Start Lecture #4
A process contains a number of resources such as address space, open files, accounting information, etc. In addition to these resources, a process has a thread of control, e.g., program counter, register contents, stack. The idea of threads is to permit multiple threads of control to execute within one process. This is often called multithreading and threads are sometimes called lightweight processes. Because threads in the same process share so much state, switching between them is much less expensive than switching between separate processes.
Individual threads within the same process are not completely independent. For example there is no memory protection between them. This is typically not a security problem as the threads are cooperating and all are from the same user (indeed the same process). However, the shared resources do make debugging harder. For example one thread can easily overwrite data needed by another thread in the process and when the second thread fails, the cause may be hard to determine because the tendency is to assume that the failed thread caused the failure.
A new thread in the same process is created by a routine named something like thread_create; similarly there is thread_exit. The analogue to waitpid is thread_join (the name comes presumably from the fork-join model of parallel execution).
The routine tread_yield, which relinquishes the processor, does not have a direct analogue for processes. The corresponding system call (if it existed) would move the process from running to ready.
Homework: 11.
Assume a process has several threads. What should we do if one of these threads
POSIX threads (pthreads) is an IEEE standard specification that is supported by many Unix and Unix-like systems. Pthreads follows the classical thread model above and specifies routines such as pthread_create, pthread_yield, etc.
An alternative to the classical model are the so-called Linux threads (see the section 10.3 in the 3e).
Write a (threads) library that acts as a mini-scheduler and implements thread_create, thread_exit, thread_wait, thread_yield, etc. This library acts as a run-time system for the threads in this process. The central data structure maintained and used by this library is a thread table, the analogue of the process table in the operating system itself.
There is a thread table and an instance of the threads library in each multithreaded process.
Advantages of User-Mode Threads
:
Disadvantages
For a uniprocessor, which is all we are officially considering, there is little gain in splitting pure computation into pieces. If the CPU is to be active all the time for all the threads, it is simpler to just have one (unithreaded) process.
But this changes for multiprocessors/multicores. Now it is very useful to split computation into threads and have each executing on a separate processor/core. In this case, user-mode threads are wonderful, there are no system calls and the extremely low overhead is beneficial.
However, there are serious issues involved is programming applications for this environment.
One can move the thread operations into the operating system itself. This naturally requires that the operating system itself be (significantly) modified and is thus not a trivial undertaking.
One can write a (user-level) thread library even if the kernel also has threads. This is sometimes called the N:M model since N user-mode threads run on M kernel threads. In this scheme, the kernel threads cooperate to execute the user-level threads.
An offshoot of the N:M terminology is that kernel-level threading (without user-level threading) is sometimes referred to as the 1:1 model since one can think of each thread as being a user level thread executed by a dedicated kernel-level thread.
Homework: 12, 14.
Skipped
The idea is to automatically issue a thread-create system call upon message arrival. (The alternative is to have a thread or process blocked on a receive system call.) If implemented well, the latency between message arrival and thread execution can be very small since the new thread does not have state to restore.
Definitely NOT for the faint of heart.
Remark: We shall do section 2.4 before section 2.3 for two reasons.
Scheduling processes on the processor is often called
processor scheduling
or process scheduling
or
simply scheduling
.
As we shall see later in the course, a more descriptive name would
be short-term, processor scheduling
.
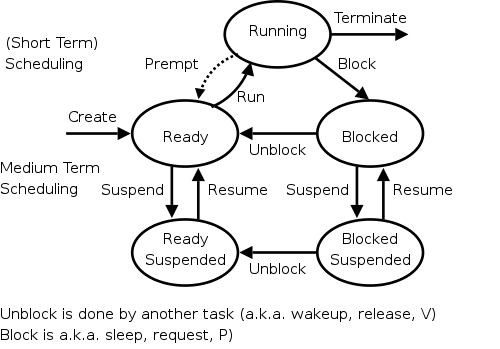
For now we are discussing the arcs connecting running↔ready in the diagram on the right showing the various states of a process. Medium term scheduling is discussed later as is disk-arm scheduling.
Naturally, the part of the OS responsible for (short-term, processor) scheduling is called the (short-term, processor) scheduler and the algorithm used is called the (short-term, processor) scheduling algorithm.
Early computer systems were monoprogrammed and, as a result, scheduling was a non-issue.
For many current personal computers, which are definitely multiprogrammed, there is in fact very rarely more than one runnable process. As a result, scheduling is not critical.
For servers (or old mainframes), scheduling is indeed important and these are the systems you should think of.
Processes alternate CPU bursts with I/O activity, as we shall see in lab2. The key distinguishing factor between compute-bound (aka CPU-bound) and I/O-bound jobs is the length of the CPU bursts.
The trend over the past decade or two has been for more and more jobs to become I/O-bound since the CPU rates have increased faster than the I/O rates.
An obvious point, which is often forgotten (I don't think 3e mentions it) is that the scheduler cannot run when the OS is not running. In particular, for the uniprocessor systems we are considering, no scheduling can occur when a user process is running. (In the mulitprocessor situation, no scheduling can occur when all processors are running user jobs).
Again we refer to the state transition diagram above.
It is important to distinguish preemptive from non-preemptive scheduling algorithms.
run until completion, or block (, or yield).
preemptarc in the diagram is present for preemptive scheduling algorithms.
We distinguish three categories of scheduling algorithms with regard to the importance of preemption.
For multiprogramed batch systems (we don't consider uniprogrammed systems, which don't need schedulers) the primary concern is efficiency. Since no user is waiting at a terminal, preemption is not crucial and if it is used, each process is given a long time period before being preempted.
For interactive systems (and multiuser servers), preemption is crucial for fairness and rapid response time to short requests.
We don't study real time systems in this course, but can say that preemption is typically not important since all the processes are cooperating and are programmed to do their task in a prescribed time window.
There are numerous objectives, several of which conflict, that a scheduler tries to achieve. These include.
more importantprocesses higher priority. For example, if my laptop is trying to fold proteins in the background, I don't want that activity to appreciably slow down my compiles and especially don't want it to make my system seem sluggish when I am modifying these class notes. In general,
interactivejobs should have higher priority.
jobto its termination. This is important for batch jobs.
shortest job first.
wasted cyclesand limited logins for repeatability.
This is used for real time systems. The objective of the scheduler is to find a schedule for all the tasks (there are a fixed set of tasks) so that each meets its deadline. The run time of each task is known in advance.
Actually it is more complicated.
There is an amazing inconsistency in naming the different (short-term) scheduling algorithms. Over the years I have used primarily 4 books: In chronological order they are Finkel, Deitel, Silberschatz, and Tanenbaum. The table just below illustrates the name game for these four books. After the table we discuss several scheduling policy in some detail.
Finkel Deitel Silbershatz Tanenbaum
-------------------------------------
FCFS FIFO FCFS FCFS
RR RR RR RR
PS ** PS PS
SRR ** SRR ** not in tanenbaum
SPN SJF SJF SJF
PSPN SRT PSJF/SRTF SRTF
HPRN HRN ** ** not in tanenbaum
** ** MLQ ** only in silbershatz
FB MLFQ MLFQ MQ
Remark: For an alternate organization of the scheduling algorithms (due to my former PhD student Eric Freudenthal and presented by him Fall 2002) click here.
If the OS doesn't
schedule, it still needs to store the list
of ready processes in some manner.
If it is a queue you get FCFS.
If it is a stack (strange), you get LCFS.
Perhaps you could get some sort of random policy as well.
Sort jobs by execution time needed and run the shortest first.
This is a Non-preemptive algorithm.
First consider a static situation where all jobs are available
in the beginning and we know how long each one takes to run.
For simplicity lets consider run-to-completion
, also
called uniprogrammed
(i.e., we don't even switch to
another process on I/O).
In this situation, uniprogrammed SJF has the shortest average
waiting time.
The above argument illustrates an advantage of favoring short jobs (e.g., RR with small quantum): The average waiting time is reduced.
In the more realistic case of true SJF where the scheduler switches to a new process when the currently running process blocks (say for I/O), we could also consider the policy shortest next-CPU-burst first.
The difficulty is predicting the future (i.e., knowing in advance the time required for the job or the job's next-CPU-burst).
SJF Can starve a process that requires a long burst.
Preemptive version of above. Indeed some authors call it preemptive shortest job first.
The following algorithms can also be used for batch systems, but in that case, the gain may not justify the extra complexity.
triggeredby three conditions: process terminating, process blocking, and process preempted. If the first trigger condition to arise is never preemption, we can erase that arc and then RR becomes FCFS.
The round robin was originally a petition, its signatures arranged in a circular form to disguise the order of signing. Most probably it takes its name from theruban rond, (round ribbon), in 17th-century France, where government officials devised a method of signing their petitions of grievances on ribbons that were attached to the documents in a circular form. In that way no signer could be accused of signing the document first and risk having his head chopped off for instigating trouble.Ruban rondlater becameround robinin English and the custom continued in the British navy, where petitions of grievances were signed as if the signatures were spokes of a wheel radiating from its hub. Todayround robinusually means a sports tournament where all of the contestants play each other at least once and losing a match doesn't result in immediate elimination.
Encyclopedia of Word and Phrase Origins by Robert Hendrickson (Facts on File, New York, 1997).
Homework: 20, 35.
Homework: Round-robin schedulers normally maintain a list of all runnable processes, with each process occurring exactly once in the list. What would happen if a process occurred more than once in the list? Can you think of any reason for allowing this?
Homework: Give an argument favoring a large quantum; give an argument favoring a small quantum.
| Process | CPU Time | Creation Time |
|---|---|---|
| P1 | 20 | 0 |
| P2 | 3 | 3 |
| P3 | 2 | 5 |
Homework:
Homework: Redo the previous homework for q=2 with the following changes. After process P1 runs for 3ms (milliseconds), it blocks for 2ms. P1 never blocks again. P2 never blocks. After P3 runs for 1 ms it blocks for 1ms. Assume the context switch time is zero. Remind me to answer this one in class next lecture.
Merge the ready and running states and permit all ready jobs to be run at once. However, the processor slows down so that when n jobs are running at once, each progresses at a speed 1/n as fast as it would if it were running alone.
Homework: 32.