Start Lecture #13
Homework: Read Chapter 8.
Goal: Transform the intermediate code and tables produced by the front end into final machine (or assembly) code. Code generation plus optimization constitutes the back end of the compiler.
As expected the input to the code generator is the output of the intermediate code generator. We assume that all syntactic and semantic error checks have been done by the front end. Also, all needed type conversions are already done and any type errors have been detected.
We are using three address instructions for our intermediate language. These instructions have several representations, quads, triples, indirect triples, etc. In this chapter I will tend to use the term quad (for brevity) when I should really say three-address instruction, since the representation doesn't matter.
A RISC (Reduced Instruction Set Computer), e.g. PowerPC, Sparc, MIPS (popular for embedded systems), is characterized by
Onlyloads and stores touch memory.
A CISC (Complex Instruct Set Computer), e.g. x86, x86-64/amd64 is characterized by
A stack-based computer is characterized by
Noregisters.
An accumulator-based computer is characterized by
IBM 701/704/709/7090/7094 (Moon shot, MIT CTSS) were accumulator based.
Stack based machines were believed to be good compiler targets. They became very unpopular when it was believed that register architecture would perform better. Better compilation (code generation) techniques appeared that could take advantage of the multiple registers.
Pascal P-code and Java byte-code are the machine instructions for a hypothetical stack-based machines, the JVM (Java Virtual Machine) in the case of Java. This code can be interpreted or compiled to native code.
RISC became all the rage in the 1980s.
CISC made a gigantic comeback in the 90s with the intel pentium
pro.
A key idea of the pentium pro is that the hardware would
dynamically translate a complex x86 instruction into a series of
simpler RISC-like
instructions called ROPs (RISC ops).
The actual execution engine dealt with ROPs.
The jargon would be that, while the architecture (the ISA) remained
the x86, the micro-architecture was quite different and more like
the micro-architecture seen in previous RISC processors.
For maximum compilation speed of modest size programs, the compiler
accepts the entire program at once and produces code that can be
loaded and executed (the compilation system can include a simple
loader and can start the compiled program).
This was popular for student jobs
when computer time was
expensive.
The alternative, where each procedure can be compiled separately,
requires a linkage editor.
It eases the compiler's task to produce assembly code instead of machine code and we will do so. This decision increases the total compilation time since it requires an extra assembler pass (or two).
A big question is the level of code quality we seek to attain.
For example we can simply translate one quadruple at a time.
The quad
x = y + z
can always (assuming the addresses x, y, and z are each a compile
time constant off a given register, e.g., the sp) be compiled
into 4 RISC-like instructions (fewer CISC instructions would
suffice) using only 2 registers R0 and R1.
LD R0, y
LD R1, z
ADD R0, R0, R1
ST x, R0
But if we apply this to each quad separately (i.e., as a separate
problem) then
a = b + c
d = a + e
is compiled into
LD R0, b
LD R1, c
ADD R0, R0, R1
ST a, R0
LD R0, a
LD R1, e
ADD R0, R0, R1
ST d, R0
The fifth statement is clearly not needed since we are loading into
R0 the same value that it contains.
This inefficiency is caused by our compiling the second quad with no
knowledge of how we compiled the first quad.
Since registers are the fastest memory in the computer, the ideal solution is to store all values in registers. However, there are normally not nearly enough registers for this to be possible. So we must choose which values are in the registers at any given time.
Actually this problem has two parts.
The reason for the second problem is that often there are register requirements, e.g., floating-point values in floating-point registers and certain requirements for even-odd register pairs (e.g., 0&1 but not 1&2) for multiplication/division. We shall concentrate on the first problem.
Sometimes better code results if the quads are reordered. One example occurs with modern processors that can execute multiple instructions concurrently, providing certain restrictions are met (the obvious one is that the input operands must already be evaluated).
This is a delicate compromise between RISC and CISC.
The goal is to be simple but to permit the study of nontrivial
addressing modes and the corresponding optimizations.
A charging
scheme is instituted to reflect that complex addressing
modes are not free.
We postulate the following (RISC-like) instruction set
Load. LD dest, addr
loads the destination dest with the contents of the
address addr.
LD reg1, reg2
is a register copy.
A question is whether dest can be a memory location or whether it must be a register. This is part of the RISC/CISC debate. In CISC parlance, no distinction is made between load and store, both are examples of the general move instruction that can have an arbitrary source and an arbitrary destination.
We will normally not use a memory location for the destination of a load (or the source of a store). This implies that we are not able to perform a memory to memory copy in one instruction.
As will be seen below, in those places where a memory location is permitted, we charge more than for a register.
Store. ST addr, src
stores the value of the source src (register) into
the address addr.
#181) to be used instead of a register, but again we charge extra.
Computation. OP dest, src1, src2
or dest = src1 OP
src2
performs the operation OP on the two source operands
src1 and src2.
For a RISC architecture the three operands must be registers. This will be our emphasis (extra charge for an integer src). If the destination register is one of the sources, the source is read first and then overwritten (in one cycle by utilizing a master-slave flip-flop, when both are registers.)
Unconditional branch. BR L
transfers control to the (instruction with) label L.
When used with an address rather than a label it means to goto that address. Note that we are using the l-value of the address.
Remark: This is unlike the situation with a load instruction in which case the r-value i.e., the contents of the address, is loaded into the register. Please do not be confused by this usage. The address or memory address always refers to the location, i.e., the l-value. Some instructions, e.g., LD, require that the location be dereferenced, i.e, that the r-value be obtained
Conditional Branch. Bcond r, L
transfers to the label (or location) L if register
r satisfies the condition cond.
For example,
BNEG R0, joe
branches to joe if
R0 is negative.
The addressing modes are not simply RISC-like, as they permit indirection through memory locations. Again, note that we shall charge extra for some such operands.
Recall the difference between an l-value and an r-value, e.g. the
difference between the uses of x in
x = y + 3
and
z = x + 12
The first refers to an address, the second to a value
(stored in that address).
We assume the machine supports the following addressing modes.
Variable name.
This is shorthand (or assembler-speak) for the memory location
containing the variable, i.e., we use the l-value of the
variable name.
So
LD R1, a
sets the contents of R1 equal to the contents of
a, i.e.,
contents(R1) := contents(a)
Do not get confused here. The l-value of a is used as the address (that is what the addressing mode tells us). But the load instruction itself loads the first operand with the contents of the second. That is why it is the r-value of the second operand that is placed into the first operand.
Indexed address.
The address a(reg), where a is a variable name and
reg is a register (i.e., a register number), specifies the
address that is the r-value-of-reg bytes past the address
specified by a.
That is, the address is computed as the l-value of a plus the
r-value of reg.
So
LD r1, a(r2)
sets
contents(r1) :=
contents(a+contents(r2))
NOT
contents(r1) :=
contents(contents(a)+contents(r2))
Permitting this addressing mode outside a load or store instruction, which we shall not do, would strongly suggest a CISC architecture.
Indexed constant.
An integer constant can be indexed by a register.
So
LD r1, 8(r4)
sets
contents(r1) :=
contents(8+contents(r4)).
In particular,
LD r1, 0(r4)
sets
contents(r1) :=
contents(contents(r4)).
Indirect addressing.
If I is an integer constant and r is a
register, the previous addressing mode tells us that
I(r) refers to the address
I+contents(r).
The new addressing mode *I(r) refers to the address
contents(I+contents(r)).
The address *r is shorthand for *0(r).
The address *10 is shorthand for
*10(fakeRegisterContainingZero).
So
LD r1, *50(r2)
sets
contents(r1) :=
contents(contents(50+contents(r2))).
and
LD r1, *r2
sets
(get ready)
contents(r1) :=
contents(contents(contents(r2)))
and
LD r1, *10
sets
contents(r1) :=
contents(contents(10))
Immediate constant. If a constant is preceded by a # it is treated as an r-value instead of as a register number. So
ADD r2, r2, #1is an increment instruction. Indeed
ADD 2, 2, #1does the same thing, but we probably won't write that; for clarity we will normally write registers beginning with an r
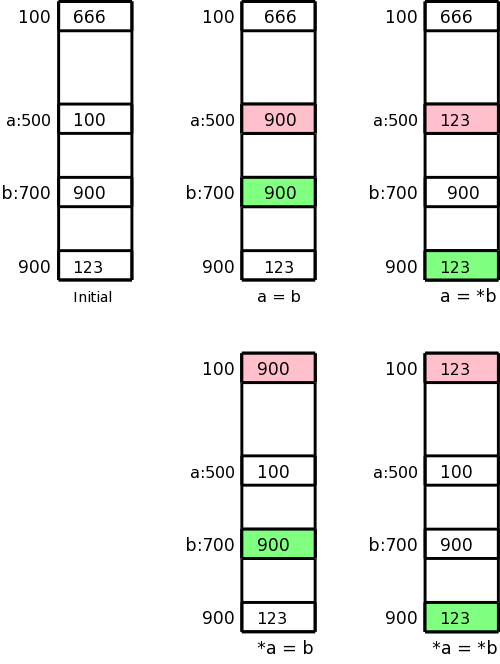
Remember that in 3-address instructions, the variables written are addresses, i.e., they represent l-values.
Let us assume the l-value of a is 500 and the l-value b is 700, i.e., a and b refer to locations 500 and 700 respectively. Assume further that location 100 contains 666, location 500 contains 100, location 700 contains 900, and location 900 contains 123. This initial state is shown in the upper left picture.
In the four other pictures the contents of the pink location has been changed to the contents of the light green location. These correspond to the three-address assignment statements shown below each picture. The machine instructions indicated below implement each of these assignment statements.
a = b
LD R1, b
ST a, R1
a = *b
LD R1, b
LD R1, 0(R1)
ST a, R1
*a = b
LD R1, b
LD R2, a
ST 0(R2), R1
*a = *b
LD R1, b
LD R1, 0(R1)
LD R2, a
ST 0(R2), R1
For many quads the naive (RISC-like) translation is 4 instructions.
Array assignment statements are also four instructions. We can't have a quad A[i]=B[j] because that needs four addresses and quads have only three. Similarly, we can't use an array in a computation statement like a[i]=x+y because it again would need four addresses.
The instruction x=A[i] becomes (assuming each element of A is 4 bytes. Actually, our intermediate code generator already does the multiplication so we would not generate a multiply here).
LD R0, i
MUL R0, R0, #4
LD R0, A(R0)
ST x, R0
Similarly A[i]=x becomes (again our intermediate code generator already does the multiplication).
LD R0, i
MUL R0, R0, #4
LD R1, x
ST A(R0), R1
The (C-like) pointer reference x = *p becomes
LD R0, p
LD R0, 0(R0)
ST x, R0
The assignment through a pointer *p = x becomes
LD R0, x
LD R1, p
ST 0(R1), R0
Finally, if x < y goto L becomes
LD R0, x
LD R1, y
SUB R0, R0, R1
BNEG R0, L
With a modest amount of additional effort much of the output of lab 4 could be turned into naive assembly language. We will not do this. Instead, we will spend the little time remaining learning how to generate less-naive assembly language.
Generating good code requires that we have a metric, i.e., a way of quantifying the cost of executing the code.
The run-time cost of a program depends on (among other factors)
Here we just determine the first cost, and use quite a simple metric. We charge for each instruction one plus the cost of each addressing mode used.
Addressing modes using just registers have zero cost, while those involving memory addresses or constants are charged one. None of our addressing modes have both a memory address and a constant or two of either one.
The charge corresponds to the size of the instruction since a memory address or a constant is assumed to be stored in a word right after the instruction word itself.
You might think that we are measuring the memory (or space) cost of the program not the time cost, but this is mistaken: The primary space cost is the size of the data, not the size of the instructions. One might say we are charging for the pressure on the I-cache.
For example, LD R0, *50(R2) costs 2, the additional cost is for the constant 50.
I believe that the book special cases the addresses 0(reg) and *0(reg) so that the 0 is not explicitly stored and not charged for. The significance for us is calculating the length an instruction such as
LD R1, 0(R2)
We care about the length of an instruction when we need to generate
a branch that skips over it.
Homework: 1, 2, 3, 4. Calculate the cost for 2c.
There are 4 possibilities for addresses that must be generated depending on which of the following areas the address refers to.
Returning to the glory days of Fortran, we first consider a system with only static allocation, i.e., with all address in the first two classes above. Remember, that with static allocation we know before execution where all the data will be stored. There are no recursive procedures; indeed, there is no run-time stack of activation records. Instead the ARs (one per procedure) are statically allocated by the compiler.
In this simplified situation, calling a parameterless procedure just
uses static addresses and can be implemented by two instructions.
Specifically,
call callee
can be implemented by
ST callee.staticArea, #here+20
BR callee.codeArea
Assume, for convenience, that the return address is the first location in the activation record (in general, for a parameterless procedure, the return address would be a fixed offset from the beginning of the AR). We use the attribute staticArea for the address of the AR for the given procedure (remember again that there is no stack and no heap).
What is the mysterious #here+20?
We know that # signifies an immediate constant. We use here to represent the address of the current instruction (the compiler knows this value since we are assuming that the entire program, i.e., all procedures, are compiled at once). The two instructions listed contain 3 constants, which means that the entire sequence takes 2+3=5 words or 20 bytes. Thus here+20 is the address of the instruction after the BR, which is indeed the return address.
With static allocation, the compiler knows the address of the the AR for the callee and we are assuming that the return address is the first entry. Then a procedure return is simply
BR *callee.staticArea
Let's make sure we understand the indirect addressing here.
The value callee.staticArea is the address of a memory location into which the caller placed the return address. So the branch is not to callee.staticArea, but instead to the return address, which is the value contained in callee.staticArea.
Note: You might well wonder why the load
LD r0, callee.staticArea
places the contents of callee.staticArea into R0
without needing a *.
The answer, as mentioned above, is that branch and load have different semantics: Both take an address as an argument, branch jumps to that address, whereas, load retrieves the contents.
We consider a main program calling a procedure P and then
halting.
Other actions by Main and P are indicated by subscripted uses
of other
.
// Quadruples of Main other1 call P other2 halt // Quadruples of P other3 return
Let us arbitrarily assume that the code for Main starts in location 1000 and the code for P starts in location 2000 (there might be other procedures in between). Also assume that each otheri requires 100 bytes (all addresses are in bytes). Finally, we assume that the ARs for Main and P begin at 3000 and 4000 respectively. Then the following machine code results.
// Code for Main
1000: Other1
1100: ST 4000, #1120 // P.staticArea, #here+20
1112: BR 2000 // Two constants in previous instruction take 8 bytes
1120: other2
1220: HALT
...
// Code for P
2000: other3
2100: BR *4000
...
// AR for Main
3000: // Return address stored here (not used
)
3004: // Local data for Main starts here
...
// AR for P
4000: // Return address stored here
4004: // Local data for P starts here