Start Lecture #3
I must note that Tanenbaum is a big advocate of the so called microkernel approach in which as much as possible is moved out of the (supervisor mode) kernel into separate processes. The (hopefully small) portion left in supervisor mode is called a microkernel.
In the early 90s this was popular.
Digital Unix (now called True64) and Windows NT/2000/XP/Vista/7 are
examples.
Digital Unix is based on Mach, a research OS from Carnegie Mellon
university.
Lately, the growing popularity of Linux has called into
question the belief that
all new operating systems will be microkernel based
.
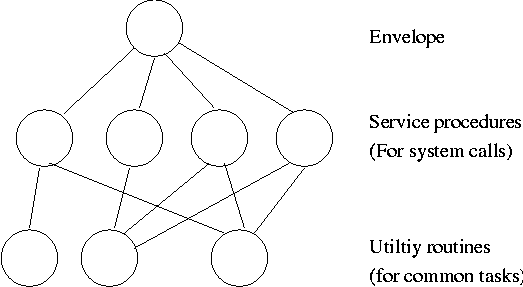
The previous picture: one big program
The system switches from user mode to kernel mode during the poof and
then back when the OS does a return
(an RTI or return
from interrupt).
But of course we can structure the system better, which brings us to.
Some systems have more layers and are more strictly structured.
An early layered system was THE
operating system by
Dijkstra and his students at Technische Hogeschool Eindhoven.
This was a simple batch system so the operator
was the user.
The layering was done by convention, i.e. there was no enforcement by hardware and the entire OS is linked together as one program. This is true of many modern OS systems as well (e.g., linux).
The multics system was layered in a more formal manner. The hardware provided several protection layers and the OS used them. That is, arbitrary code could not jump into or access data in a more protected layer.
The idea is to have the kernel, i.e. the portion running in supervisor mode, as small as possible and to have most of the operating system functionality provided by separate processes. The microkernel provides just enough to implement processes.
This does have advantages. For example an error in the file server cannot corrupt memory in the process server since they have separate address spaces (they are after all separate process). Confining the effect of errors makes them easier to track down. Also an error in the ethernet driver can corrupt or stop network communication, but it cannot crash the system as a whole.
But the microkernel approach does mean that when a (real) user process makes a system call there are more processes switches. These are not free.
Related to microkernels is the idea of putting the mechanism in the kernel, but not the policy. For example, the kernel would know how to select the highest priority process and run it, but some user-mode process would assign the priorities. One could envision changing the priority scheme being a relatively minor event compared to the situation in monolithic systems where the entire kernel must be relinked and rebooted.
Dennis Ritchie, the inventor of the C programming language and co-inventor, with Ken Thompson, of Unix was interviewed in February 2003. The following is from that interview.
What's your opinion on microkernels vs. monolithic?
Dennis Ritchie: They're not all that different when you actually use them. "Micro" kernels tend to be pretty large these days, and "monolithic" kernels with loadable device drivers are taking up more of the advantages claimed for microkernels.
I should note, however, that the Minix microkernel (excluding the processes) is quite small, about 4000 lines.

When implemented on one computer, a client-server OS often uses the microkernel approach in which the microkernel just handles communication between clients and servers, and the main OS functions are provided by a number of separate processes.
A distributed system can be thought of as an extension of the client server concept where the servers are remote.
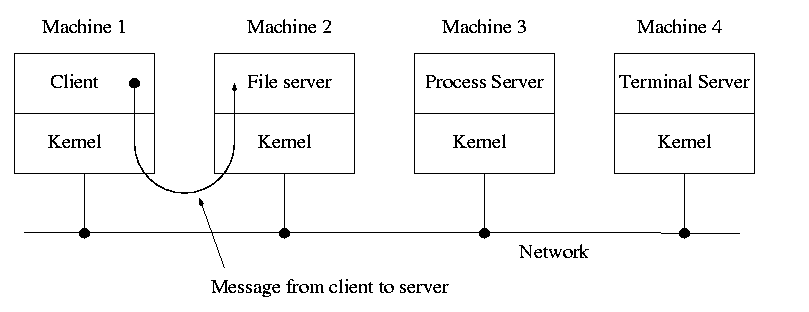
Today with plentiful memory, each machine would have all the different servers. So the only reason am OS-internal message would go to another computer is if the originating process wished to communicate with a specific process on that computer (for example wanted to access a remote disk).
Distributes systems are becoming increasingly important for application programs. Perhaps the program needs data found only on certain machine (no one machine has all the data). For example, think of (legal, of course) file sharing programs.
Homework: 24
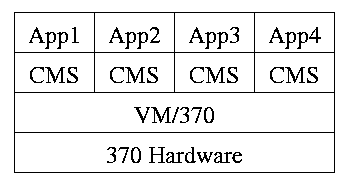
Use a hypervisor
(i.e., beyond supervisor, i.e. beyond a
normal OS) to switch between multiple
Operating Systems.
A more modern name for a hypervisor is a
Virtual Machine Monitor (VMM)
.
The hypervisor idea was made popular by IBM's CP/CMS (now VM/370). CMS stood for Cambridge Monitor System since it was developed at IBM's Cambridge (MA) Science. It was renamed, with the same acronym (an IBM specialty, cf. RAID) to Conversational Monitor System.
Recently, virtual machine technology has moved to machines (notably
x86) that are not fully virtualizable.
Recall that when CMS executed a privileged instruction, the hardware
trapped to the real operating system.
On x86, privileged instructions are ignored when executed
in user mode, so running the guest OS in user mode won't work.
Bye bye (traditional) hypervisor.
But a new style emerged where the hypervisor runs, not on the
hardware, but on the host operating system.
See the text for a sketch of how this (and another idea
paravirtualization
) works.
An important academic advance was Disco from Stanford that led to
the successful commercial product VMware.
Both AMD and Intel have extended the x86 architecture to better support virtualization. The newest processors produced today (2008) by both companies now support an additional (higher) privilege mode for the VMM. The guest OS now runs in the old privileged mode (for which it was designed) and the hypervisor/VMM runs in the new higher privileged mode from which it is able to monitor the usage of hardware resources by the guest operating system(s).
The idea is that a new (rather simple) computer architecture called the Java Virtual Machine (JVM) was invented but not built (in hardware). Instead, interpreters for this architecture are implemented in software on many different hardware platforms. Each interpreter is also called a JVM. The java compiler transforms java into instructions for this new architecture, which then can be interpreted on any machine for which a JVM exists.
This has portability as well as security advantages, but at a cost in performance.
Of course java can also be compiled to native code for a particular hardware architecture and other languages can be compiled into instructions for a software-implemented virtual machine (e.g., pascal with its p-code).
Similar to VM/CMS but the virtual machines have disjoint resources (e.g., distinct disk blocks) so less remapping is needed.
Assumed knowledge.
Assumed knowledge.
Mostly assumed knowledge. Linker's are very briefly discussed. Our earlier discussion was much more detailed.
Extremely brief treatment with only a few points made about the running of the operating itself.
Skipped
Skipped
Assumed knowledge. Note that what is covered is just the prefixes, i.e. the names and abbreviations for various powers of 10.
Skipped, but you should read and be sure you understand it (about 2/3 of a page).
Tanenbaum's chapter title is Processes and Threads
.
I prefer to add the word management.
The subject matter is processes, threads, scheduling, interrupt
handling, and IPC (InterProcess Communication—and
Coordination).
Definition: A process is a program in execution.
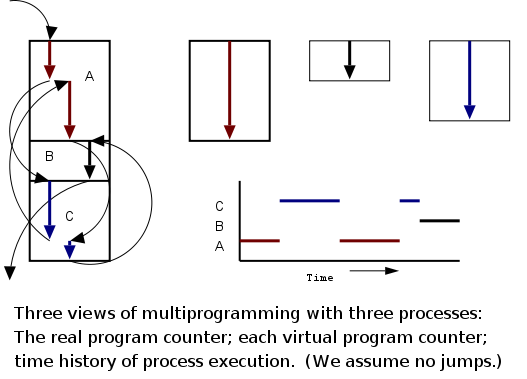
Even though in actuality there are many processes running at once, the OS gives each process the illusion that it is running alone.
overheadvirtual time occurs.)
Virtual time and virtual memory are examples of abstractions provided by the operating system to the user processes so that the latter experiences a more pleasant virtual machine than actually exists.
From the users' or external viewpoint there are several mechanisms for creating a process.
But looked at internally, from the system's viewpoint, the second method dominates. Indeed in early Unix only one process is created at system initialization (the process is called init); all the others are decendents of this first process.
Why have init?
That is why not have all processes created via method 2?
Ans: Because without init there would be no running process to create
any others.
Many systems have daemon
process lurking around to perform
tasks when they are needed.
I was pretty sure the terminology was related to mythology, but
didn't have a reference until a student found
The {Searchable} Jargon Lexicon
at http://developer.syndetic.org/query_jargon.pl?term=demon
daemon: /day'mn/ or /dee'mn/ n. [from the mythological meaning, later rationalized as the acronym `Disk And Execution MONitor'] A program that is not invoked explicitly, but lies dormant waiting for some condition(s) to occur. The idea is that the perpetrator of the condition need not be aware that a daemon is lurking (though often a program will commit an action only because it knows that it will implicitly invoke a daemon). For example, under {ITS}, writing a file on the LPT spooler's directory would invoke the spooling daemon, which would then print the file. The advantage is that programs wanting (in this example) files printed need neither compete for access to nor understand any idiosyncrasies of the LPT. They simply enter their implicit requests and let the daemon decide what to do with them. Daemons are usually spawned automatically by the system, and may either live forever or be regenerated at intervals. Daemon and demon are often used interchangeably, but seem to have distinct connotations. The term `daemon' was introduced to computing by CTSS people (who pronounced it /dee'mon/) and used it to refer to what ITS called a dragon; the prototype was a program called DAEMON that automatically made tape backups of the file system. Although the meaning and the pronunciation have drifted, we think this glossary reflects current (2000) usage.
As is often the case, wikipedia.org proved useful. Here is the first paragraph of a more thorough entry. The wikipedia also has entries for other uses of daemon.
In Unix and other computer multitasking operating systems, a daemon is a computer program that runs in the background, rather than under the direct control of a user; they are usually instantiated as processes. Typically daemons have names that end with the letter "d"; for example, syslogd is the daemon which handles the system log.
Again from the outside there appear to be several termination mechanism.
And again, internally the situation is simpler.
In Unix
terminology, there are two system calls kill and
exit that are used. Kill (poorly named in my view) sends a
signal to another process.
If this signal is not caught (via the
signal system call) the process is terminated.
There is also an uncatchable
signal.
Exit is used for self termination and can indicate success or
failure.
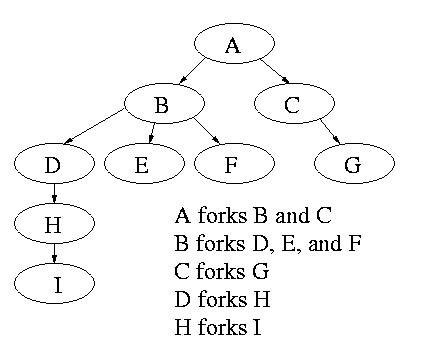
Modern general purpose operating systems permit a user to create and destroy processes.
Old or primitive operating system like MS-DOS are not fully multiprogrammed, so when one process starts another, the first process is automatically blocked and waits until the second is finished. This implies that the process tree degenerates into a line.
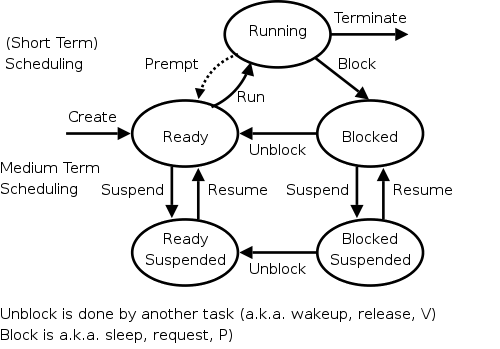
The diagram on the right contains much information. I often include it on exams.
Homework: 1.
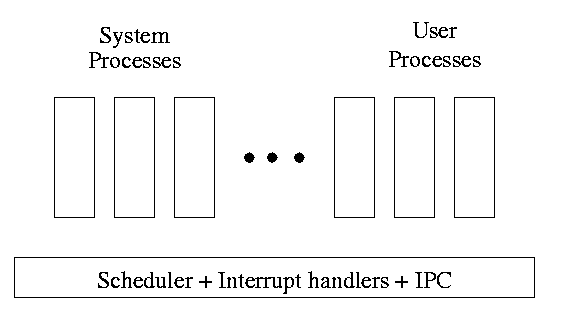 One can organize an OS around the scheduler.
One can organize an OS around the scheduler.
kernel(a micro-kernel) consisting of the scheduler, interrupt handlers, and IPC (interprocess communication).
Minixoperating system works this way.
The OS organizes the data about each process in a table naturally called the process table. Each entry in this table is called a process table entry or process control block (PCB).
(I have often referred to a process table entry as a PTE, but this is bad since I also use PTE for Page Table Entry. Because the latter usage is very common, I must stop using PTE to abbreviate the former. Please correct me if I slip up.)
Characteristics of the process table.
an active entity becomes a data structure when looked at from a lower level.
This should be compared with the addenda on transfer of control and trap.
In a well defined location in memory (specified by the hardware) the OS stores an interrupt vector, which contains the address of the interrupt handler.
Assume a process P is running and a disk interrupt occurs for the completion of a disk read previously issued by process Q, which is currently blocked. Note that disk interrupts are unlikely to be for the currently running process (because the process that initiated the disk access is likely blocked).
this instruction caused the interrupt.
program, namely the OS, and hence might well be using the same variables. We will soon see how this can cause great problems even in what appear to be trivial cases.
Consider a job that is unable to compute (i.e., it is waiting for I/O) a fraction p of the time.
There are at least two causes of inaccuracy in the above modeling procedure.
Nonetheless, it is correct that increasing MPL does increase CPU utilization up to a point.
An important limitation is memory. That is, we assumed that we have many jobs loaded at once, which means we must have enough memory for them. There are other memory-related issues as well and we will discuss them later in the course.
Homework: 5.
| Per process items | Per thread items |
|---|---|
| Address space | Program counter |
| Global variables | Machine registers |
| Open files | Stack |
| Child processes | |
| Pending alarms | |
| Signals and signal handlers | |
| Accounting information |
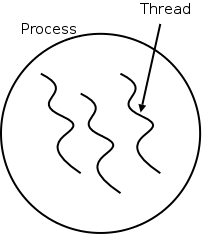
The idea behind threads to have separate threads of control (hence the name) running in the address space of a single process as shown in the diagram to the right. An address space is a memory management concept. For now think of an address space as the memory in which a process runs. (In reality it also includes the mapping from virtual addresses, i.e., addresses in the program, to physical addresses, i.e., addresses in the machine. The table on the left shows which properties are common to all threads in a given process and which properties are thread specific.
Each thread is somewhat like a process (e.g., it shares the processor with other threads) but a thread contains less state than a process (e.g., the address space belongs to the process in which the thread runs.)
Often, when a process P executing an application is blocked (say for I/O), there is still computation that can be done for the application. Another process can't do this computation since it doesn't have access to P's memory. But two threads in the same process do share memory so that problem doesn't occur.
An important modern example is a multithreaded web server.
Each thread is responding to a single WWW connection.
While one thread is blocked on I/O, another thread can be processing
another WWW connection.
Question: Why not use separate processes, i.e.,
what is the shared memory?
Answer: The cache of frequently referenced pages.
A common organization for a multithreaded application is to have a dispatcher thread that fields requests and then passes each request on to an idle worker thread. Since the dispatcher and worker share memory, passing the request is very low overhead.
Another example is a producer-consumer problem (see below) in which we have 3 threads in a pipeline. One thread reads data from an I/O device into an input buffer, the second thread performs computation on the input buffer and places results in an output buffer, and the third thread outputs the data found in the output buffer. Again, while one thread is blocked the others can execute.
Really you want 2 (or more) input buffers and 2 (or more) output buffers. Otherwise the middle thread would be using all the buffers and would block both outer threads.
Question: When does each thread block?
Answer:
A final (related) example is that an application wishing to perform automatic backups can have a thread to do just this. In this way the thread that interfaces with the user is not blocked during the backup. However some coordination between threads may be needed so that the backup is of a consistent state.