Start Lecture #27
Remark: I added an example above answering the question raised last time about minor numbers.
Buffering is necessary since requests come in a size specified by the user and data is delivered by reads and accepted by writes in a size specified by the device. It is also important so that a user process using getchar() is not blocked and unblocked for each character read.
The text describes double buffering and circular buffers, which are important programming techniques, but are not specific to operating systems.
Skipped.
The system must enforce exclusive access for non-shared devices like CD-ROMs.
A good deal of I/O software is actually executed by unprivileged code running in user space. This code includes library routines linked into user programs, standard utilities, and daemon processes.
If one uses the strict definition that the operating system consists of the (supervisor-mode) kernel, then this I/O code is not part of the OS. However, very few use this strict definition.
Some library routines are very simple and just move their arguments into the correct place (e.g., a specific register) and then issue a trap to the correct system call to do the real work.
I think everyone considers these routines to be part of the operating system. Indeed, they implement the published user interface to the OS. For example, when we specify the (Unix) read system call by
count = read (fd, buffer, nbytes)
as we did in chapter 1, we are really
giving the parameters and accepting the return value of such a
library routine.
Although users could write these routines, it would make their programs non-portable and would require them to write in assembly language since neither trap nor specifying individual registers is available in high-level languages.
Other library routines, notably standard I/O (stdio) in Unix, are definitely not trivial. For example consider the formatting of floating point numbers done in printf and the reverse operation done in scanf.
In unix-like systems the graphics libraries and the gui itself are outside the kernel. Graphics libraries are quite large and complex. In windows, the gui is inside the kernel.
Printing to a local printer is often performed in part by a regular program (lpr in Unix) that copies (or links) the file to a standard place, and in part by a daemon (lpd in Unix) that reads the copied files and sends them to the printer. The daemon might be started when the system boots.
Note that this implementation of printing uses spooling, i.e., the file to be printed is copied somewhere by lpr and then the daemon works with this copy. Mail uses a similar technique (but generally it is called queuing, not spooling).
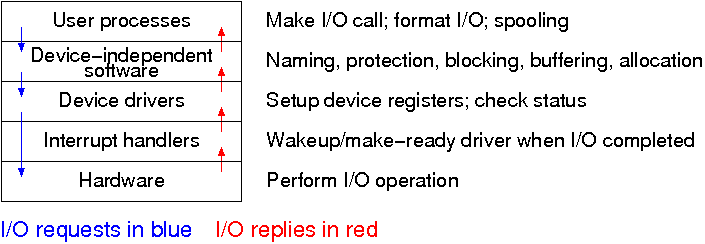
The diagram on the right shows the various layers and some of the actions that are performed by each layer.
The arrows show the flow of control. The blue downward arrows show the execution path made by a request from user space eventually reaching the device itself. The red upward arrows show the response, beginning with the device supplying the result for an input request (or a completion acknowledgement for an output request) and ending with the initiating user process receiving its response.
Homework: 11, 13.
The ideal storage device is
When compared to central memory, disks are big and cheap, but slow.
Show a real disk opened up and illustrate the components.
Consider the following characteristics of a disk.
Remark: A practice final is available off the web page. Note the format and good luck.
Overlapping I/O operations is important when the system has more than one disk. Many disk controllers can do overlapped seeks, i.e. issue a seek to one disk while another disk is already seeking.
As technology improves the space taken to store a bit decreases, i.e., the bit density increases. This changes the number of cylinders per inch of radius (the cylinders are closer together) and the number of bits per inch along a given track.
Despite what Tanenbaum says later, it is not true that when one head is reading from cylinder C, all the heads can read from cylinder C with no penalty. It is, however, true that the penalty is very small.
Current commodity disks for desktop computers (not for commodity laptops) require about 10ms. before transferring the first byte and then transfer about 40K bytes per ms. (if contiguous). Specifically
This is quite extraordinary. For a large sequential transfer, in the first 10ms, no bytes are transmitted; in the next 10ms, 400,000 bytes are transmitted. The analysis suggests using large disk blocks, 100KB or more.
But the internal fragmentation would be severe since many files are small. Moreover, transferring small files would take longer with a 100KB block size.
In practice typical block sizes are 4KB-8KB.
Multiple block sizes have been tried (e.g. blocks are 8KB but a
file can also have fragments
that are a fraction of
a block, say 1KB).
Some systems employ techniques to encourage consecutive blocks of a given file to be stored near each other. In the best case, logically sequential blocks are also physically sequential and then the performance advantage of large block sizes is obtained without the disadvantages mentioned.
In a similar vein, some systems try to cluster related
files
(e.g., files in the same directory).
Homework: Consider a disk with an average seek time of 5ms, an average rotational latency of 5ms, and a transfer rate of 40MB/sec.
Originally, a disk was implemented as a three dimensional array
Cylinder#, Head#, Sector#
The cylinder number determined the cylinder, the head number
specified the surface (recall that there is one head per surface),
i.e., the head number determined the track within the cylinder, and
the sector number determined the sector within the track.
But there is something wrong here. An outer track is longer (in centimeters) than an inner track, but each stores the same number of sectors. Essentially some space on the outer tracks was wasted.
Later disks lied. They said they had a virtual geometry as above, but really had more sectors on outer tracks (like a ragged array). The electronics on the disk converted between the published virtual geometry and the real geometry.
Modern disk continue to lie for backwards compatibility, but also support Logical Block Addressing in which the sectors are treated as a simple one dimensional array with no notion of cylinders and heads.
The name and its acronym RAID came from Dave Patterson's group at Berkeley. IBM changed the name to Redundant Array of Independent Disks. I wonder why?
The basic idea is to utilize multiple drives to simulate a single larger drive, but with added redundancy.
The different RAID configurations are often called different
levels, but this is not a good name since there is no hierarchy and
it is not clear that higher levels are better
than low ones.
However, the terminology is commonly used so I will follow the trend
and describe them level by level, but having very little to say
about some levels.