Start Lecture #7
Remark: Lab3 assigned.
I really believe this is very clear, but I understand that the formalism makes it seem confusing. Let me begin with the idea.
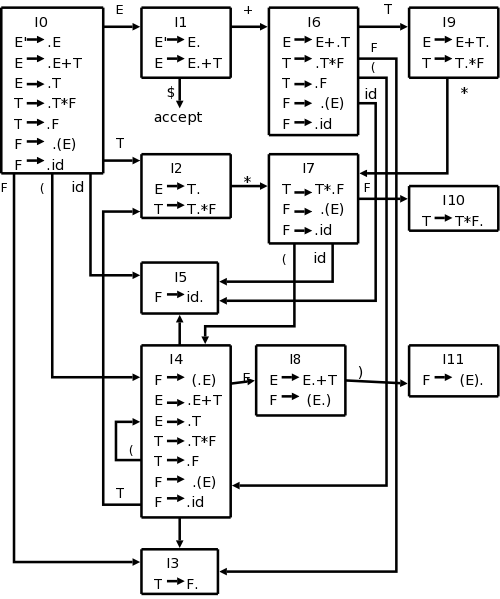
We augment the grammar and get this one new production; take its closure. That is the first element of the collection; call it Z (we will actually call it I0). Try GOTOing from Z, i.e., for each grammar symbol, consider GOTO(Z,X); each of these (almost) is another element of the collection. Now try GOTOing from each of these new elements of the collection, etc. Start with jane smith, add all her friends F, then add the friends of everyone in F, called FF, then add all the friends of everyone in FF, etc
The (almost)
is because GOTO(Z,X) could be empty so formally
we construct the canonical collection of LR(0) items, C, as follows
This GOTO gives exactly the arcs in the DFA I constructed earlier. The formal treatment does not include the NFA, but works with the DFA from the beginning.
Homework:
Our main example
E' → E
E → E + T | T
T → T * F | F
F → ( E ) | id
is larger than the toy I did before.
The NFA would have 2+4+2+4+2+4+2=20 states (a production with k
symbols on the RHS gives k+1 N-states since there k+1 places to
place the dot).
This gives rise to 12 D-states.
However, the development in the book, which we are following now,
constructs the DFA directly.
The resulting diagram is on the right.
Start constructing the diagram on the board:
Begin with {E' → ·E},
take the closure, and then keep applying GOTO.
The LR-parsing algorithm must decide when to shift and when to reduce (and in the latter case, by which production). It does this by consulting two tables, ACTION and GOTO. The basic algorithm is the same for all LR parsers, what changes are the tables ACTION and GOTO.
We have already seen GOTO (for SLR).
Technical point that may, and probably should, be ignored: our GOTO was defined on pairs [item-set,grammar-symbol]. The new GOTO is defined on pairs [state,nonterminal]. A state (except the initial state) is an item set together with the grammar symbol that was used to generate it (via the old GOTO). We will not use the new GOTO on terminals so we just define it on nonterminals.
Given a state i and a terminal a (or the endmarker), ACTION[i,a] can be
So ACTION is the key to deciding shift vs. reduce. We will soon see how this table is computed for SLR.
Since ACTION is defined on [state,terminal] pairs and GOTO is defined on [state,nonterminal], we can combine these tables into one defined on [state,grammar-symbol] pairs.
This formalism is useful for stating the actions of the parser precisely, but I believe the parser can be explained without this formalism. The essential idea of the formalism is that the entire state of the parser can be represented by the vector of states on the stack and input symbols not yet processed.
As mentioned above the Symbols column is redundant so a configuration of the parser consists of the current stack and the remainder of the input. Formally it is
The parser consults the combined ACTION-GOTO table for its current state (TOS) and next input symbol, formally this is ACTION[sm,ai], and proceeds based on the value in the table. If the action is a shift, the next state is clear from the DFA We have done this informally just above; here we use the formal treatment).
The missing piece of the puzzle is finally revealed.
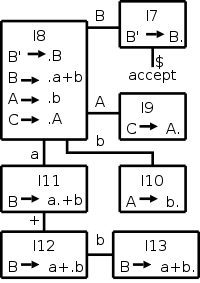
Before defining the ACTION and GOTO tables precisely, I want to do it informally via the simple example on the right. I produced that diagram without starting from a grammar so I really don't know if it is realistic, but it does illustrate how the tables are constructed directly from the diagram.
For convenience number the productions of the grammar to make them easy to reference. Assume that the production B → a+b is numbered 2.
IMPORTANT: In order to construct the ACTION table, you do need something not in the diagram. You need to know the FOLLOW sets, the same sets that we constructed for top-down parsing.
For this example let us assume FOLLOW(B)={b} and all other follow sets are empty. Again, I am not claiming that there is a grammar with this diagram and these FOLLOW sets.
The action table is defined with states (item sets) as rows and terminals and the $ endmarker as columns. GOTO has the same rows, but has nonterminals as columns. So we construct a combined ACTION-GOTO table, with states as rows and grammar symbols (terminals + nonterminals) as columns.
| State | a | b | + | $ | A | B | C |
|---|---|---|---|---|---|---|---|
| 7 | + | acc | |||||
| 8 | s11 | s10 | 9 | 7 | |||
| 9 | |||||||
| 10 | |||||||
| 11 | s12 | ||||||
| 12 | s13 | ||||||
| 13 | r2 |
accept.
The book (both editions) and the rest of the world seem to use GOTO for both the function defined on item sets and the derived function on states. As a result we will be defining GOTO in terms of GOTO. Item sets are denoted by I or Ij, etc. States are denoted by s or si or (get ready) i. Indeed both books use i in this section. The advantage is that on the stack we placed integers (i.e., i's) so this is consistent. The disadvantage is that we are defining GOTO(i,A) in terms of GOTO(Ii,A), which looks confusing. Actually, we view the old GOTO as a function and the new one as an array (mathematically, they are the same) so we actually write GOTO(i,A) and GOTO[Ii,A].
We start with an augmented grammar (i.e., we added S' → S).
shift j, where GOTO(Ii,b)=Ij.
reduce A→α.
accept.
error.
| State | ACTION | GOTO | |||||||
|---|---|---|---|---|---|---|---|---|---|
| id | + | * | ( | ) | $ | E | T | F | |
| 0 | s5 | s4 | 1 | 2 | 3 | ||||
| 1 | s6 | acc | |||||||
| 2 | r2 | s7 | r2 | r2 | |||||
| 3 | r4 | r4 | r4 | r4 | |||||
| 4 | s5 | s4 | 8 | 2 | 3 | ||||
| 5 | r6 | r6 | r6 | r6 | |||||
| 6 | s5 | s4 | 9 | 3 | |||||
| 7 | s5 | s4 | 10 | ||||||
| 8 | s6 | s11 | |||||||
| 9 | r1 | s7 | r1 | r1 | |||||
| 10 | r3 | r3 | r3 | r3 | |||||
| 11 | r5 | r5 | r5 | r5 | |||||
shift and go to state 5.
reduce by production number 2, where we have numbered the productions as follows.
The shift actions can be read directly off the DFA. For example I1 with a + goes to I6, I6 with an id goes to I5, and I9 with a * goes to I7.
The reduce actions require FOLLOW.
Consider I5={F→id·}.
Since the dot is at the end, we are ready to reduce, but we must
check if the next symbol can follow the F we are reducing to.
Since FOLLOW(F)={+,*,),$}, in row 5 (for I5) we put
r6 (for reduce by production 6
) in the columns for
+, *, ), and $.
The GOTO columns can also be read directly off the DFA. Since there is an E-transition (arc labeled E) from I0 to I1, the column labeled E in row 0 contains a 1.
Since the column labeled + is blank for row 7, we see that it would be an error if we arrived in state 7 when the next input character is +.
Finally, if we are in state 1 when the input is exhausted ($ is the next input character), then we have a successfully parsed the input.
| Stack | Symbols | Input | Action |
|---|---|---|---|
| 0 | id*id+id$ | shift | |
| 05 | id | *id+id$ | reduce by F→id |
| 03 | F | *id+id$ | reduct by T→id |
| 02 | T | *id+id$ | shift |
| 027 | T* | id+id$ | shift |
| 0275 | T*id | +id$ | reduce by F→id |
| 027 10 | T*F | +id$ | reduce by T→T*F |
| 02 | T | +id$ | reduce by E→T |
| 01 | E | +id$ | shift |
| 016 | E+ | id$ | shift |
| 0165 | E+id | $ | reduce by F→id |
| 0163 | E+F | $ | reduce by T→F |
| 0169 | E+T | $ | reduce by E→E+T |
| 01 | E | $ | accept |
Example: The diagram on the right shows the actions when SLR is parsing id*id+id. On the blackboard let's do id+id*id and see how the precedence is handled.
Homework: 2 (you already constructed the LR(0) automaton for this example in the previous homework), 3, 4 (this problem refers to 4.2.2(a-g); only use 4.2.2(a-c).
Example: What about ε-productions? Let's do
A → B C
B → b B | ε
C → c
Reducing by the ε-production actually adds a state (pops ZERO states since zero symbols on RHS and pushes one).