Operating Systems
Start Lecture #21
3.4.A Belady's Anomaly
Consider a system that has no pages loaded and that uses the FIFO
PRU.
Consider the following reference string
(sequences of
pages referenced).
0 1 2 3 0 1 4 0 1 2 3 4
If we have 3 frames this generates 9 page faults (do it).
If we have 4 frames this generates 10 page faults (do it).
Theory has been developed and certain PRA (so called
stack algorithms
) cannot suffer this anomaly for any
reference string.
FIFO is clearly not a stack algorithm.
LRU is.
Repeat the above calculations for LRU.
3.5 Design Issues for (Demand) Paging Systems
3.5.1 Local vs Global Allocation Policies
A local PRA is one is which a victim page is
chosen among the pages of the same process that requires a new
frame.
That is the number of frames for each process is fixed.
So LRU for a local policy means the page least recently used by this
process.
A global policy is one in which the choice of
victim is made among all pages of all processes.
- Of course we can't have a purely local policy,
why?
Answer: A new process has no pages and, even if we didn't
restrict the frame needed to a local one for the first page
loaded, the process would remain with only one page.
- Perhaps wait until a process has been running a while before
restricting it to existing frames or give the process an initial
allocation of frames based on the size of the executable.
In general a global policy seems to work better.
For example, consider LRU.
With a local policy, the local LRU page might have
been more recently used than many resident pages of
other processes.
A global policy needs to be coupled with a good method to decide how
many frames to give to each process.
By the working set principle, each process should be given |w(k,t)|
frames at time t, but this value is hard to calculate exactly.
If a process is given too few frames (i.e., well below |w(k,t)|),
its faulting rate will rise dramatically.
If this occurs for many or all the processes, the resulting
situation in which the system is doing very little useful work due
to the high I/O requirements for all the page faults is
called thrashing.
Page Fault Frequency (PFF)
An approximation to the working set policy that is useful for
determining how many frames a process needs (but not which pages)
is the Page Fault Frequency algorithm.
- For each process keep track of the page fault frequency, which
is the number of faults divided by the number of references.
- Actually, must use a window or a weighted calculation since
you are interested in the recent page fault frequency.
- Actually, it is too expensive to calculate the number of
references so, as above, we approximate this by the amount of
(virtual) time.
- If the PFF is exceptionally low, free some of this processes
frames (e.g., limit victim selection to this process for a
while).
- If the PFF is too high, allocate more frames to this process.
Either
- Raise its number of frames if using a local policy; or
- Bar its frames from eviction (for a while) and use a
global policy.
- What if there are not enough frames in the entire system?
That is, what if the PFF is too high for all processes?
Answer: Reduce the MPL as we now discuss.
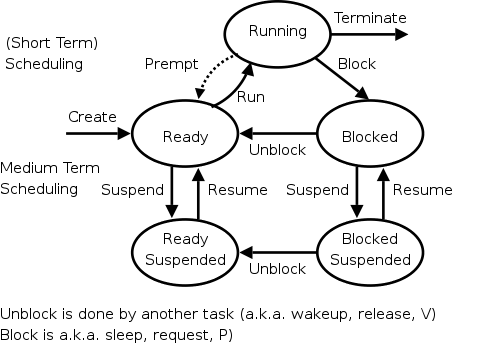
3.5.2 Load Control
To reduce the overall memory pressure, we must reduce the
multiprogramming level (or install more memory while the system is
running, which is not possible with current technology).
That is, we have a connection between memory management and process
management.
These are the suspend/resume arcs we saw way back when and are shown
again in the diagram on the right.
When the PFF (or another indicator) is too high, we choose a
process and suspend it, thereby swapping it to disk and
releasing all its frames.
When the frequency gets low, we can resume one or more
suspended processes.
We also need a policy to decide when a suspended process should be
resumed even at the cost of suspending another.
This is called medium-term scheduling.
Since suspending or resuming a process can take seconds, we clearly
do not perform this scheduling decision every few milliseconds as we
do for short-term scheduling.
A time scale of minutes would be more appropriate.
3.5.3 Page Size
Page size must
be a multiple of the disk block size.
Why?
Answer: When copying out a page if you have a partial disk block, you
must do a read/modify/write (i.e., 2 I/Os).
Characteristics of a large page size.
- Good for demand paging I/O:
We will learn later this term that the total time for
performing 8 I/O operations each of size 1KB is much larger
that the time for a single 8KB I/O.
Hence it is better to swap in/out one big page than several small
pages.
But if the page is too big you will be swapping in data that
are not local and hence might well not be used.
- Large internal fragmentation (1/2 page size).
- Small page table
(process size / page size * size of PTE).
- These last two can be analyzed together by setting the
derivative of the sum equal to 0.
The minimum overhead occurs at a page size of
sqrt(2 * process size * size of PTE)
Since the term inside the sqrt is typically megabytes, we see
that modern practice of having the page size a few kilobytes
is near the minimum point.
- A very large page size leads to very few pages.
A process will have many faults if it references
more
regions
than the number of (large) frames that the
process has been allocated.
A small page size has the opposite characteristics.
Homework: Consider a 32-bit address machine using
paging with 8KB pages and 4 byte PTEs.
How many bits are used for the offset and what is the size of the
largest page table?
Repeat the question for 128KB pages.
3.5.4 Separate Instruction and Data (I and D) Spaces
This was used when machine have very small virtual
address spaces.
Specifically the PDP-11, with 16-bit addresses, could address only
216 bytes or 64KB, a severe limitation.
With separate I and D spaces there could be 64KB of instructions and
64KB of data.
Separate I and D are no longer needed with modern architectures
having large address spaces.
3.5.5 Shared pages
Permit several processes to each have the same page loaded in the
same frame.
Of course this can only be done if the processes are using the same
program and/or data.
- Really should share segments.
- Must keep reference counts or something so that, when a
process terminates, pages it shares with another process are not
automatically discarded.
- Similarly, a reference count would make a widely shared page
(correctly) look like a poor choice for a victim.
- A good place to store the reference count would be in a
structure pointed to by both PTEs.
If stored in the PTEs themselves, we must keep somehow keep the
count consistent between processes.
- If you want the pages to be initially shared for reading but
want each process's updates to be private, then use so called
copy on write
techniques.
Homework:
Can a page shared between two processes be read-only for one process
and read-write for the other?
3.5.6 Shared Libraries (Dynamic-Linking)
In addition to sharing individual pages, process can share entire
library routines.
The technique used is called dynamic linking and
the objects produced are called shared libraries or
dynamically-linked libraries (DLLs).
(The traditional linking you did in lab1 is today often called
static linking).
- With dynamic linking, frequently used routines are not linked
into the program.
Instead, just a stub is linked.
- When the routine is called (or when the process begins), the
stub checks to see if the real routine has been loaded by
another program).
- If it has not been loaded, load it (really page it in as
needed).
- If it is already loaded, share it.
The read-write data must be shared copy-on-write.
- Advantages of dynamic linking.
- Saves RAM: Only one copy of a routing is in memory even
when it is used concurrently by many processes.
For example even a big server with hundreds of active
processes will have only one copy of printf in memory.
(In fact with demand paging only part of the routine will be
in memory.)
- Saves disk space: Files containing executable programs no
longer contain copies of the shared libraries.
- A bug fix to a dynamically linked library fixes all
applications that use that library, without
having to relink these applications.
- Disadvantages of dynamic linking.
- New bugs in dynamically linked library infect all
applications.
- Applications
change
even when they haven't changed.
- A Technical Difficulty with dynamic
linking.
The shared library has different virtual addresses in
each process so addresses relative to the beginning of the
module cannot be used (they would need to be relocated to
different addresses in the multiple
copies
of the
module).
Instead position-independent code must be used.
For example, jumps within the module would use PC-relative
addresses.
3.5.7 Mapped Files
The idea of memory-mapped files is to use the
mechanisms in place for demand paging (and segmentation, if present)
to implement I/O.
A system call is used to map a file into a portion of the address
space.
(No page can be part of a file and part of regular
memory;
the mapped file would be a complete segment if segmentation is
present).
The implementation of demand paging we have presented assumes that
the entire process is stored on disk.
This portion of secondary storage is called the backing store for the
pages.
Sometimes it is called a paging disk.
For memory-mapped files, the file itself is the backing store.
Once the file is mapped into memory, reads and writes become loads
and stores.
3.5.8 Cleaning Policy (Paging Daemons)
Done earlier
The only point to add is now that we know replacement algorithms
one can suggest an implementation.
If a clock-like algorithm is used for victim selection, one can have
a two handed clock with one hand (the paging daemon) staying ahead
of the other (the one invoked by the need for a free frame).
The front hand simply writes out any page it hits that is dirty and
thus the trailing hand is likely to see clean pages and hence is
more quickly able to find a suitable victim.
Unless specifically requested, you may ignore paging
daemons when answering exam questions.
3.5.9 Virtual Memory Interface
Skipped.
3.6 Implementation Issues
3.6.1 Operating System Involvement with Paging
When must the operating system be involved with paging?
- During process creation.
The OS must guess at the size of the process and then allocate a
page table and a region on disk to hold the pages that are not
memory resident.
A few pages of the process must be loaded.
- The Ready→Running transition.
Real memory must be allocated for the page table if the table
has been swapped out (which is permitted when the process is not
running).
Some hardware register(s) must be set to point to the page
table.
There can be many page tables resident, but the hardware must be
told the location of the page table for the running
process—the active
page table.
The MMU must be cleared (unless it contains a process id
field).
- Processing a page fault.
Lots of work is needed; see 3.6.2 just below.
- Process termination.
Free the page table and the disk region for swapped out pages.
3.6.2 Page Fault Handling
What happens when a process, say process A, gets a page fault?
Compare the following with the processing for a trap command and for
an interrupt.
- The hardware detects the fault and traps to the kernel
(switches to supervisor mode and saves state).
- Some assembly language code saves more state, establishes the
C-language (or another programming language) environment, and
calls
the OS.
- The OS determines that a page fault occurred and which page
was referenced.
- If the virtual address is invalid, process A is killed.
If the virtual address is valid, the OS must find a free frame.
If there is no free frames, the OS selects a victim frame.
(Really, the paging daemon does this prior to the fault
occurring, but it is easier to pretend that it is done here.)
Call the process owning the victim frame, process B.
(If the page replacement algorithm is local, then B=A.)
- The PTE of the victim page is updated to show that the page is
no longer resident.
- If the victim page is dirty, the OS schedules an I/O write to
copy the frame to disk and blocks A waiting for this I/O to
occur.
- Assuming process A needed to be blocked (i.e., the victim page
is dirty) the scheduler is invoked to perform a context switch.
- Tanenbaum
forgot
some here.
- The process selected by the scheduler (say process C)
runs.
- Perhaps C is preempted for D or perhaps C blocks and D
runs and then perhaps D is blocked and E runs, etc.
- When the I/O to write the victim frame completes, a disk
interrupt occurs. Assume processes C is running at the
time.
- Hardware trap / assembly code / OS determines I/O done.
- The scheduler marks A as ready.
- The scheduler picks a process to run, maybe A, maybe B,
maybe C, maybe another processes.
- At some point the scheduler does pick process A to run.
Recall that at this point A is still executing OS code.
- Now the O/S has a free frame (this may be much later in wall
clock time if a victim frame had to be written).
The O/S schedules an I/O to read the desired page into this free
frame.
Process A is blocked (perhaps for the second time) and hence the
process scheduler is invoked to perform a context
switch.
- Again, another process is selected by the scheduler as above
and eventually a disk interrupt occurs when the I/O completes
(trap / asm / OS determines I/O done). The PTE in process A is
updated to indicate that the page is in memory.
- The O/S may need to fix up process A (e.g., reset the program
counter to re-execute the instruction that caused the page
fault).
- Process A is placed on the ready list and eventually is chosen
by the scheduler to run.
Recall that process A is executing O/S code.
- The OS returns to the first assembly language routine.
- The assembly language routine restores registers, etc. and
returns
to user mode.
The user's program running as process A is unaware
that all this happened (except for the time delay).
3.6.3 Instruction Backup
A cute horror story.
The hardware support for page faults in the original Motorola 68000
(the first microprocessor with a large address space) was so bad
that an early demand paging system for the 68000, used two
processors one running one instruction behind.
If the first got a page fault, there wasn't always enough
information to figure out what to do so (for example did a register
pre-increment occur), the system switched to the second processor
after bringing in the faulting page.
The next generation machine, the 68010, provided extra information
on the stack so the horrible 2-processor kludge was no longer
necessary.
Don't worry about instruction backup; it is very machine dependent
and modern implementations tend to get it right.
3.6.4 Locking (Pinning) Pages in Memory
We discussed pinning jobs already.
The same (mostly I/O) considerations apply to pages.
3.6.5 Backing Store
The issue is where on disk do we put pages that are not in frames.
- For program text, which is presumably read only, a good choice
is the file executable itself.
- What if we decide to keep the data and stack each contiguous
on the backing store.
Data and stack grow so we must be prepared to grow the space on
disk, which leads to the same issues and problems as we saw with
MVT.
- If those issues/problems are painful, we can scatter the pages
on the disk.
- That is we employ paging!
- This is NOT demand paging.
- Need a table to say where the backing space for each page is
located.
- This corresponds to the page table used to tell where in
real memory a page is located.
- The format of the
memory page table
is determined by
the hardware since the hardware modifies/accesses it. It
is machine dependent.
- The format of the
disk page table
is decided by the OS
designers and is machine independent.
- If the format of the memory page table were flexible,
then we might well keep the disk information in it as
well.
But normally the format is not flexible, and hence this
is not done.
- What if we felt disk space was too expensive and wanted to put
some of these disk pages on say tape?
Ans: We use demand paging of the disk blocks! That way
"unimportant" disk blocks will migrate out to tape and are brought
back in if needed.
Since a tape read requires seconds to complete (because the
request is not likely to be for the sequentially next tape block),
it is crucial that we get very few disk block
faults.
I don't know of any systems that did this.
Homework: Assume every memory reference takes 0.1
microseconds to execute providing the reference page is memory
resident.
Assume a page fault takes 10 milliseconds to service providing the
necessary disk block is actually on the disk.
Assume a disk block fault takes 10 seconds service.
So the worst case time for a memory reference is 10.0100001
seconds.
Finally assume the program requires that a billion memory references
be executed.
- If the program is always completely resident, how long does it
take to execute?
- If 0.1% of the memory references cause a page fault, but all the disk
blocks are on the disk, how long does the program take to execute
and what percentage of the time is the program waiting for a page
fault to complete?
- If 0.1% of the memory references cause a page fault and 0.1% of the
page faults cause a disk block fault, how long does the program
take to execute and what percentage of the time is the program
waiting for a disk block fault to complete?
3.6.6 Separation of Policy and Mechanism
Skipped.