Start Lecture #2
Remark: Starting next week we meet in room 312 of this building.
This will be very brief.
Much of the rest of the course will consist of
filling in the details
.
A process is program in execution. If you run the same program twice, you have created two processes. For example if you have two editors running in two windows, each instance of the editor is a separate process.
Often one distinguishes the state or context of a process—its
address space (roughly its memory image), open files), etc.—
from the thread of control.
If one has many threads running in the same task,
the result is a multithreaded processes
.
The OS keeps information about all processes in the process table. Indeed, the OS views the process as the entry. This is an example of an active entity being viewed as a data structure (cf. discrete event simulations), an observation made by Finkel in his (out of print) OS textbook.
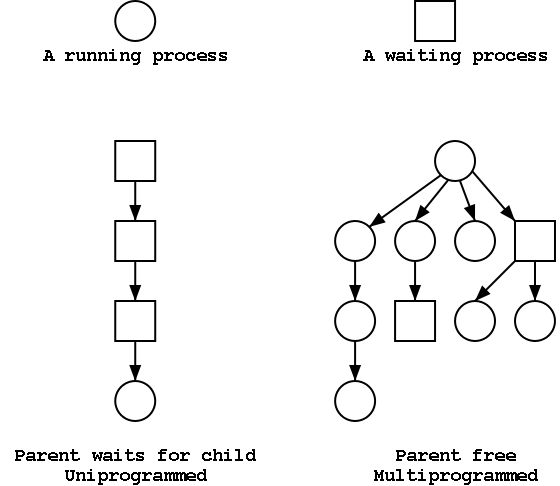
The set of processes forms a tree via the fork system call.
The forker is the parent of the forkee, which is
called a child.
If the system always blocks the parent until the child finishes, the
tree
is quite simple, just a line.
But the parent (in many OSes) is free to continue executing and in
particular is free to fork again producing another child.
A process can send a signal to another process to
cause the latter to execute a predefined function (the signal
handler).
It can be tricky to write a program with a signal handler since the
programmer does not know when in the mainline
program the
signal handler will be invoked.
Each user is assigned a User IDentification (UID) and all processes created by that user have this UID. A child has the same UID as its parent. It is sometimes possible to change the UID of a running process. A group of users can be formed and given a Group IDentification, GID. One UID is special (the superuser or administrator) and has extra privileges.
Access to files and devices can be limited to a given UID or GID.
A set of processes is deadlocked if each of the processes is blocked by a process in the set. The automotive equivalent, shown below, is called gridlock. (The photograph below was sent to me by Laurent Laor.)

Clearly, each process requires memory, but there are other issues as well. For example, your linkers (will) produce a load module that assumes the process is loaded at location 0. The result would be that every load module has the same address space. The operating system must ensure that the address spaces of concurrently executing processes are assigned disjoint real memory.
For another example note that current operating systems permit each process to be given more (virtual) memory than the total amount of (real) memory on the machine.
Modern systems have a hierarchy of files. A file system tree.
My Computeris the parent of a:\ and c:\.
You can name a file via an absolute path starting at the root directory or via a relative path starting at the current working directory.
In Unix, one file system can be mounted on (attached to) another. When this is done, access to an existing directory on the second filesystem is temporarily replaced by the entire first file system. Most often the directory chosen is empty before the mount so no files become temporarily invisible.
In addition to regular files and directories, Unix also uses the file system namespace for devices (called special files, which are typically found in the /dev directory. Often utilities that are normally applied to (ordinary) files can be applied as well to some special files. For example, when you are accessing a unix system using a mouse and do not have anything serious going on (e.g., right after you log in), type the following command
cat /dev/mouse
and then move the mouse.
You kill the cat by typing cntl-C.
I tried this on my linux box (using a text console) and no damage occurred.
Your mileage may vary.
Before a file can be accessed, it must be opened and a file descriptor obtained. Subsequent I/O system calls (e.g., read and write) use the file descriptor rather that the file name. This is an optimization that enables the OS to find the file once and save the information in a file table accessed by the file descriptor. Many systems have standard files that are automatically made available to a process upon startup. These (initial) file descriptors are fixed.
A convenience offered by some command interpreters is a pipe or pipeline. The pipeline
dir | wc
which pipes the output of dir into a character/word/line counter,
will give the number of files in the directory (plus other info).
There are a wide variety of I/O devices that the OS must manage. For example, if two processes are printing at the same time, the OS must not interleave the output.
The OS contains device specific code (drivers) for each device as well as device-independent I/O code.
Files and directories have associated permissions.
attributesas well. For example the linux ext2 and ext3 file systems support a
dattribute that is a hint to the dump program not to backup this file.
Security has of course sadly become a very serious concern. The topic is quite deep and I do not feel that the necessarily superficial coverage that time would permit is useful so we are not covering the topic at all.
The command line interface to the operating system. The shell permits the user to
dir | wc).
Instead of a shell, one can have a more graphical interface.
Homework: 7.
Some concepts become obsolete and then reemerge due in both cases to technology changes. Several examples follow. Perhaps the cycle will repeat with smart card OS.
The use of assembly languages greatly decreases when memories get larger. When minicomputers and microcomputers (early PCs) were first introduced, they each had small memories and for a while assembly language again became popular.
Multiprogramming requires protection hardware. Once the hardware becomes available monoprogramming becomes obsolete. Again when minicomputers and microcomputers were introduced, they had no such hardware so monoprogramming revived.
When disks are small, they hold few files and a flat (single directory) file system is adequate. Once disks get large a hierarchical file system is necessary. When mini and microcomputer were introduced, they had tiny disks and the corresponding file systems were flat.
Virtual memory, among other advantages, permits dynamically linked libraries so as VM hardware appears so does dynamic linking.
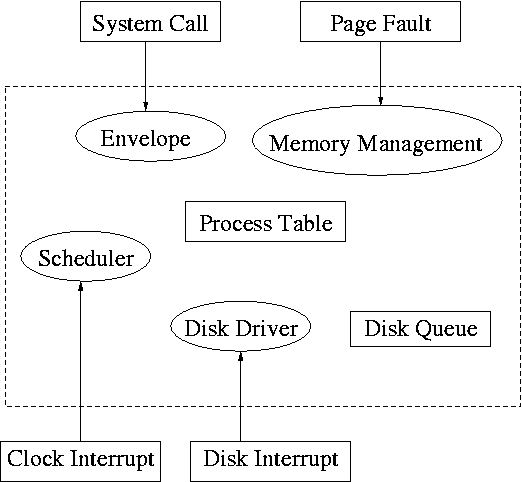
System calls are the way a user (i.e., a program) directly interfaces with the OS. Some textbooks use the term envelope for the component of the OS responsible for fielding system calls and dispatching them to the appropriate component of the OS. On the right is a picture showing some of the OS components and the external events for which they are the interface.
Note that the OS serves two masters. The hardware (at the bottom) asynchronously sends interrupts and the user (at the top) synchronously invokes system calls and generates page faults.
Homework: 14.
What happens when a user executes a system call such as read()? We show a more detailed picture below, but at a high level what happens is
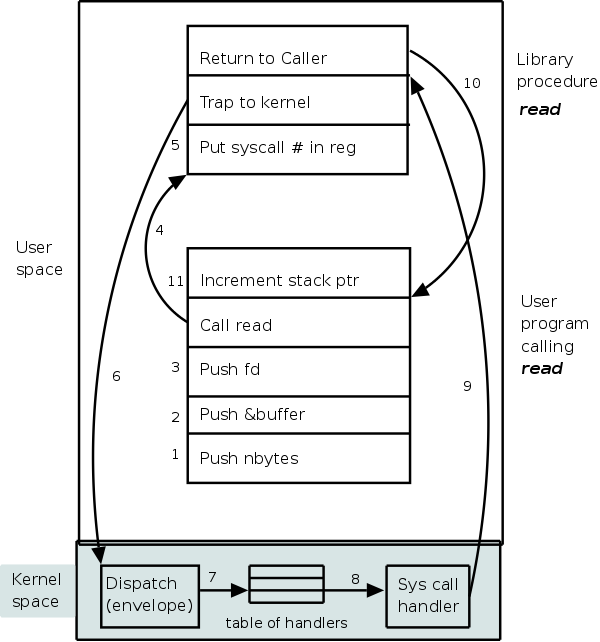
The following actions occur when the user executes the (Unix) system call
count = read(fd,buffer,nbytes)
which reads up to nbytes from the file described
by fd into buffer.
The actual number of bytes read is returned (it might be less than
nbytes if, for example, an eof was encountered).
A major complication is that the system call handler may block. Indeed, the read system call handler is likely to block. In that case a context switch is likely to occur to another process. This is far from trivial and is discussed later in the course.
| Posix | Win32 | Description |
|---|---|---|
| Process Management | ||
| Fork | CreateProcess | Clone current process |
| exec(ve) | Replace current process | |
| waid(pid) | WaitForSingleObject | Wait for a child to terminate. |
| exit | ExitProcess | Terminate process & return status |
| File Management | ||
| open | CreateFile | Open a file & return descriptor |
| close | CloseHandle | Close an open file |
| read | ReadFile | Read from file to buffer |
| write | WriteFile | Write from buffer to file |
| lseek | SetFilePointer | Move file pointer |
| stat | GetFileAttributesEx | Get status info |
| Directory and File System Management | ||
| mkdir | CreateDirectory | Create new directory |
| rmdir | RemoveDirectory | Remove empty directory |
| link | (none) | Create a directory entry |
| unlink | DeleteFile | Remove a directory entry |
| mount | (none) | Mount a file system |
| umount | (none) | Unmount a file system |
| Miscellaneous | ||
| chdir | SetCurrentDirectory | Change the current working directory |
| chmod | (none) | Change permissions on a file |
| kill | (none) | Send a signal to a process |
| time | GetLocalTime | Elapsed time since 1 jan 1970 |
We describe the unix (Posix) system calls. A short description of the Windows interface is in the book.
To show how the four process management calls enable much of process management, consider the following highly simplified shell. The fork() system call duplicates the process (so parent and child are each executing fork()); fork() returns true in the parent and false in the child.)
while (true)
display_prompt()
read_command(command)
if (fork() != 0)
waitpid(...)
else
execve(command)
endif
endwhile
Simply removing the waitpid(...) gives background jobs.
Most files are accessed sequentially from beginning to end. In this case the operations performed are
For non-sequential access, lseek is used to move
the File Pointer
, which is the location in the file where the
next read or write will take place.
Directories are created and destroyed by mkdir and rmdir. Directories are changed by the creation and deletion of files. As mentioned, open creates files. Files can have several names link is used to give another name and unlink to remove a name. When the last name is gone (and the file is no longer open by any process), the file data is destroyed. This description is approximate, we give the details later in the course where we explain Unix i-nodes.
Homework: 18.
Skipped
Skipped
The transfer of control between user processes and the operating system kernel can be quite complicated, especially in the case of blocking system calls, hardware interrupts, and page faults. Before tackling these issues later, we begin with the familiar example of a procedure call within a user-mode process.
An important OS objective is that, even in the more complicated cases of page faults and blocking system calls requiring device interrupts, simple procedure call semantics are observed from a user process viewpoint. The complexity is hidden inside the kernel itself, yet another example of the operating system providing a more abstract, i.e., simpler, virtual machine to the user processes.
More details will be added when we study memory management (and know officially about page faults) and more again when we study I/O (and know officially about device interrupts).
A number of the points below are far from standardized.
Such items as where to place parameters, which routine saves the
registers, exact semantics of trap, etc, vary as one changes
language/compiler/OS.
Indeed some of these are referred to as calling conventions
,
i.e. their implementation is a matter of convention rather than
logical requirement.
The presentation below is, we hope, reasonable, but must be viewed as
a generic description of what could happen instead of an exact
description of what does happen with, say, C compiled by the Microsoft
compiler running on Windows XP.
Procedure f calls g(a,b,c) in process P.
stack-likestructure of control transfer: we can be sure that control will return to this f when this call to g exits. The above statement holds even if, via recursion, g calls f. (We are ignoring language features such as
throwingand
catchingexceptions, and the use of unstructured assembly coding. In the latter case all bets are off.)
We mean one procedure running in kernel mode calling another procedure, which will also be run in kernel mode. Later, we will discuss switching from user to kernel mode and back.
There is not much difference between the actions taken during a kernel-mode procedure call and during a user-mode procedure call. The procedures executing in kernel-mode are permitted to issue privileged instructions, but the instructions used for transferring control are all unprivileged so there is no change in that respect.
One difference is that often a different stack is used in kernel mode, but that simply means that the stack pointer must be set to the kernel stack when switching from user to kernel mode. But we are not switching modes in this section; the stack pointer already points to the kernel stack. Often there are two stack pointers one for kernel mode and one for user mode.
The trap instruction, like a procedure call, is a synchronous transfer of control: We can see where, and hence when, it is executed. In this respect, there are no surprises. Although not surprising, the trap instruction does have an unusual effect, processor execution is switched from user-mode to kernel-mode. That is, the trap instruction normally itself is executed in user-mode (it is naturally an UNprivileged instruction), but the next instruction executed (which is NOT the instruction written after the trap) is executed in kernel-mode.
Process P, running in unprivileged (user) mode, executes a trap.
The code being executed is written in assembler since there are no
high level languages that generate a trap instruction.
There is no need to name the function that is executing.
Compare the following example to the explanation of f calls g
given above.
nameof the code-sequence to which the processor will jump rather than as an argument to trap. Indeed arguments to trap are typically constants.
interruptappears because an RTI is also used when the kernel is returning from an interrupt as well as the present case when it is returning from an trap.
Remark: A good way to use the material in the addendum is to compare the first case (user-mode f calls user-mode g) to the TRAP/RTI case line by line so that you can see the similarities and differences.
I must note that Tanenbaum is a big advocate of the so called microkernel approach in which as much as possible is moved out of the (supervisor mode) kernel into separate processes. The (hopefully small) portion left in supervisor mode is called a microkernel.
In the early 90s this was popular.
Digital Unix (now called True64) and Windows NT/2000/XP/Vista are
examples.
Digital Unix is based on Mach, a research OS from Carnegie Mellon
university.
Lately, the growing popularity of Linux has called into
question the belief that
all new operating systems will be microkernel based
.
The previous picture: one big program
The system switches from user mode to kernel mode during the poof and
then back when the OS does a return
(an RTI or return
from interrupt).
But of course we can structure the system better, which brings us to.
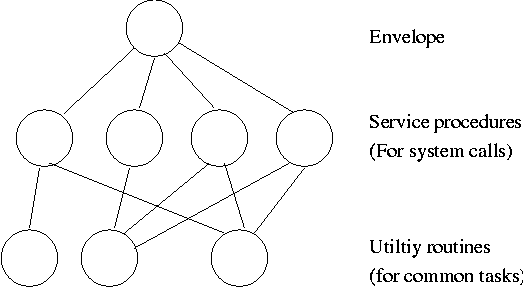
Some systems have more layers and are more strictly structured.
An early layered system was THE
operating system by
Dijkstra and his students at Technische Hogeschool Eindhoven.
This was a simple batch system so the operator
was the user.
The layering was done by convention, i.e. there was no enforcement by hardware and the entire OS is linked together as one program. This is true of many modern OS systems as well (e.g., linux).
The multics system was layered in a more formal manner. The hardware provided several protection layers and the OS used them. That is, arbitrary code could not jump into or access data in a more protected layer.
The idea is to have the kernel, i.e. the portion running in supervisor mode, as small as possible and to have most of the operating system functionality provided by separate processes. The microkernel provides just enough to implement processes.
This does have advantages. For example an error in the file server cannot corrupt memory in the process server since they have separate address spaces (they are after all separate process). Confining the effect of errors makes them easier to track down. Also an error in the ethernet driver can corrupt or stop network communication, but it cannot crash the system as a whole.
But the microkernel approach does mean that when a (real) user process makes a system call there are more processes switches. These are not free.
Related to microkernels is the idea of putting the mechanism in the kernel, but not the policy. For example, the kernel would know how to select the highest priority process and run it, but some user-mode process would assign the priorities. One could envision changing the priority scheme being a relatively minor event compared to the situation in monolithic systems.
Dennis Ritchie, the inventor of the C programming language and co-inventor, with Ken Thompson, of Unix was interviewed in February 2003. The following is from that interview.
What's your opinion on microkernels vs. monolithic?
Dennis Ritchie: They're not all that different when you actually use them. "Micro" kernels tend to be pretty large these days, and "monolithic" kernels with loadable device drivers are taking up more of the advantages claimed for microkernels.
I should note, however, that the Minix microkernel (excluding the processes) is quite small, about 4000 lines.

When implemented on one computer, a client-server OS often uses the microkernel approach in which the microkernel just handles communication between clients and servers, and the main OS functions are provided by a number of separate processes.
A distributed system can be thought of as an extension of the client server concept where the servers are remote.
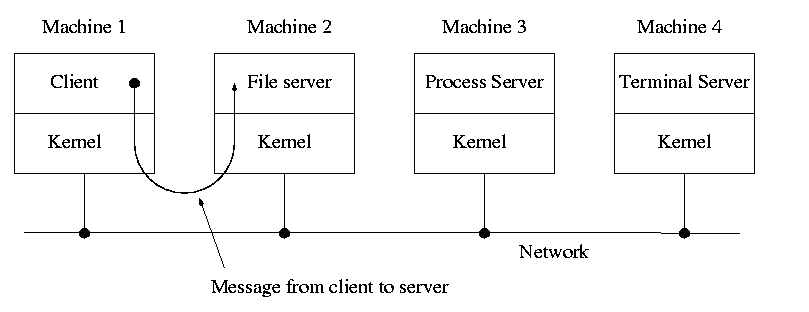
Today with plentiful memory, each machine would have all the different servers. So the only reason a message would go to another computer is if the originating process wished to communicate with a specific process on that computer (for example wanted to access a remote disk).
Homework: 24
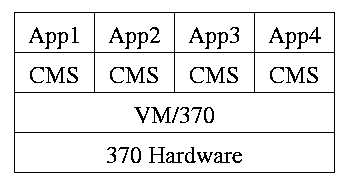
Use a hypervisor
(i.e., beyond supervisor, i.e. beyond a
normal OS) to switch between multiple
Operating Systems.
A more modern name for a hypervisor is a
Virtual Machine Monitor (VMM)
.
Recently, virtual machine technology has moved to machines (notably
x86) that are not fully virtualizable.
Recall that when CMS (running in user mode) executed a privileged
instruction, the hardware trapped to the real operating system.
On x86, privileged instructions are ignored when executed
in user mode.
Bye bye (traditional) hypervisor.
But a new style emerged where the hypervisor runs, not on the
hardware, but on the host operating system.
See the text for a sketch of how this (and another idea
paravirtualization
) works.
An important academic advance was Disco from Stanford that led to
the successful commercial product VMware.
Both AMD and Intel have extended the x86 architecture to better support virtualization. The newest processors produced today (2008) by both companies now support an additional (higher) privilege mode for the VMM. The guest OS now runs in the old privileged mode (for which it was designed) and the hypervisor/VMM runs in the new higher privileged mode from which it is able to monitor the usage of hardware resources by the guest operating system(s).
The idea is that a new (rather simple) computer architecture called the Java Virtual Machine (JVM) was invented but not built (in hardware). Instead, interpreters for this architecture are implemented in software on many different hardware platforms. Each interpreter is also called a JVM. The java compiler transforms java into instructions for this new architecture and hence can be interpreted on any machine for which a JVM exists.
This has portability as well as security advantages, but at a cost in performance.
Of course java can also be compiled to native code for a particular hardware architecture and other languages can be compiled into instructions for a software-implemented virtual machine (e.g., pascal and p-code.
Similar to VM/CMS but the virtual machines have disjoint resources (e.g., distinct disk blocks) so less remapping is needed.
Assumed knowledge.
Assumed knowledge.
Mostly assumed knowledge. Linker's very briefly discussed. My earlier discussion was much more detailed.
Extremely brief treatment with only a few points made about the running of the operating itself.
Skipped
Skipped
Assumed knowledge. Note that what is covered is just the prefixes, i.e. the names and abbreviations for various powers of 10.
Skipped, but you should read and be sure you understand it (about 2/3 of a page).