Operating Systems
Start Lecture #26
Since PIO is pure software it is easier to change, which is an
advantage.
DMA does need a number of bus transfers from the CPU to the
controller to specify the DMA.
So DMA is most effective for large transfers where the setup is
amortized.
Why have the buffer?
Why not just go from the disk straight to the memory?
- Speed matching.
The disk supplies data at a fixed rate, which might exceed the
rate the memory can accept it.
In particular the memory might be busy servicing a request from
the processor or from another DMA controller.
Alternatively, the disk might supply data at a slower rate than
the memory (and memory bus) can handle thus under-utilizing an
important system resource.
- Error detection and correction.
The disk controller verifies the checksum written on the disk.
Homework: 12
5.1.5 Interrupts Revisited
Precise and Imprecise Interrupts
5.2 Principles of I/O Software
As with any large software system, good design and layering is
important.
5.2.1 Goals of the I/O Software
Device Independence
We want to have most of the OS to be unaware of the characteristics
of the specific devices attached to the system.
(This principle of device independence is not limited to I/O; we
also want the OS to be largely unaware of the CPU type itself.)
This objective has been accomplished quite well for files stored on
various devices.
Most of the OS, including the file system code, and most
applications can read or write a file without knowing if the file is
stored on a floppy disk, an internal SATA hard disk, an external
USB SCSI disk, an external USB Flash Ram, a tape, or (for reading) a
CD-ROM.
This principle also applies for user programs reading or writing
streams.
A program reading from ``standard input'', which is normally the
user's keyboard can be told to instead read from a disk file with no
change to the application program.
Similarly, ``standard output'' can be redirected to a disk file.
However, the low-level OS code dealing with disks is rather different
from that dealing keyboards and (character-oriented) terminals.
One can say that device independence permits programs to be
implemented as if they will read and write generic or abstract
devices, with the actual devices specified at run time.
Although writing to a disk has differences from writing to a
terminal, Unix cp, DOS copy, and
many programs we compose need not be aware of these differences.
However, there are devices that really are special.
The graphics interface to a monitor (that is, the graphics interface
presented by the video controller—often called a ``video
card'') does not resemble the ``stream of bytes'' we see for disk
files.
Homework:
What is device independence?
Uniform naming
We have already discussed the value of
the name space implemented by file systems.
There is no dependence between the name of the file and the device
on which it is stored.
So a file called IAmStoredOnAHardDisk might well be stored on a
floppy disk.
More interesting once a device is mounted on (Unix) directory, the
device is named exactly the same as the directory was.
So if a CD-ROM was mounted on (existing) directory /x/y, a file
named joe on the CD-ROM would now be accessible as /x/y/joe.
Error handling
There are several aspects to error handling including: detection,
correction (if possible) and reporting.
-
Detection should be done as close to where the error occurred
as possible before more damage is done (fault containment).
Moreover, the error may be obvious at the low level, but
harder to discover and classify if the erroneous data is
passed to higher level software.
-
Correction is sometimes easy, for example ECC memory does
this automatically (but the OS wants to know about the error
so that it can request replacement of the faulty chips before
unrecoverable double errors occur).
Other easy cases include successful retries for failed
ethernet transmissions.
In this example, while logging is appropriate, it is quite
reasonable for no action to be taken.
-
Error reporting tends to be awful.
The trouble is that the error occurs at a low level but by the
time it is reported the context is lost.
Creating the illusion of synchronous I/O
I/O must be asynchronous for good performance.
That is the OS cannot simply wait for an I/O to complete.
Instead, it proceeds with other activities and responds to the
interrupt that is generated when the I/O has finished.
Users (mostly) want no part of this.
The code sequence
Read X
Y = X+1
Print Y
should print a value one greater than that read.
But if the assignment is performed before the read completes, the
wrong value can easily be printed.
Performance junkies sometimes do want the asynchrony so
that they can have another portion of their program executed while
the I/O is underway.
That is, they implement a mini-scheduler in their application
code.
See this message from linux kernel
developer Ingo Molnar for his take on asynchronous IO and
kernel/user threads/processes.
You can find the entire discussion
here.
Buffering
Buffering is often needed to hold data for examination prior to
sending it to its desired destination.
Since this involves copying the data, which can be expensive,
modern systems try to avoid as much buffering as possible.
This is especially noticeable in network transmissions, where the
data could conceivably be copied many times.
- From user space to kernel space as part of the write system
call.
- From kernel space to a kernel I/O buffer.
- From the I/O buffer to a buffer on the network adaptor.
- From the adapter on the source to the adapter on the destination.
- From the destination adapter to an I/O buffer.
- From the I/O buffer to kernel space.
- From kernel space to user space as part of the read system
call.
I am not sure if any systems actually do all seven.
Sharable vs. Dedicated Devices
For devices like printers and CD-ROM drives, only one user at a
time is permitted.
These are called serially reusable devices, which
we studied in the deadlocks chapter.
Devices such as disks and ethernet ports can, on the contrary, be
shared by concurrent processes without any deadlock risk.
5.2.2 Programmed I/O
As mentioned just above, with programmed I/O the
main processor (i.e., the one on which the OS runs) moves the data
between memory and the device.
This is the most straightforward method for performing I/O.
One question that arises is how does the processor know when the
device is ready to accept or supply new data.
In the simplest implementation, the processor, when it seeks to use
a device, loops continually querying the device status, until the
device reports that it is free.
This is called polling or
busy waiting.
If we poll infrequently (and do useful work in between), there can
be a significant delay from when the previous I/O is complete to when
the OS detects the device availability.
loop
if device-available exit loop
do-useful-work
If we poll frequently (and thus are able to do little useful work
in between) and the device is (sometimes) slow, polling is clearly
wasteful.
The extreme case is where the process does nothing between polls.
For a slow device this can take the CPU out of service for a
significant period.
This bad situation leads us to ... .
5.2.3 Interrupt-Driven (Programmed) I/O
As we have just seen, a difficulty with polling is determining the
frequency with which to poll.
Another problem is that the OS must continually return to the
polling loop, i.e., we must arrange that do-useful-work takes the
desired amount of time.
Really we want the device to tell the CPU when it is available,
which is exactly what an interrupt does.
The device interrupts the processor when it is ready and an
interrupt handler (a.k.a. an interrupt service routine) then
initiates transfer of the next datum.
Normally interrupt schemes perform better than polling, but not
always since
interrupts are expensive on modern machines.
To minimize interrupts, better controllers often employ ...
5.2.4 I/O Using DMA
We discussed DMA above.
An additional advantage of dma, not mentioned above, is that the
processor is interrupted only at the end of a command not after each
datum is transferred.
Many devices receive a character at a time, but with a dma
controller, an interrupt occurs only after a buffer has been
transferred.
5.3 I/O Software Layers
Layers of abstraction as usual prove to be effective.
Most systems are believed to use the following layers (but for many
systems, the OS code is not available for inspection).
- User-level I/O routines.
- Device-independent (kernel-level) I/O software.
- Device drivers.
- Interrupt handlers.
We will give a bottom up explanation.
5.3.1 Interrupt Handlers
We discussed the behavior of an interrupt handler
before when studying page faults.
Then it was called assembly-language code
.
A difference is that page faults are caused by specific user
instructions, whereas interrupts just occur
.
However, the assembly-language code
for a page fault
accomplishes essentially the same task as the interrupt handler does
for I/O.
In the present case, we have a process blocked on I/O and the I/O
event has just completed.
So the goal is to make the process ready and then call the
scheduler.
Possible methods are.
- Releasing a semaphore on which the process is waiting.
- Sending a message to the process.
- Inserting the process table entry onto the ready list.
Once the process is ready, it is up to the scheduler to decide when
it should run.
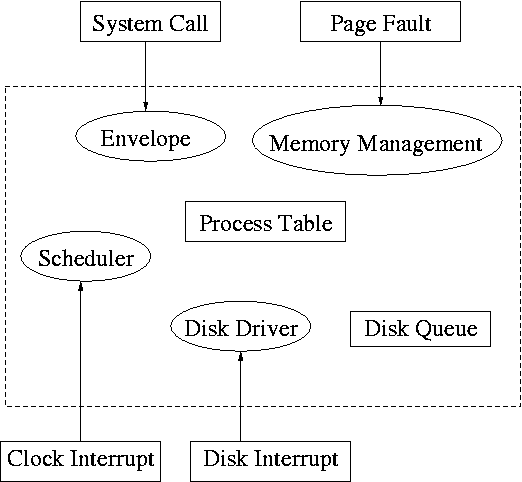
5.3.2 Device Drivers
Device drivers form the portion of the OS that is tailored to the
characteristics of individual controllers.
They form the dominant portion of the source code of the OS since
there are hundreds of drivers.
Normally some mechanism is used so that the only drivers loaded on a
given system are those corresponding to hardware actually present.
Indeed, modern systems often have loadable device drivers
,
which are loaded dynamically when needed.
This way if a user buys a new device, no changes to the operating
system are needed.
When the device is installed it will be detected during the boot
process and the corresponding driver is loaded.
Sometimes an even fancier method is used and the device can be
plugged in while the system is running (USB devices are like this).
In this case it is the device insertion that is detected by the OS
and that causes the driver to be loaded.
Some systems can dynamically unload a driver, when
the corresponding device is unplugged.
The driver has two parts
corresponding to its two access
points.
Recall the figure at the upper right, which we saw at the beginning
of the course.
- The driver is accessed by the main line OS via the envelope in
response to an I/O system call.
The portion of the driver accessed in this way is sometimes called
the
top
part.
- The driver is also accessed by the interrupt handler when the
I/O completes (this completion is signaled by an interrupt).
The portion of the driver accessed in this way is sometimes call
the
bottom
part.
In some system the drivers are implemented as user-mode processes.
Indeed, Tannenbaum's MINIX system works that way, and in previous
editions of the text, he describes such a scheme.
However, most systems have the drivers in the kernel itself and the
3e describes this scheme.
I previously included both descriptions, but have eliminated the
user-mode process description (actually I greyed it out).
Driver in a self-service paradigm
The numbers in the diagram to the right correspond to the numbered
steps in the description that follows.
The bottom diagram shows the state of processes A and B at steps 1,
6, and 9 in the execution sequence described.
What follows is the Unix-like view in which the driver is invoked
by the OS acting in behalf of a user process (alternatively stated,
the process shifts into kernel mode).
Thus one says that the scheme follows a self-service
paradigm
in that the process itself (now in kernel mode) executes the driver.
- The user (A) issues an I/O system call.
- The main line, machine independent, OS prepares a
generic request for the driver and calls (the top part of)
the driver.
- If the driver was idle (i.e., the controller was idle), the
driver writes device registers on the controller ending with a
command for the controller to begin the actual I/O.
- If the controller was busy (doing work the driver gave it
previously), the driver simply queues the current request (the
driver dequeues this request below).
- The driver jumps to the scheduler indicating that the current
process should be blocked.
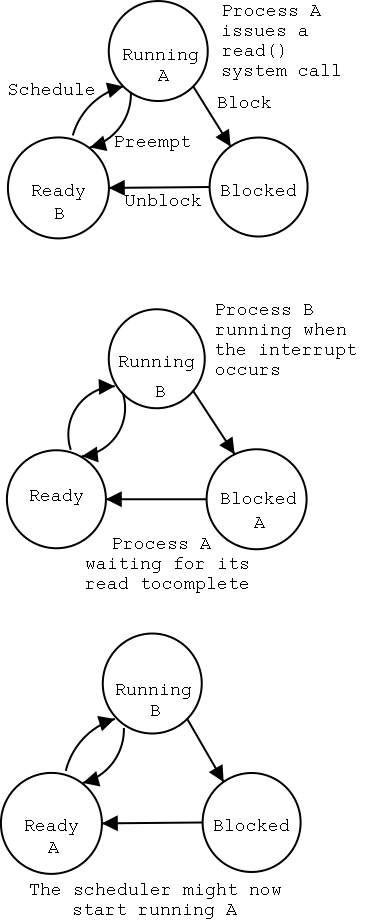
- The scheduler blocks A and runs (say) B.
- B starts running.
- An interrupt arrives (i.e., an I/O has been completed) and the
handler is invoked.
- The interrupt handler invokes (the bottom part of) the driver.
- The driver informs the main line perhaps passing data and
surely passing status (error, OK).
- The top part is called to start another I/O if the queue is
nonempty. We know the controller is free. Why?
Answer: We just received an interrupt saying so.
- The driver jumps to the scheduler indicating that process A should
be made ready.
- The scheduler picks a ready process to run. Assume it picks A.
- A resumes in the driver, which returns to the main line, which
returns to the user code.
Driver as a Process (Less Detailed Than Above)
Actions that occur when the user issues an I/O request.
- The main line OS prepares a generic request (e.g. read, not
read using Buslogic BT-958 SCSI controller) for the driver and
the driver is awakened.
Perhaps a message is sent to the driver to do both jobs.
- The driver wakes up.
- If the driver was idle (i.e., the controller is idle), the
driver writes device registers on the controller ending with a
command for the controller to begin the actual I/O.
- If the controller is busy (doing work the driver gave it), the
driver simply queues the current request (the driver dequeues this
below).
- The driver blocks waiting for an interrupt or for more
requests.
Actions that occur when an interrupt arrives (i.e., when an I/O has
been completed).
- The driver wakes up.
- The driver informs the main line perhaps passing data and
surely passing status (error, OK).
- The driver finds the next work item or blocks.
- If the queue of requests is non-empty, dequeue one and
proceed as if just received a request from the main line.
- If queue is empty, the driver blocks waiting for an
interrupt or a request from the main line.
5.3.3 Device-Independent I/O Software
The device-independent code cantains most of the I/O functionality,
but not most of the code since there are very many drivers.
All drivers of the same class (say all hard disk drivers) do
essentially the same thing in slightly different ways due to
slightly different controllers.
Uniform Interfacing for Device Drivers
As stated above the bulk of the OS code is made of device drivers
and thus it is important that the task of driver writing not be made
more difficult than needed.
As a result each class of devices (e.g. the class of all disks) has
a defined driver interface to which all drivers for that class of
device conform.
The device independent I/O portion processes user requests and calls
the drivers.
Naming is again an important O/S functionality.
In addition it offers a consistent interface to the drivers.
The Unix method works as follows
- Each device is associated with a
special
file in the
/dev directory.
- The i-nodes for these files contain an indication that these
are
special
files and also contain so called major and
minor device numbers.
- The major device number gives the number of the driver.
(These numbers are rather ad hoc, they correspond to the
position of the function pointer to the driver in a table of
function pointers.)
- The minor number indicates for which device (e.g., which scsi
cdrom drive) the request is intended.
- For example my system has two scsi disks (one is external via
USB, but that is not relevant).
The two disks are named by linux sda and sdb.
The partitions of sda are named sda1, sda2, etc.
From the following listing we can see that the scsi driver is
number 8 and that numbers are reserved for 15 partitions for
each scsi drive, which is the limit scsi supports.
The result is as follows.
allan dev # ls -l /dev/sd*
brw-r----- 1 root disk 8, 0 Apr 25 09:55 /dev/sda
brw-r----- 1 root disk 8, 1 Apr 25 09:55 /dev/sda1
brw-r----- 1 root disk 8, 2 Apr 25 09:55 /dev/sda2
brw-r----- 1 root disk 8, 3 Apr 25 09:55 /dev/sda3
brw-r----- 1 root disk 8, 4 Apr 25 09:55 /dev/sda4
brw-r----- 1 root disk 8, 5 Apr 25 09:55 /dev/sda5
brw-r----- 1 root disk 8, 6 Apr 25 09:55 /dev/sda6
brw-r----- 1 root disk 8, 16 Apr 25 09:55 /dev/sdb
brw-r----- 1 root disk 8, 17 Apr 25 09:55 /dev/sdb1
brw-r----- 1 root disk 8, 18 Apr 25 09:55 /dev/sdb2
brw-r----- 1 root disk 8, 19 Apr 25 09:55 /dev/sdb3
brw-r----- 1 root disk 8, 20 Apr 25 09:55 /dev/sdb4
allan dev #
Protection. A wide range of possibilities are
actually done in real systems.
Including both extreme examples of
everything is permitted and nothing is (directly) permitted.
- In ms-dos any process can write to any file.
Presumably, our offensive nuclear missile launchers never ran
dos.
- In IBM 360/370/390 mainframe OS's, normal processors do not
access devices.
Indeed the main CPU doesn't issue the I/O requests.
Instead an I/O channel is used and the mainline constructs a
channel program and tells the channel to invoke it.
- Unix uses normal rwx bits on files in /dev (I don't believe x
is used).