Operating Systems
Start Lecture #10
Other-Than-Regular Files
We will discuss several files that are not called regular
.
- Directories.
- Symbolic Links, which are used to
give alternate names to files.
- Special files (for devices).
Uses the naming power of files to unify many actions.
dir # prints on screen
dir > file # result put in a file
dir > /dev/cdrom1 # results written to CD-ROM
4.1.4 File Access
There are two possibilities, sequential access and random access
(a.k.a. direct access).
With sequential access, each access to a given file starts where
the previous access to that file finished (the first access to the
file starts at the beginning of the file.
Sequential access is the most common and gives the highest
performance.
For some devices (e.g. magnetic or paper tape) access must
be
sequential.
With random access, the bytes are accessed in any
order.
Thus each access must specify which bytes are desired.
This is done either by having each read/write specify the
starting location or by defining another seek operation
that specifies the starting location for the
next read/write.
If no seek occurs between two read/write
operations, then the second begins where the first finished.
That is, the second method treats read/write as sequential,
but supports seeking to achieve random access.
Previously, files were declared to be sequential or random.
Modern systems do not do this.
Instead all files are random, and optimizations are applied as the
system dynamically determines that a file is (probably) being
accessed sequentially.
4.1.5 File Attributes
A laundry list of properties that can be specified for a file
For example:
- hidden
- do not dump
- owner
- key length (for keyed files)
4.1.6 File Operations
- Create.
The effect of create is essential if a system is to add files.
However, it need not be a separate system call
(For example, it can be merged with open).
- Delete.
Essential if a system is to delete files.
- Open.
Not essential.
An optimization in which the translation from file name to disk
locations is perform only once per file rather than once per
access.
- Close.
Not essential.
Frees resources without waiting for the process to terminate.
- Read.
Essential.
Must specify filename, file location, number of bytes, and a
buffer into which the data is to be placed.
Several of these parameters can be set by other system calls and
in many operating systems they are.
- Write.
Essential if updates are to be supported.
See read for parameters.
- Seek.
Not essential (could be in read/write).
Specify the offset of the next (read or write) access to this
file.
- Get attributes.
Essential if attributes are to be used.
- Set attributes.
Essential if attributes are to be user settable.
- Rename.
Tanenbaum has strange words.
Copy and delete is not an acceptable substitute for big files.
Moreover, copy-delete is not atomic.
Indeed link-delete is not atomic so, even if link
(discussed below) is provided, renaming a
file adds functionality.
Homework: 4, 5.
4.1.7 An Example Program Using File System Calls
Homework: Read and understand copyfile
.
Note the error checks.
Specifically, the code checks the return value from each I/O system
call.
It is a common error to assume that
- Open succeeds.
It can fail due to the file not existing or inadequate
permissions.
- Read succeeds.
An end of file can occur.
Fewer than expected bytes could have been read.
Also the file descriptor could be bad, but this should have been
caught when checking the return value from open.
- Create succeeds.
It can fail when the disk (partition) is full (really when no
inodes are available—unix) or due to inadequate
permissions.
- Write succeeds.
It can fail when the disk (partition) is full or due to
inadequate permissions.
4.2 Directories
Directories form the primary unit of organization for the filesystem.
4.2.1-4.2.3 Single-Level (Two-Level) and Hierarchical Directory Systems
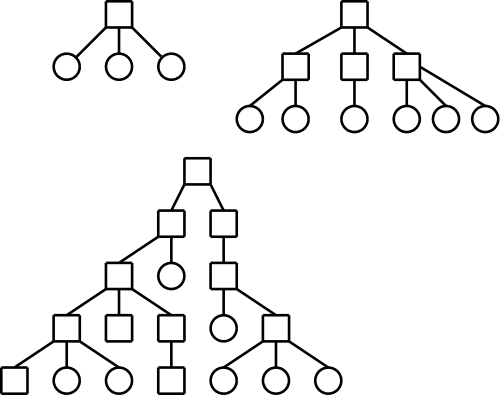
One often refers to the level structure of a directory system.
It is easy to be fooled by the names given.
A single level directory structure results in a file system tree
with two levels: the single root directory and
(all) the files in this directory.
That is there is one level of directories and another level of files
so the full tree has two levels.
Possibilities.
- One directory in the system (single-level).
This possibility is illustrated by the top left tree.
- One directory per user and a root above these (two-level).
This possibility is illustrated by the top right tree.
- One tree in the system.
This possibility is illustrated by the bottom tree.
- One tree per user with a root above.
This possibility is also illustrated by the bottom tree.
- One forest in the system.
This possibility is illustrated by viewing all three trees as
together constituting the file system forest.
- One forest per user.
This possibility is not illustrated.
To do so would require, for each user, one picture similar to
the entire picture on the right.
These possibilities are not as wildly different as they sound.
- Assume the system has only one directory, but also assume the
character
/
is allowed in a file name.
Then one could fake a tree by having a file named
/allan/gottlieb/courses/arch/class-notes.html
rather than a directory allan, a subdirectory gottlieb, ..., a
file class-notes.html.
- The Dos (windows) file system is a forest, the Unix file
system is a tree (until we learn about
links below).
In Dos, there is no common parent of a:\ and c:\, so the file
system is not a tree.
- But Windows explorer makes the dos forest look quite a bit
like a tree.
- You can get an effect similar to (but not the same as) one X
per user by having just one X in the system and having
permissions that permits each user to visit only a subset.
Of course if the system doesn't have permissions, this is not
possible.
- Today's multiuser systems have a tree per system or a forest
per system.
- Simple embedded systems often use a one-level directory
system.
4.2.4 Path Names
You can specify the location of a file in the file hierarchy by
using either an absolute or a
Relative path to the file.
- An absolute path starts at the (or
one of the
, if we have a
forest) root(s).
- A relative path starts at the current
(a.k.a working) directory.
- The special directories . and .. represent the current directory
and the parent of the current directory respectively.
Homework:
Give 8 different path names for the file /etc/passwd.
Homework: 7.
4.2.5 Directory Operations
- Create.
Produces an
empty
directory.
Normally the directory created actually contains . and .., so is not
really empty
- Delete.
Requires the directory to be empty (i.e., to just contain . and
..).
We are describing the system call.
Commands for users to execute have options that cause the command
to first empty the directory (except for . and ..) and then delete
it.
These commands make use of file and directory delete system
calls.
- Opendir.
As with the file open system call, opendir creates a
handle
for the directory that speeds future access by eliminating the
need to process the name of the directory.
- Closedir.
As with the file close system call, closedir is an optimization
that enables the system to free resources prior to process
termination.
- Readdir.
In the old days (of unix) one could read directories as files so
there was no special readdir (or opendir/closedir) system call.
It was then believed that the uniform treatment would make
programming (or at least system understanding) easier as there was
less to learn.
However, experience has taught that this was a poor idea since the
structure of directories was exposed to users.
Early unix had a simple structure (and there was only one type of
structure for all implementations).
Modern systems have more sophisticated structures and more
importantly they are not fixed across implementations.
So if programs used read() to read directories, the programs would
have to be changed whenever the structure of a directory changed.
Now we have a readdir() system call that knows the structure of
directories.
Therefore if the structure is changed only readdir() need be
changed.
- Rename.
Similar to the file rename system call.
Again note that rename is atomic; whereas, creating a new
directory moving the contents and then removing the old one is
not.
- Link.
Add another name for a file; discussed
below.
- Unlink.
Remove a directory entry.
This is how a file is deleted.
However, if there are many links and just one is unlinked, the
file remains.
Unlink is discussed in more detail below.
4.3 File System Implementation
Now that we understand how the file system looks to a user, we turn
our attention to how it is implemented.
4.3.1 File System Layout
We look at how the disks and file systems are laid out on PCs.
Much of this is required by the bios so all PC operating systems
have the same lowest level layout.
I do not know the corresponding layout for mainframe systems
or supercomputers.
A system often has more than one physical disk (3e forgot this).
The first
disk is the boot disk.
How do we determine which is the first disk?
- Easiest case: only one disk.
- Only one disk controller.
The disk with the lowest number is the boot disk.
The numbering is system dependent, for SCSI (small computer
system interconnect, now used on big computers as well) you set
switch on the drive itself (normally
jumpers
).
- Multiple disk controllers.
The controllers are ordered in a system dependent way.
The BIOS reads the first sector (smallest addressable unit of a
disk) of the boot disk into memory and transfers to control to it.
A sector contains 512 bytes.
The contents of this sector is called the MBR (master boot record).
The MBR contains two key components: the partition table and the
first-level loader.
- A disk can be logically divided into variable
size partitions, each acting as a
logical disk
.
That is, normally each partition holds a complete file system.
The partition table (like a process's page table) gives the
starting point of each partition.
It is actually more like a pure segmentation's segment table
since the objects pointed to (partitions and segments) are of
variable size so the size of each partition is also stored in
the corresponding entry of the partition table.
- One partition in the partition table is marked as the active
partition.
- The first level loader then loads 2nd-level loader, which
resides in the first sector of the
active partition and transfers control to it.
This sector is called the boot sector or boot block.
- The boot block then loads the OS (actually it can load another
loader, etc)
Contents of a Partition
The contents vary from one file system to another but there is some
commonality.
- Each partition has a boot block as mentioned above.
- Each partition must have some information saying what type of
file system is stored in this partition.
The region containing this and other administrative information is
often called the superblock.
The location of the superblock is fixed.
- The location of the root directory is either fixed, or is in the
superblock, or (as in unix i-node file systems) the root i-node
is in a fixed location.
The root i-node points to the root directory.
We will have more to say about
i-nodes below.
- Free (i.e., available) disk blocks must be maintained.
If these blocks are linked together, the head of the list (or a
pointer to it) must be in a well defined spot.
If a bitmap is used, it (or a pointer to it) must be in a well
defined place.
- Files and directories (i.e., in use disk blocks).
These are of course the reason we have the file system.
- For i-node based systems, the i-nodes are normally stored in a
separate region of the partition.
4.3.2 Implementing Files
A fundamental property of disks is that they cannot read or write
single bytes.
The smallest unit that can be read or written is called
a sector and is normally 512 bytes (plus error
correction/detection bytes).
This is a property of the hardware, not the operating system.
The operating system reads or writes disk blocks.
The size of a block is a multiple (normally a power of 2) of the
size of a sector.
Since sectors are usually (always?) 512 bytes, the block size can be
512, 1024=1K, 2K, 4K, 8K, 16K, etc.
The most common block sizes today are 4K and 8K.
So files will be composed of blocks.
When we studied memory management, we had to worry about
fragmentation, processes growing and shrinking, compaction, etc..
Many of these same considerations apply to files; the difference is
that instead of a memory region being composed of bytes, a file is
composed of blocks.
Contiguous Allocation
Recall the simplest form of memory management beyond uniprogramming
was OS/MFT where memory was divided into a very few regions and each
process was given one of these regions.
The analogue for disks would be to give each file an entire
partition.
This is too inflexible and is not used for files.
The next simplest memory management scheme was the one used in
OS/MVT, where the memory for a process was contiguous.
- The analogous scheme for files is called contiguous allocation.
- The entire file is stored as one piece.
- This scheme is simple and fast for access.
As we shall see next chapter, disks give much better performance
when accessed sequentially.
- However contiguous allocation is problematic for growing files.
- If a growing file reaches another file, the system must
move files.
- The extreme would be to compactify the disk, which entails
moving many files and the result will have trouble with any
file growing (except the last file).
- OS/MVT had the analogous problem when jobs grew.
- As with memory, there is the problem of external fragmentation.
- Contiguous allocation is no longer used for general purpose
rewritable file systems.
- It is ideal for file systems where files do not change size.
- It is used for CD-ROM file systems.
- It is used (almost) for DVD file systems.
A DVD movie is a few gigabytes in size but the 30 bit file
length field limits files to 1 gigabyte so each movie is
composed of a few contiguous files.
The reason I said
almost
is that the terminology used is
that the movie is one file stored as a sequence
of extents and only the extents are contiguous.
Homework: 10.
There is a typo: the first sentence should end at the comma.
Linked allocation
A file is an ordered sequence of blocks.
We tried to store the blocks one right after the other (contiguous)
the same way that one can store an in-memory ordered list as an
array.
The other common method for in-memory ordered lists is to link the
elements together via pointers.
This can also be done for files as follows.
- The directory entry for the file contains a pointer to the
first block of the file.
- Each file block contains a pointer to the next.
However
- This scheme gives horrible performance for random access: N
disk accesses are needed to access block N.
- Having the pointer part of the block is a nuisance.
- As a result it is not used.
Consider the following two code segments that store the same data
but in a different order.
The first is analogous to the linked list file organization above and
the second is analogous to the ms-dos FAT file system we study next.
struct node_type {
float data; float node_data[100];
int next; int node_next[100];
} node[100]
With the second arrangement the data can be stored far away from
the next pointers.
In FAT this idea is taken to an extreme: The data, which is large (a
disk block), is stored on disk; whereas, the next pointers, which are
small (each is an integer) are stored in memory in a File Allocation
Table or FAT.
(When the system is shut down the FAT is copied to disk and when the
system is booted, the FAT is copied to memory.)
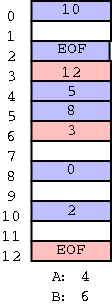
The FAT (File Allocation Table) File System
The FAT file system stores each file as a linked list of disk
blocks.
The blocks, which contain file data only (not the linked list
structure) are stored on disk.
The pointers implementing the linked list are stored in memory.
- There is a long line of FAT file systems (FAT-12, FAT-16,
vfat, ...) all of which use the file allocation table.
The following description of FAT is fairly generic and applies
to all of them.
- FAT was the file system used by dos and and early versions of
Windows.
- The NT series of Windows (NT, 2000, XP, Vista) supports FAT as
well as the superior NTFS (NT File System).
- Linux has full support for FAT (and improving support for
NTFS).
- FAT is used on flash RAMS (USB memory sticks) as well as
memory cards for digital cameras.
- The directory entry for a file points to first block (i.e.,
the directory entry specifies the block number).
- A FAT is maintained in memory having one (1-word) entry for
each disk block.
The entry for block N contains the block number of the next
block in the same file as N.
- This implements linked allocation but the links are stored
separate from the data.
- The time needed to access a random block is still is linear in
the size of the file but now all the references are to the FAT,
which is in memory.
So it is bad for random accesses, but not nearly as horrible as
plain linked allocation.
- The size of the table is one pointer per disk block.
So the ratio of the disk space supported to the memory space
needed is
(disk block size) / (size of a pointer)
If the block size is 8KB and a pointer is 2B, the memory
requirement is 1/4 megabyte for each disk gigabyte.
Large but perhaps not prohibitive.
- If the block size is 512B (the sector size of most disks) and
a pointer is 8B then the memory requirement is 16 megabytes for
each disk gigabyte, which is definitely prohibitive.
Continuing the idea of adapting storage schemes from other regimes
to file storage, why don't we mimic the idea of (non-demand) paging
and have a table giving, for each block of the file, where on the
disk that file block is stored?
In other words a ``file block table'' mapping each file block to its
corresponding disk block.
This is the idea of (the first part of) the unix i-node solution,
which we study next.
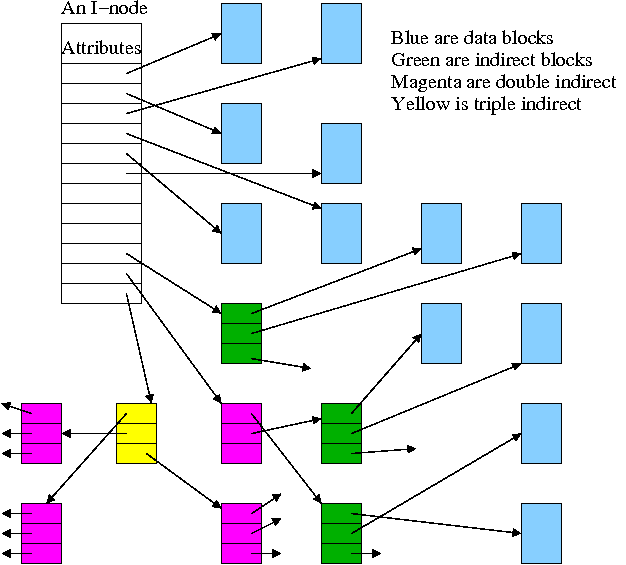
I-Nodes
Although Linux and other Unix and Unix-like operating systems have
a variety of file systems, the most widely used Unix file systems
are i-node based as was the original Unix file system from Bell Labs.
There is some question of what the i
stands for.
The consensus seems to be index.
Now, however, people often write inode (not i-node) and don't view the
i
as standing for anything.
Inode based systems have the following properties.
- The directory entry for a file points to the file's i-node.
- The i-node itself points to first few data blocks, often
called direct blocks.
(As of June 2006, the main Linux file system organization uses
twelve direct blocks.)
In the diagram on the right, all data blocks are colored
blue.
- The inode also points to an indirect block, which then points
to disk blocks.
In the diagram, the indirect blocks (also called single indirect
blocks) are colored green.
- The inode also points to a double indirect block, which points
an indirect block, which points to data blocks.
In the diagram, double indirect blocks are colored
magenta.
- For some implementations there is a triple indirect block as
well.
A triple indirect block points to double indirect blocks, which
point ... .
In the diagram, the triple indirect block is colored
yellow.
- The i-node is in memory for open files.
So references to direct blocks require just one I/O.
- For big files most references require two I/Os (indirect +
data).
- For huge files most references require three I/Os (double
indirect, indirect, and data).
- For humongous files most references require four I/Os.
- Actually, fewer I/Os are normally required due
to caching.
Retrieving a Block in an Inode-Based File System
Given a block number (byte number / block size), how do you find
the block?
Specifically assume
- The file system does not have a triple indirect block.
- We desire block number N (N=0 is the "first" block).
- There are D direct pointers in the inode.
These pointers are numbered 0..(D-1).
- There are K pointers in each indirect block.
These pointers are numbered 0..(K-1).
If N < D // This is a direct block in the i-node
use direct pointer N in the i-node
else if N < D + K // The single indirect block has a ptr to this block
use pointer D in the inode to get the indirect block
use pointer N-D in the indirect block to get block N
else // This is one of the K*K blocks obtained via the double indirect block
use pointer D+1 in the inode to get the double indirect block
let P = (N-(D+K)) DIV K // Which single indirect block to use
use pointer P to get the indirect block B
let Q = (N-(D+K)) MOD K // Which pointer in B to use
use pointer Q in B to get block N
For example, let D=12, assume all blocks are 1000B, assume
all pointers are 4B.
Retrieve the block containing byte 1,000,000.
- K = 1000/4 = 250.
- Byte 1,000,000 is in block number N=1000.
- N > D + K so we need the double indirect block.
- Follow pointer number D+1=13 in the inode to retrieve the
double indirect block.
- P=(1000-262) DIV 250 = 2.
- Follow pointer number P=2 in the double indirect block to
retrieve the needed single indirect block.
- Q=(1000-262) MOD 250 = 738 MOD 250 = 238.
- Follow pointer number 238 in the single indirect block to
retrieve the desired block (block number 1000).
With a triple indirect block, the ideas are the same, but there is
more work.
Homework: Consider an inode-based system with the
same parameters as just above, D=12, K=250, etc.
- What is the largest file that can be stored.
- How much space is used to store this largest possible file
(assume the attributes require 64B)?
- What percentage of the space used actually holds file data?
- Repeat all the above, now assuming the file system supports a
triple indirect block.
End of Problem