Start Lecture #12
Should file names be case sensitive. For example, do x.y, X.Y, x.Y all name the same file? There is no clear answer.
How should the file be structured. Alternatively, how does the OS interpret the contents of a file.
A file can be interpreted as a
The traditional file is simply a collection of data that forms the unit of sharing for processes, even concurrent processes. These are called regular files.
The advantages of uniform naming have encouraged the inclusion in the file system of objects that are not simply collections of data.
Some regular files contain lines of text and are called (not
surprisingly) text files or ascii files.
Each text line concludes with some end of line indication: on unix
and recent MacOS this is a newline (a.k.a line feed), in MS-DOS it
is the two character sequence carriage return
followed by
newline, and in earlier MacOS it was carriage return
.
Ascii, with only 7 bits per character, is poorly suited for most human languages other than English. Latin-1 (8 bits) is a little better with support for most Western European Languages.
Perhaps, with growing support for more varied character sets, ascii files will be replaced by unicode (16 bits) files. The Java and Ada programming languages (and perhaps others) already support unicode.
An advantage of all these formats is that they can be directly printed on a terminal or printer.
Other regular files, often referred to as binary files, do not represent a sequence of characters. For example, a four-byte, twos-complement representation of integers in the range from roughly -2 billion to +2 billion is definitely not to be thought of as 4 latin-1 characters, one per byte.
Just because a file is unstructured (i.e., is a byte stream) from the OS perspective does not mean that applications cannot impose structure on the bytes. So a document written without any explicit formatting in MS word is not simply a sequence of ascii (or latin-1 or unicode) characters.
On unix, an executable file must begin with one of certain
magic numbers
in the first few bytes.
For a native executable, the remainder of the file has a well
defined format.
Another option is for the magic number to be the ascii
representation of the two characters #!
in which case the
next several characters specify the location of the executable
program that is to be run with the current file fed in as input.
That is how interpreted (as opposed to compiled) languages work in
unix.
#!/usr/bin/perl
perl script
In some systems the type of the file (which is often specified by the extension) determines what you can do with the file. This make the easy and (hopefully) common case easier and, more importantly, safer.
It tends to make the unusual case harder. For example, you have a program that turns out data (.dat) files. Now you want to use it to turn out a java file, but the type of the output is data and cannot be easily converted to type java and hence cannot be given to the java compiler.
We will discuss several file types that are not
called regular
.
dir # prints on screen
dir > file # result put in a file
dir > /dev/audio # results sent to speaker (sounds awful)
There are two possibilities, sequential access and random access (a.k.a. direct access).
With sequential access, each access to a given
file starts where the previous access to that file finished (the
first access to the file starts at the beginning of the file).
Sequential access is the most common and gives the highest
performance.
For some devices (e.g. magnetic or paper tape) access must
be
sequential.
With random access, the bytes are accessed in any order. Thus each access must specify which bytes are desired. This is done either by having each read/write specify the starting location or by defining another system call (often named seek) that specifies the starting location for the next read/write.
For example, in unix, if no seek occurs between two read/write operations, then the second begins where the first finished. That is, unix treats a sequences of reads and writes as sequential, but supports seeking to achieve random access.
Previously, files were declared to be sequential or random. Modern systems do not do this. Instead all files are random, and optimizations are applied as the system dynamically determines that a file is (probably) being accessed sequentially.
Various properties that can be specified for a file For example:
Homework: 4, 5.
Homework: Read and understand copyfile
.
Note the error checks. Specifically, the code checks the return value from each I/O system call. It is a common error to assume that
Directories form the primary unit of organization for the filesystem.
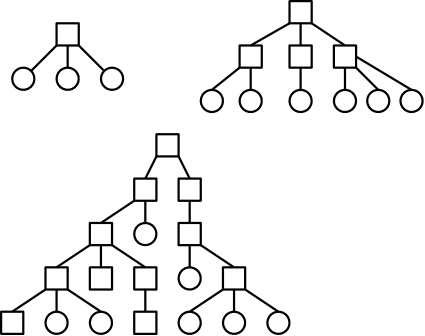
One often refers to the level structure of a directory system. It is easy to be fooled by the names given. A single level directory structure results in a file system tree with two levels: the single root directory and (all) the files in this directory. That is, there is one level of directories and another level of files so the full file system tree has two levels.
Possibilities.
These possibilities are not as wildly different as they sound or as the pictures suggests.
/is allowed in a file name. Then one could fake a tree by having a file named
links, which we will study soon.
You can specify the location of a file in the file hierarchy by using either an absolute or a relative path to the file.
one of the, if we have a forest) root(s).
Homework: Give 8 different path names for the file /etc/passwd.
Homework: 7.
emptydirectory. Normally the directory created actually contains . and .., so is not really empty
handlefor the directory that speeds future access by eliminating the need to process the name of the directory.
However, experience has taught that this was a poor idea since the structure of directories was exposed to users. Early unix had a simple directory structure and there was only one type of structure for all implementations. Modern systems have more sophisticated structures and more importantly they are not fixed across implementations. So if programs used read() to read directories, the programs would have to be changed whenever the structure of a directory changed. Now we have a readdir() system call that knows the structure of directories. Therefore if the structure is changed only readdir() need be changed.
This is an example of the software principle of
information hiding.
Now that we understand how the file system looks to a user, we turn our attention to how it is implemented.
We look at how the file systems are laid out on disk in modern PCs. Much of this is required by the bios so all PC operating systems have the same lowest level layout. I do not know the corresponding layout for mainframe systems or supercomputers.
A system often has more than one physical disk (3e forgot this).
The first
disk is the boot disk.
How do we determine which is the first disk?
jumpers).
The BIOS reads the first sector (smallest addressable unit of a disk) of the boot disk into memory and transfers control to it. A sector contains 512 bytes. The contents of this particular sector is called the MBR (master boot record).
The MBR contains two key components: the partition table and the first-level loader.
logical disk. That is, normally each partition holds a complete file system. The partition table (like a process's page table) gives the starting point of each partition. It is actually more like the segment table of a pure segmentation system since the objects pointed to (partitions and segments) are of variable size. As with segments, the size of each partition is stored in the corresponding entry of the partition table.
The contents vary from one file system to another but there is some commonality.
A fundamental property of disks is that they cannot read or write single bytes. The smallest unit that can be read or written is called a sector and is normally 512 bytes (plus error correction/detection bytes). This is a property of the hardware, not the operating system.
The operating system reads or writes disk blocks. The size of a block is a multiple (normally a power of 2) of the size of a sector. Since sectors are usually (always?) 512 bytes, the block size can be 512, 1024=1K, 2K, 4K, 8K, 16K, etc. The most common block sizes today are 4K and 8K.
So files will be composed of blocks.
When we studied memory management, we had to worry about fragmentation, processes growing and shrinking, compaction, etc.. Many of these same considerations apply to files; the difference is that instead of a memory region being composed of bytes, a file is composed of blocks.
Recall the simplest form of memory management beyond uniprogramming was OS/MFT where memory was divided into a very few regions and each process was given one of these regions. The analogue for disks would be to give each file an entire partition. This is too inflexible and is not used for files.
The next simplest memory management scheme was the one used in OS/MVT, where the memory for a process was contiguous.
almostis that the terminology used is that the movie is one file stored as a sequence of extents and only the extents are contiguous.
Homework: 10.
There is a typo: the first sentence should end at the first comma.
Contiguous allocation of files leads to disk fragmentation.
A file is an ordered sequence of blocks. We just considered storing the blocks one right after the other (contiguous) the same way that one can store an in-memory list as an array. The other common method for in-memory lists is to link the elements together via pointers. This can also be done for files as follows.
However
As a result this implementation of linked allocation is not used.
Consider the following two code segments that store the same data but in a different order. The first is analogous to the horrible linked list file organization above and the second is analogous to the ms-dos FAT file system we study next.
struct node_type {
float data; float node_data[100];
int next; int node_next[100];
} node[100]
With the second arrangement the data can be stored far away from the next pointers. In FAT this idea is taken to an extreme: The data, which is large (a disk block), is stored on disk; whereas, the next pointers, which are small (each is an integer) are stored in memory in a File Allocation Table or FAT. (When the system is shut down the FAT is copied to disk and when the system is booted, the FAT is copied to memory.)
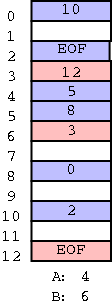
The FAT file system stores each file as a linked list of disk blocks. The blocks, which contain file data only (not the linked list structure) are stored on disk. The pointers implementing the linked list are stored in memory.
(size of a disk block) / (size of a pointer)
If the block size is 8KB and a pointer is 2B, the memory
requirement is 1/4 megabyte for each disk gigabyte.
Large but not prohibitive.
(While 8KB is reasonable today for blocksize, 2B pointers is not
since that would mean the largest partition could be
216 blocks = 216×213
bytes = 229 bytes = 1/2 GB, which is much too small.)
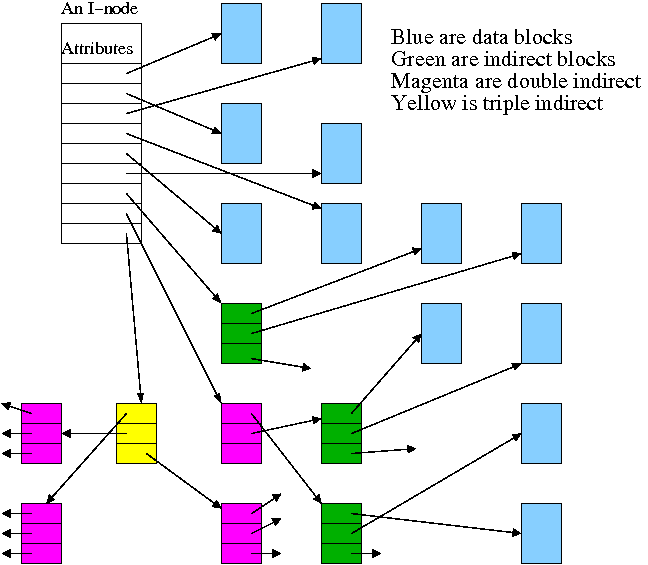
Continuing the idea of adapting storage schemes from other regimes to file storage, why don't we mimic the idea of (non-demand) paging and have a table giving, for each block of the file, where on the disk that file block is stored? In other words a ``file block table'' mapping each file block to its corresponding disk block. This is the idea of (the first part of) the unix i-node solution, which we study next.
Although Linux and other Unix and Unix-like operating systems have a variety of file systems, the most widely used Unix file systems are i-node based as was the original Unix file system from Bell Labs.
There is some question of what the i
stands for.
The consensus seems to be index.
Now, however, people often write inode (not i-node) and don't view the
i
as standing for anything.
Inode based systems have the following properties.
Given a block number (byte number / block size), how do you find the block?
Specifically assume
firstblock.
If N < D // This is a direct block in the i-node
use direct pointer N in the i-node
else if N < D + K // The single indirect block has a pointer to this block
use pointer D in the inode to get the indirect block
the use pointer N-D in the indirect block to get block N
else // This is one of the K*K blocks obtained via the double indirect block
use pointer D+1 in the inode to get the double indirect block
let P = (N-(D+K)) DIV K // Which single indirect block to use
use pointer P to get the indirect block B
let Q = (N-(D+K)) MOD K // Which pointer in B to use
use pointer Q in B to get block N
For example, let D=12, assume all blocks are 1000B, assume all pointers are 4B. Retrieve the block containing byte 1,000,000.
With a triple indirect block, the ideas are the same, but there is more work.
Homework: Consider an inode-based system with the same parameters as just above, D=12, K=250, etc.