Start Lecture #2
They are Machine Independent.
This is clear.
They are easier to use and understand.
This is clearly true but the exact reasons are not clear. Many studies have shown that the number ofbugs per line of code is roughly constant between low- and high-level languages. Since low-level languages need more lines of code for the same functionality, writing a programs using these languages results in more bugs.
Studies also support the statement that programs can be written quicker in high-level languages (comparable number of documented lines of code per day for high- and low-level languages).
What is not clear is exactly what aspects of high-level languages are the most important and hence how should such languages be designed. There has been some convergence, which will be reflected in the course, but this is not a dead issue.
A name is an identifier, i.e., a string of characters (with some restrictions) that represents something else.
Many different kinds of things can be named, for example.
Names are an important part of abstraction.
procedure Demo is
type Color is (Red, Blue, Green, Purple, White, Black);
type ColorMatrix is array (Integer range <>, Integer range <>) of Color;
subtype ColorMatrix10 is ColorMatrix(0..9,0..9);
A : ColorMatrix10;
B : ColorMatrix(3..8, 6..12);
begin
A(2,3) := Red;
B(4,11) := Blue;
end Demo;
In general a binding is as association of two things. We will be interesting in binding a name to the thing it names and will see that a key question is when does this binding occur. The answer to that question is called the binding time.
There is quite a range of possibilities. The following list is ordered from early binding to late binding.
A+B+C.
procedure Demo is
X : Integer;
begin
X := 3;
declare
type Color is (Red, Blue, Green, Purple, White, Black);
type ColorMatrix is array (Integer range <>, Integer range <>) of Color;
subtype ColorMatrix10 is ColorMatrix(0..9,0..9);
A : ColorMatrix10;
B : ColorMatrix(X..8, 6..12); -- could not be bound at start
begin
A(2,3) := Red;
A(2,X) := Red; -- Same as previous statement
B(4,11) := Blue;
end;
X := 4;
end Demo;
Static binding refers to binding performed
prior to run time.
Dynamic binding refers to binding performed
during run time.
These terms are not very precise since there are many times
prior to run time, and run time itself covers several times
.
Run time is generally reduced if we can compile, rather than interpret, the program. It is typically further reduced if the compiler can make more decisions rather than deferring them to run time, i.e., if static binding can be used.
Summary: The earlier (binding time) decisions are made, the better the code that the compiler can produce.
Early binding times are typically associated with compiled languages while late binding times are typically associated with interpreted languages.
The compiler is easier to implement if there are bindings done even earlier than compile time
We shall see, however, that dynamic binding gives added flexibility.
For one example, late-binding languages
like Smalltalk, APL,
and most scripting languages permit polymorphism: The same code can
be executed on objects of different types.
Moreover, late-binding gives control to the programmer since they control run time. This gives increased flexibility when compared to early-binding, which is done by the compiler or language designer.
We use the term lifetime to refer to the interval between creation and destruction.
For example, the interval between the binding's creation and destruction is the binding's lifetime. For another example, the interval between the creation and destruction of an object is the object's lifetime.
How can the binding lifetime differ from the object lifetime?
There are three primary mechanisms used for storage allocation:
We study these three in turn.
This is the simplest and least flexible of the allocation mechanisms. It is designed for objects whose lifetime is the entire program execution.
The obvious examples are global variables. These variables are bound once at the beginning and remain bound until execution ends; that is their object and binding lifetimes are the entire execution.
Static binding permits slightly better code to be compiled (for some architectures and compilers) since the addresses are computable at compile time.
In a (perhaps overzealous) attempt to achieve excellent run time performance, early versions of the Fortran language were designed to permit static allocation of all objects.
The price of this decision was high.
Before condemning this decision, one must remember that, at the time Fortran was introduced (mid 1950s), it was believed by many to be impossible for a compiler to turn out high-quality machine code. The great achievement of Fortran was to provide the first significant counterexample to this mistaken belief.
For languages supporting recursion (which includes recent versions of Fortran), the same local variable name can correspond to multiple objects corresponding to the multiple instantiations of the recursive procedure containing the variable. Thus a static implementation is not feasible and stack-based allocation is used instead. These same considerations apply to compiler-generated temporaries, parameters, and the return value of a function.
If a constant is constant throughout execution (what??, see below), then it can be stored statically, even if used recursively or by many different procedures. These constants are often called manifest constants or compile time constants.
In some languages a constant is just an object whose value doesn't change (but whose lifetime can be short). In ada
loop
declare
v : integer;
begin
get(v); -- input a value for v
declare
c : constant integer := v; -- c is a "constant"
begin
v := 5; -- legal; c unchanged.
c := 5; -- illegal
end;
end;
end loop;
For these constants static allocation is again not feasible.
This mechanism is tailored for objects whose lifetime is the same
as the block/procedure in which it is declared.
Examples include local variables, parameters, temporaries, and
return values.
The key observation is that the lifetimes of such objects obey a
LIFO (stack-like) discipline:
If object A is created prior to object B, then A will be
destroyed no earlier than B
.
When procedure P is invoked the local variables, etc for P are allocated together and are pushed on a stack. This stack is often called the control stack and the data pushed on the stack for a single invocation of a procedure/block is called the activation record or frame of the invocation.
When P calls Q, the frame for Q is pushed on to the stack, right after the frame for P and the LIFO lifetime property guarantees that we will remove frames from the stack in the safe order (i.e., will always remove (pop) the frame on the top of the stack.
This scheme is very effective, but remember it is only for objects with LIFO lifetimes. For more information, see any compiler book or my compiler notes.
What if we don't have LIFO lifetimes and thus cannot use stack-based allocation methods? Then we use heap-based allocation, which just means we can allocate and destroy objects in any order and with lifetimes unrelated to program/block entry and exit.
A heap is a region of memory from which allocations and destructions can be performed at arbitrary times.
Remark: Please do not confuse these heaps with the heaps you may have learned in a data structures course. Those (data-structure) heaps are used to implement priority queues; they are not used to implement our heaps.
What objects are heap allocated
?
The question is how do respond to allocate/destroy commands? Looked at from the memory allocators viewpoint, the question is how to implement requests and returns of memory blocks (typically, the block returned must be one of those obtained by a request, not just a portion of a requested block).
Note that, since blocks are not necessarily returned in LIFO order, the heap will have not simply be a region of allocated memory and another region of available memory. Instead it will have free regions interleaved with allocated regions.
So the first question becomes, when a request arrives, which region should be (partially) uses to satisfy it. Each algorithmic solution to this question (e.g., first fit, best fit, worst fit, circular first fit, quick fit, buddy, Fibonacci) also includes a corresponding algorithm for processing the return of a block.
What happens when the user no longer needs the heap-allocated space?
Poorly done manual deallocation is a common programming error.
We can run out of heap space for at least three different reasons.
The 3e covers garbage collection twice. It is covered briefly here in 3.2.4 and in more depth in 7.7.3. My coverage here contains much of 7.7.3.
A garbage collection algorithm is one that automatically deallocates heap storage when it is no longer needed.
It should be compared to manual deallocation functions such as free(). There are two aspects to garbage collection: first, determining automatically what portions of heap allocated storage will (definitely) not be used in the future, and second making this unneeded storage available for reuse.
After describing the pros and cons of garbage collection, we describe several of the algorithms used.
We start with the negative. Providing automatic reclamation of unneeded storage is an extra burden for the language implementer.
More significantly, when the garbage collector is running, machine resources are being consumed. For some programs the garbage collection overhead can be a significant portion of the total execution time. If, as is often the case, the programmer can easily tell when the storage is no longer needed, it is normally much quicker for the programmer to free it manually than to have a garbage collector do it.
Homework: What would characterizes programs for which garbage collection causes significant overhead?
The advantages of garbage collection are quite significant (perhaps they should be considered problems with manual deallocation). Unfortunately, there are often times when it seems obvious that storage is no longer needed; but it fact it used later. The mistaken use of previously freed storage is called a dangling reference. One possible cause is that the program is changed months later and a new use is added.
Another problem with manual deallocation is that the user may forget to do it. This bug, called a storage leak might only turn up in production use when the program is run for an extended period. That is if the program leaks 1KB/sec, you might well not notice any problem during test runs of 5 minutes, but a production run may crash (or begin to run intolerably slowly) after a month.
The balance is swinging in favor of garbage collection.
This is perhaps the simplest scheme, but misses some of the garbage.
Remarks:
The idea is to find the objects that are live and then reclaim all dead objects.
A heap object is live if it can be reached starting from a non-heap object and following pointers. The remaining heap objects are dead. That is, we start at machine registers, stack variables and constants, and static variables and constants that point to heap objects. These starting places are called roots. It is assumed that pointers to heap objects can be distinguished from other objects (e.g., integers).
The idea is that for each root
we preform a graph traversal
following all pointers.
Everything we find this way is live; the rest is dead.
This is a two phase algorithm as the name suggests and basically follows the idea just given: We mark live objects during the mark phase and reclaim dead ones during the sweep phase.
It is assumed that each object has an extra mark
bit.
The code below defines a procedure mark(p), which uses the mark bit.
Please don't confuse the uses of the name mark as both a procedure
and a bit.
Procedure GC is
for each root pointer p
mark(p)
sweep
for each root pointer p
p.mark := false
Procedure mark(p) is
if not p.mark -- i.e. if the mark bit is not set
p.mark := true
for each pointer p.x -- i.e. each ptr in obj pointed to by p
mark(p.x) -- i.e. invoke the mark procedure on x recursively
Procedure sweep is
for each object x in the heap
if not x.mark
insert(x,free_list)
else
x.mark := false
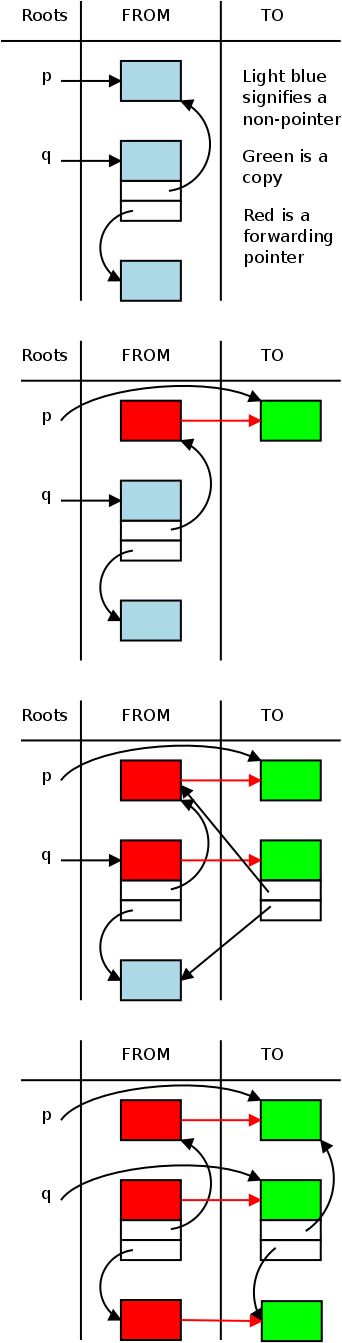
A performance problem with mark-and-sweep is that it moves each dead object (i.e., each piece of garbage). Since experimental data from LISP indicates that, when garbage collection is invoked, about 2/3 of the heap is garbage, it would be better to leave the garbage alone and move the live data instead. That is the motivation for stop-and-copy.
Divide the heap into two equal size pieces, often called
FROM
and TO
.
Initially, all allocations are performed using FROM; TO is unused.
When FROM is (nearly) full, garbage collection is performed.
During the collection, all the live data is moved from FROM to TO.
Naturally the pointers must now point to TO.
The tricky part is that live data may move while there are still
pointers to it.
For this reason a forwarding address
is left in FROM.
Once, all the data is moved, we flip the names FROM and TO and
resume program execution.
Procedure GC is
for each root pointer p
p := traverse(p)
Procedure traverse is
if p.ALL is a forwarding address
p := the forwarding address in p.ALL
return p
else
newP := copy(p,TO)
p.ALL := newP -- write forwarding address
for each pointers x in newP.ALL
newP.x := traverse(newP.x)
return newP
The movie on the right illustrates stop and copy in action.
Remarks
procedure f is
x : integer;
begin
x := 4;
declare
x : float;
begin
x := 21.75;
end;
end f;
Homework: CYU p. 121 (2, 4, 9)
Homework: Give a program in C that would not work if local variables were statically.
The region of program text where a binding is active is called the scope of the binding.
Note that this can be different from the lifetime. The lifetime of the outer x in the example on the right is all of procedure f, but the scope of that x has a hole where the inner x hides the binding. We shall see below that in some languages, the hole can be filled.
procedure main is
x : integer := 1;
procedure f is
begin
put(x);
end f;
procedure g is
x : integer := 2;
begin
f;
end g;
begin
g;
end main;
Before we begin in earnest, I thought a short example might be helpful. What is printed when the procedure main on the right is run?
That looks pretty easy, main just calls g, g just calls f, and f just prints (put is ada-speak for print) x. So x is printed.
Sure, but which x? There are, after all, two of them. Is is ambiguous, i.e., erroneous?
Since this section about scope, we see that the question is which x is in scope at the put(x) call? Is it the one declared in main, inside of which f is defined, or is the one inside g, which calls f, or is it both, or neither?
For some languages, the answer is the x declared in main and for others it is the x declared in g. The program is actually written in Ada, which is statically scoped (a.k.a. lexically scoped) and thus gives the answer 1.
How about Scheme, a dialect of lisp?
(define x 1)
(define f (lambda () x))
(define g (lambda () (let ((x 2)) (f))))
We get the same result: when g is evaluated, 1 is printed.
Scheme, like, ada, C, Java, C++, C#, ... is statically scoped.
Is every language statically scoped? No, some dialects of Lisp are dynamically scoped, as is Snobol, Tex, and APL. In Perl the programmer gets to choose.
(setq x 1)
(defun f () x)
(defun g () (let ((x 2)) (f)))
In particular, the last program on the right, which is written in
emacs lisp, gives 2 when g is evaluated.
The two Lisps are actually more similar that they might appear on
the right:
The emacs Lisp defun (which stands for "define function") is
essentially a combination of Scheme's define and lambda.
In static scoping, the binding of a name can be determined by reading the program text; it does not depend on the execution. Thus it can be determined at compile time.
The simplest situation is the one in early versions of Basic: There is only one scope, the whole program. Recall, that early basic was intended for tiny programs. I believe variable names were limited to two characters, a letter optionally follow by a digit. For large programs a more flexible approach is needed, as given in the next section.
The typical situation is that the relevant binding for a name is the one that occurs in the smallest containing block and the scope of the binding is that block.
So the rule for finding the relevant binding is to look in the current block (I consider a procedure/function definition to be a block). If the name is found, that is the binding. If the name is not found, look in the immediately enclosing scope and repeat until the name is found. If the name is not found at all, the program is erroneous.
What about built in names such as type names (Integer, etc), standard functions (sin, cos, etc), or I/O routines (Print, etc)? It is easiest to consider these as defined in an invisible scope enclosing the entire program.
Given a binding B in scope S, the above rules can be summarized by the following two statements.
Some languages have facilities that enable the programmer to reference bindings that would otherwise be hidden by statement 1 above. For example
procedure outer is procedure outer is
x : integer := 6; x : integer := 6;
procedure inner is procedure inner is
begin x : integer := 88;
put(x); begin
end inner; put(x,outer.x);
begin end inner;
inner; begin
end outer; inner;
end outer2;
Consider first two easy cases of nested scopes illustrated on the right with procedures outer and inner. How does the left execution of inner find the binding to x? How does the right execution of inner find both bindings of x? We need a link from the activation record of the inner to the activation record of outer. This is called the static link or the access link.
But it is actually more difficult than that. The static link must point to the most recent invocation of the surrounding subroutine.
Of course the nesting can be deeper; but that just means following a series of static links from one scope to the next outer one. Moreover, finding the most recent invocation of outer is not trivial; for example, inner may have been called by a routine nested inside inner. For the details see a compilers book or my course notes.
There are several questions here.
procedure <declarations> begin <statements> end;
declare <declarations> begin <statements> end;
In C, C++, and java the answer is no.
The following is legal.
int z; z=4; int y;
int z=4; int y=z;
int y; y=z; int z=4;
In Java, Ada, C, C++ they start at the declaration so the
example above is illegal.
In JavaScript and Modula3 they start at the beginning of the
block so the above is legal.
In Pascal the declaration starts at block beginning, but can't
be used before it is declared.
This has a weird effect:
In inner declaration hides an outer declaration but can't be
used in earlier statements of the inner.
Scheme uses let, let* and letrec to introduce a nested scope. The variables named are given initial values. In the simple case where the initial values are manifest constants, the three let's are the same.
(let ( (x 2)(y 3) ) body) ; eval body using new variables x=2 & y=3
We will study the three when we do scheme.
For now, I just add that for letrec the scope of each declaration is
the whole block (including the preceding declarations, so x and y
can depend on each other), for let* the scope starts at the
declaration (so y can depend on x, but not the reverse) and for let
the declarations start at the body (so neither y nor x can depend on
the other).
The above is somewhat oversimplified.
Homework: 5, 6(a).
Many languages (e.g., C, C++, Ada) require names to be declared before they are used, which causes problems for recursive definitions. Consider a payroll program with employees and managers.
procedure payroll is
type Employee;
type Manager is record
Salary : Float;
Secretary : access Employee; -- access is ada-speak for pointer
end record;
type Employee is record
Salary : Float;
Boss : access Manager;
end record;
end payroll;
These languages introduce a distinction between a declaration, which simply introduces the name and indicates its scope, and a definition, which fully describes the object to which the name is bound.
Essentially all the points made above about nested procedures
applies to nested blocks as well.
For example the code on the right, using nested blocks, exhibits the
same hole in the scope
as does the code on the left, using
nested procedures.
procedure outer is declare
x : integer; x : integer;
procedure inner is begin
x : float: -- start body of outer x is integer
begin declare
-- body of inner x : float;
end inner; begin
begin -- body of inner, x is float
-- body of outer end;
end outer; -- more of body of outer. x again integer
end;
Some (mostly interpreted) languages permit a redeclaration in which a new binding is created for a name already bound in the scope. Does this new binding start at the beginning of the scope or just where the redeclaration is written?
int f (int x) { return x+10; }
int g (int x) { return f(x); }
g(0)
int f (int x) { return x+20; }
g(5);
Consider the code on the right.
The evaluation of g(0) uses the first definition of f and returns
10.
Does the evaluation of g(5) use the first f, the one in effect when
g was defined, or does it use the second f, the one in effect when
g(5) was invoked.
The answer is: it depends. For most languages supporting redeclaration, the second f is used; but in ML it is the first. In other words for most languages the redeclaration replaces the old in all contexts; in ML it replaces the old only in later uses, not previous ones. This has some of the flavor of static vs. dynamic scoping.
Will be done later.
Will be done later.
We covered dynamic scoping already.