Start Lecture #5
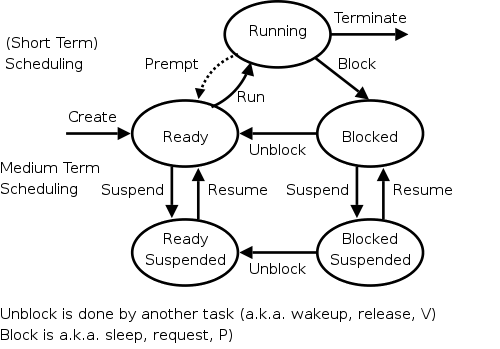
triggeredby three conditions: process terminating, process blocking, and process preempted. If the first trigger condition to arise is never preemption, we can erase that arc and then RR becomes FCFS.
The round robin was originally a petition, its signatures arranged in a circular form to disguise the order of signing. Most probably it takes its name from theruban rond, (round ribbon), in 17th-century France, where government officials devised a method of signing their petitions of grievances on ribbons that were attached to the documents in a circular form. In that way no signer could be accused of signing the document first and risk having his head chopped off for instigating trouble.Ruban rondlater becameround robinin English and the custom continued in the British navy, where petitions of grievances were signed as if the signatures were spokes of a wheel radiating from its hub. Todayround robinusually means a sports tournament where all of the contestants play each other at least once and losing a match doesn't result in immediate elimination.
Encyclopedia of Word and Phrase Origins by Robert Hendrickson (Facts on File, New York, 1997).
Homework: 20, 35.
Homework: Round-robin schedulers normally maintain a list of all runnable processes, with each process occurring exactly once in the list. What would happen if a process occurred more than once in the list? Can you think of any reason for allowing this?
Homework: Give an argument favoring a large quantum; give an argument favoring a small quantum.
| Process | CPU Time | Creation Time |
|---|---|---|
| P1 | 20 | 0 |
| P2 | 3 | 3 |
| P3 | 2 | 5 |
Homework:
Homework: Redo the previous homework for q=2 with the following changes. After process P1 runs for 3ms (milliseconds), it blocks for 2ms. P1 never blocks again. P2 never blocks. After P3 runs for 1 ms it blocks for 1ms. Assume the context switch time is zero. Remind me to answer this one in class next lecture.
Merge the ready and running states and permit all ready jobs to be run at once. However, the processor slows down so that when n jobs are running at once, each progresses at a speed 1/n as fast as it would if it were running alone.
Homework: 32.
Each job is assigned a priority (externally, perhaps by charging more for higher priority) and the highest priority ready job is run.
External prioritiesabove
standard technique.
As a job is waiting, increase its priority; hence it will eventually have the highest priority.
No job can remain in the ready state forever.
standard techniqueused to prevent starvation (assuming all jobs terminate or the policy is preemptive).
Homework: 36, 37. Note that when the book says RR with each process getting its fair share, it means Processor Sharing.
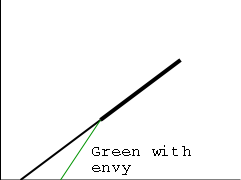
SRR is a preemptive policy in which unblocked (i.e. ready and
running) processes are divided into two classes the Accepted
processes
, which run RR and the others
(perhaps SRR
really stands for snobbish RR
).
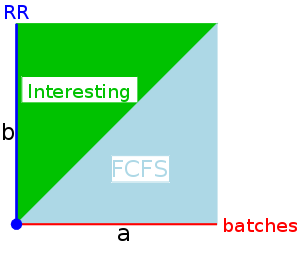
The behavior of SRR depends on the relationship between a and b (and zero).
batches. This is similar to n-step scan for disk I/O.
It is not clear what is supposed to happen when a process blocks. Should its priority get reset to zero and have unblock act like create? Should the priority continue to grow (at rate a or b)? Should its priority be frozen during the blockage. Let us assume the first case (reset to zero) since it seems the simplest.
Recall that SFJ/PSFJ do a good job of minimizing the average waiting time. The problem with them is the difficulty in finding the job whose next CPU burst is minimal. We now learn three scheduling algorithms that attempt to do this. The first algorithm does it statically, presumably with some manual help; the other two are dynamic and fully automatic.
Put different classes of processs in different queues
cycle soaker.
As with multilevel queues above we have many queues, but now
processes move from queue to queue in an attempt to dynamically
separate batch-like
from interactive processs so that we can
favor the latter.
An attempt to apply sjf to interactive scheduling. What is needed is an estimate of how long the process will run until it blocks again. One method is to choose some initial estimate when the process starts and then, whenever the process blocks choose a new estimate via
NewEstimate = A*OldEstimate + (1-A)*LastBurst
where 0<A<1 and LastBurst is the actual time used
during the burst that just ended.
Run the process that has been hurt
the most.
A variation on HPRN.
The penalty ratio is a little different.
It is nearly the reciprocal of the above, namely
t / (T/n)
where n is the multiprogramming level.
So if n is constant, this ratio is a constant times 1/r.
Each process gets a fixed number of tickets and at each scheduling event a random ticket is drawn (with replacement) and the process holding that ticket runs for the next interval (probably a RR-like quantum q).
On the average a process with P percent of the tickets will get P percent of the CPU (assuming no blocking, i.e., full quanta).
If you treat processes fairly
you may not be treating
users fairly
since users with many processes will get more
service than users with few processes.
The scheduler can group processes by user and only give one of a
user's processes a time slice before moving to another user.
Fancier methods have been implemented that give some fairness to groups of users. Say one group paid 30% of the cost of the computer. That group would be entitled to 30% of the cpu cycles providing it had at least one process active. Furthermore a group earns some credit when it has no processes active.
Considerable theory has been developed.
In addition to the short-term scheduling we have discussed, we add medium-term scheduling in which decisions are made at a coarser time scale.
Recall my favorite diagram, shown again on the right. Medium term scheduling determines the transitions from the top triangle to the bottom line. We suspend (swap out) some process if memory is over-committed dropping the (ready or blocked) process down. We also need resume transitions to return a process to the top triangle.
Criteria for choosing a victim to suspend include:
We will discuss medium term scheduling again when we study memory management.
This is sometimes called Job scheduling
.
A similar idea (but more drastic and not always so well coordinated) is to force some users to log out, kill processes, and/or block logins if over-committed.
LEM jobs during the day(Grumman).
Skipped
Skipped.
Skipped.
Show the detailed output
A race condition occurs when two (or more) processes are about to perform some action. Depending on the exact timing, one or other goes first. If one of the processes goes first, everything works correctly, but if another one goes first, an error, possibly fatal, occurs.
Imagine two processes both accessing x, which is initially 10.
A1: LOAD r1,x B1: LOAD r2,x A2: ADD r1,1 B2: SUB r2,1 A3: STORE r1,x B3: STORE r2,x
We must prevent interleaving sections of code that need to be atomic with respect to each other. That is, the conflicting sections need mutual exclusion. If process A is executing its critical section, it excludes process B from executing its critical section. Conversely if process B is executing is critical section, it excludes process A from executing its critical section.
Requirements for a critical section implementation.
We will study only solutions in this class. Note that higher level solutions, e.g., having one process block when it cannot enter its critical are implemented using busy waiting algorithms.
The operating system can choose not to preempt itself. That is, we could choose not to preempt system processes (if the OS is client server) or processes running in system mode (if the OS is self service). Forbidding preemption for system processes would prevent the problem above where x<--x+1 not being atomic crashed the printer spooler if the spooler is part of the OS.
The way to prevent preemption of kernel-mode code is to disable
interrupts.
Indeed, disabling (i.e., temporarily preventing) interrupts
is often done for exactly this reason.
This is not, however, sufficient for all cases.
Initially P1wants=P2wants=false
Code for P1 Code for P2
Loop forever { Loop forever {
P1wants <-- true ENTRY P2wants <-- true
while (P2wants) {} ENTRY while (P1wants) {}
critical-section critical-section
P1wants <-- false EXIT P2wants <-- false
non-critical-section } non-critical-section }
Explain why this works.
But it is wrong!
Why?
Let's try again. The trouble was that setting want before the loop permitted us to get stuck. We had them in the wrong order!
Initially P1wants=P2wants=false
Code for P1 Code for P2
Loop forever { Loop forever {
while (P2wants) {} ENTRY while (P1wants) {}
P1wants <-- true ENTRY P2wants <-- true
critical-section critical-section
P1wants <-- false EXIT P2wants <-- false
non-critical-section } non-critical-section }
Explain why this works.
But it is wrong again!
Why?
Now let's try being polite and really take turns. None of this wanting stuff.
Initially turn=1
Code for P1 Code for P2
Loop forever { Loop forever {
while (turn = 2) {} while (turn = 1) {}
critical-section critical-section
turn <-- 2 turn <-- 1
non-critical-section } non-critical-section }
This one forces alternation, so is not general enough. Specifically, it does not satisfy condition three, which requires that no process in its non-critical section can stop another process from entering its critical section. With alternation, if one process is in its non-critical section (NCS) then the other can enter the CS once but not again.
The first example violated rule 4 (the whole system blocked). The second example violated rule 1 (both in the critical section. The third example violated rule 3 (one process in the NCS stopped another from entering its CS).
In fact, it took years (way back when) to find a correct solution.
Many earlier solutions
were found and several were published, but
all were wrong.
The first correct solution was found by a mathematician named Dekker,
who combined the ideas of turn and wants.
The basic idea is that you take turns when there is contention, but
when there is no contention, the requesting process can enter.
It is very clever, but I am skipping it (I cover it when I teach
distributed operating systems in V22.0480 or G22.2251).
Subsequently, algorithms with better fairness properties were found
(e.g., no task has to wait for another task to enter the CS twice).
What follows is Peterson's solution, which also combines wants and turn to force alternation only when there is contention. When Peterson's algorithm was published, it was a surprise to see such a simple solution. In fact Peterson gave a solution for any number of processes. A proof that the algorithm satisfies our properties (including a strong fairness condition) for any number of processes can be found in Operating Systems Review Jan 1990, pp. 18-22.
Initially P1wants=P2wants=false and turn=1
Code for P1 Code for P2
Loop forever { Loop forever {
P1wants <-- true P2wants <-- true
turn <-- 2 turn <-- 1
while (P2wants and turn=2) {} while (P1wants and turn=1) {}
critical-section critical-section
P1wants <-- false P2wants <-- false
non-critical-section } non-critical-section }
Tanenbaum calls this instruction
test and set lock TSL
.
I call it test and set (TAS)
and define
TAS(b), where b is a binary variable,
to ATOMICALLY set b←true and return the OLD value of b.
Of course it would be silly to return the new value of b since we know the new value is true.
The word atomically means that the two actions performed by TAS(x), testing (i.e., returning the old value of x) and setting (i.e., assigning true to x) are inseparable. Specifically it is not possible for two concurrent TAS(x) operations to both return false (unless there is also another concurrent statement that sets x to false).
With TAS available implementing a critical section for any number of processes is trivial.
loop forever {
while (TAS(s)) {} ENTRY
CS
s<--false EXIT
NCS }