Start Lecture #12
Remark: Lab 4 assigned.
Type Checking includes several aspects.
All type checking could be done at run time: The compiler generates code to do the checks. Some languages have very weak typing; for example, variables can change their type during execution. Often these languages need run-time checks. Examples include lisp, snobol, apl.
A sound type system guarantees that all checks can be performed prior to execution. This does not mean that a given compiler will make all the necessary checks.
An implementation is strongly typed if compiled programs are guaranteed to run without type errors.
There are two forms of type checking.
We consider type checking for expessions. Checking statements is very similar. View the statement as a function having its components as arguments and returning void. The SDDs below (and for lab 4) contain type checking (and coercions) for assignment statements.
A very strict type system would do no automatic conversion. Instead it would offer functions for the programer to explicitly convert between selected types. Then either the program has compatible types or is in error.
However, we will consider a more liberal approach in which the
language permits certain implicit conversions that the compiler is
to supply.
This is called type coercion.
Explicit conversions supplied by the programmer are
called casts.
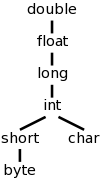
We continue to work primarily with the two basic types used in lab 3, namely integer and real, and postulate a unary function denoted (real) that converts an integer into the real having the same value. Nonetheless, we do consider the more general case where there are multiple types some of which have coercions (often called widening). For example in C/Java, int can be widened to long, which in turn can be widened to float as shown in the figure to the right.
Mathematically the hierarchy on the right is a partially order set (poset) in which each pair of elements has a least upper bound (LUB). For many binary operators (all the arithmetic ones we are considering, but not exponentiation) the two operands are converted to the LUB. So adding a short to a char, requires both to be converted to an int. Adding a byte to a float, requires the byte to be converted to a float (the float remains a float and is not converted).
The steps for addition, subtraction, multiplication, and division are all essentially the same: Convert each types if necessary to the LUB and then perform the arithmetic on the (converted or original) values. Note that conversion often requires the generation of code.
Two functions are convenient.
LUB is simple, just look at the address latice. If one of the type arguments is not in the lattice, signal an error; otherwise find the lowest common ancestor.
widen is more interesting. It involves n2 cases for n types. Many of these are error cases (e.g., if t wider than w). Below is the code for our situation with two possible types integer and real. The four cases consist of 2 nops (when t=w), one error (t=real; w=integer) and one conversion (t=integer; w=real).
widen (a:addr, t:type, w:type, newcode:string, newaddr:addr)
if t=w
newcode = ""
newaddr = a
else if t=integer and w=real
newaddr = new Temp()
newcode = gen(newaddr = (real) a)
else signal error
With these two functions it is not hard to modify the rules to catch type errors and perform coercions for arithmetic expressions.
This requires that we have type information for the base entities, identifiers and numbers. The lexer can supply the type of the numbers. We retrieve it via get(NUM.type).
It is more interesting for the identifiers. We insert that information when we process declarations. So we now have another semantic check: Is the identifier declared before it is used?
I will use the function get(ID.type), which returns the type from the identifier table and signals an error if it is not there. The original SDD for assignment statements was here and the changes for arrays was here.
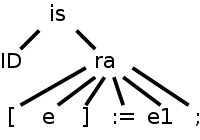
Before taking on the entire SDD, let's examine a particularly interesting entry. Consider the assignment statement
A[3/X+4] := X*5+Y;
whose parse tree is shown on the right.
Consider the ra node, i.e., the node corresponding to the production.
ra → [ e ] := e1 ;
When the tree traversal gets to this node, its parent has passed in
the value of the inherited attribute ra.id=id.entry.
Thus the ra node has access to the identifier table entry for ID,
which in our example is the variable A.
Prior to doing its calculations, the ra node invokes its children and gets back all the synthesized attributes. To summarize, when the ra node performs its calculations, it has available.
What must the ra node do?
I hope this clarifies the semantic rules for this production.
Remark: In preparing this explanation, I fixed errors in the table below and also in the corresponding entry of the last table of section 6.4, which we did last time.
| Production | Semantic Rule |
|---|---|
| ids → ID ra | ra.id = ID.entry
ids.code = ra.code
|
| ra → = e ; | widen(e.addr, e.type, ra.id.basetype, ra.code1, ra.addr) ra.code = e.code || ra.code1 || gen(ra.id.lexeme)=ra.addr) |
| ra → [ e ] = e1 ; | ra.t1 = newTemp() widen(e1.addr, e1.type, ra.id.basetype, ra.code1, ra.addr) ra.code = e.code || gen(ra.t1 = getBaseWidth(ra.id) * e.addr ) || e1.code || ra.code1 || gen(ra.id.lexeme[ra.t1] = ra.addr) |
| e → e1 + t | e.addr = new Temp() e.type = LUB(e1.type, t.type) widen(e1.addr, e1.type, e.type, e.code1, e.addr1) widen(t.addr, t.type, e.type, e.code2, e.addr2) e.code = e1.code || t.code || e.code1 || e.code2 || gen(e.addr = e.addr1 + e.addr2) |
| e → e1 - t | e.addr = new Temp() e.type = LUB(e1.type, t.type) widen(e1.addr, e1.type, e.type, e.code1, e.addr1) widen(t.addr, t.type, e.type, e.code2, e.addr2) e.code = e1.code || t.code || e.code1 || e.code2 || gen(e.addr = e.addr1 - e.addr2) |
| e → t | e.addr = t.addr e.type = t.type e.code = t.code |
| t → t1 * f | t.addr = new Temp() t.type = LUB(t1.type, f.type) widen(t1.addr, t1.type, t.type, t.code1, t.addr1) widen(f.addr, f.type, t.type, t.code2, t.addr2) t.code = t1.code || f.code || t.code1 || t.code2 || gen(t.addr = t.addr1 * t.addr2) |
| t → t1 / f | t.addr = new Temp() t.type = LUB(t1.type, f.type) widen(t1.addr, t1.type, t.type, t.code1, t.addr1) widen(f.addr, f.type, t.type, t.code2, t.addr2) t.code = t1.code || f.code || t.code1 || t.code2 || gen(t.addr = t.addr1 / t.addr2) |
| t → f | t.addr = f.addr t.type = f.type t.code = f.code |
| f → ( e ) | f.addr = e.addr f.type = e.type f.code = e.code |
| f → NUM | f.addr = get(NUM.lexeme) f.type = get(NUM.type) f.code = ε |
| f → if | f.addr = if.addr f.type = if.type f.code = if.code |
| if → ID | if.addr = ID.lexeme if.type = getBaseType(ID.type) if.code = ε |
| if → ID [ e ] Note: e not es |
if.t1 = new Temp() if.addr = new Temp() if.type = getBaseType(ID.type) if.code = e.code || gen(if.t1=e.addr*getBaseWidth(ID.entry)) || gen(if.addr=ID.lexeme[if.t1]) |
Homework: Same question as the previous homework (What code is generated for the program written above?). But the answer is different!
Skipped.
Overloading is when a function or operator has several definitions depending on the types of the operands and result.
Skipped.
Skipped.
Control flow includes the study of Boolean expressions, which have two roles.
One question that comes up with Boolean expressions is whether both
operands need be evaluated.
If we are evaluating A or B
and find that A is true, must we
evaluate B?
For example, consider evaluating
A=0 OR 3/A < 1.2
when A is zero.
This issue arises in other cases as well. Consider A*F(x). If the compiler knows that for this run A is zero, must it generate code to evaluate F(x)? Don't forget that functions can have side effects,
This is also called jumping code. Here the Boolean operators AND, OR, and NOT do not appear in the generated instruction stream. Instead we just generate jumps to either the true branch or the false branch.
The lab3 grammar has the following productions concerning
flow of control statements.
I added a start
production which will be used to initiate a
series of *.next inherited attributes.
start → program
program → function-def program | procedure-def program | ε
procedure-def → PROCEDURE name-and-parameters IS declarations BEGIN statement statements END ;
statements → statement statements | ε
statement → keyword-statement | identifier-statement
keyword-statement → return-statement | while-statement | if-statement
if-statement → IF condition THEN statements optional-else END ;
optional-else → ELSE statements | ε
while-statement → WHILE condition DO statements END ;
I do not include the production for function-def since, for control
flow, it is the same as procedure-def.
I don't show the productions for name-and-parameters, declarations,
identifier-statement, and return-statement since they do not have
conditional control flow (return just generates a goto, but doesn't
use any of the techniques in this section).
The production for condition will be done in the next section.
To make the tables fit we abbreviate the names of the nonterminals appearing in the grammar above to pg, fd, pd, np, ds, ss, s, ks, is, rs, ws, is, c, and oe.
In this section we will produce an SDD for these productions under the assumption that the SDD for condition generates jumps to the labels c.true and c.false (depending of course on whether the condition c is true or false).
In the lab3 grammar, a condition is simply two expressions separated by a relational operator e RELOP e1. In the next section we give the SDD for a more general nonterminal boolean-expression, for which the lab3 condition is a special case.
The grammar for boolean-expression given in the next section is not LL(1). Since the lab3 grammar does not have general Boolean expressions, I did not massage the grammar to make it LL(1).
I don't know why the sections aren't in the reverse order and I came close to reversing the order of presentation.
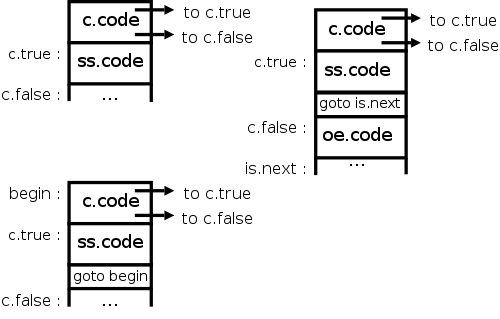
The diagrams on the right give the idea for the three basic control
flow statements, if-then (not in the lab3 grammar), if-then-else,
and while-do.
The table below gives the details for the latter two via an SDD.
| Production | Semantic Rules |
|---|---|
| start → pg | pg.next = newLabel()
start.code = pg.code || label(pg.next)
|
| pg → pd pg1 | pd.next = newLabel()
pg1.next = pg.next
pg.code = pd.code || label(pd.next) || pg1.code
|
| pg → ε | pg.code = "" |
| pd → PROC np IS ds BEGIN s ss END ; | s.next = newLabel()
ss.next = pd.next
pd.code = s.code || label(s.next) || ss.code
|
| ss → s ss1 | s.next = newLabel()
ss1.next = ss.next
ss.code = s.code || label(s.next) || ss1.code
|
| ss → ε | ss.code = "" |
| s → ks | ks.next = s.next
s.code = ks.code
|
| ks → is | is.next = ks.next
ks.code = is.code
|
| is → IF c THEN ss oe END ; | c.true = newLabel()
c.false = newLabel()
ss.next = is.next
oe.next = is.next
is.code = c.code || label(c.true) || ss.code || gen(goto is.next) || label(c.false) || oe.code
|
| oe → ELSE ss | ss.next = oe.next
oe.code = ss.code
|
| oe → ε | oe.code = "" |
| ks → ws | ws.next = ks.next
ks.code = ws.code
|
| ws → WHILE c DO ss END ; | begin = newLabel() c.true = newLabel()
c.false = ws.next
ss.next = begin
ws.code = label(begin) || c.code || label(c.true) || ss.code
|| gen(goto begin)
|
The treatment of the various *.next attributes deserves some comment. Each statement is given, as an inherited attribute, a label *.next which the parent normally places after the code for the child. The child and/or the parent can generate code that performs a goto this label. An alternative would be for the child to itself generate the label and place it as the last component of its code. I believe this alternative would make for a clearer SDD; however, the method chosen does have two advantages.
Homework: Give the SDD for a repeat statement
REPEAT ss WHILE c END ;
| Production | Semantic Rules |
|---|---|
| BE → BE1 || BT | BE1.true = BE.true |
| BE1.false = newlabel() | |
| BT.true = BE.true | |
| BT.false = BE.false | |
| BE.code = BE1.code || label(BE1.false) || BT.code | |
| BE → BT | BT.true = B.true |
| BT.false = B.false | |
| BE.code = BT.code | |
| BT → BT1 && BF | BT1.true = newlabel() |
| BT1.false = BT.false | |
| BF.true = BT.true | |
| BF.false = BT.false | |
| BT.code = BT1.code || label(BT1.true) || BF.code | |
| BT → BF | BF.true = BT.true |
| BF.false = BT.false | |
| BT.code = BF.code | |
| BF → ! BF1 | BF1.true = BF.false |
| BF1.false = BF.true | |
| B.code = BF1.code | |
| BF → true | BF.code = gen(goto BF.true) |
| BF → false | BF.code = gen(goto BF.false) |
| BF → ID | BF.code = gen(if get(ID.lexeme) goto BF.true)
|| gen(goto BF.false) |
| BF → E relop E1 | BF.code = E.code || E1.code
|| gen(if E.addr relop.lexeme E1.addr goto BF.true) || gen(goto B.false) |
Do on the board the translation of
if ( x < 5 || x > 10 && x == y ) x = 3 ;
We get
if x < 5 goto L2
goto L3
L3: if x > 10 goto L4
goto L1
L4: if x == y goto L2
goto L1
L2: x = 3
Note that there are three extra gotos. One is a goto the next statement. Two others could be eliminated by using ifFalse.
Skipped.
If there are boolean variables (or variables into which a boolean value can be placed), we can have boolean assignment statements. That is we might evaluate boolean expressions outside of control flow statements.
Recall that the code we generated for boolean expressions (inside control flow statements) used inherited attributes to push down the tree the exit labels B.true and B.false. How are we to deal with Boolean assignment statements?
Up to now we have used the so called jumping code
method for
Boolean quantities.
We evaluated Boolean expressions (in the context of control flow
statements) by using inherited attributes to push down the tree the
true and false exits (i.e., the target locations to jump to if the
expression evaluates to true and false).
With this method if we have a Boolean assignment statement, we just let the true and false exits lead respectively to statements
LHS = true
LHS = false
In the second method we simply treat boolean expressions as
expressions.
That is, we just mimic the actions we did for integer/real
evaluations.
Thus Boolean assignment statements like
a = b OR (c AND d AND (x < y))
just work.
For control flow statements like
while boolean-expression do statement-list end ;
if boolean-expression then statement-list else statement-list end ;
we simply evaluate the boolean expression as if it was part of an
assignment statement and then have two jumps to where we should go
if the result is true or false.
However, as mentioned before, this is wrong.
In C and other languages if (a=0 || 1/a > f(a)) is guaranteed not
to divide by zero and the above implementation fails to provide this
guarantee.
We must implement short-circuit boolean evaluation.