Start Lecture #11
Remark: Lab 4 assigned.
The steps for addition, subtraction, multiplication, and division are all essentially the same:
Two functions are convenient.
LUB is simple, just look at the address latice. If one of the type arguments is not in the lattice, signal an error; otherwise find the lowest common ancestor. For our case the lattice is trivial, real is above int.
The widen function is more interesting. It involves n2 cases for n types. Many of these are error cases (e.g., if t wider than w). Below is the code for our situation with two possible types integer and real. The four cases consist of 2 nops (when t=w), one error (t=real; w=integer) and one conversion (t=integer; w=real).
widen (a:addr, t:type, w:type, newcode:string, newaddr:addr)
if t=w
newcode = ""
newaddr = a
else if t=integer and w=real
newaddr = new Temp()
newcode = gen(newaddr = (real) a)
else signal error
With these two functions it is not hard to modify the rules to catch type errors and perform coercions for arithmetic expressions.
This requires that we have type information for the base entities, identifiers and numbers. The lexer supplies the type of the numbers.
It is more interesting for the identifiers. We inserted that information when we processed declarations. So we now have another semantic check: Is the identifier declared before it is used?
We will not explicitly perform this check. To do so would not be hard.
The following analysis is similar to the one given in the previous homework solution. I repeat the explanation here because it is important to understand the workings of SDDs.
Before taking on the entire SDD, let's examine a particularly interesting entry
identifier-statement → IDENTIFIER rest-of-assignment
and its right child
rest-of-assignment → index := expression ;
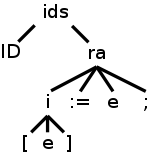
Consider the assignment statement
A[3/X+4] := X*5+Y;
the top of whose parse tree is shown on the right (again making the
simplification to one-dimensional arrays by replacing indices with
index).
Consider the ra node, i.e., the node corresponding to the
production.
ra → i := e ;
When the tree traversal gets to the ra node the first time, its parent has passed in the value of the inherited attribute ra.id=id.entry. Thus the ra node has access to the identifier table entry for ID, which in our example is the variable A.
Prior to doing its calculations, the ra node invokes its children and gets back all the synthesized attributes. Alternately said, when the tree traversal gets to this node the last time, the children have returned all the synthesized attributes. To summarize, when the ra node finally performs its calculations, it has available.
| Production | Semantic Rule |
|---|---|
| ids → ID ra | ra.id = ID.entry
ids.code = ra.code
|
| ra → := e ; |
widen(e.addr, e.type, ra.id.basetype, ra.code1, ra.addr)
ra.code = e.code || ra.code1 || gen(ra.id.lexeme=ra.addr)
|
| ra → i = e ; Note: i not is | ra.t1 = newTemp()
widen(e.addr, e.type, ra.id.basetype, ra.code1, ra.addr)
ra.code = i.code || gen(ra.t1 = getBaseWidth(ra.id)*i.addr)|| e.code || ra.code1 || gen(ra.id.lexeme[ra.t1]=ra.addr) |
| i → e | i.addr = e.addr
i.type = e.type
i.code = e.code
|
| e → e1 ADDOP t | e.addr = new Temp()
e.type = LUB(e1.type, t.type)
e.code = e1.code || e.code1 || t.code || e.code2 ||widen(e1.addr, e1.type, e.type, e.code1, e.addr1) widen(t.addr, t.type, e.type, e.code2, e.addr2) gen(e.addr = e.addr1 ADDOP.lexeme e.addr2) |
| e → t | e.addr = t.addr
e.type = t.type
e.code = t.code
|
| t → t1 MULOP f | t.addr = new Temp()
t.type = LUB(t1.type, f.type)
t.code = t1.code || t.code1 || f.code || t.code2 ||widen(t1.addr, t1.type, t.type, t.code1, t.addr1) widen(f.addr, f.type, t.type, t.code2, t.addr2) gen(t.addr = t.addr1 MULOP.lexeme t.addr2) |
| t → f | t.addr = f.addr
t.type = f.type
t.code = f.code
|
| f → ( e ) | f.addr = e.addr
f.type = e.type
f.code = e.code
|
| f → NUM | f.addr = NUM.lexeme
f.type = NUM.entry.type
f.code = ""
|
|
f → ID (i.e., indices=ε) |
f.addr = ID.lexeme
f.type = getBaseType(ID.entry)
f.code = ε
|
| f → ID i Note: i not is |
f.t1 = new Temp() f.addr = new Temp() f.type = getBaseType(ID.entry)
f.code = i.code || gen(f.t1=i.addr*getBaseWidth(ID.entry))|| gen(f.addr=ID.lexeme[f.t1]) |
What must the ra node do?
I hope the above illustration clarifies the semantic rules for
the
ra → i := e ;
production in the SDD on the right.
Because we are not considering multidimensional-arrays, the
f → ID is
production (is abbreviates indices) is replaced by the two
special cases corresponding to scalars and one-dimensional arrays,
namely:
f → ID
f → ID i
The above illustration should also help understanding the semantic rules for this last production.
The result of incorporating these rules in our growing SDD is given here.
Homework: Same question as the previous homework
(What code is generated for the program written above?).
But the answer is different!
Please remind me to go over the answer next class.
For lab 4, I eliminated the left recursion for expression evaluation. This was an instructive exercise for me, so let's do it here.
Overloading is when a function or operator has several definitions depending on the types of the operands and result.
A key to the understand of control flow is the study of Boolean expressions, which themselves are used in two roles.
One question that comes up with Boolean expressions is whether both operands need be evaluated. If we are evaluating A or B and find that A is true, must we evaluate B? For example, consider evaluating
A=0 OR 3/A < 1.2
when A is zero.
This issue arises in other cases not involving Booleans at all. Consider A*F(x). If the compiler determines that A must be zero at this point, must it generate code to evaluate F(x)? Don't forget that functions can have side effects.
Consider
IF bool-expr-1 OR bool-expr-2 THEN
then-clause
ELSE
else-clause
END;
where bool-expr-1 and bool-expr-2 are Boolean
expressions we have already generated code for.
For a simple case think of them as Boolean variables, x and
y.
When we compile the if condition bool-expr-1 OR bool-expr-2 we do not use an OR operator. Instead, we generate jumps to either the true branch or the false branch. We shall see that the above source code in the comparatively simple case where bool-expr-1=x and bool-expr-2=y will generate
if x goto L2
goto L4
L4:
if y goto L2
goto L3
L2:
then-clause-code
goto L1
L3:
else-clause-code
L1: -- This label (if-stmt.next) was defined higher in the SDD tree
Note that the compiled code does not evaluate y if x is true. This is the sense in which it is called short-circuit code. As we have stated above, for many programming languages, it is required that we not evaluate y if x is true.
The class grammar has the following productions concerning flow of control statements.
program → procedure-def program | ε
procedure-def → PROCEDURE name-and-params IS decls BEGIN statement statements END ;
statements → statement statements | ε
statement → keyword-statement | identifier-statement
keyword-statement → return-statement | while-statement | if-statement
if-statement → IF boolean-expression THEN statements optional-else END ;
optional-else → ELSE statements | ε
while-statement → WHILE boolean-expression DO statements END ;
I don't show the productions for name-and-parameters, declarations, identifier-statement, and return-statement since they do not have conditional control flow. The productions for boolean-expression will be done in the next section.
In this section we will produce an SDD for the productions above under the assumption that the SDD for Boolean expressions generates jumps to the labels be.true and be.false (depending of course on whether the Boolean expression be is true or false).
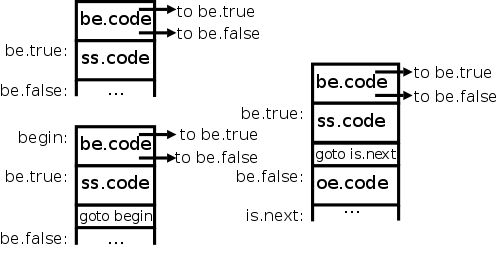
The diagrams on the right give the idea for the three basic control
flow statements, if-then (upper left), if-then-else (right), and
while-do (lower-left).
| Production | Semantic Rules |
|---|---|
| pg → pd pg1 | pd.next = new Label()
pg.code = pd.code || label(pd.next) || pg1.code
|
| pg → ε | pg.code = "" |
| pd → PROC np IS ds BEG s ss END ; | s.next = new Label()
ss.next = pd.next
pd.code = s.code || label(s.next) || ss.code
|
| ss → s ss1 | s.next = new Label()
ss1.next = ss.next
ss.code = s.code || label(s.next) || ss1.code
|
| ss → ε | ss.code = "" |
| s → ks | ks.next = s.next
s.code = ks.code
|
| ks → ifs | ifs.next = ks.next
ks.code = is.code
|
| ifs → IF be THEN ss oe END ; | be.true = new Label()
be.false = new Label()
ss.next = ifs.next
oe.next = ifs.next
ifs.code = be.code || label(be.true) || ss.code ||gen(goto is.next) || label(be.false) || oe.code |
| oe → ELSE ss | ss.next = oe.next
oe.code = ss.code
|
| oe → ε | oe.code = "" |
| ks → ws | ws.next = ks.next
ks.code = ws.code
|
| ws → WHILE be DO ss END ; | ws.begin = new Label() be.true = new Label()
be.false = ws.next
ss.next = ws.begin
ws.code = label(ws.begin) || be.code ||label(be.true) || ss.code || gen(goto begin) |
The table to the right gives the details via an SDD.
To enable the tables to fit I continue to abbreviate severely the names of the nonterminals. New abbreviations are ks (keyword-statement), ifs (if-statement), be (boolean-expression), oe (optional-else) and ws (while-statement). The remaining abbreviations, to be introduced next section, are bt (boolean-term) and bf (boolean-factor)
The treatment of the various *.next attributes deserves some
comment.
Each statement (e.g., if-statement
abbreviated ifs or while-stmt
abbreviated ws) is given, as an inherited attribute, a new
label *.next.
You can see the new label generated in the
statements → statement statements
production and then notice how it is passed down the tree
from statements to statement
to keyword-statement to
if-statementt.
The child generates a goto *.next if it wants to end (look at
ifs.code in the if-statement production).
The parent, in addition to sending this attribute to the child, normally places label(*.next) after the code for the child. See ss.code in the stmts → stmt stmts production.
An alternative design would have been for the child to itself generate the label and place it as the last component of its code (or elsewhere if needed). I believe that alternative would have resulted in a clearer SDD with fewer inherited attributes. The method actually chosen does, however, have one and possibly two advantages.
jump to jumpsequence.
I must say, however, that, given all the non-optimal code we are generating, it might have been pedagogically better to use the alternative scheme and live with the jump to a jump embarrassment. I decided in the end to follow the book, but am not sure that was the right decision.
Homework: Give the SDD for a repeat statement
REPEAT ss WHILE be END ;
| Production | Semantic Rules |
|---|---|
| be → bt OR be1 | bt.true = be.true
bt.false = new Label()
be1.true = be.true
be1.false = be.false
be.code = bt.code || label(bt.false) || be1.code
|
| be → bt | bt.true = be.true
bt.false = be.false
be.code = bt.code
|
| bt → bf AND bt1 |
bf.true = new Label()
bf.false = bt.false
bt1.true = bt.true
bt1.false = bt.false
bt.code = bf.code || label(bf.true) || bt1.code
|
| bt → bf | bf.true = bt.true
bf.false = bt.false
bt.code = bf.code
|
| bf → NOT bf1 | bf1.true = bf.false
bf1.false = bf.true
bf.code = bf1.code
|
| bf → TRUE | bf.code = gen(goto bf.true) |
| bf → FALSE | bf.code = gen(goto bf.false) |
| bf → ID | bf.code = gen(if get(ID.lexeme) goto bf.true) || gen(goto bf.false) |
| bf → e RELOP e1 | bf.code = e.code || e1.code || gen(if e.addr RELOP.lexeme e1.addr goto bf.true) || gen(goto bf.false) |
The SDD for the evaluation of Boolean expressions is given on the right. All the SDDs are assembled together here.
Recall that in evaluating the Boolean expression the objective is not simply to produce the value true or false, but instead, the goal is to generate a goto be.true or a goto be.false (depending of course on whether the Boolean expression evaluates to true or to false).
Recall as well that we must not evaluate the right-hand argument of an OR if the left-hand argument evaluates to true and we must not evaluate the right-hand argument of an AND if the left-hand argument evaluates to true.
Notice a curiosity. When evaluating arithmetic expressions, we needed to write
expr → expr + term
and not
expr → term + expr
in order to achieve left associativity.
But with jumping code we evaluate each factor (really
boolean-factor) in left to right order and jump out as soon as the
condition is determined.
Hence we can use the productions in the table, which conveniently
are not left recursive.
Look at the rules for the first production in the table. If bt yields true, then we are done (i.e., we want to jump to be.true). Thus we set bt.true=be.true, knowing that when bt is evaluated (look at be.code) bt will now jump to be.true.
On the other hand, if bt yields false, then we must evaluate be1, which is why be.code has the label for bt.false right before be1.code. In this case the value of be is the same as the value of be1, which explains the assignments to be1.true and be1.false.
Do on the board the translation of
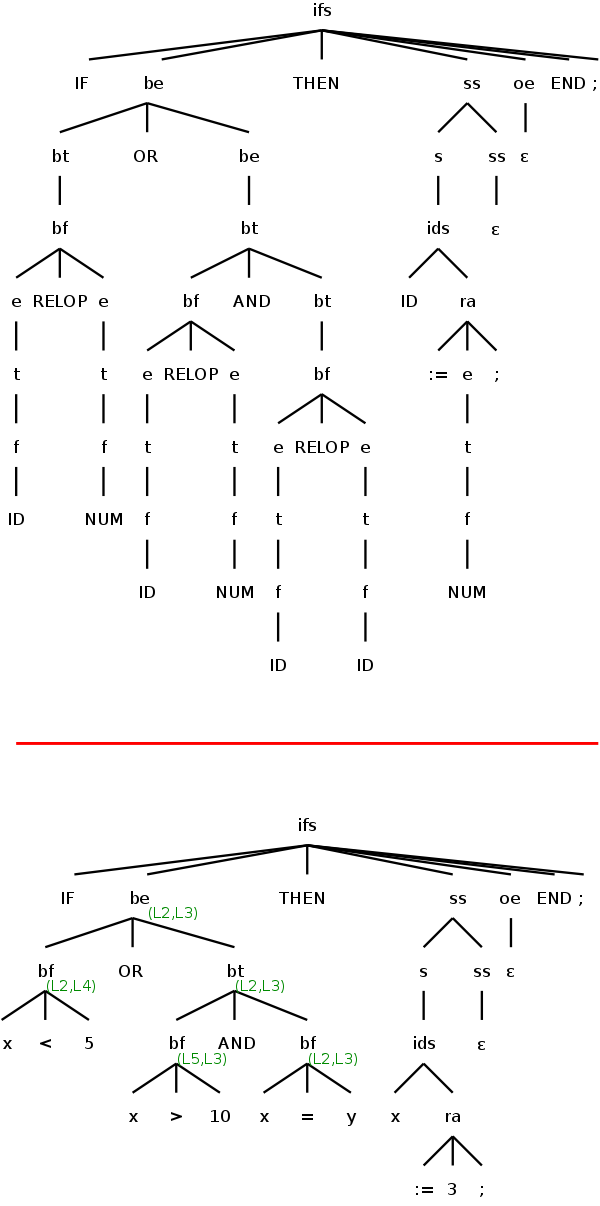
IF x<5 OR x>10 AND x=y THEN
x := 3;
END ;
We first produce the parse tree, as shown on the upper right. The tree appears quite large for such a small example. Do remember that production compilers use the (abstract) syntax tree, which is quite a bit smaller.
Notice that each e.code="" and that each e.addr is the ID or
NUM directly below it.
The real action begins with the three bf and one ra productions.
Another point is that there are several identity
productions
such as be→bt.
Thus we can simplify the parse tree to the one at the lower right.
This is not an official
tree, I am using it here just to save
some work.
Basically, I eliminated nodes that would have simply copied
attributes (inherited attributes are copied downward; synthesized
attributes are copied upwards).
I also replaced the ID, NUM, and RELOP terminals with their
corresponding lexemes.
Then, as mentioned above, I moved these lexemes up the tree to the
expr directly above them (the only exception is the LHS of the
assignment statement; the ID there is not reduced to an expr).
The Euler-tour traversal to evaluate the SDD for this parse tree
begins by processing the inherited attributes at the root.
The code fragment we are considering is not a full example (recall
that the start symbol of the grammar is program not if-stmt).
So when we start
at the if-stmt node, its inherited attribute
is.next will have been evaluated (it is a label, let's call it L1)
and the .code computed higher in the tree will place this label
right after is.code.
We go down the tree to bool-expr with be.true and .false set to new labels say L2 and L3 (these are shown in green in the diagram), and ss.next and oe.next set to ifs.next=L1 (these two .next attributes will not be used). We go down to bf (really be→bt→bf) and set .true to L2 and .false to a new label L4. We start back up with
bf.code=""||""||gen(if x<5 goto L2)||
gen(goto L4)
Next we go up to be and down to bt setting .true and .false to L2 and L3. Then down to bf with .true=L5 .false=L3, giving
bf.code=gen(if x>10 goto L5)||gen(goto L3)
Up and down to the other bf gives
bf.code=gen(if x=y goto L2)||gen(goto L3)
Next we go back up to bt and synthesize
bt.code=gen(if>10 goto L5)||gen(goto L3)||
label L5||gen(if x=y goto L2)||gen(goto L3)
We complete the Boolean expression processing by going up to be and synthesizing
be.code=gen(if x<5 goto L2)||gen(goto L4)||label(L4)||
gen(if>10 goto L5)||gen(goto L3)||
label L5||gen(if x=y goto L2)||gen(goto L3)
We have already seen assignments. You can check that s.code=gen(x:=3)
Finally we synthesize ifs.code and get (written in a more familiar style)
if x<5 goto L2
goto L4
L4:
if x>10 goto L5
goto L3
L5:
if x=y goto L2
goto L3
L2:
x:=3
goto L1
L3:
// oe.code is empty
L1:
Note that there are four extra gotos. One is a goto the next statement. Two others could be eliminated by using ifFalse. The fourth just skips over a label and empty code.
Remark: This ends the material for lab 4.