Start Lecture #12
Modern systems have utility programs that check the consistency of
a file system.
A different utility is needed for each file system type in the
system, but a wrapper
program is often created so that the
user is unaware of the different utilities.
The unix utility is called fsck (file system check) and the window utility is called chkdsk (check disk).
fixthe errors found (for most errors).
Not so much of a problem now. Disks are more reliable and, more importantly, disks and disk controllers take care most bad blocks themselves.
Demand paging again!
Demand paging is a form of caching: Conceptually, the process resides on disk (the big and slow medium) and only a portion of the process (hopefully a small portion that is heavily access) resides in memory (the small and fast medium).
The same idea can be applied to files. The file resides on disk but a portion is kept in memory. The area in memory used to for those file blocks is called the buffer cache or block cache.
Some form of LRU replacement is used.
The buffer cache is clearly good and simple for reads.
What about writes?
write-allocate policyAlthough
no-write-allocateis possible and sometimes used for memory caches, it performs poorly for disk caching.
needed.
Homework: 27.
When the access pattern looks
sequential read ahead is employed.
This means that after completing a read() request for block n of a file.
The system guesses that a read() request for block n+1 will shortly be
issued and hence automatically fetches block n+1.
The idea is to try to place near each other blocks that are likely to be accessed sequentially.
super-blocks, consisting of several contiguous blocks.
If clustering is not done, files can become spread out all over the disk and a utility (defrag on windows) should be run to make the files contiguous on the disk.
CP/M was a very early and simple OS. It ran on primitive hardware with very little ram and disk space. CP/M had only one directory in the entire system. The directory entry for a file contained pointers to the disk blocks of the file. If the file contained more blocks than could fit in a directory entry, a second entry was used.
File systems on cdroms do not need to support file addition or deletion and as a result have no need for free blocks. A CD-R (recordable) does permit files to be added, but they are always added at the end of the disk. The space allocated to a file is not recovered even when the file is deleted, so the (implicit) free list is simply the blocks after the last file recorded.
The result is that the file systems for these devices are quite simple.
This international standard forms the basis for essentially all file systems on data cdroms (music cdroms are different and are not discussed). Most Unix systems use iso9660 with the Rock Ridge extensions, and most windows systems use iso9660 with the Joliet extensions.
The ISO9660 standard permits a single physical CD to be partitioned and permits a cdrom file system to span many physical CDs. However, these features are rarely used and we will not discuss them.
Since files do not change, they are stored contiguously and each directory entry need only give the starting location and file length.
File names are 8+3 characters (directory names just 8) for iso9660-level-1 and 31 characters for -level-2. There is also a -level-3 in which a file is composed of extents which can be shared among files and even shared within a single file (i.e. a single physical extent can occur multiple times in a given file).
Directories can be nested only 8 deep.
The Rock Ridge extensions were designed by a committee from the unix community to permit a unix file system to be copied to a cdrom without information loss.
These extensions included.
special files, i.e. including devices in the file system name structure.
The Joliet extensions were designed by Microsoft to permit a windows file system to be copied to a cdrom without information loss.
These extensions included.
We discussed this linked-list, File-Allocation-Table-based file system previously. Here we add a little history.
The FAT file system has been supported since the first IBM PC (1981) and is still widely used. Indeed, considering the number of cameras and MP3 players, it is very widely used.
Unlike CP/M, MS-DOS always had support for subdirectories and metadata such as date and size.
File names were restricted in length to 8+3.
As described above, the directory entries point to the first block of each file and the FAT contains pointers to the remaining blocks.
The free list was supported by using a special code in the FAT for
free blocks.
You can think of this as a bitmap with a wide bit
.
The first version FAT-12 used 12-bit block numbers so a partition could not exceed 212 blocks. A subsequent release went to FAT-16.
Two changes were made: Long file names were supported and the file allocation table was switched from FAT-16 to FAT-32. These changes first appeared in the second release of Windows 95.
The hard part of supporting long names was keeping compatibility
with the old 8+3 naming rule.
That is, new file systems created with windows 98 using long file
names must be accessible if the file system is subsequently used
with an older version of windows that supported only 8+3 file names.
The ability for new old systems to read data from new systems was
important since users often had both new and old systems and kept
many files on floppy disks that were used on both systems.
This abiliity called backwards compatibility
.
The solution was to permit a file to have two names: a long one and an 8+3 one. The primary directory entry for a file in windows 98 is the same format as it was in MS-DOS and contains the 8+3 file name. If the long name fits the 8+3 format, the story ends here.
If the long name does not fit in 8+3, an 8+3 version is produce
via an algorithm that works but produces names with severely
limited aesthetic value.
The long name is stored in one or more axillary
directory
entries adjacent to the main entry.
These axillary entries are set up to appear invalid to the old OS,
which therefore ignores them.
FAT-32 used 32 bit words for the block numbers (actually, it used 28 bits) so the FAT could be huge (228 entries). Windows 98 kept only a portion of the FAT-32 table in memory at a time.
I presented the inode system in some detail above. Here we just describe a few properties of the filesystem beyond the inode structure itself.
touch 255-char-name
is OK but
touch 256-char-name
is not.
Skipped
Read
The most noticeable characteristic of current ensemble of I/O devices is their great diversity.
output onlydevice such as a printer supplies very little output to the computer (perhaps an out of paper indication) but receives voluminous input from the computer. Again it is better thought of as a transducer, converting electronic data from the computer to paper data for humans.
These are the devices as far as the OS is concerned. That is, the OS code is written with the controller specification in hand not with the device specification.
Consider a disk controller processing a read request. The goal is to copy data from the disk to some portion of the central memory. How is this to be accomplished?
The controller contains a microprocessor and memory, and is connected to the disk (by wires). When the controller requests a sector from the disk, the sector is transmitted to the control via the wires and is stored by the controller in its memory.
The separate processor and memory on the controller gives rise to two questions.
Typically the interface the OS sees consists of some several registers located on the controller.
go button.
So the first question above becomes, how does the OS read and write the device register?
I/O spaceinto which the registers are mapped. In this case special I/O space instructions are used to accomplish the loads and stores.
elegantsolution in that it uses an existing mechanism to accomplish a second objective.
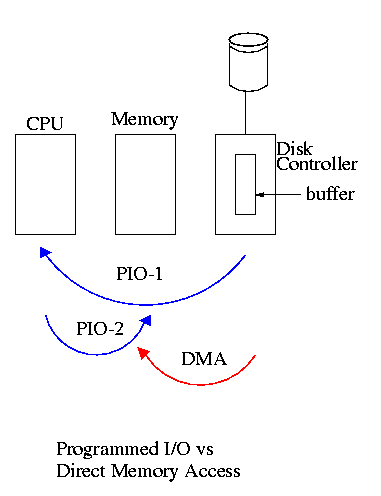
We now address the second question, moving data between the controller and the main memory. Recall that (independent of the issue with respect to DMA) the disk controller, when processing a read request pulls the desired data from the disk to its own buffer (and pushes data from the buffer to the disk when processing a write).
Without DMA, i.e., with programmed I/O (PIO), the cpu then does loads and stores (assuming the controller buffer is memory mapped, or uses I/O instructions if it is not) to copy the data from the buffer to the desired memory locations.
A DMA controller, instead writes the main memory itself, without intervention of the CPU.
Clearly DMA saves CPU work. But this might not be important if the CPU is limited by the memory or by system buses.
An important point is that there is less data movement with DMA so the buses are used less and the entire operation takes less time. Compare the two blue arrows vs. the single red arrow.
Since PIO is pure software it is easier to change, which is an advantage.
DMA does need a number of bus transfers from the CPU to the controller to specify the DMA. So DMA is most effective for large transfers where the setup is amortized.
Why have the buffer? Why not just go from the disk straight to the memory?
Homework: 12