needed
per bus load.
With PIO, two transactions are needed: controller to
processor and then processor to memory.
- This was for an input operation (the controller writes
to memory).
A similar situation occurs for output where the controller
reads from the memory).
Once again one bus transaction per bus load.
- When the controller detects that the I/O is complete or if
an error occurs, it sets the status register accordingly and
sends an interrupt to the processor to notify the latter that
the I/O is complete.
More Sophisticated Controllers
- Sometimes called
intelligent
device controlers, but I
prefer not to use anthropomorphic terminology.
- Some devices, for example a modem on a serial line, deliver
data without being requested to.
So a controller may need to be prepared for unrequested
data.
- Some devices, for example an ethernet, have a complicated
protocol so it is desirable for the controller to process some
of that protocol.
In particular, the collision detection and retry with
exponential backoff characteristic of (non-switched) ethernet
requires areal program.
- Hence some controllers have microprocessors on board that
handle much more than block transfers.
- In the old days there were I/O channels, which would execute
programs written dynamically by the main processor.
For the modern controllers, the programs are fixed and loaded in
ROM or PROM.
Subtleties involving the memory system
- Having the controller simply write to memory doesn't update
the cache.
Must at least invalidate the cache line.
- Having the controller simply read from memory gets old values
with a write-back cache.
Must force write backs.
- The memory area to be read or written is specified by the
program using virtual addresses.
But the I/O must actually go to physical addresses.
Need helpfrom the MMU.
8.6: I/O Performace Measures: Examples from Disk and File Systems
Transaction Processing I/O Benchmarks
File System and Web I/O Benchmarks
I/O Performance versus Processor Performance
We do an example to illustrate the increasing impact of I/O time.
It is similar to the one in the book.
Assume
- A job currently takes 100 seconds of CPU time and 50 seconds
of I/O time.
- The CPU and I/O times can not be overlapped.
Thus the total time required is 150 seconds.
- The CPU speed increases at a rate of 40% per year.
This implies that the CPU time required in year n+1 is (1/1.4)
times the CPU time required in year n.
- The I/O speed increases at a rate of 10% per year.
Calculate
- The CPU, I/O, and overall time required after 1,2,5,10,20 years.
- The percentage of the job time that the CPU is active for each
year.
- The CPU, I/O, and overall speedup for each year.
What would happen if CPU and I/O can be overlapped, i.e., if the
overall time is MAX(CPU,I/O) rather than SUM(CPU,I/O)?
8.7: Designing an I/O system
We do an example similar to the one in the book to see how the
various components affect overall performance.
Assume a system with the following characteristics.
- A CPU that executes 300 million instructions/sec.
- 50K (OS) instructions required for each I/O.
- A Backplane bus (on which all I/O travels) that supports a
data rate of 100MB/sec.
- Disk controllers supporting a data rate of 20MB/sec and
accommodating up to 7 disks.
- Disks with bandwidth 5MB/sec and seek plus rotational latency
of 10ms.
Assume a workload of 64-KB reads and 100K instructions between
reads.
Find
- The maximum I/O rate achievable.
- How many controllers are needed for this rate?
- How many disks are needed for this rate?
Solution
- One I/O plus the user's code between I/Os takes 150,000
instructions combined.
- So the CPU limits us to 2000 I/O per sec.
- The backplane bus limits us to 100 million / 64,000 = 1562 I/Os
per sec.
- Hence the CPU limit is not relevant and the maximum I/O rate is
1562 I/Os per sec.
- The disk time for each I/O is 10ms + (64KB / (5MB/sec)).
= 10ms + (12.8*10-3)sec = 22.8ms.
- So each disk can achieve 1/(.0228) = 43.9 I/Os per sec.
- So need ceil (1562/ 43.9) = 36 disks.
- Each disk uses 64KB/22.8ms = 2.74 MB/sec of bus bandwidth.
- Since the controller supports 20 MB/sec, we can put 7 disks (the
maximum permitted) on it without it saturating.
- So, to support 36 disks we need 6 controllers (not all will
have 7 disks).
Remark: The above analysis was very simplistic.
It assumed everything overlapped just right and the I/Os were not
bursty and that the I/Os conveniently spread themselves accross the
disks.
Remark: Review of practice final.
Good luck on the (real) final!