Start Lecture #4
These look like the productions of a context free grammar we saw previously, but there are differences. Let Σ be an alphabet, then a regular definition is a sequence of definitions
d1 → r1
d2 → r2
...
dn → rn
where the d's are unique and not in Σ andNote that each di can depend on all the previous d's.
Note also that each di can not depend on following d's. This is an important difference between regular definitions and productions (the latter are more powerful).
Example: C identifiers can be described by the following regular definition
letter_ → A | B | ... | Z | a | b | ... | z | _
digit → 0 | 1 | ... | 9
CId → letter_ ( letter_ | digit)*
Regular definitions are just a convenience; they add no power to
regular expressions.
The C identifier example can be done simply as a regular expression
by simply plugging in
the earlier definitions to the later
ones.
There are many extensions of the basic regular expressions given above. The following three, especially the third, will be occasionally used in this course as they are useful for lexical analyzers.
All three are simply shorthand. That is, the set of possible languages generated using the extensions is the same as the set of possible languages generated without using the extensions.
Examples:
letter_ → [A-Za-z_]
digit → [0-9]
CId → letter_ ( letter_ | digit )*
digit → [0-9]
digits → digit+
number → digits (. digits)?(E[+-]? digits)?
This is actually fairly restrictive.
For example, it doesn't permit 3. as a number.
Homework: 1(a) (you might need to read a C manual first to find out all the numerical constants in C).
Our current goal is to perform the lexical analysis needed for the following grammar.
stmt → if expr then stmt
| if expr then stmt else stmt
| ε
expr → term relop term // relop is relational operator =, >, etc
| term
term → id
| number
Recall that the terminals are the tokens, the nonterminals produce terminals.
A regular definition for the terminals is
digit → [0-9]
digits → digits+
number → digits (. digits)? (E[+-]? digits)?
letter → [A-Za-z]
id → letter ( letter | digit )*
if → if
then → then
else → else
relop → < | > | <= | >= | = | <>
On the board show how this can be done with just REs.
| Lexeme | Token | Attribute |
|---|---|---|
| Whitespace | ws | — |
| if | if | — |
| then | then | — |
| else | else | — |
| An identifier | id | Pointer to table entry |
| A number | number | Pointer to table entry |
| < | relop | LT |
| <= | relop | LE |
| = | relop | EQ |
| <> | relop | NE |
| > | relop | GT |
| >= | relop | GE |
We also want the lexer to remove whitespace so we define a new token
ws → ( blank | tab | newline ) +
where blank, tab, and newline are symbols used to represent the
corresponding ascii characters.
Recall that the lexer will be called by the parser when the latter needs a new token. If the lexer then recognizes the token ws, it does not return it to the parser but instead goes on to recognize the next token, which is then returned. Note that you can't have two consecutive ws tokens in the input because, for a given token, the lexer will match the longest lexeme starting at the current position that yields this token. The table on the right summarizes the situation.
For the parser all the relational ops are to be treated the same so they are all the same token, relop. Naturally, other parts of the compiler, for example the code generator, will need to distinguish between the various relational ops so that appropriate code is generated. Hence, they have distinct attribute values.
A transition diagram is similar to a flowchart for (a part of) the lexer. We draw one for each possible token. It shows the decisions that must be made based on the input seen. The two main components are circles representing states (think of them as decision points of the lexer) and arrows representing edges (think of them as the decisions made).
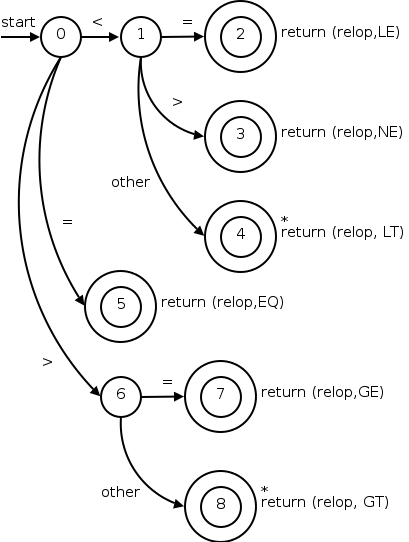
The transition diagram (3.13) for relop is shown on the right.
too farin finding the token, one (or more) stars are drawn.
It is fairly clear how to write code corresponding to this diagram. You look at the first character, if it is <, you look at the next character. If that character is =, you return (relop,LE) to the parser. If instead that character is >, you return (relop,NE). If it is another character, return (relop,LT) and adjust the input buffer so that you will read this character again since you have not used it for the current lexeme. If the first character was =, you return (relop,EQ).
The next transition diagram corresponds to the regular definition given previously.
Note again the star affixed to the final state.

Two questions remain.
then, which also match the pattern in the transition diagram?
We will continue to assume that the keywords are reserved, i.e., may not be used as identifiers. (What if this is not the case—as in Pl/I, which had no reserved words? Then the lexer does not distinguish between keywords and identifiers and the parser must.)
We will use the method mentioned last chapter and have the keywords installed into the identifier table prior to any invocation of the lexer. The table entry will indicate that the entry is a keyword.
installID() checks if the lexeme is already in the table. If it is not present, the lexeme is installed as an id token. In either case a pointer to the entry is returned.
gettoken() examines the lexeme and returns the token name, either id or a name corresponding to a reserved keyword.
The text also gives another method to distinguish between identifiers and keywords.
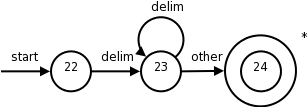
So far we have transition diagrams for identifiers (this diagram also handles keywords) and the relational operators. What remains are whitespace, and numbers, which are respectively the simplest and most complicated diagrams seen so far.
The diagram itself is quite simple reflecting the simplicity of the corresponding regular expression.
delimin the diagram represents any of the whitespace characters, say space, tab, and newline.
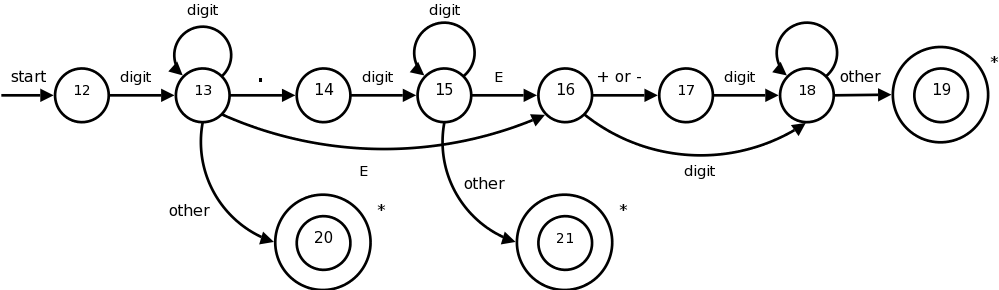
This certainly looks formidable, but it is not that bad; it follows from the regular expression.
In class go over the regular expression and show the corresponding parts in the diagram.
When an accepting states is reached, action is required but is not shown on the diagram. Just as identifiers are stored in a identifier table and a pointer is returned, there is a corresponding number table in which numbers are stored. These numbers are needed when code is generated. Depending on the source language, we may wish to indicate in the table whether this is a real or integer. A similar, but more complicated, transition diagram could be produced if the language permitted complex numbers as well.
Homework: 1 (only the ones done before).
The idea is that we write a piece of code for each decision diagram. I will show the one for relational operations below. This piece of code contains a case for each state, which typically reads a character and then goes to the next case depending on the character read. The numbers in the circles are the names of the cases.
Accepting states often need to take some action and return to the parser. Many of these accepting states (the ones with stars) need to restore one character of input. This is called retract() in the code.
What should the code for a particular diagram do if at one state the character read is not one of those for which a next state has been defined? That is, what if the character read is not the label of any of the outgoing arcs? This means that we have failed to find the token corresponding to this diagram.
The code calls fail(). This is not an error case. It simply means that the current input does not match this particular token. So we need to go to the code section for another diagram after restoring the input pointer so that we start the next diagram at the point where this failing diagram started. If we have tried all the diagram, then we have a real failure and need to print an error message and perhaps try to repair the input.
Note that the order the diagrams are tried is important. If the input matches more than one token, the first one tried will be chosen.
TOKEN getRelop() // TOKEN has two components
TOKEN retToken = new(RELOP); // First component set here
while (true)
switch(state)
case 0: c = nextChar();
if (c == '<') state = 1;
else if (c == '=') state = 5;
else if (c == '>') state = 6;
else fail();
break;
case 1: ...
...
case 8: retract(); // an accepting state with a star
retToken.attribute = GT; // second component
return(retToken);
The book gives two other methods for combining the multiple transition-diagrams (in addition to the one above).
We are skipping 3.5 because
The newer version, which we will use, is called flex, the f stands for fast. I checked and both lex and flex are on the cs machines. I will use the name lex for both.
Lex is itself a compiler that is used in the construction of other compilers (its output is the lexer for the other compiler). The lex language, i.e, the input language of the lex compiler, is described in the few sections. The compiler writer uses the lex language to specify the tokens of their language as well as the actions to take at each state.
Let us pretend I am writing a compiler for a language called pink. I produce a file, call it lex.l, that describes pink in a manner shown below. I then run the lex compiler (a normal program), giving it lex.l as input. The lex compiler output is always a file called lex.yy.c, a program written in C.
One of the procedures in lex.yy.c (call it pinkLex()) is the lexer itself, which reads a character input stream and produces a sequence of tokens. pinkLex() also sets a global value yylval that is shared with the parser. I then compile lex.yy.c together with a the parser (typically the output of lex's cousin yacc, a parser generator) to produce say pinkfront, which is an executable program that is the front end for my pink compiler.
The general form of a lex program like lex.l is
declarations
%%
translation rules
%%
auxiliary functions
The lex program for the example we have been working with follows (it is typed in straight from the book).
%{
/* definitions of manifest constants
LT, LE, EQ, NE, GT, GE,
IF, THEN, ELSE, ID, NUMBER, RELOP */
%}
/* regular definitions */
delim [ \t\n]
ws {delim}*
letter [A-Za-z]
digit [0-9]
id {letter}({letter}{digit})*
number {digit}+(\.{digit}+)?(E[+-]?{digit}+)?
%%
{ws} {/* no action and no return */}
if {return(IF);}
then {return(THEN);}
else {return(ELSE);}
{id} {yylval = (int) installID(); return(ID);}
{number} {yylval = (int) installNum(); return(NUMBER);}
"<" {yylval = LT; return(RELOP);}
"<=" {yylval = LE; return(RELOP);}
"=" {yylval = EQ; return(RELOP);}
"<>" {yylval = NE; return(RELOP);}
">" {yylval = GT; return(RELOP);}
">=" {yylval = GE; return(RELOP);}
%%
int installID() {/* function to install the lexeme, whose first
character is pointed to by yytext, and whose
length is yyleng, into the symbol table and
return a pointer thereto */
}
int installNum() {/* similar to installID, but puts numerical
constants into a separate table */
The first, declaration, section includes variables and constants as well as the all-important regular definitions that define the building blocks of the target language, i.e., the language that the generated lexer will analyze.
The next, translation rules, section gives the patterns of the lexemes that the lexer will recognize and the actions to be performed upon recognition. Normally, these actions include returning a token name to the parser and often returning other information about the token via the shared variable yylval.
If a return is not specified the lexer continues executing and finds the next lexeme present.
Anything between %{ and %} is not processed by lex, but instead is copied directly to lex.yy.c. So we could have had statements like
#define LT 12
#define LE 13
The regular definitions are mostly self explanatory. When a definition is later used it is surrounded by {}. A backslash \ is used when a special symbol like * or . is to be used to stand for itself, e.g. if we wanted to match a literal star in the input for multiplication.
Each rule is fairly clear: when a lexeme is matched by the left, pattern, part of the rule, the right, action, part is executed. Note that the value returned is the name (an integer) of the corresponding token. For simple tokens like the one named IF, which correspond to only one lexeme, no further data need be sent to the parser. There are several relational operators so a specification of which lexeme matched RELOP is saved in yylval. For id's and numbers's, the lexeme is stored in a table by the install functions and a pointer to the entry is placed in yylval for future use.
Everything in the auxiliary function section is copied directly to lex.yy.c. Unlike declarations enclosed in %{ %}, however, auxiliary functions may be used in the actions
The first rule makes = one instead of two lexemes.
The second rule makes if
a keyword and not an id.
Sorry.
Sometimes a sequence of characters is only considered a certain
lexeme if the sequence is followed by specified other sequences.
Here is a classic example.
Fortran, PL/I, and some other languages do not have reserved words.
In Fortran
IF(X)=3
is a legal assignment statement and the IF is an identifier.
However,
IF(X.LT.Y)X=Y
is an if/then statement and IF is a keyword.
Sometimes the lack of reserved words makes lexical disambiguation
impossible, however, in this case the slash / operator of lex is
sufficient to distinguish the two cases.
Consider
IF / \(.*\){letter}
This only matches IF when it is followed by a ( some text a ) and a letter. The only FORTRAN statements that match this are the if/then shown above; so we have found a lexeme that matches the if token. However, the lexeme is just the IF and not the rest of the pattern. The slash tells lex to put the rest back into the input and match it for the next and subsequent tokens.
Homework: 1(a-c), 2, 3.
The secret weapon used by lex et al to convert (compile
) its
input into a lexer.
Finite automata are like the graphs we saw in transition diagrams but they simply decide if a sentence (input string) is in the language (generated by our regular expression). That is, they are recognizers of the language.
There are two types of finite automata
executionis deterministic; hence the name.
lookaheadsymbol.
Surprising Theorem: Both DFAs and NFAs are capable of recognizing the same languages, the regular languages, i.e., the languages generated by regular expressions (plus the automata can recognize the empty language).
There are certainly NFAs that are not DFAs. But the language recognized by each such NFA can also be recognized by at least one DFA.
The DFA that recognizes the same language as an NFA might be significantly larger that the NFA.
The finite automaton that one constructs naturally from a regular expression is often an NFA.
Here is the formal definition.
A nondeterministic finite automaton (NFA) consists of
An NFA is basically a flow chart like the transition diagrams we have already seen. Indeed an NFA (or a DFA, to be formally defined soon) can be represented by a transition graph whose nodes are states and whose edges are labeled with elements of Σ ∪ ε. The differences between a transition graph and our previous transition diagrams are:
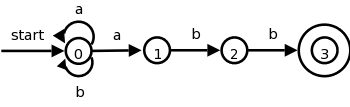
The transition graph to the right is an NFA for the regular expression (a|b)*abb, which (given the alphabet {a,b}) represents all words ending in abb.
Consider aababb.
If you choose the wrong
edge for the initial a's you will get
stuck.
But an NFA accepts a word if any path (beginning at the start
state and using the symbols in
the word in order) ends at an accepting state.
It essentially tries all such paths at once and accepts if any end at an accepting state. This means in addition that, if some paths uses all the input and end in a non-accepting state, but at least one path uses all the input (doesn't get stuck) and ends in an accepting state, the input is accepted.
Remark: Patterns like (a|b)*abb are useful regular expressions! If the alphabet is ascii, consider *.java.
Homework: 3, 4.
| State | a | b | ε |
|---|---|---|---|
| 0 | {0,1} | {0} | φ |
| 1 | φ | {2} | φ |
| 2 | φ | {3} | φ |
There is an equivalent way to represent an NFA, namely a table giving, for each state s and input symbol x (and ε), the set of successor states x leads to from s. The empty set φ is used when there is no edge labeled x emanating from s. The table on the right corresponds to the transition graph above.
The downside of these tables is their size, especially if most of the entries are φ since those entries would not take any space in a transition graph.
Homework: 5.
An NFA accepts a string if the symbols of the string specify a path from the start to an accepting state.
Again note that these symbols may specify several paths, some of which lead to accepting states and some that don't. In such a case the NFA does accept the string; one successful path is enough.
Also note that if an edge is labeled ε, then it can be
taken for free
.
For the transition graph above any string can just sit at state 0 since every possible symbol (namely a or b) can go from state 0 back to state 0. So every string can lead to a non-accepting state, but that is not important since if just one path with that string leads to an accepting state, the NFA accepts the string.
The language defined by an NFA or the language accepted by an NFA is the set of strings (a.k.a. words) accepted by the NFA.
So the NFA in the diagram above accepts the same language as the regular expression (a|b)*abb.
If A is an automaton (NFA or DFA) we use L(A) for the language accepted by A.
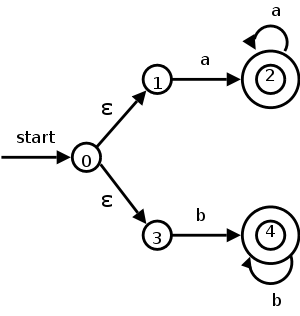
The diagram on the right illustrates an NFA accepting the language
L(aa*|bb*).
The path
0 → 3 → 4 → 4 → 4 → 4
shows that bbbb is accepted by the NFA.
Note how the ε that labels the edge 0 → 3 does not appear in the string bbbb since ε is the empty string.
There is something weird about an NFA if viewed as a model of computation. How is a computer of any realistic construction able to check out all the (possibly infinite number of) paths to determine if any terminate at an accepting state?
We now consider a much more realistic model, a DFA.
Definition: A deterministic finite automata or DFA is a special case of an NFA having the restrictions
This is realistic. We are at a state and examine the next character in the string, depending on the character we go to exactly one new state. Looks like a switch statement to me.
Minor point: when we write a transition table for a DFA, the entries are elements not sets so there are no {} present.
Indeed a DFA is so reasonable there is an obvious algorithm for simulating it (i.e., reading a string and deciding whether or not it is in the language accepted by the DFA). We present it now.
s := s0; // start state.
c := nextChar(); // a priming
read
while (c /= eof) {
s := move(s,c);
c := nextChar();
}
if (s is in F, the set of accepting states) return yes
else return no
This is not from the book.
Do not forget the goal of the chapter is to understand lexical analysis. (Languages generated by) regular expressions are the key to this task, since we use them to specify tokens. So we want to recognize (languages generated by) regular expressions. We are going to see two methods.
So we need to learn 4 techniques.
The list I just gave is in the order the algorithms would be applied—but you would use either 2 or (3 and 4).
However, we will follow the order in the book, which is exactly the reverse.
Indeed, we just did item #4 and will now do #3.
The book gives a detailed proof; I am just trying to motivate the ideas.
Let N be an NFA, we construct D, a DFA that accepts the same strings
as does N.
Call a state of N an N-state, and call a state of D a D-state.
The idea is that a D-state corresponds to a set of N-states and
hence the procedure we are describing is called the
subset algorithm.
Specifically for each string X of symbols we consider all the
N-states that can result when N processes X.
This set of N-states is a D-state.
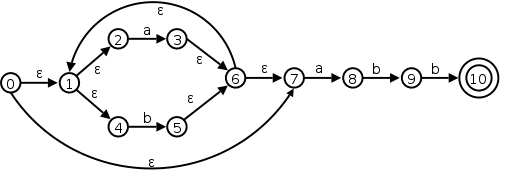
Let us consider the transition graph on the right, which is an NFA
that accepts strings satisfying the regular expression
(a|b)*abb.
The alphabet is {a,b}.
The start state of D is the set of N-states that can result when N
processes the empty string ε.
This is called the ε-closure of the start state
s0 of N, and consists of those N-states that can be
reached from s0 by following edges labeled with ε.
Specifically it is the set {0,1,2,4,7} of N-states.
We call this state D0 and enter it in the transition
table we are building for D on the right.
| NFA states | DFA state | a | b |
|---|---|---|---|
| {0,1,2,4,7} | D0 | D1 | D2 |
| {1,2,3,4,6,7,8} | D1 | D1 | D3 |
| {1,2,4,5,6,7} | D2 | D1 | D2 |
| {1,2,4,5,6,7,9} | D3 | D1 | D4 |
| {1,2,4,5,6,7,10} | D4 | D1 | D2 |
Next we want the a-successor of D0, i.e., the D-state
that occurs when we start at D0 and move along an edge
labeled a.
We call this successor D1.
Since D0 consists of the N-states corresponding to
ε, D1 is the N-states corresponding
to εa
=a
.
We compute the a-successor of all the N-states in D0 and
then form the ε-closure.
Next we compute the b-successor of D0 the same way and call it D2.
We continue forming a- and b-successors of all the D-states until no new D-states result (there are only a finite number of subsets of all the N-states so this process does indeed stop).
This gives the table on the right. D4 is the only D-accepting state as it is the only D-state containing the (only) N-accepting state 10.
Theoretically, this algorithm is awful since for a set with k elements, there are 2k subsets. Fortunately, normally only a small fraction of the possible subsets occur in practice. For example, the NFA we just did had 11 states so there are 2048 possible subsets, only 5 of which occurred in the DFA we constructed.
Homework: 1.
Instead of producing the DFA, we can run the subset algorithm as a simulation itself. This is item #2 in my list of techniques
S = ε-closure(s0);
c = nextChar();
while ( c != eof ) {
S = ε-closure(move(S,c));
c = nextChar();
}
if ( S ∩ F != φ ) return yes
; // F is accepting states
else return no
;
Homework: 2.
Slick implementation.
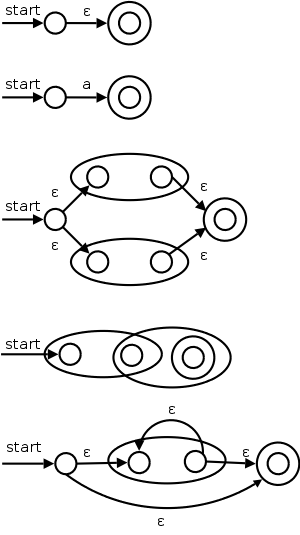
I give a pictorial proof by induction. This is item #1 from my list of techniques.
The pictures on the right illustrate the base and inductive cases.
Remarks:
Do the NFA for (a|b)*abb and see that we get the same diagram that we had before.
Do the steps in the normal leftmost, innermost order (or draw a normal parse tree and follow it).
Homework: 3 a,b,c
How lexer-generators like Lex work. Since your lab2 is to produce a lexer, this is also a section on how you should solve lab2.
We have seen simulators for DFAs and NFAs.
The remaining large question is how is the lex input converted into one of these automatons.
Also
In this section we will use transition graphs. Of course lexer-generators do not draw pictures; instead they use the equivalent transition tables.
Recall that the regular definitions in Lex are mere conveniences
that can easily be converted to REs and hence we need only convert
REs into an FSA.
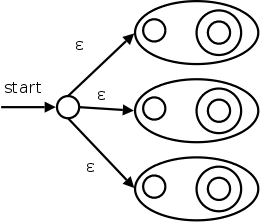
We already know how to convert a single RE into an NFA. But lex input will contain several REs (since it wishes to recognize several different tokens). The solution is to
Label each of the accepting states (for all NFAs constructed in step 1) with the actions specified in the lex program for the corresponding pattern.
We use the algorithm for simulating NFAs presented in 3.7.2.
The simulator starts reading characters and calculates the set of states it is at.
At some point the input character does not lead to any state or we have reached the eof. Since we wish to find the longest lexeme matching the pattern we proceed backwards from the current point (where there was no state) until we reach an accepting state (i.e., the set of NFA states, N-states, contains an accepting N-state). Each accepting N-state corresponds to a matched pattern. The lex rule is that if a lexeme matches multiple patterns we choose the pattern listed first in the lex-program.
| Pattern | Action to perform |
|---|---|
| a | Action1 |
| abb | Action2 |
| a*bb* | Action3 |
Consider the example on the right with three patterns and their
associated actions and consider processing the input aaba.
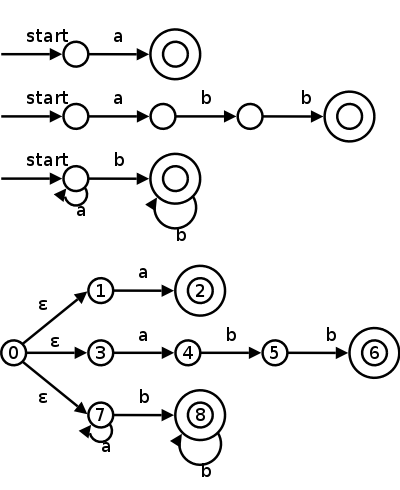
optimization.
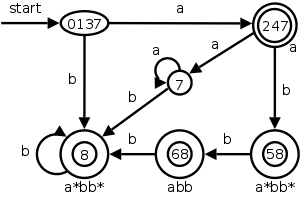
We could also convert the NFA to a DFA and simulate that. The resulting DFA is on the right. Note that it shows the same D-states (i.e., sets of N-states) we saw in the previous section, plus some other D-states that arise from inputs other than aaba.
We label the accepting states with the pattern matched. If multiple patterns are matched (because the accepting D-state contains multiple accepting N-states), we use the first pattern listed (assuming we are using lex conventions). For example, the middle D-state on the bottom row contains two accepting N-states, 6 and 8. Since the RE for 6 was listed first, it appears below the state.
Technical point. For a DFA, there must be a outgoing edge from each D-state for each possible character. In the diagram, when there is no NFA state possible, we do not show the edge. Technically we should show these edges, all of which lead to the same D-state, called the dead state, and corresponds to the empty subset of N-states.
There are trade-offs depending on how much you want to do by hand and how much you want to program. At the extreme you could write a program that reads in the regular expression for the tokens and produces a lexer, i.e., you could write a lexical-analyzer-generator. I very much advise against this, especially since the first part of the lab requires you to draw the transition diagrams anyway.
The two reasonable alternatives are.
This has some tricky points; we are basically skipping it. This lookahead operator is for when you must look further down the input but the extra characters matched are not part of the lexeme. We write the pattern r1/r2. In the NFA we match r1 then treat the / as an ε and then match s1. It would be fairly easy to describe the situation when the NFA has only one ε-transition at the state where r1 is matched. But it is tricky when there are more than one such transition.
Remark: Lab 2 assigned. It is due in 2 weeks, 9 October 2008.>