Start Lecture #1
I start at -1 so that when we get to chapter 1, the numbering will agree with the text.
There is a web site for the course. You can find it from my home page, which is http://cs.nyu.edu/~gottlieb
The course text is Tanenbaum, "Modern Operating Systems", Third Edition (3e).
Replyto contribute to the current thread, but NOT to start another topic.
top post, that is, when replying, I ask that you either place your reply after the original text or interspersed with it.
musttop post.
Grades are based on the labs and the final exam, with each
very important.
The weighting will be approximately
40%*LabAverage + 60%*FinalExam
(but see homeworks below).
I use the upper left board for lab/homework assignments and announcements. I should never erase that board. Viewed as a file it is group readable (the group is those in the room), appendable by just me, and (re-)writable by no one. If you see me start to erase an announcement, let me know.
I try very hard to remember to write all announcements on the upper left board and I am normally successful. If, during class, you see that I have forgotten to record something, please let me know. HOWEVER, if I forgot and no one reminds me, the assignment has still been given.
I make a distinction between homeworks and labs.
Labs are
Homeworks are
Homeworks are numbered by the class in which they are assigned. So any homework given today is homework #1. Even if I do not give homework today, the homework assigned next class will be homework #2. Unless I explicitly state otherwise, all homeworks assignments can be found in the class notes. So the homework present in the notes for lecture #n is homework #n (even if I inadvertently forgot to write it to the upper left board).
You may solve lab assignments on any system you wish, but ...
request receiptfeature from home.nyu.edu or mail.nyu.edu and select the
when deliveredoption.
I sent it ... I never received itdebate. Thank you.
Good methods for obtaining help include
You may write your lab in Java, C, or C++.
Incomplete
The rules set by GSAS state:
3.6. Incomplete Grades: An unresolved grade, I, reverts to F one
year after the beginning of the semester in which the course
was taken unless an extension of the incomplete grade has been
approved by the Vice Dean.
3.6.1. At the request of the departmental DGS and with the
approval of the course instructor, the Vice Dean will
review requests for an extension of an incomplete grade.
3.6.2. A request for an extension of incomplete must be
submitted before the end of one year from the beginning
of the semester in which the course was taken.
3.6.3. An extension of an incomplete grade may be requested for
a period of up to, but not exceeding, one year
3.6.4. Only one one-year extension of an incomplete may be granted.
3.6.5. If a student is approved for a leave of absence (See 4.4)
any time the student spends on that leave of absence will
not count toward the time allowed for completion of the
coursework.
This email from the assistant director, describes the policy.
Dear faculty,
The vast majority of our students comply with the
department's academic integrity policies; see
www.cs.nyu.edu/web/Academic/Undergrad/academic_integrity.html
www.cs.nyu.edu/web/Academic/Graduate/academic_integrity.html
Unfortunately, every semester we discover incidents in
which students copy programming assignments from those of
other students, making minor modifications so that the
submitted programs are extremely similar but not identical.
To help in identifying inappropriate similarities, we
suggest that you and your TAs consider using Moss, a
system that automatically determines similarities between
programs in several languages, including C, C++, and Java.
For more information about Moss, see:
http://theory.stanford.edu/~aiken/moss/
Feel free to tell your students in advance that you will be
using this software or any other system. And please emphasize,
preferably in class, the importance of academic integrity.
Rosemary Amico
Assistant Director, Computer Science
Courant Institute of Mathematical Sciences
I do not assume you have had an OS course as an undergraduate, and I do not assume you have had extensive experience working with an operating system.
If you have already had an operating systems course, this course is probably not appropriate. For example, if you can explain the following concepts/terms, the course is probably too elementary for you.
I do assume you are an experienced programmer, at least to the extent that you are comfortable writing modest size (several hundred line) programs.
Originally called a linkage editor by IBM.
A linker is an example of a utility program included with an operating system distribution. Like a compiler, the linker is not part of the operating system per se, i.e. it does not run in supervisor mode. Unlike a compiler it is OS dependent (what object/load file format is used) and is not (normally) language dependent.
Link of course.
When the compiler and assembler have finished processing a module, they produce an object module that is almost runnable. There are two remaining tasks to be accomplished before object modules can be run. Both are involved with linking (that word, again) together multiple object modules. The tasks are relocating relative addresses and resolving external references.
The output of a linker is called a load module because, with relative addresses relocated and the external addresses resolved, the module is ready to be loaded and run.
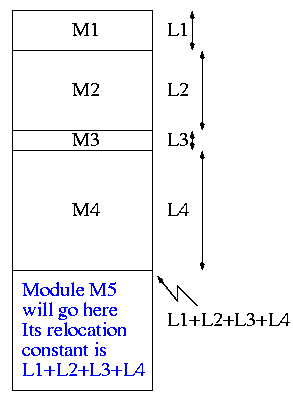
The compiler and assembler (mistakenly) treat each module as if it will be loaded at location zero.
To convert this relative address to an absolute address, the linker adds the base address of the module to the relative address. The base address is the address at which this module will be loaded.
How does the linker know that Module A is to be loaded starting at location 2300?
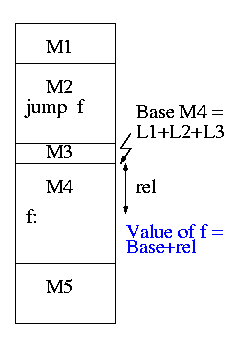
If a C (or Java, or Pascal, or ada, etc) program contains a
function call
f(x)
to a function f() that is compiled separately, the
resulting object module must contain some kind of jump to the
beginning of
f.
To see how a linker works lets consider the following example, which is the first dataset from lab #1. The description in lab1 is more detailed.
The target machine is word addressable and each word consists of 4 decimal digits. The first (leftmost) digit is the opcode and the remaining three digits form an address.
Each object module contains three parts, a definition list, a use list, and the program text itself. Each definition is a pair (sym, loc). Each use is also a pair (sym, loc), but sym is used in other loc's as well (see below).
The program text consists of a count N followed by N pairs (type, word), where word is a 4-digit instruction described above and type is a single character indicating if the address in the word is Immediate, Absolute, Relative, or External.
The actions taken by the linker depend on the type of the instruction, as we now illustrate. Consider the first input set from the lab.
Input set #1
1 xy 2
2 z xy
5 R 1004 I 5678 E 2000 R 8002 E 7001
0
1 z
6 R 8001 E 1000 E 1000 E 3000 R 1002 A 1010
0
1 z
2 R 5001 E 4000
1 z 2
2 xy z
3 A 8000 E 1001 E 2000
The first pass simply finds the base address of each module and produces the symbol table giving the values for xy and z (2 and 15 respectively). The second pass does the real work using the symbol table and base addresses produced in pass one.
The resulting output (shown below) is more detailed than I expect you to produce. The detail is there to help me explain what the linker is doing. All I would expect from you is the symbol table and the rightmost column of the memory map.
Symbol Table
xy=2
z=15
Memory Map
+0
0: R 1004 1004+0 = 1004
1: I 5678 5678
2: xy: E 2000 ->z 2015
3: R 8002 8002+0 = 8002
4: E 7001 ->xy 7002
+5
0 R 8001 8001+5 = 8006
1 E 1000 ->z 1015
2 E 1000 ->z 1015
3 E 3000 ->z 3015
4 R 1002 1002+5 = 1007
5 A 1010 1010
+11
0 R 5001 5001+11= 5012
1 E 4000 ->z 4015
+13
0 A 8000 8000
1 E 1001 ->z 1015
2 z: E 2000 ->xy 2002
You must process each module separately, i.e. except for the symbol table and memory map your space requirements should be proportional to the largest module not to the sum of the modules. This does NOT make the lab harder.
Remark: It is faster (less I/O)
to do a one pass approach, but is harder since you need
fix-up code
whenever a use occurs in a module that precedes
the module with the definition.
The linker on unix was mistakenly called ld (for loader), which is unfortunate since it links but does not load.
.TH LD 1
.SH NAME
ld \- loader
.SH SYNOPSIS
.B ld
[ option ] file ...
.SH DESCRIPTION
.I Ld
combines several
object programs into one, resolves external
references, and searches libraries.
By the mid 80s the Berkeley version (4.3BSD) man
page referred to ld as link editor
and this more accurate
name is now standard in unix/linux distributions.
During the 2004-05 fall semester a student wrote to me
BTW - I have meant to tell you that I know the lady who wrote ld. She told me that they called it loader, because they just really didn't have a good idea of what it was going to be at the time.
Lab #1: Implement a two-pass linker. The specific assignment is detailed on the class home page.
Homework: Read Chapter 1 (Introduction)
Software (and hardware, but that is not this course) is often implemented in layers. The higher layers use the facilities provided by lower layers.
Alternatively said, the upper layers are written using a more powerful and more abstract virtual machine than the lower layers.
In other words, each layer is written as though it runs on the virtual machine supplied by the lower layers and in turn provides a more abstract (pleasant) virtual machine for the higher layers to run on.
Using a broad brush, the layers are.
An important distinction is that the kernel runs in privileged/kernel/supervisor mode); whereas compilers, editors, shell, linkers. browsers etc run in user mode.
The kernel itself is itself normally layered, e.g.
The machine independent I/O part is written assuming
virtual (i.e. idealized) hardware
.
For example, the machine independent I/O portion simply reads a
block from a disk
.
But in reality one must deal with the specific disk controller.
Often the machine independent part is more than one layer.
The term OS is not well defined. Is it just the kernel? How about the libraries? The utilities? All these are certainly system software but it is not clear how much is part of the OS.
As mentioned above, the OS raises the abstraction level by providing a higher level virtual machine. A second related key objective for the OS is to manage the resources provided by this virtual machine.
The kernel itself raises the level of abstraction and hides details. For example a user (of the kernel) can write to a file (a concept not present in hardware) and ignore whether the file resides on a floppy, a CD-ROM, or a hard disk. The user can also ignore issues such as whether the file is stored contiguously or is broken into blocks.
Well designed abstractions are a key to managing complexity.
The kernel must manage the resources to resolve conflicts between users. Note that when we say users, we are not referring directly to humans, but instead to processes (typically) running on behalf of humans.
Typically the resource is shared or multiplexed between the users. This can take the form of time-multiplexing, where the users take turns (e.g., the processor resource) or space-multiplexing, where each user gets a part of the resource (e.g., a disk drive).
With sharing comes various issues such as protection, privacy, fairness, etc.
Homework: What are the two main functions of an operating system?
Answer: Concurrency! Per Brinch Hansen in Operating Systems Principles (Prentice Hall, 1973) writes.
The main difficulty of multiprogramming is that concurrent activities can interact in a time-dependent manner, which makes it practically impossibly to locate programming errors by systematic testing. Perhaps, more than anything else, this explains the difficulty of making operating systems reliable.
Homework: 1. (unless otherwise stated, problems numbers are from the end of the current chapter in Tanenbaum.)
The subsection heading describe the hardware as well as the OS; we are naturally more interested in the latter. These two development paths are related as the improving hardware enabled the more advanced OS features.
One user (program; perhaps several humans) at a time. Although this time frame predates my own usage, computers without serious operating systems existed during the second generation and were now available to a wider (but still very select) audience.
I have fond memories of the Bendix G-15 (paper tape) and the IBM 1620 (cards; typewriter; decimal). During the short time you had the machine, it was truly a personal computer.
Many jobs were batched together, but the systems were still uniprogrammed, a job once started was run to completion without interruption and then flushed from the system.
A change from the previous generation is that the OS was not reloaded for each job and hence needed to be protected from the user's execution. Previously, the beginning of your job contained the trivial OS-like support features.
The batches of user jobs were prepared offline (cards to magnetic tape) using a separate computer (an IBM 1401 with a 1402 card reader/punch). The tape was brought to the main computer (an IBM 7090/7094) where the output to be printed was written on another tape. This tape went back to the 1401 and was printed on a 1403.