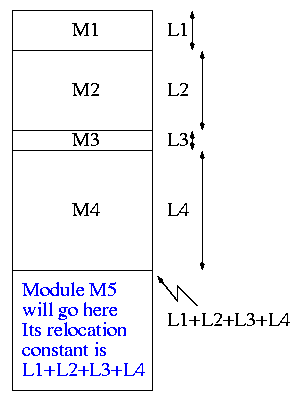
I start at -1 so that when we get to chapter 1, the numbering will agree with the text.
There is a web site for the course. You can find it from my home page, which is http://cs.nyu.edu/~gottlieb
The course text is Tanenbaum, "Modern Operating Systems", Third Edition (3e).
Replyto contribute to the current thread, but NOT to start another topic.
Grades will computed as 40%*LabAverage + 60%*FinalExam (but see homeworks below).
I use the upper left board for lab/homework assignments and announcements. I should never erase that board. Viewed as a file it is group readable (the group is those in the room), appendable by just me, and (re-)writable by no one. If you see me start to erase an announcement, let me know.
I try very hard to remember to write all announcements on the upper left board and I am normally successful. If, during class, you see that I have forgotten to record something, please let me know. HOWEVER, if I forgot and no one reminds me, the assignment has still been given.
I make a distinction between homeworks and labs.
Labs are
Homeworks are
Homeworks are numbered by the class in which they are assigned. So any homework given today is homework #1. Even if I do not give homework today, the homework assigned next class will be homework #2. Unless I explicitly state otherwise, all homeworks assignments can be found in the class notes. So the homework present in the notes for lecture #n is homework #n (even if I inadvertently forgot to write it to the upper left board).
You may solve lab assignments on any system you wish, but ...
request receiptfeature from home.nyu.edu or mail.nyu.edu and select the
when deliveredoption.
I sent it ... I never received itdebate. Thank you.
Good methods for obtaining help include
You may write your lab in Java, C, or C++.
Incomplete
The rules for incompletes and grade changes are set by the school and not the department or individual faculty member. The rules set by GSAS state:
The assignment of the grade Incomplete Pass(IP) or Incomplete Fail(IF) is at the discretion of the instructor. If an incomplete grade is not changed to a permanent grade by the instructor within one year of the beginning of the course, Incomplete Pass(IP) lapses to No Credit(N), and Incomplete Fail(IF) lapses to Failure(F).
Permanent grades may not be changed unless the original grade resulted from a clerical error.
Our policy on academic integrity, which applies to all graduate courses in the department, can be found here.
A recent email from Rosmary Amico may also be of interest.
Dear faculty,
The vast majority of our students comply with the
department's academic integrity policies; see
www.cs.nyu.edu/web/Academic/Undergrad/academic_integrity.html
www.cs.nyu.edu/web/Academic/Graduate/academic_integrity.html
Unfortunately, every semester we discover incidents in
which students copy programming assignments from those of
other students, making minor modifications so that the
submitted programs are extremely similar but not identical.
To help in identifying inappropriate similarities, we
suggest that you and your TAs consider using Moss, a
system that automatically determines similarities between
programs in several languages, including C, C++, and Java.
For more information about Moss, see:
http://theory.stanford.edu/~aiken/moss/
Feel free to tell your students in advance that you will be
using this software or any other system. And please emphasize,
preferably in class, the importance of academic integrity.
Rosemary Amico
Assistant Director, Computer Science
Courant Institute of Mathematical Sciences
I do not assume you have had an OS course as an undergraduate, and I do not assume you have had extensive experience working with an operating system.
If you have already had an operating systems course, this course is probably not appropriate. For example, if you can explain the following concepts/terms, the course is probably too elementary for you.
I do assume you are an experienced programmer, at least to the extent that you are comfortable writing modest size (several hundred line) programs.
Originally called a linkage editor by IBM.
A linker is an example of a utility program included with an operating system distribution. Like a compiler, the linker is not part of the operating system per se, i.e. it does not run in supervisor mode. Unlike a compiler it is OS dependent (what object/load file format is used) and is not (normally) language dependent.
Link of course.
When the compiler and assembler have finished processing a module,
they produce an object module
that is almost runnable.
There are two remaining tasks to be accomplished before object modules
can be run.
Both are involved with linking (that word, again) together multiple
object modules.
The tasks are relocating relative addresses
and resolving external references.
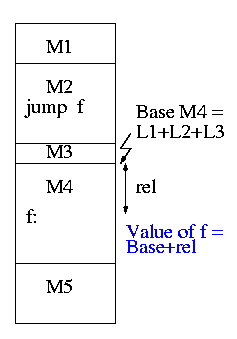
The output of a linker is called a load module because it is now ready to be loaded and run.
To see how a linker works lets consider the following example, which is the first dataset from lab #1. The description in lab1 is more detailed.
The target machine is word addressable and each word consists of 4 decimal digits. The first (leftmost) digit is the opcode and the remaining three digits form an address.
Each object module contains three parts, a definition list, a use list, and the program text itself. Each definition is a pair (sym, loc). Each entry in the use list is a symbol.
The program text consists of a count N followed by N pairs (type, word), where word is a 4-digit instruction described above and type is a single character indicating if the address in the word is Immediate, Absolute, Relative, or External.
The actions taken by the linker depend on the type of the instruction below as we now illustrate.
Input set #1 1 xy 2 2 z 2 -1 xy 4 -1 5 R 1004 I 5678 E 2000 R 8002 E 7001 0 1 z 1 2 3 -1 6 R 8001 E 1000 E 1000 E 3000 R 1002 A 1010 0 1 z 1 -1 2 R 5001 E 4000 1 z 2 2 xy 2 -1 z 1 -1 3 A 8000 E 1001 E 2000
The first pass simply finds the base address of each module and produces the symbol table giving the values for xy and z (2 and 15 respectively). The second pass does the real work using the symbol table and base addresses produced in pass one.
Symbol Table
xy=2
z=15
Memory Map
+0
0: R 1004 1004+0 = 1004
1: I 5678 5678
2: xy: E 2000 ->z 2015
3: R 8002 8002+0 = 8002
4: E 7001 ->xy 7002
+5
0 R 8001 8001+5 = 8006
1 E 1000 ->z 1015
2 E 1000 ->z 1015
3 E 3000 ->z 3015
4 R 1002 1002+5 = 1007
5 A 1010 1010
+11
0 R 5001 5001+11= 5012
1 E 4000 ->z 4015
+13
0 A 8000 8000
1 E 1001 ->z 1015
2 z: E 2000 ->xy 2002
The output above is more complex than I expect you to produce. The detail is there to help me explain what the linker is doing. All I would expect from you is the symbol table and the rightmost column of the memory map.
You must process each module separately, i.e. except for the symbol table and memory map your space requirements should be proportional to the largest module not to the sum of the modules. This does NOT make the lab harder.
Remark: It is faster (less I/O) to do a one pass
approach, but is harder since you need fix-up code
whenever a use occurs in a module that precedes the module with the
definition.
The linker on unix was mistakenly called ld (for loader), which is unfortunate since it links but does not load.
.TH LD 1
.SH NAME
ld \- loader
.SH SYNOPSIS
.B ld
[ option ] file ...
.SH DESCRIPTION
.I Ld
combines several
object programs into one, resolves external
references, and searches libraries.
By the mid 80s the Berkeley version (4.3BSD) man
page referred to ld as link editor
and this more accurate
name is now standard in unix/linux distributions.
During the 2004-05 fall semester a student wrote to me
BTW - I have meant to tell you that I know the lady who
wrote ld. She told me that they called it loader, because they just
really didn't
have a good idea of what it was going to be at the time.
Lab #1: Implement a two-pass linker. The specific assignment is detailed on the class home page.
Homework: Read Chapter 1 (Introduction)
Software (and hardware, but that is not this course) is often implemented in layers. The higher layers use the facilities provided by lower layers.
Alternatively said, the upper layers are written using a more powerful and more abstract virtual machine than the lower layers.
In other words, each layer is written as though it runs on the virtual machine supplied by the lower layers and in turn provides a more abstract (pleasant) virtual machine for the higher layers to run on.
Using a broad brush, the layers are.
An important distinction is that the kernel runs in privileged/kernel/supervisor mode); whereas compilers, editors, shell, linkers. browsers etc run in user mode.
The kernel itself is itself normally layered, e.g.
The machine independent I/O part is written assuming virtual
(i.e. idealized) hardware
.
For example, the machine independent I/O portion simply reads a
block from a disk
.
But in reality one must deal with the specific disk controller.
Often the machine independent part is more than one layer.
The term OS is not well defined. Is it just the kernel? How about the libraries? The utilities? All these are certainly system software but it is not clear how much is part of the OS.
As mentioned above, the OS raises the abstraction level by providing a higher level virtual machine. A second related key objective for the OS is to manage the resources provided by this virtual machine.
The kernel itself raises the level of abstraction and hides details. For example a user (of the kernel) can write to a file (a concept not present in hardware) and ignore whether the file resides on a floppy, a CD-ROM, or a hard disk. The user can also ignore issues such as whether the file is stored contiguously or is broken into blocks.
Well designed abstractions are a key to managing complexity.
The kernel must manage the resources to resolve conflicts between users. Note that when we say users, we are not referring directly to humans, but instead to processes (typically) running on behalf of humans.
Typically the resource is shared or multiplexed between the users. This can take the form of time-multiplexing, where the users take turns (e.g., the processor resource) or space-multiplexing, where each user gets a part of the resource (e.g., memory).
With sharing comes various issues such as protection, privacy, fairness, etc.
Homework: What are the two main functions of an operating system?
Answer: Concurrency! Per Brinch Hansen in Operating Systems Principles (Prentice Hall, 1973) writes.
The main difficulty of multiprogramming is that concurrent activities can interact in a time-dependent manner, which makes it practically impossibly to locate programming errors by systematic testing. Perhaps, more than anything else, this explains the difficulty of making operating systems reliable.
Homework: 1. (unless otherwise stated, problems numbers are from the end of the current chapter in Tanenbaum.)
The subsection heading describe the hardware as well as the OS; we are naturally more interested in the latter. These two development paths are related as the improving hardware enabled the more advanced OS features.
One user (program; perhaps several humans) at a time. Although this time frame predates my own usage, computers without serious operating systems existed during the second generation and were now available to a wider (but still very select) audience.
I have fond memories of the Bendix G-15 (paper tape) and the IBM 1620 (cards; typewriter; decimal). During the short time you had the machine, it was truly a personal computer.
Many jobs were batched together, but the systems were still uniprogrammed, a job once started was run to completion without interruption and then flushed from the system.
A change from the previous generation is that the OS was not reloaded for each job and hence needed to be protected from the user's execution. Previously, the beginning of your job contained the trivial OS-like support features.
The batches of user jobs were prepared offline (cards to tape) using a separate computer (an IBM 1401 with a 1402 reader/punch). The tape was brought to the main computer (an IBM 7090/7094) where the output to be printed was written on another tape. This tape went back to the 1401 and was printed on a 1403.
In my opinion this is the biggest change from the OS point of view. It is with multiprogramming (multiple users executing concurrently) that we have the operating system fielding requests whose arrival order is non-deterministic (at the pragmatic level). Now operating systems become notoriously hard to get right due to the inability to test a significant percentage of the possible interactions and the inability to reproduce bugs on request.
efficientuser of resources, but is more difficult.
holesarise.
spoolingtheir own jobs on a remote terminal. Deciding when to switch and which process to switch to is called scheduling.
Homework: Why was timesharing not widespread on second generation computers?
Homework: 2.
Remark: I very much recommend reading all of 1.2, not for this course especially, but for general interest. Tanenbaum writes well and is my age so lived through much of the history himself.
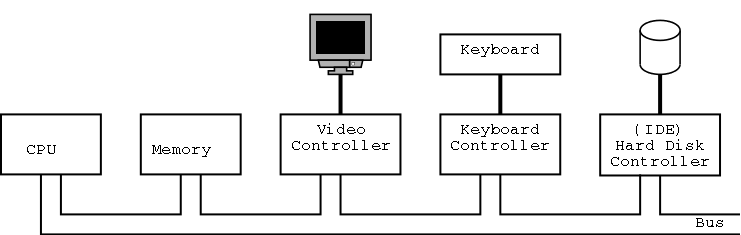
The picture above is very simplified. (For one thing, today separate buses are used to Memory and Video.)
A bus is a set of wires that connect two or more devices.
Only one message can be on the bus at a time.
All the devices receive
the message:
There are no switches in between to steer the message to the desired
destination, but often some of the wires form an address that
indicates which devices should actually process the message.
Only at a few points will we get into sufficient detail to need to understand the various processor registers such as program counters, stack pointers, and Program Status Words (PSWs). We will ignore computer design issues such as pipelining and superscalar.
We do, however, need the notion of a trap, that is an instruction that atomically switches the processor into privileged mode and jumps to a pre-defined physical address. We will have much more to say about traps later in the course.
Many of the OS issues introduced by muti-processors of any flavor are also found in a uni-processor, multi-programmed system. In particular, successfully handling the concurrency offered by the second class of systems, goes a long way toward preparing for the first class. The remaining multi-processor issues are not covered in this course.
We will ignore caches, but will (later) discuss demand paging, which is very similar (although demand paging and caches use completely disjoint terminology). In both cases, the goal is to combine large, slow memory with small, fast memory to achieve the effect of large, fast memory. We cover caches in our computer design (aka architecture) courses (you can access my class notes off my home page).
The central memory in a system is called RAM (Random Access Memory). A key point is that it is volatile, i.e. the memory loses its data if power is turned off.
ROM (Read Only Memory) is used to hold software that often comes with devices (low-level control) on general purpose computers and for the entire software system on non-user-programmable devices such as microwaves and wristwatches. It is also used for non-changing data. A modern, familiar ROM is CD-ROM (or the denser DVD). ROM is non-volatile.
But often this unchangable data needs to be changed (e.g., to fix bugs). This gives rise first to PROM (Programmable ROM), which, like a CD-R, can be written once (as opposed to being mass produced already written like a CD-ROM), and then to EPROM (Erasable PROM), which is like a CD-RW. An EPROM is especially convenient if it can be erased with a normal circuit (EEPROM, Electrically EPROM or Flash RAM).
As mentioned above when discussing OS/MFT and OS/MVT, multiprogramming requires that we protect one process from another. That is we need to translate the virtual addresses of each program into physical addresses such that the physical address of each process do not clash. The hardware that performs this translation is called the MMU or Memory Management Unit.
When context switching from one process to another, the translation must change, which can be an expensive operation.
When we do I/O for real, I will show a real disk opened up and illustrate the components
Devices are often quite difficult to manage and a separate computer, called a controller, is used to translate OS commands into what the device requires.
The bottom of the memory hierarchy, tapes have huge capacities, tiny cost per byte, and very long access times.
In addition to the disks and tapes just mentioned, I/O devices include monitors (and graphics controllers), NICs (Network Interface Controllers), Modems, Keyboards, Mice, etc.
The OS communicates with the device controller, not with the device itself. For each different controller, a corresponding device driver is included in the OS. Note that, for example, many graphics controllers are capable of controlling a standard monitor, and hence the OS needs many graphics device drivers.
In theory any SCSI (Small Computer System Interconnect) controller can control any SCSI disk. In practice this is not true as SCSI gets inproved to wide scsi, ultra scsi, etc. The newer controllers can still control the older disks and often the newer disks can run in degraded mode with an older controller.
Three methods are employed.
We discuss these alternatives more in chapter 5. In particular, we explain the last point about halving bus accesses.
Homework: 3.
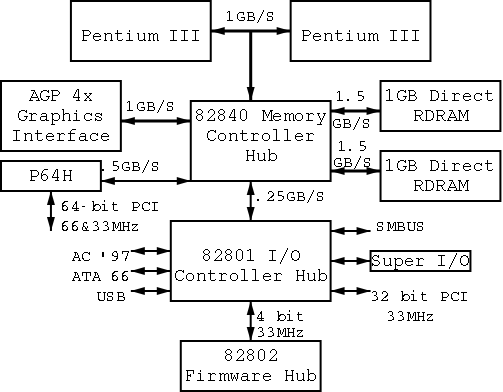
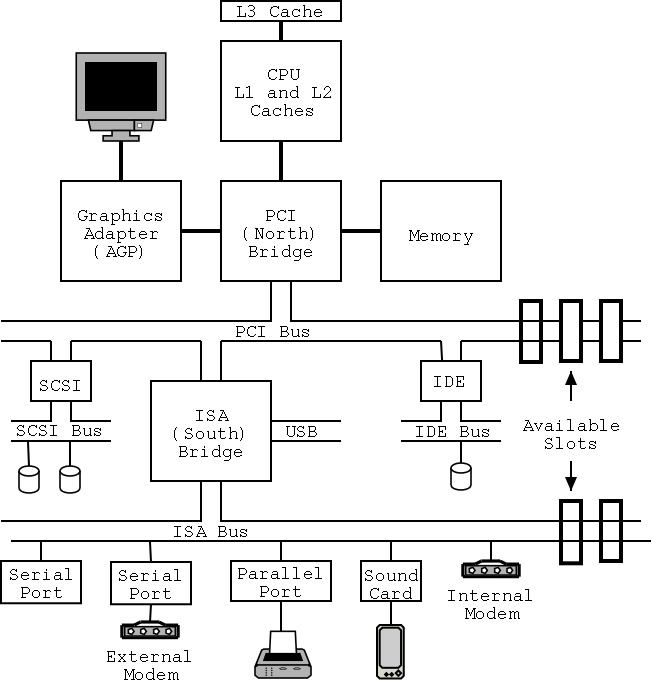
On the right is a figure showing the specifications for an Intel chip set introduced in 2000. Many different names are used, e.g., hubs are often called bridges. Most likely due to their location on the diagram to the right, the Memory Controller Hub is called the Northbridge and the I/O Controller Hub the Southbridge.
As shown on the right the chip set has two different width PCI buses. The figure below, which includes some devices themselves, does not show the two different PCI buses. This particular chip set supplies USB, but others do not. In the latter case, a PCI USB controller may be used.
The use of ISA (Industry Standard Architecture) is decreasing but is still found on most southbridges.
Note that the diagram below, which is close to figure 1-12 of the 3e differs from the figure to the right in at least two respects. The connection between the bridges is a proprietary bus and the PCI bus is generated by the Northbridge. The figure on the right is definitely correct for the specific chip set described and is very similar to the Wikipedia article.
Remark: In January 2008, I received an email reply from Tanenbaum stating that he will try to fix the diagram in the book in the next printing.
When the power button is pressed control starts at the BIOS a
(typically flash) ROM in the system.
Control is then passed to (the tiny program stored in) the MBR
(Master Boot Record), which is the first 512-byte block on the
primary
disk.
Control then proceeds to the first block in the active
partition and from there the OS (normally via an OS loader) is
finally invoked.
The above assumes that the boot medium selected by the bios was the hard disk. Other possibilities include: floppy, CD-ROM, NIC.
There is not much difference between mainframe, server, multiprocessor, and PC OS's. Indeed 3e has considerably softened the differences given in the 2e. For example Unix/Linux and Windows runs on all of them.
This course covers these four classes (or one class).
Used in data centers, these systems ofter tremendous I/O capabilities and extensive fault tolerance.
Perhaps the most important servers today are web servers. Again I/O (and network) performance are critical.
A multiprocessor (as opposed to a multi-computer or multiple computers or computer network or grid) means multiple processors sharing memory and controlled by a single instance of the OS, which typically can run on any of the processors. Often it can run on several simultaneously.
These existed almost from the beginning of the computer age, but now are not exotic. Indeed even my laptop is a multiprocessor.
The operating system(s) controlling a system of multiple computers often are classified as either a Network OS, which is basically a collection of ordinary PCs on a LAN that use the network facilities available on PC operating systems. Some extra utilities are often present to ease running jobs on other processors.
A more sophisticated Distributed OS is a
more seamless
version of the above where the boundaries
between the processors are made nearly invisible to users (except
for performance).
This subject is not part of our course (but often is covered G22.2251).
In the recent past some OS systems (e.g., ME) were claimed to be tailored to client operation. Others felt that they were restricted to client operation. This seems to be gone now; a modern PC OS is fully functional. I guess for marketing reasons some of the functionality can be disabled.
This includes PDAs and phones, which are rapidly merging.
The only real difference between this class and the above is the
restriction to very modest memory.
However, very modest
keeps getting bigger and some phones now
include a stripped-down linux.
The OS is part of
the device, e.g., microwave ovens,
and cardiac monitors.
The OS is on a ROM so is not changed.
Since no user code is run, protection is not as important. In that respect the OS is similar to the very earliest computers. Embedded OS are very important commercially, but not covered much in this course.
Embedded systems that also contain sensors and communication devices so that the systems in an area can cooperate.
As the name suggests, time (more accurately timeliness) is an important consideration. There are two classes: Soft vs hard real time. In the latter missing a deadline is a fatal error—sometimes literally. Very important commercially, but not covered much in this course.
Very limited in power (both meanings of the word).