Operating Systems
Start Lecture #9
Approximating the Behavior of SFJ and PSJF
Recall that SFJ/PSFJ do a good job of minimizing the average
waiting time.
The problem with them is the difficulty in finding the job whose
next CPU burst is minimal.
We now learn three scheduling algorithms that attempt to do this.
The first algorithm does it statically, presumably with some manual
help; the other two are dynamic and fully automatic.
Multilevel Queues (**, **, MLQ, **)
Put different classes of processs in different queues
- Processes do not move from one queue to another.
- Can have different policies on the different queues.
For example, might have a background (batch) queue that is FCFS
and one or more foreground queues that are RR (possibly with
different quanta).
- Must also have a policy among the queues.
For example, might have two queues, foreground and background, and give
the first absolute priority over the second
- Might apply priority aging to prevent background starvation.
- But might not, i.e., no guarantee of service for background
processes.
View a background process as a
cycle soaker
.
- Might have 3 queues, foreground, background, cycle soaker.
- Another possible inter-queue policy would be
have 2 queues, apply RR to each but cycle through the higher
priority twice and then cycle through the lower priority queue
once.
Multiple Queues (FB, MFQ, MLFBQ, MQ)
As with multilevel queues above we have many queues, but now
processes move from queue to queue in an attempt to dynamically
separate batch-like
from interactive processs so that we can
favor the latter.
- Remember that low average waiting time is achieved by SJF and
this is an attempt to determine dynamically those processes that
are interactive, which means have a very short cpu burst.
- Run processs from the highest priority nonempty queue in a RR manner.
- When a process uses its full quanta (looks a like batch process),
move it to a lower priority queue.
- When a process doesn't use a full quanta (looks like an interactive
process), move it to a higher priority queue.
- A long process with frequent (perhaps spurious) I/O will remain
in the upper queues.
- Might have the bottom queue FCFS.
- Many variants.
For example, might let process stay in top queue 1 quantum, next
queue 2 quanta, next queue 4 quanta (i.e., sometimes return a
process to the rear of the same queue it was in if the quantum
expires).
Might move to a higher queue only if a keyboard interrupt
occurred rather than if the quantum failed to expire for any
reason (e.g., disk I/O).
Shortest Process Next
An attempt to apply sjf to interactive scheduling.
What is needed is an estimate of how long the process will run until
it blocks again.
One method is to choose some initial estimate when the process starts
and then, whenever the process blocks choose a new estimate via
NewEstimate = A*OldEstimate + (1-A)*LastBurst
where 0<A<1 and LastBurst is the actual time used
during the burst that just ended.
Highest Penalty Ratio Next (HPRN, HRN, **, **)
Run the process that has been hurt
the most.
- For each process, let r = T/t; where T is the wall clock time this
process has been in system and t is the running time of the
process to date.
- If r=2.5, that means the job has been running 1/2.5 = 40% of the
time it has been in the system.
- We call r the penalty ratio and run the process having
the highest r value.
- We must worry about a process that just enters the system
since t=0 and hence the ratio is undefined.
Define t to be the max of 1 and the running time to date.
Since now t is at least 1, the ratio is always defined.
- HPRN is normally defined to be non-preemptive (i.e., the system
only checks r when a burst ends), but there is an preemptive analogue
- When putting a process into the run state compute the time
at which it will no longer have the highest ratio and set a
timer.
- When a process is moved into the ready state, compute its ratio
and preempt if needed.
- HRN stands for highest response ratio next and means the same thing.
- This policy is yet another example of priority scheduling
Guaranteed Scheduling
A variation on HPRN.
The penalty ratio is a little different.
It is nearly the reciprocal of the above, namely
t / (T/n)
where n is the multiprogramming level.
So if n is constant, this ratio is a constant times 1/r.
Lottery Scheduling
Each process gets a fixed number of tickets and at each scheduling
event a random ticket is drawn (with replacement)
and the process holding that ticket runs for the next interval
(probably a RR-like quantum q).
On the average a process with P percent of the tickets will get P
percent of the CPU (assuming no blocking, i.e., full quanta).
Fair-Share Scheduling
If you treat processes fairly
you may not be treating
users fairly
since users with many processes will get more
service than users with few processes.
The scheduler can group processes by user and only give one of a
user's processes a time slice before moving to another user.
Fancier methods have been implemented that give some fairness to
groups of users.
Say one group paid 30% of the cost of the computer.
That group would be entitled to 30% of the cpu cycles providing it
had at least one process active.
Furthermore a group earns some credit when it has no processes
active.
Theoretical Issues
Considerable theory has been developed.
- NP completeness results abound.
- Much work in queuing theory to predict performance.
- Not covered in this course.
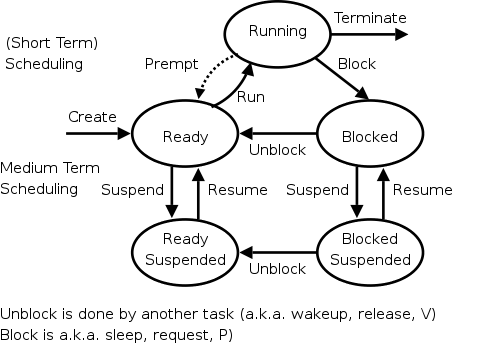
Medium-Term Scheduling
In addition to the short-term scheduling we have discussed, we add
medium-term scheduling in which decisions are made at a
coarser time scale.
Recall my favorite diagram, shown again on the right.
Medium term scheduling determines the transitions from the top
triangle to the bottom line.
We suspend (swap out) some process if memory is over-committed
dropping the (ready or blocked) process down.
We also need resume transitions to return a process to the top
triangle.
Criteria for choosing a victim to suspend include:
- How long since previously suspended.
- How much CPU time used recently.
- How much memory does it use.
- External priority (pay more, get swapped out less).
We will discuss medium term scheduling again when we study memory
management.
Long Term Scheduling
This is sometimes called Job scheduling
.
- The system decides when to start jobs, i.e., it does not
necessarily start them when submitted.
- Used at many supercomputer sites.
A similar idea (but more drastic and not always so well
coordinated) is to force some users to log out, kill processes,
and/or block logins if over-committed.
- CTSS (an early time sharing system at MIT) did this to insure
decent interactive response time.
- Unix does this if out of memory.
LEM jobs during the day
(Grumman).
Review Homework Assigned Last Time
Lab 2 (Scheduling) Discussion
Remark: Lab 2 assigned.
It is due in 2 weeks, 3 March 2009.
Show the detailed output
- In FCFS see the affect of A, B, C, and I/O
- In RR see how the cpu burst is limited.
- Note the intital sorting to ease finding the tie breaking
process.
- Note show random.
- Comment on how to do it: (time-based) discrete-event
simulation (DES).
- DoBlockedProcesses()
- DoRunningProcesses()
- DoCreatedProcesses()
- DoReadyProcesses()
- For processor sharing need event-based DES.
2.4.4 Scheduling in Real Time Systems
Skipped
2.4.5 Policy versus Mechanism
Skipped.
2.4.6 Thread Scheduling
Skipped.