Operating Systems
Start Lecture #18
Remark: Here is a better
explanation of the problematic exam question.
Multiprogramming with Variable Partitions
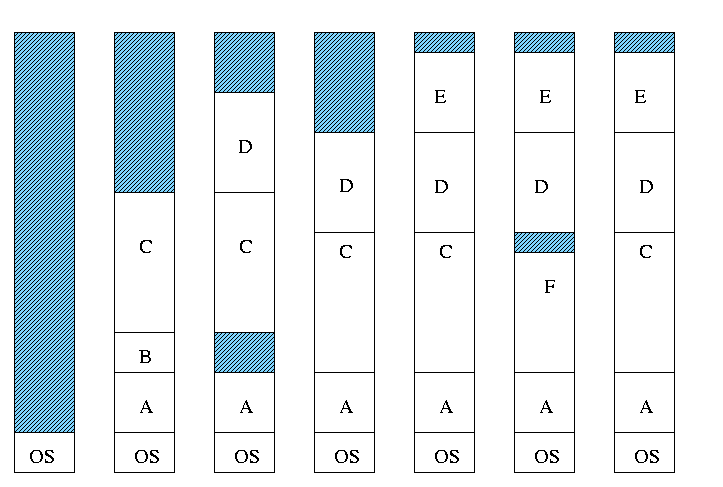
Both the number and size of the
partitions change with time.
Homework: A swapping system eliminates holes by
compaction.
Assume a random distribution of holes and data segments, assume the
data segments are much bigger than the holes, and assume a time to
read or write a 32-bit memory word of 10ns.
About how long does it take to compact 128 MB?
For simplicity, assume that word 0 is part of a hole and the highest
word in memory conatains valid data.
3.2.3 Managing Free Memory
MVT Introduces the Placement Question
That is, which hole (partition) should one choose?
- There are various algorithms for choosing a hole including best
fit, worst fit, first fit, circular first fit, quick fit, and
Buddy.
- Best fit doesn't waste big holes, but does leave slivers and
is expensive to run.
- Worst fit avoids slivers, but eliminates all big holes so
a big job will require compaction.
Even more expensive than best fit (best fit stops if it
finds a perfect fit).
- Quick fit keeps lists of some common sizes (but has other
problems, see Tanenbaum).
- Buddy system
- Round request to next highest power of two (causes
internal fragmentation).
- Look in list of blocks this size (as with quick fit).
- If list empty, go higher and split into buddies.
- When returning coalesce with buddy.
- Do splitting and coalescing recursively, i.e. keep
coalescing until can't and keep splitting until successful.
- See Tanenbaum (look in the index) or an algorithms
book for more details.
- A current favorite is circular first fit, also known as next fit.
- Use the first hole that is big enough (first fit) but start
looking where you left off last time.
- Doesn't waste time constantly trying to use small holes that
have failed before, but does tend to use many of the big holes,
which can be a problem.
- Buddy comes with its own implementation.
How about the others?
Homework:
Consider a swapping system in which memory consists of the following
hole sizes in memory order: 10K, 4K, 20K, 18K 7K, 9K, 12K, and 15K.
Which hole is taken for successive segment requests of
- 12K
- 10K
- 9K
for first fit?
Now repeat the question for best fit, worst fit, and next fit.
Memory Management with Bitmaps
Divide memory into blocks and associate a bit with each block, used
to indicate if the corresponding block is free or allocated.
To find a chunk of size N blocks need to find N consecutive
bits indicating a free block.
The only design question is how much memory does one bit represent.
- Big: Serious internal fragmentation.
- Small: Many bits to store and process.
Memory Management with Linked Lists
Instead of a bit map, use a linked list of nodes where each node
corresponds to a region of memory either allocated to a process or
still available (a hole).
- Each item on list gives the length and starting location of
the corresponding region of memory and says whether it is a hole
or Process.
- The items on the list are not taken from the memory to be
used by processes.
- The list is kept in order of starting address.
- Merge adjacent holes when freeing memory.
- Use either a singly or doubly linked list.
Memory Management using Boundary Tags
See Knuth, The Art of Computer Programming vol 1.
- Use the same memory for list items as for processes.
- Don't need an entry in linked list for the blocks in use, just
the avail blocks are linked.
- The avail blocks themselves are linked, not a node that points to
an avail block.
- When a block is returned, we can look at the boundary tag of the
adjacent blocks and see if they are avail.
If so they must be merged with the returned block.
- For the blocks currently in use, just need a hole/process bit at
each end and the length.
Keep this in the block itself.
- We do not need to traverse the list when returning a block can use
boundary tags to find predecessor.
MVT also introduces the Replacement Question
That is, which victim should we swap out?
This is an example of the suspend arc mentioned in process
scheduling.
We will study this question more when we discuss
demand paging in which case
we swap out only part of a process.
Considerations in choosing a victim
- Cannot replace a job that is pinned,
i.e. whose memory is tied down. For example, if Direct Memory
Access (DMA) I/O is scheduled for this process, the job is pinned
until the DMA is complete.
- Victim selection is a medium term scheduling decision
- A job that has been in a wait state for a long time is a good
candidate.
- Often choose as a victim a job that has been in memory for a long
time.
- Another question is how long should it stay swapped out.
- For demand paging, where swaping out a page is not as drastic
as swapping out a job, choosing the victim is an important
memory management decision and we shall study several policies.
NOTEs:
- So far the schemes presented so far have had two properties:
- Each job is stored contiguously in memory.
That is, the job is contiguous in physical addresses.
- Each job cannot use more memory than exists in the system.
That is, the virtual addresses space cannot exceed the
physical address space.
- Tanenbaum now attacks the second item.
I wish to do both and start with the first.
- Tanenbaum (and most of the world) uses the term
paging
to mean what I call demand paging.
This is unfortunate as it mixes together two concepts.
- Paging (dicing the address space) to solve the placement
problem and essentially eliminate external fragmentation.
- Demand fetching, to permit the total memory requirements of
all loaded jobs to exceed the size of physical memory.
- Most of the world uses the term virtual memory as a synonym for
demand paging.
Again I consider this unfortunate.
- Demand paging is a fine term and is quite descriptive.
- Virtual memory
should
be used in contrast with
physical memory to describe any virtual to physical address
translation.
** (non-demand) Paging
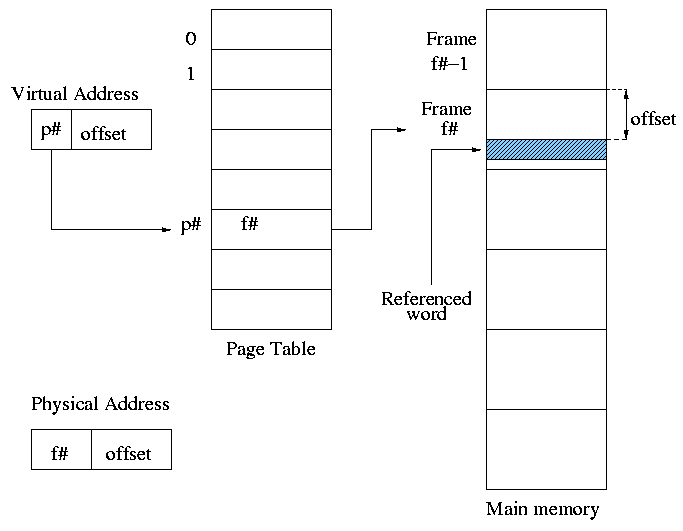
Simplest scheme to remove the requirement of contiguous physical
memory.
- Chop the program into fixed size pieces called
pages, which are invisible to the user.
Tanenbaum sometimes calls pages
virtual pages.
- Chop the real memory into fixed size pieces called
page frames or
simply frames.
- The size of a page (the page size) = size of a frame (the frame
size).
- Sprinkle the pages into the frames.
- Keep a table (called the page table) having
an entry for each page.
The page table entry or PTE for page p contains
the number of the frame f that contains page p.
Example: Assume a decimal machine with
page size = frame size = 1000.
Assume PTE 3 contains 459.
Then virtual address 3372 corresponds to physical address 459372.
Properties of (non-demand) paging (without segmentation).
- The entire process must be memory resident to run.
- No holes, i.e., no external fragmentation.
- If there are 50 frames available and the page size is 4KB than
any job requiring ≤ 200KB will fit, even if the available
frames are scattered over memory.
- Hence (non-demand) paging is useful.
- Indeed, it was used (but no longer).
- Introduces internal fragmentation approximately equal to 1/2 the
page size for every process (really every segment).
- Can have a job unable to run due to insufficient memory and
have some (but not enough) memory available.
This is not called external fragmentation since it is
not due to memory being fragmented.
- Eliminates the placement question.
All pages are equally good since don't have external
fragmentation.
- The replacement question remains.
- Since page boundaries occur at
random
points and can
change from run to run (the page size can change with no effect
on the program—other than performance), pages are not
appropriate units of memory to use for protection and sharing.
But if all you have is a hammer, everything looks like a nail.
Segmentation, which is discussed later, is sometimes more
appropriate for protection and sharing.
- Virtual address space remains contiguous.
Address translation
- Each memory reference turns into 2 memory references
- Reference the page table
- Reference central memory
- This would be a disaster!
- Hence the MMU caches page#→frame# translations.
This cache is kept near the processor and can be accessed
rapidly.
- This cache is called a translation lookaside buffer
(TLB) or translation buffer (TB).
- For the above example, after referencing virtual address 3372,
there would be an entry in the TLB containing the mapping
3→459.
- Hence a subsequent access to virtual address 3881 would be
translated to physical address 459881 without an extra memory
reference.
Naturally, a memory reference for location 459881 itself would be
required.
Choice of page size is discuss below.
Homework:
Using the page table of Fig. 3.9, give the physical address
corresponding to each of the following virtual addresses.
- 20
- 4100
- 8300