Answer: We will need to enforce
declaration before use. So, in expression evaluation, we will check the entry in the identifier table to be sure that the type has already been set.
Start Lecture #10
A triple optimizes
a quad by eliminating the result field of
a quad since the result is often a temporary.
When this result occurs as a source operand of a subsequent instruction, the source operand is written as the value-number of the instruction yielding this result (distinguished some way, say with parens).
If the result field of a quad is a program name and not a temporary then two triples may be needed:
When an optimizing compiler reorders instructions for increased performance, extra work is needed with triples since the instruction numbers, which have changed, are used implicitly. Hence the triples must be regenerated with correct numbers as operands.
With Indirect triples we maintain an array of pointers to triples and, if it is necessary to reorder instructions, just reorder these pointers. This has two advantages.
Homework: 1, 2 (you may use the parse tree instead of the syntax tree if you prefer).
This has become a big deal in modern optimizers, but we will
largely ignore it.
The idea is that you have all assignments go to unique (temporary)
variables.
So if the code is
if x then y=4 else y=5
it is treated as though it was
if x then y1=4 else y2=5
The interesting part comes when y is used later in the program and
the compiler must choose between y1 and y2.
Much of the early part of this section is really about programming languages more than about compilers.
A type expression is either a basic type or the result of applying a type constructor.
There are two camps, name equivalence and structural equivalence.
Consider the following example.
declare
type MyInteger is new Integer;
MyX : MyInteger;
x : Integer := 0;
begin
MyX := x;
end
This generates a type error in Ada, which has name equivalence since
the types of x and MyX do not have the same name, although they have
the same structure.
As another example, consider an object of an anonymous
type
as in
X : array [5] of integer;
X does not have the same type as any other object not even Y
declared as
y : array [5] of integer;
However, x[2] has the same type as y[3]; both are integers.
The following example from the 2ed uses C/Java array notation. (The 1ed had pascal-like notation.) Although I prefer Ada-like constructs as in lab 3, I realize that the class knows C/Java best so like the authors I will sometimes follow the 2ed as well as presenting lab3-like grammars.
The grammar below gives C/Java like records/structs/methodless-classes as well as multidimensional arrays (really singly dimensioned arrays of singly dimensioned arrays).
D → T id ; D | ε
T → B C | RECORD { D }
B → INT | FLOAT
C → [ NUM ] C | ε
The lab 3 grammar doesn't support records. Here is the part of the lab3 grammar that handles declarations of ints, reals, arrays, and user-defined types (the last is incomplete).
declarations → declaration declarations | ε
declaration → defining-identifier : type ; |
TYPE defining-identifier IS type ;
defining-identifier → IDENTIFIER
type → INT | REAL | ARRAY [ NUMBER ] OF type
So that the tables below are not too wide, let's use shorter names
for the nonterminals.
Also, for now we ignore the second possibility for declaration
(declaring a type itself).
Indeed as given it is fairly useless since we cannot then declare a
object of this new type.
ds → d ds | ε
d → di : t ;
di → ID
t → INT | REAL | ARRAY [ NUMBER ] OF t
My intention was to support user-declared types. For example
type vector5 is array [5] of real;
v5 : vector5;
As given in the lab3 grammar the first statement is supported the
second is not.
To support the second we would add
ds → d ds | ε
d → di : t ; | TYPE di IS t ;
di → ID
t → INT | REAL | ARRAY [ NUMBER ] OF t | ID
Ada supports both constrained array types such as
type t1 is array [5] of integer;
and unconstrained array types such as
type t2 is array of integer;
With the latter, the constraint is specified when the array (object)
itself is declared.
x1 : t1
x2 : t2[5]
You might wonder why we want the unconstrained type. These types permit a procedure to have a parameter that is an array of integers of unspecified size. Remember that the declaration of a procedure specifies only the type of the parameter; the object is determined at the time of the procedure call.
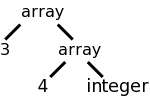
Previously we considered an SDD for
arrays that was able to compute the type.
The key point was that it called the function array(size,type) so as
to produce a tree structure exhibiting the dimensionality of the
array.
For example the tree on the right would be produced for
int[3][4]
or array [3] of array [4] of int.
Now we will extend the SDD to calculate the size of the array as well. For example, the array pictured has size 48, assuming that each int has size 4. When we declare a list of objects, we need to know the size of each in order to determine the offset of each object from the start of the list.
We are considering here only those types for which the storage requirements can be computed at compile time. For others, e.g., string variables, dynamic arrays, etc, we would only be reserving space for a pointer to the structure; the structure itself would be created at run time. Such structures are discussed in the next chapter.
The idea (for arrays whose size can be determined at compile time)
is that the basic type determines the width of the object, and the
number of elements in the array determines the height
.
These are then multiplied to get the size (area) of the object.
The terminology actually used is that the basetype determines the
basewidth, which when multiplied by the number of elements gives the
width.
| Production | Actions | Semantic Rules |
|---|---|---|
| T → B | { t = B.type } | C.bt = B.bt |
| { w = B.width } | C.bw = B.bw | |
| C | { T.type = C.type } | T.type = C.type |
| { T.width = B.width; } | T.width = C.width | |
| B → INT | { B.type = integer; B.width = 4; } | B.bt = integer B.bw = 4 |
| B → FLOAT | { B.type = float; B.width = 8; } | B.bt = float B.bw = 8 |
| C → [ NUM ] C1 | C.type = array(NUM.value, C1.type) | |
| C.width = NUM.value * C1.width; | ||
| { C.type = array(NUM.value, C1.type); | C1.bt = C.bt | |
| C.width = NUM.value * C1.width; } | C1.bw = C.bw | |
| C → ε | { C.type = t; C.width=w } | C.type = C.bt C.width = C.bw |
The book uses semantic actions (i.e., a syntax directed translation SDT). I added the corresponding semantic rules so that we have an SDD as well. in both case cases we just show a single declaration (i.e., the start symbol is T not D).
The goal of the SDD is to calculate two attributes of the start symbol T, namely T.type and T.width, the rest of the rules can be viewed as the implementation.
Remember that for an SDT, the placement of the actions within the production is important. Since it aids reading to have the actions lined up in a column, we sometimes write the production itself on multiple lines. For example the production T→BC in the table below has the B and C on separate lines so that (the first two) actions can be in between even though they are written to the right. These two actions are performed after the B child has been traversed, but before the C child has been traversed. The final two actions are at the very end so are done after both children have been traversed.
The actions use global variables t and w to carry the base type (INT or FLOAT) and width down to the ε-production, where they are then sent on their way up and become multiplied by the various dimensions. In the rules I use inherited attributes bt and bw for the same purpose. This is similar to the comment above that instead of having the identifier table passed up and down via attributes, the bullet can be bitten and a globally visible table used instead.
The base types and base widths are set by the lexer or, as shown in the table, are constants in the parser. NUM.value is set by the lexer.
| Production | Semantic Rules (All Attributes Synthesized) |
|---|---|
| d → di : t ; | addType(di.entry, t.type); addSize(di.entry, t.size) |
| di → ID | di.entry = ID.entry |
| t → ARRAY [ NUM ] OF t1 ; | t.type = array(NUM.value, t1.type) t.size = NUM.value * t1.size |
| t → INT | t.type = integer t.size = 4 |
| t → REAL | t.type = real t.size = 8 |
This is easier with the lab3 grammar since there are no inherited attributes. We again assume that the lexer has defined NUM.value (it is likely a field in the numbers table entry for the token NUM). The goal is to augment the identifier table entry for ID to include the type and size information found in the declaration. This can be written two ways.
Recall that addType is viewed as a synthesized since its parameters come from the RHS, i.e., from children of this node. It has a side effect (of modifying the identifier table) so we must be sure that we are using this table value before it is calculated. Later, when we evaluate expressions, we will need to look up the types of objects.
How can we ensure that the type has already been determined and
saved?
Answer: We will need to enforce declaration before use
.
So, in expression evaluation, we will check the entry in the
identifier table to be sure that the type has already been set.
Remark
Our lab3 grammar also has type
declarations; that is, you can declare that an identifier is a type
and can then declare objects of that type.
Actually, the lab3 grammar was supposed to support such
declarations.
The lab3 grammar does permit us to declare that an identifier is a
type but does not permit us to declare objects of
that type.
To do so would require adding the production
type → identifier
End of Remark
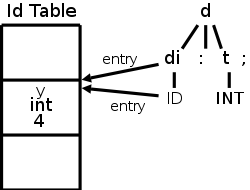
On the board, construct the parse tree, starting from the declaration
for
y : int ;
We should get the diagram at the upper right, which also shows the
effects of the semantic rules.
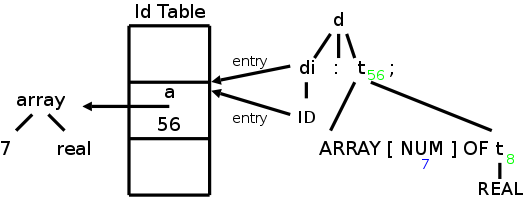
Now do the same for the array declaration
a : array [7] of int ;
The result is again shown on the right.
The green numbers show the value of t.size and the blue number shows
the value of NUM.value.
Finally consider the following program
Procedure P1 is
y : int;
a : array [7] of real;
begin
end;
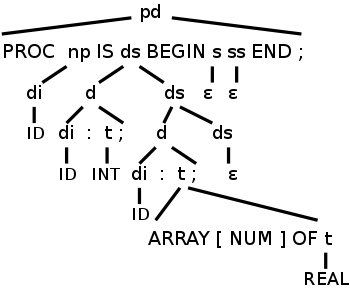 It is in fact illegal since the lab3 grammar requires a statement
between begin and end, but let's pretend that we have the additional
production
It is in fact illegal since the lab3 grammar requires a statement
between begin and end, but let's pretend that we have the additional
productionBe careful to distinguish between three methods used to store and pass information.
To summarize, the identifier table (and others we have used) are not present when the program is run. But there must be run time storage for objects. We need to know the address each object will have during execution. Specifically, we need to know its offset from the start of the area used for object storage.
For just one object, it is trivial: the offset is zero. For many objects we need to keep a running sum of the sizes of the preceding objects, which is our next objective.
The goal is to permit multiple declarations in the same procedure (or program or function). For C/java like languages this can occur in two ways.
In either case we need to associate with each object being declared the location in which it will be stored at run time. Specifically we include in the table entry for the object, its offset from the beginning of the current procedure. We initialize this offset at the beginning of the procedure and increment it after each object declaration.
The lab3 grammar does not support multiple objects in a single declaration.
C/Java does permit multiple objects in a single declaration, but surprisingly the 2e grammar does not.
Naturally, the way to permit multiple declarations is to have a
list of declarations in the natural right-recursive way.
The 2e C/Java grammar has D which is a list of semicolon-separated
T ID's
D → T ID ; D | ε
The lab 3 grammar has a list of declarations
(each of which ends in a semicolon).
Shortening declarations to ds we have
ds → d ds | ε
| Production | Semantic Action |
|---|---|
| P → | { offset = 0; } |
| D | |
| D → T ID ; | { top.put(id.lexeme, T.type, offset); |
| offset = offset + T. width; } | |
| D1 | |
| D → ε |
As mentioned, we need to maintain an offset, the next storage location to be used by an object declaration. The 2e snippet on the right introduces a nonterminal P for program that gives a convenient place to initialize offset.
The name top is used to signify that we work with the top symbol table (when we have nested scopes for record definitions, nested procedures, or nested blocks we need a stack of symbol tables). Top.put places the identifier into this table with its type and storage location and then bumps offset for the next variable or next declaration.
Rather than figure out how to put this snippet together with the previous 2e code that handled arrays, we will just present the snippets and put everything together on the lab 3 grammar.
| Production | Semantic Rules |
|---|---|
| pd → PROC np IS ds BEG s ss END ; | ds.offset = 0 |
| np → di ( ps ) | di | not used yet |
| ds → d ds1 |
d.offset = ds.offset ds1.offset = d.newoffset |
| ds.totalSize = ds1.totalSize | |
| ds → ε | ds.totalSize = ds.offset |
| d → di : t ; | addType(di.entry, t.type) addSize(di.entry, t.size) addOffset(di.entry, d.offset) d.newoffset = d.offset + t.size |
| t → ARRAY [ NUM ] OF t1 |
t.type = array(NUM.value, t1.type) t.size = NUM.value * t1.size |
| t → INT |
t.type = integer t.size = 4 |
| t → REAL |
t.type = real t.size = 8 |
In the procedure-def (pd) production of the lab3 grammar we give
the nonterminal declarations
(ds) the inherited attribute
offset (ds.offset), which we initialize to zero.
We inherit this offset down to individual declarations. At each declaration, we store the offset in the entry for the identifier being declared and increment the offset by the size of this object. When we get the to the end of the declarations (the ε-production), the offset value is the total size needed. We turn it around and send it back up the tree in case the total is needed by some higher level production.
Now show what happens when the following program is parsed and the semantic rules above are applied.
procedure P2 is
y : integer;
a : array [7] of real;
begin
y := 5; // not yet done
a[2] := y; // type error?
end;
Since records can essentially have a bunch of declarations inside,
we only need add
T → RECORD { D }
to get the syntax right.
For the semantics we need to push the environment and offset onto
stacks since the namespace inside a record is distinct from that on
the outside.
The width of the record itself is the final value of (the inner)
offset.
T → record { { Env.push(top); top = new Env()
Stack.puch(offset); offset = 0; }
D } { T.type = record(top); T.width = offset;
top = Env.pop(); offset = Stack.pop(); }
This does not apply directly to the lab 3 grammar since the grammar does not have records.
This same technique would be used for other examples of nested scope, e.g., nested procedures/functions and nested blocks. To have nested procedures/functions, we need other alternatives for declaration: procedure/function definitions. Similarly if we wanted to have nested blocks we would add another alternative to statement.
s → ks | is | block-stmt
block-stmt → DECLARE ds BEGIN ss END ;
If we wanted to generate code for nested procedures or nested blocks, we would need to stack the symbol table as done above and in the text.
Homework: 1.