Start Lecture #10
Remark: Lab 4 (the last lab) is assigned).
A local PRA is one is which a victim page is chosen among the pages of the same process that requires a new frame. That is the number of frames for each process is fixed. So LRU for a local policy means the page least recently used by this process. A global policy is one in which the choice of victim is made among all pages of all processes.
In general a global policy seems to work better. For example, consider LRU. With a local policy, the local LRU page might have been more recently used than many resident pages of other processes. A global policy needs to be coupled with a good method to decide how many frames to give to each process. By the working set principle, each process should be given |w(k,t)| frames at time t, but this value is hard to calculate exactly.
If a process is given too few frames (i.e., well below |w(k,t)|), its faulting rate will rise dramatically. If this occurs for many or all the processes, the resulting situation in which the system is doing very little useful work due to the high I/O requirements for all the page faults is called thrashing.
An approximation to the working set policy that is useful for determining how many frames a process needs (but not which pages) is the Page Fault Frequency algorithm.
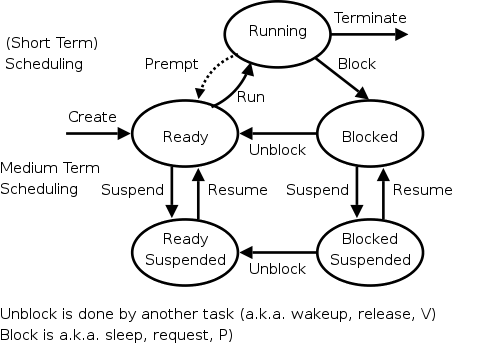
To reduce the overall memory pressure, we must reduce the multiprogramming level (or install more memory while the system is running, which is not possible with current technology). That is, we have a connection between memory management and process management. These are the suspend/resume arcs we saw way back when and are shown again in the diagram on the right.
When the PFF (or another indicator) is too high, we choose a process and suspend it, thereby swapping it to disk and releasing all its frames. When the frequency gets low, we can resume one or more suspended processes. We also need a policy to decide when a suspended process should be resumed even at the cost of suspending another.
This is called medium-term scheduling. Since suspending or resuming a process can take seconds, we clearly do not perform this scheduling decision every few milliseconds as we do for short-term scheduling. A time scale of minutes would be more appropriate.
Page size must
be a multiple of the disk block size.
Why?
Answer: When copying out a page if you have a partial disk block, you
must do a read/modify/write (i.e., 2 I/Os).
Characteristics of a large page size.
We will learn later this term that the total time for performing 8 I/O operations each of size 1KB is much larger that the time for a single 8KB I/O. Hence it is better to swap in/out one big page than several small pages.
But if the page is too big you will be swapping in data that are not local and hence might well not be used.
sqrt(2 * process size * size of PTE)
Since the term inside the sqrt is typically megabytes, we see
that modern practice of having the page size a few kilobytes
is near the minimum point.regionsthan the number of (large) frames that the process has been allocated.
A small page size has the opposite characteristics.
Homework: Consider a 32-bit address machine using paging with 8KB pages and 4 byte PTEs. How many bits are used for the offset and what is the size of the largest page table? Repeat the question for 128KB pages.
This was used when machine have very small virtual address spaces. Specifically the PDP-11, with 16-bit addresses, could address only 216 bytes or 64KB, a severe limitation. With separate I and D spaces there could be 64KB of instructions and 64KB of data.
Separate I and D are no longer needed with modern architectures having large address spaces.
Permit several processes to each have the same page loaded in the same frame. Of course this can only be done if the processes are using the same program and/or data.
copy on writetechniques.
Homework: Can a page shared between two processes be read-only for one process and read-write for the other?
In addition to sharing individual pages, process can share entire library routines. The technique used is called dynamic linking and the objects produced are called shared libraries or dynamically-linked libraries (DLLs). (The traditional linking you did in lab1 is today often called static linking).
changeeven when they haven't changed.
copiesof the module). Instead position-independent code must be used. For example, jumps within the module would use PC-relative addresses.
The idea of memory-mapped files is to use the mechanisms in place for demand paging (and segmentation, if present) to implement I/O.
A system call is used to map a file into a portion of the address
space.
(No page can be part of a file and part of regular
memory;
the mapped file would be a complete segment if segmentation is
present).
The implementation of demand paging we have presented assumes that the entire process is stored on disk. This portion of secondary storage is called the backing store for the pages. Sometimes it is called a paging disk. For memory-mapped files, the file itself is the backing store.
Once the file is mapped into memory, reads and writes become loads and stores.
Done earlier
The only point to add is now that we know replacement algorithms one can suggest an implementation. If a clock-like algorithm is used for victim selection, one can have a two handed clock with one hand (the paging daemon) staying ahead of the other (the one invoked by the need for a free frame).
The front hand simply writes out any page it hits that is dirty and thus the trailing hand is likely to see clean pages and hence is more quickly able to find a suitable victim.
Unless specifically requested, you may ignore paging daemons when answering exam questions.
Skipped.