{kind=link}
Start Lecture #11
Remark: Lab 4 assigned.
We saw this in chapter 2.
The method in the previous section generates long strings as we walk the tree. By using SDT instead of using SDD, you can output parts of the string as each node is processed.
| Production | Semantic Rules |
|---|---|
| pd → PROC np IS ds BEG s ss END ; | ds.offset = 0 |
| np → di ( ps ) | di | not used yet |
| ds → d ds1 |
d.offset = ds.offset ds1.offset = d.newoffset |
| ds.totalSize = ds1.totalSize | |
| ds → ε | ds.totalSize = ds.offset |
| d → di : t ; |
addType(di.entry, t.type) addBaseType(di.entry, t.basetype)
addSize(di.entry, t.size)addOffset(di.entry, d.offset) d.newoffset = d.offset + t.size |
| di → id | di.entry = ID.entry |
| t → ARRAY [ NUM ] OF t1 |
t.type = array(NUM.value, t1.type)
t.basetype = t1.basetype
t.size = NUM.value * t1.size
|
| t → INT |
t.type = integer
t.basetype = integer
t.size = 4
|
| t → REAL |
t.type = real
t.basetype = real
t.size = 8
|
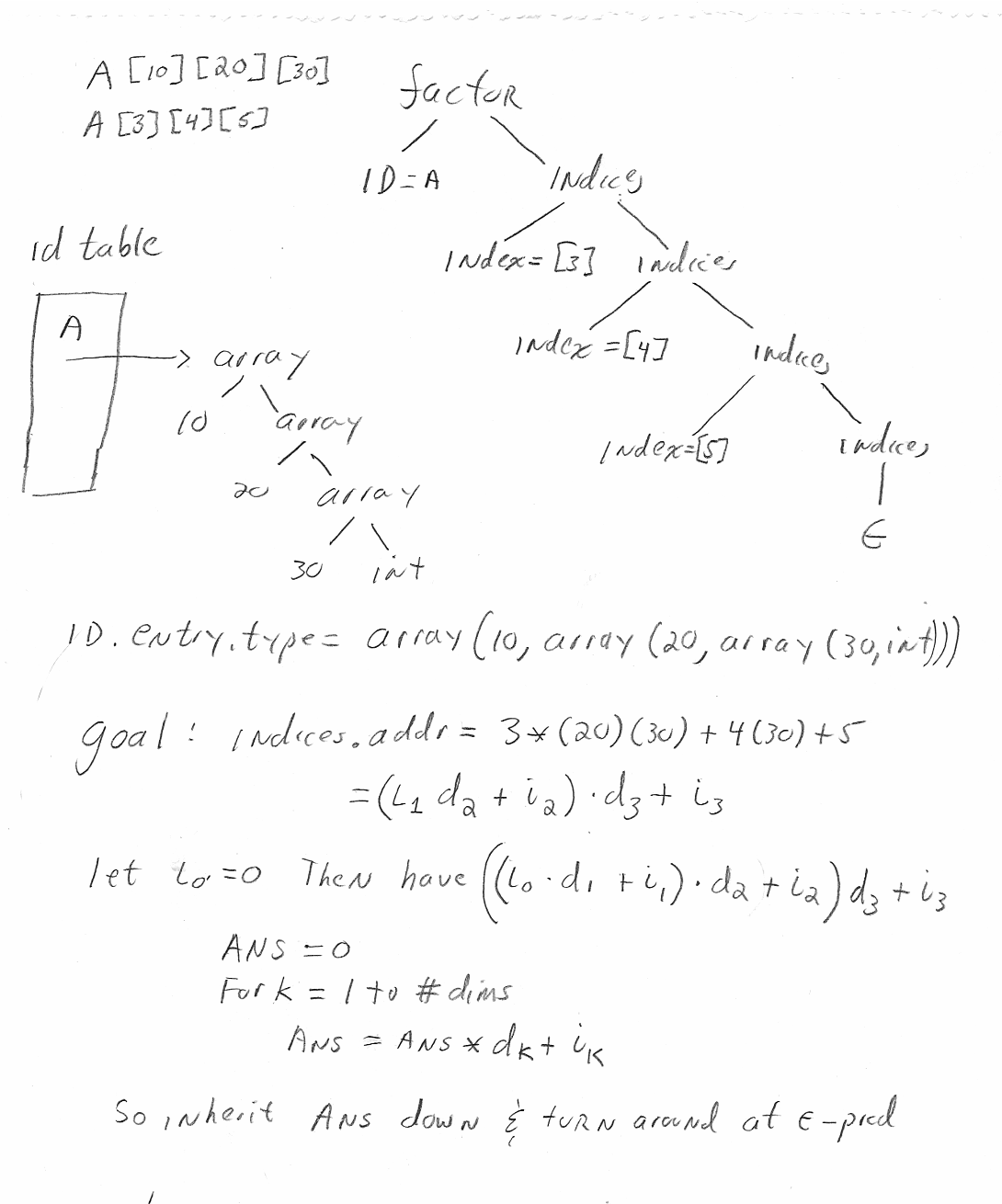
The idea is that you associate the base address with the array name. That is, the offset stored in the identifier table entry for the array is the address of the first element. When an element is referenced, the indices and the array bounds are used to compute the amount, often called the offset (unfortunately, we have already used that term), by which the address of the referenced element differs from the base address.
To implement this technique, we store the base type of each identifier in the identifier table. For example, consider
arr: array [ 10 ] of integer ;
x : real ;
Our previous SDD for declarations calculates the size and type of
each identifier.
For arr these are 40 and array(10,integer).
The enhanced SDD on the right calculates, in addition, the base
type.
For arr this is integer.
For a scalar, such as x, the base type is the same as the
type, which in the case of x is real.
The new material is shaded in blue.
Calculating the address of an element of a one dimensional array is easy. The address increment is the width of each element times the index (assuming indices start at 0). So the address of A[i] is the base address of A, which is the offset component of A's entry in the identifier table, plus i times the width of each element of A.
The width of each element is the width of what we have called the
base type.
So for an ID the element width is
sizeof(getBaseType(ID.entry)).
For convenience, we define getBaseWidth by the formula
getBaseWidth(ID.entry) = sizeof(getBaseType(ID.entry)) = sizeof(ID.entry.baseType)
Let us assume row major ordering. That is, the first element stored is A[0,0], then A[0,1], ... A[0,k-1], then A[1,0], ... . Modern languages use row major ordering.
With the alternative column major ordering, after A[0,0] comes A[1,0], A[2,0], ... .
For two dimensional arrays the address of A[i,j] is the sum of three terms
Remarks
End of Remarks
The generalization to higher dimensional arrays is clear.
Consider the following expression containing a simple array reference, where a and c are integers and b is a real array.
a = b[3*c]
We want to generate code something like
T1 = 3 * c // i.e. mult T1,3,c
T2 = T1 * 8 // each b[i] is size 8
a = b[T2] // Uses the x[i] special form
If we considered it too easy to use the that special form we would
generate something like
T1 = 3 * c
T2 = T1 * 8
T3 = &b
T4 = T2 + T3
a = *T4
| Production | Semantic Rules |
|---|---|
| i → [ e ] |
i.addr = e.addr i.code = e.code |
| f → ID i |
f.t1 = new Temp() f.addr = new Temp f.code = i.code || gen(f.t1 = i.addr * getBaseWidth(ID.entry)) || gen(f.addr = get(ID.lexeme)[f.t1]) |
| f → ID i |
f.t1 = new Temp() f.t2 = new Temp() f.t3 = new Temp() f.addr = new Temp f.code = i.code || gen(f.t1 = i.addr * getBaseWidth(ID.entry)) || gen(f.t2 = &get(ID.lexeme)) || gen(f.t3 = f.t2 + f.t1) || gen(f.addr = *f.t3) |
To include arrays we need to specify the semantic actions for the
production
factor → IDENTIFIER indices
As a warm-up, lets start with references to one-dimensional arrays.
That is we consider instead of the above production, the simpler
factor → IDENTIFIER index
The table on the right does this in two ways, both with and without using the special addressing form x[i]. I included the version without a[i] for two reasons.
Normally lisp is taught in our programming languages course, which is a prerequisite for compilers. If you no longer remember lisp, don't worry.
special formsthat are evaluated differently.
special formin that, unlike the normal rules for three-address code, we don't use the address of i but instead its value. Specifically the value of i is added to the address of a.
The rules for addresses in 3-address code also include
a = &b
a = *b
*a = b
which are other special forms. They have the same meaning as in the C programming language.
Let's carefully evaluate the simple example above
This is an exciting moment. At long last we really seem to be compiling!
As mentioned above in the general case we must process the
production
f → IDENTIFIER indices
Following the method used in the 1D case we need to produce is.addr (is stands for indices). The basic idea is shown here
Now that we can evaluate expressions (including one-dimensional
array reverences) we need to handle the left-hand side of an
assignment statement (which also can be an array reference).
Specifically we need semantic actions for the following productions
from the lab3 grammar.
id-statement → ID rest-of-assign
rest-of-assign → = expression ;
rest-of-assign → indices = expression
| Production | Semantic Rules |
|---|---|
| ids → ID ra |
ra.id = id.entry
ids.code = ra.code
|
| ra → := e ; | ra.code = e.code || gen(ra.id.lexeme=e.addr) |
| ra → i := e ; | ra.t1 = newTemp() ra.code = i.code || e.code || gen(ra.t1 = getBaseWidth(ra.id) * i.addr || gen(ra.id.lexeme[ra.t1]=e.addr) |
Once again we begin by restricting ourselves to one-dimensional arrays, which corresponds to replacing indices by index in the last production. The SDD for this restricted case is shown on the right.
The idea is the same as when a multidimensional array appears in an expression. Specifically,
Recall the program we could partially handle.
procedure test () is
y : integer;
x : array [10] of real;
begin
y = 5; // we haven't yet done statements
x[2] = y; // type error?
end;
Now we can do the statements.
What about the possible type error?
Let's take the last option.
Homework: What code is generated for the program written above?
Type Checking includes several aspects.
For any language, all type checking could be done at run time, i.e. there would be no compile-time checking. However, that does not mean the compiler is absolved from the type checking. Instead, the compiler generates code to do the checks at run time.
It is normally preferable to perform the checks at compile time, if possible. Some languages have very weak typing; for example, variables can change their type during execution. Often these languages need run-time checks. Examples include lisp, snobol, and apl.
A sound type system guarantees that all checks can be performed prior to execution. This does not mean that a given compiler will make all the necessary checks.
An implementation is strongly typed if compiled programs are guaranteed to run without type errors.
There are two forms of type checking.
We will implement type checking for expressions. Type checking statements is similar. The SDDs below (and for lab 4) contain type checking (and coercions) for assignment statements as well as expressions.
A very strict type system would do no automatic conversion. Instead it would offer functions for the programmer to explicitly convert between selected types. Then either the program has compatible types or is in error. Such explicit conversions supplied by the programmer are called casts.
We, however, will consider a more liberal approach in which the
language permits certain implicit conversions that the compiler is
to supply.
This is called type coercion.
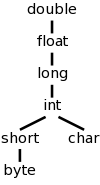
We continue to work primarily with the two basic types used in lab 3, namely integer and real, and postulate a unary function denoted (real) that converts an integer into the real having the same value. Nonetheless, we do consider the more general case where there are multiple types some of which have coercions (often called widenings). For example in C/Java, int can be widened to long, which in turn can be widened to float as shown in the figure to the right.
Mathematically the hierarchy on the right is a partially order set (poset) in which each pair of elements has a least upper bound (LUB). For many binary operators (all the arithmetic ones we are considering, but not exponentiation) the two operands are converted to the LUB. So adding a short to a char, requires both to be converted to an int. Adding a byte to a float, requires the byte to be converted to a float (the float remains a float and is not converted).
The steps for addition, subtraction, multiplication, and division are all essentially the same: Convert each types if necessary to the LUB and then perform the arithmetic on the (converted or original) values. Note that conversion often requires the generation of code.
Two functions are convenient.
LUB is simple, just look at the address latice. If one of the type arguments is not in the lattice, signal an error; otherwise find the lowest common ancestor. For our case the lattice is trivial, real is above int.
The widen function is more interesting. It involves n2 cases for n types. Many of these are error cases (e.g., if t wider than w). Below is the code for our situation with two possible types integer and real. The four cases consist of 2 nops (when t=w), one error (t=real; w=integer) and one conversion (t=integer; w=real).
widen (a:addr, t:type, w:type, newcode:string, newaddr:addr)
if t=w
newcode = ""
newaddr = a
else if t=integer and w=real
newaddr = new Temp()
newcode = gen(newaddr = (real) a)
else signal error
With these two functions it is not hard to modify the rules to catch type errors and perform coercions for arithmetic expressions.
This requires that we have type information for the base entities, identifiers and numbers. The lexer can supply the type of the numbers. We retrieve it via get(NUM.type).
It is more interesting for the identifiers. We inserted that information when we processed declarations. So we now have another semantic check: Is the identifier declared before it is used?
I will use the function get(ID.type), which returns the type from the identifier table and signals an error if it is not there. The original SDD for expressions was here and the changes for (one-dimensional) arrays was here. We extended out treatment of expressions to include assignment statements by processing the LHS here
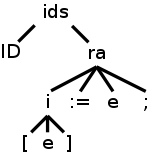
Before taking on the entire SDD, let's examine a particularly
interesting entry
identifier-statement → IDENTIFIER rest-of-assignment
and its right child
rest-of-assignment → indices := expression ;.
Consider the assignment statement
A[3/X+4] := X*5+Y;
the top of whose parse tree is shown on the right (again making the
simplification to one-dimensional arrays by replacing indices with
index).
Consider the ra node, i.e., the node corresponding to the
production.
ra → i := e ;
| Production | Semantic Rule |
|---|---|
| ids → ID ra | ra.id = ID.entry
ids.code = ra.code
|
| ra → := e ; | widen(e.addr, e.type, ra.id.basetype, ra.code1, ra.addr) ra.code = e.code || ra.code1 || gen(ra.id.lexeme=ra.addr) |
| ra → i = e ; Note: i not is | ra.t1 = newTemp() widen(e.addr, e.type, ra.id.basetype, ra.code1, ra.addr) ra.code = i.code || gen(ra.t1 = getBaseWidth(ra.id)*i.addr) || e.code || ra.code1 || gen(ra.id.lexeme[ra.t1]=ra.addr) |
| e → e1 ADDOP t | e.addr = new Temp() e.type = LUB(e1.type, t.type) widen(e1.addr, e1.type, e.type, e.code1, e.addr1) widen(t.addr, t.type, e.type, e.code2, e.addr2) e.code = e1.code || e.code1 || t.code || e.code2 || gen(e.addr = e.addr1 ADDOP.lexeme e.addr2) |
| e → t | e.addr = t.addr e.type = t.type e.code = t.code |
| t → t1 MULOP f | t.addr = new Temp() t.type = LUB(t1.type, f.type) widen(t1.addr, t1.type, t.type, t.code1, t.addr1) widen(f.addr, f.type, t.type, t.code2, t.addr2) t.code = t1.code || t.code1 || f.code || t.code2 || gen(t.addr = t.addr1 MULOP.lexeme t.addr2) |
| t → f | t.addr = f.addr t.type = f.type t.code = f.code |
| f → ( e ) | f.addr = e.addr f.type = e.type f.code = e.code |
| f → NUM | f.addr = NUM.lexeme f.type = NUM.entry.type f.code = ε |
| f → if | f.addr = if.addr f.type = if.type f.code = if.code |
| if → ID (i.e., indices=ε) | if.addr = ID.lexeme if.type = getBaseType(ID.entry) if.code = ε |
| if → ID i Note: i not is |
if.t1 = new Temp() if.addr = new Temp() if.type = getBaseType(ID.entry) if.code = i.code || gen(if.t1=i.addr*getBaseWidth(ID.entry)) || gen(if.addr=ID.lexeme[if.t1]) |
Prior to doing its calculations, the ra node invokes its children and gets back all the synthesized attributes. Alternately said, when the tree traversal gets to this node the last time, the children have returned all the synthesized attributes. To summarize, when the ra node finally performs its calculations, it has available.
What must the ra node do?
I hope the above illustration clarifies the semantic rules for
the
ra → i := e ;
production in the SDD on the right.
Because we are not considering multidimensional-arrays, the
f → ID is
production (is abbreviates indices) is replaced by the two
special cases corresponding to scalars and one-dimensional arrays,
namely:
f → ID
f → ID i
The above illustration should also help understanding the semantic rules for this last production.
Homework: Same question as the previous homework (What code is generated for the program written above?). But the answer is different!
Skipped.
Overloading is when a function or operator has several definitions depending on the types of the operands and result.
Skipped.
Skipped.
A key to the understand of control flow is the study of Boolean expressions, which themselves are used in two roles.
One question that comes up with Boolean expressions is whether both operands need be evaluated. If we are evaluating A or B and find that A is true, must we evaluate B? For example, consider evaluating
A=0 OR 3/A < 1.2
when A is zero.
This issue arises in other cases not involving Booleans at all. Consider A*F(x). If the compiler determines that A must be zero at this point, must it generate code to evaluate F(x)? Don't forget that functions can have side effects.
Consider
if bool-expr-1 OR bool-expr-2 then
then-clause
else
else-clause
end
where bool-expr-1 and bool-expr-2 are Boolean
expressions we have already generated code for.
For a simple case think of them as Boolean variables, x and
y.
When we compile the if condition bool-expr-1 OR bool-expr-2 we do not have an OR operator. Instead we just generate jumps to either the true branch or the false branch. We shall see that the above source code (with the simple bool-expr-1=x and bool-expr-2=y will generate
if x goto L2
goto L1
L1:
if y goto L2
goto l3
L2:
then-clause-code
goto L4
L3:
else-clause-code
L4
Note that the compiled code does not evaluate y if x is true. This is the sense in which it is called short-circuit code. As we have stated above, for many programming languages, it is required that we not evaluate y if x is true.