Start Lecture #8
Remark: Midterm grades are based only on lab1, which is a very small part of the final grade.
These are solutions to the replacement question. Good solutions take advantage of locality when choosing the victim page to replace.
likelyto be referenced. So it is good to bring in the entire page on a miss and to keep the page in memory for a while.
When programs begin there is no history so nothing to base locality
on.
At this point the paging system is said to be undergoing a
cold start
.
Programs exhibit phase changes
in which the set of pages
referenced changes abruptly (similar to a cold start).
An example would occurs in your linker lab when you finish pass 1
and start pass 2.
At the point of a phase change, many page faults occur because
locality is poor.
Pages belonging to processes that have terminated are of course perfect choices for victims.
Pages belonging to processes that have been blocked for a long time are good choices as well.
A lower bound on performance. Any decent scheme should do better.
Replace the page whose next reference will be furthest in the future.
Divide the frames into four classes and make a random selection from the lowest nonempty class.
Assumes that in each PTE there are two extra flags R (for referenced; sometimes called U, for used) and M (for modified, often called D, for dirty).
NRU is based on the belief that a page in a lower priority class is a better victim.
Implementation
We again have the prisoner problem: We do a good job of making little ones out of big ones, but not as good a job on the reverse. We need more resets. Therefore, every k clock ticks, the OS resets all R bits.
Why not reset M as well?
Answer: If a dirty page has a clear M, we will not copy the page
back to disk when it is evicted, and thus the only accurate version
of the page will be lost!
I suppose one could have two M bits one accurate and one reset, but I don't know of any system (or proposal) that does so.
What if the hardware doesn't set these bits?
Answer: The OS can uses tricks.
We ignore the tricks and assume the hardware does set the bits.
Simple but poor since the usage of the page is ignored.
Belady's Anomaly: Can have more frames yet generate more faults. An example is given later.
The natural implementation is to have a queue of nodes each pointing to a resident page (i.e., pointing to a frame).
Similar to the FIFO PRA, but altered so that a page recently referenced is given a second chance.
Same algorithm as 2nd chance, but a better implementation for the nodes: Use a circular list with a single pointer serving as both head and tail.
Let us begin by assuming that the number of pages loaded is constant.
clockPRA.)
oldest, unreferencedpage by a new page.
Thus, when the number of loaded pages (i.e., frames) is constant,
the algorithm is just like 2nd chance except that only the one
pointer (the clock hand
) is updated.
How can the number of frames change for a fixed machine? Presumably we don't (un)plug DRAM chips while the system is running?
The number of frames can change when we use a so called
local algorithm
—discussed later—where the victim
must come from the frames assigned to the faulting process.
In this case we have a different frame list for each process.
At times we want to change the number of frames assigned to a given
process and hence the number of frames in a given frame list changes
with time.
How does this affect 2nd chance?
This is terrible!
Why?
Ans: All but the last frame are frozen once loaded so you can
replace only one frame.
This is especially bad after a phase shift in the program as now the
program is references mostly new pages but only one frame is
available to hold them.
When a page fault occurs, choose as victim that page that has been unused for the longest time, i.e. the one that has been least recently used.
LRU is definitely
Homework: 28, 22.
A clever hardware method to determine the LRU page.
Keep a count of how frequently each page is used and evict the one that has been the lowest score. Specifically:
| R | counter |
|---|---|
| 1 | 10000000 |
| 0 | 01000000 |
| 1 | 10100000 |
| 1 | 11010000 |
| 0 | 01101000 |
| 0 | 00110100 |
| 1 | 10011010 |
| 1 | 11001101 |
| 0 | 01100110 |
NFU doesn't distinguish between old references and recent ones. The following modification does distinguish.
Aging does indeed give more weight to later references, but an n bit counter maintains data for only n time intervals; whereas NFU maintains data for at least 2n intervals.
Homework: 24, 33.
The goals are first to specify which pages a given process needs to have memory resident in order for the process to run without too many page faults and second to ensure that these pages are indeed resident.
But this is impossible since it requires predicting the future. So we again make the assumption that the near future is well approximated by the immediate past.
We measure time in units of memory references, so t=1045 means the time when the 1045th memory reference is issued. In fact we measure time separately for each process, so t=1045 really means the time when this process made its 1045th memory reference.
Definition: w(k,t), the working set at time t (with window k) is the set of pages referenced by the last k memory references ending at reference t.
The idea of the working set policy is to ensure that each process keeps its working set in memory.
Homework: Describe a process (i.e., a program) that runs for a long time (say hours) and always has a working set size less than 10. Assume k=100,000 and the page size is 4KB. The program need not be practical or useful.
Homework: Describe a process that runs for a long time and (except for the very beginning of execution) always has a working set size greater than 1000. Again assume k=100,000 and the page size is 4KB. The program need not be practical or useful.
The definition of Working Set is local to a process. That is, each process has a working set; there is no system wide working set other than the union of all the working sets of each process.
However, the working set of a single process has effects on the demand paging behavior and victim selection of other processes. If a process's working set is growing in size, i.e., w(t,k) is increasing as t increases, then we need to obtain new frames from other processes. A process with a working set decreasing in size is a source of free frames. We will see below that this is an interesting amalgam of local and global replacement policies.
Interesting questions concerning the working set include:
... Various approximations to the working set, have been devised. We will study two: Using virtual time instead of memory references (immediately below), and Page Fault Frequency (part of section 3.5.1). In 3.4.9 we will see the popular WSClock algorithm that includes an approximation of the working set as well as several other ideas.
Instead of counting memory referenced and declaring a page in the working set if it was used within k references, we keep track of time, which the system does anyway, and declare a page in the working set if it was used in the past τ seconds. Note that the time is measured only while this process is running, i.e., we are using virtual time.
time of last useto the PTE. The procedure for setting this field is in item 3 below.
The WSClock algorithm combines aspects of the working set algorithm and the clock implementation of second chance.
Like clock we create a circular list of nodes with a hand
pointing to the next node to examine.
There is one such node for every resident page of this process; thus
the nodes can be thought of as a list of frames or a kind of
inverted page table.
Like working set we store in each node the referenced and modified bits R and M and the time of last use. R and M are cleared when the page is read in. R is set by the hardware on a reference and cleared periodically by the OS (perhaps at the end of each page fault or perhaps every m milliseconds). M is set by the hardware on a write. We indicate below the setting of the time of last use and the clearing of M.
We use virtual time and declare a page old if its last reference is more than τ seconds in the past. Other pages are declared young (i.e., in the working set).
As with clock, on every page fault a victim is found by scanning the list starting with the node indicated by the clock hand.
It is possible to go all around the clock without finding a victim. In that case
An alternative treatment of WSClock, including more details of its interaction with the I/O subsystem, can be found here.
| Algorithm | Comment |
|---|---|
| Random | Poor, used for comparison |
| Optimal | Unimplementable, used for comparison |
| NRU | Crude |
| FIFO | Not good ignores frequency of use |
| Second Chance | Improvement over FIFO |
| Clock | Better implementation of Second Chance |
| LIFO | Horrible, useless |
| LRU | Great but impractical |
| NFU | Crude LRU approximation |
| Aging | Better LRU approximation |
| Working Set | Good, but expensive |
| WSClock | Good approximation to working set |
Consider a system that has no pages loaded and that uses the FIFO
PRU.
Consider the following reference string
(sequences of
pages referenced).
0 1 2 3 0 1 4 0 1 2 3 4
If we have 3 frames this generates 9 page faults (do it).
If we have 4 frames this generates 10 page faults (do it).
Theory has been developed and certain PRA (so called
stack algorithms
) cannot suffer this anomaly for any
reference string.
FIFO is clearly not a stack algorithm.
LRU is.
Repeat the above calculations for LRU.
A local PRA is one is which a victim page is chosen among the pages of the same process that requires a new frame. That is the number of frames for each process is fixed. So LRU for a local policy means the page least recently used by this process. A global policy is one in which the choice of victim is made among all pages of all processes.
In general a global policy seems to work better. For example, consider LRU. With a local policy, the local LRU page might have been more recently used than many resident pages of other processes. A global policy needs to be coupled with a good method to decide how many frames to give to each process. By the working set principle, each process should be given |w(k,t)| frames at time t, but this value is hard to calculate exactly.
If a process is given too few frames (i.e., well below |w(k,t)|), its faulting rate will rise dramatically. If this occurs for many or all the processes, the resulting situation in which the system is doing very little useful work due to the high I/O requirements for all the page faults is called thrashing.
An approximation to the working set policy that is useful for determining how many frames a process needs (but not which pages) is the Page Fault Frequency (PFF) algorithm.
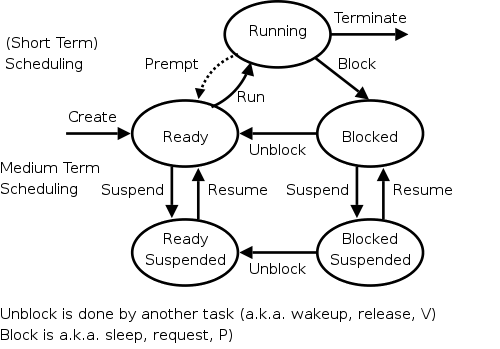
To reduce the overall memory pressure, we must reduce the multiprogramming level (or install more memory while the system is running, which is not possible with current technology). That is, we have a connection between memory management and process management. These are the suspend/resume arcs we saw way back when and are shown again in the diagram on the right.
When the PFF (or another indicator) is too high, we choose a process and suspend it, thereby swapping it to disk and releasing all its frames. When the frequency gets low, we can resume one or more suspended processes. We also need a policy to decide when a suspended process should be resumed even at the cost of suspending another.
This is called medium-term scheduling. Since suspending or resuming a process can take seconds, we clearly do not perform this scheduling decision every few milliseconds as we do for short-term scheduling. A time scale of minutes would be more appropriate.