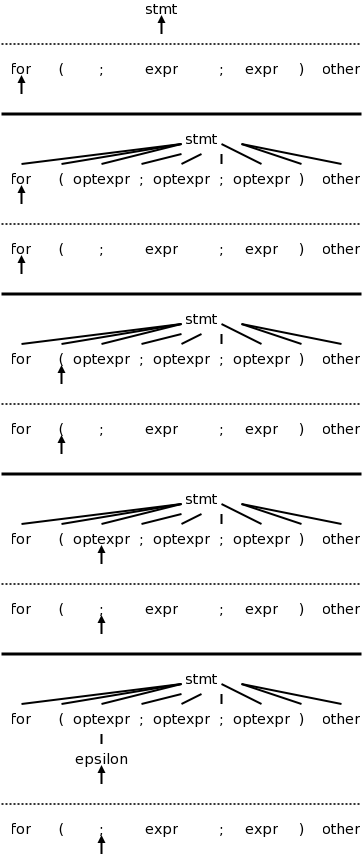
Not all grammars are as friendly as the last example. The first complication is when ε occurs as a RHS. If this happens or if the RHS can generate ε, then ε is included in FIRST.
But ε would always match the current input position!
The rule is that if lookahead is not in FIRST of any production with the desired LHS, we use the (unique!) production (with that LHS) that has ε as RHS.
The text does a C instead of a pascal example. The productions are
stmt → expr ;
| if ( expr ) stmt
| for ( optexpr ; optexpr ; optexpr ) stmt
| other
optexpr → expr | ε
For completeness, on the right is the beginning of a movie for the C example. Note the use of the ε-production at the end since no other entry in FIRST will match ;
Once again, the full story will be revealed in chapter 4 when we do parsing in a more complete manner.
Predictive parsers are fairly easy to construct as we will now see. Since they are recursive descent parsers we go top-down with one procedure for each nonterminal. Do remember that we must have disjoint FIRST sets for all the productions having a given nonterminal as LHS.
The book has code at this point, which you should read. We will see code in class, later in this chapter.
Another complication.
Consider
expr → expr + term
expr → term
For the first production the RHS begins with the LHS. This is called left recursion. If a recursive descent parser would pick this production, the result would be that the next node to consider is again expr and the lookahead has not changed. An infinite loop occurs.
If we tried
expr → expr + term
expr → term
the result would be right recursive, which is no problem.
However, the resulting grammar treats addition as right associative,
which is not what we want.
Consider instead
expr → term rest
rest → + term rest
rest → ε
Both sets of productions generate the same possible token strings,
namely
term + term + ... + term
The second set is called right recursive since the RHS ends (has on
the right) the LHS.
If you draw the parse trees generated, you will see
that, for left recursive productions, the tree grows to the left; whereas,
for right recursive, it grows to the right.
In general, for any A, R, α, and β, we can replace the pair
A → A α | β
with the triple
A → β R
R → α R | ε
For the example above A is expr
, R is
rest
, α is + term
, and β is
term
.
Objective: an infix to postfix translator for expressions. We start with just plus and minus, specifically the expressions generated by the following grammar. We include a set of semantic actions with the grammar. Note that finding a grammar for the desired language is one problem, constructing a translator for the language, given a grammar, is another problem. We are tackling the second problem.
expr → expr + term { print('+') }
expr → expr - term { print('-') }
expr → term
term → 0 { print('0') }
. . .
term → 9 { print('9') }
One problem that we must solve is that this grammar is left recursive.
We prefer not to have superfluous nonterminals as they make the parsing less efficient. That is why we don't say that a term produces a digit and a digit produces each of 0,...,9. Ideally the syntax tree would just have the operators + and - and the 10 digits 0,1,...,9. That would be called the abstract syntax tree. A parse tree coming from a grammar is technically called a concrete syntax tree.
We eliminate the left recursion as we did in 2.4. This time there
are two operators + and - so we replace the triple
A → A α | A β | γ
with the quadruple
A → γ R
R → α R | β R | ε
This time we have actions so, for example
α is + term { print('+') }
However, the formulas still hold and we get
expr → term rest
rest → + term { print('+') } rest
| - term { print('-') } rest
| ε
term → 0 { print('0') }
. . .
| 9 { print('9') }
The C code is in the book. Note the else ; in rest(). This corresponds to the epsilon production. As mentioned previously. The epsilon production is only used when all others fail (that is why it is the else arm and not the then or the else if arms).
These are (useful) programming techniques.
The program in Java is in the book.
Converts a sequence of characters (the source) into a sequence of tokens. A lexeme is the sequence of characters comprising a single token. The reason we were able to produce the translator in the previous section without a lexer is that all the tokens were just one character (that is why we had just single digits).
These do not become tokens so that the parser need not worry about them.
Consider distinguishing
x<y from x<=y.
After reading the < we must read another character.
If it is a y, we have found our token (<).
However, we must unread
the y so that when asked for
the next token we will start at y.
If it is never more than one extra character that must be examined,
a single char variable would suffice.
A more general solution is discussed next chapter (Lexical Analysis).
This chapter considers only numerical integer constants. They are computed one digit at a time by value=10*value+digit. The parser will therefore receive the token num rather than a sequence of digits. Recall that our previous parsers considered only one digit numbers.
The value of the constant can be considered the attribute of the
token named num.
Alternatively, the attribute can be a pointer/index into the symbol
table entry for the number (or into a numbers table
).
The C statement
sum = sum + x;
contains 4 tokens.
The scanner will convert the input into
id = id + id ; (id standing for identifier).
Although there are three id tokens, the first and second represent
the lexeme sum; the third represents x.
These must be distinguished.
Many language keywords, for example then
, are syntactically
the same as identifiers.
These also must be distinguished.
The symbol table will accomplish these tasks.
We assume (as do most modern languages) that the keywords are
reserved, i.e., cannot be used as program variables.
The we simply initialize the symbol table to contain all these
reserved words and mark them as keywords.
When the lexer encounters a would-be identifier and searches the
symbol table, it finds out that the string is actually a keyword.
Care must be taken when one lexeme is a proper subset of another.
Consider
x<y versus x<=y
When the < is read,
the scanner needs to read another character to see if it is an =.
But if that second character is y, the current token is < and the
y must be “pushed back” onto the input stream so that
the configuration is the same after scanning < as it is after
scanning <=.
Also consider then versus thenewvalue, one is a keyword and the other an id.
A Java program is given. The book, but not the course, seems to assume knowledge of Java.
Since the scanner converts digits into num's we can shorten the grammar. Here is the shortened version before the elimination of left recursion. Note that the value attribute of a num is its numerical value.
expr → expr + term { print('+') }
expr → expr - term { print('-') }
expr → term
term → num { print(num.value) }
In anticipation of other operators with higher precedence, we could
introduce factor and, for good measure, include parentheses for
overriding the precedence.
Our grammar would then become.
expr → expr + term { print('+') }
expr → expr - term { print('-') }
expr → term
term → factor
factor → ( expr ) | num { print(num,value) }
The factor() procedure follows the familiar recursive descent
pattern: Find a production with factor as LHS and lookahead in
FIRST, then do what the RHS says
.
That is call the procedures corresponding to the nonterminals, match
the terminals, and execute the semantic actions
The symbol table is an important data structure for the entire compiler. One example of its use would be for semantic actions associated with declarations to set the type field of an entry; semantic actions associated with expression evaluation would used this type information. For the simple infix to postfix translator (which is typeless), the table is primarily used to store and retrieve <lexeme,token> pairs.
There is a serious issue here involving scope.
We will learn soon that lexers are based on regular expressions;
whereas parsers are based on the stronger but more expensive
context-free grammars.
Regular expressions are not powerful enough to handle nested scopes.
So, if the language you are compiling supports nested scopes, the
lexer can only construct the <lexeme,token> pairs.
The parser converts these pairs into a true symbol table that
reflects the nested scopes.
If the language is flat
, the scanner can produce the symbol
table.
The idea is that, when entering a block, a new symbol table is created. Each such table points to the one immediately outer. This structure supports the most-closely nested rule for symbols: a symbol is in the scope of most-closely nested declaration. This gives rise to a tree of tables.
Simply insert them into the symbol table prior to examining any
input.
Then they can be found when used correctly and, since their
corresponding token will not be id, any use of them where an
identifier is required can be flagged.
For example one would have insert(int
) performed for
every table.
Below is the grammar for a stripped down example showing nested
scopes.
The language consists just of declarations of the form
identifier : type ; -- I like ada not C style declarations
trivial statements of the form
identifier ;
and nested blocks.
program → block
block → { decls stmts } -- { } are terminals not actions
decls → decls decl | ε -- study this one
decl → id : type ;
stmts → stmts stmt | ε -- same idea, a list
stmt → block | factor ; -- get nested block
factor → id
| Production | Action | ||
|---|---|---|---|
| Program | → | {top = null} | |
| block | |||
| block | → | { | { saved = top; |
| top = new Env(top); | |||
| print ("} "); } | |||
| decls stmts } | { top = saved; | ||
| print ("} "); } | |||
| decls | → | decls decl | |
| | | ε | ||
| decl | → | type id ; | { s = new Symbol; |
| s.type = type.lexeme; | |||
| top.put(id.lexeme,s); } | |||
| stmts | → | stmts stmt | |
| | | ε | ||
| stmt | → | block | |
| | | factor ; | { print("; "); } | |
| factor | → | id | { s = top.get(id.lexeme); |
| print(s.type); } | |||
One possible program in this language is
{ x : int ; y : float ;
x ; y ;
{ x : float ;
x ; y ;
}
{ y : int ;
x ; y;
}
x ; y ;
}
To show that we have correctly parsed the input and obtained
its meaning
(i.e., performed semantic analysis), we present a
translation scheme that digests the declarations and translates the
statements so that we get
{ int ; float ; { float ; float ; } { int ; int ; } }
The translation scheme, slightly modified from the book page 90, is shown on the right. First a formatting comment.
This translation scheme looks weird, but is actually a good idea (of the authors): it reconciles the two goals of respecting the ordering and nonetheless having the actions all in one column.
Recall that the placement of the actions within the RHS of the production is significant. The RHS is process in order (from left to right) but with a postorder traversal. Thus an action is executed after all the subtrees rooted by parts of the RHS to the left of the action and is executed before all the subtrees rooted by parts of the RHS to the right of the action.
Consider the first production.
We want the action to be executed before processing block
.
Thus the action must precede block
in the RHS.
But we want the actions in the right column.
So we split the RHS over several lines and place an action in the
rightmost column of the line that puts in the right order.
The second production has some semantic actions to be performed at the start of the block, and others to be performed at the bottom.
To fully understand the details, you must read the book; but we can see how it works. A new Env initializes a new symbol table; top.put inserts into the symbol table in the environment top; top.get retrieves from that symbol table.
In some sense the star of the show
is the simple
production
factor → id
together with its semantic actions.
These actions look up the identifier in the (correct!) symbol table
and print out the type name.
There are two important forms of intermediate representations.
Another (but less common) name for parse tree is
concrete syntax tree
.
Similarly another (also less common) name for syntax tree is
abstract syntax tree
.
Very roughly speaking, (abstract) syntax trees are parse trees reduced to their essential components, and three address code looks like assembler without the concept of registers.
Remarks:
real compilershave already completed the course before starting the design so this consideration does not apply to them. :-)
Consider the production
while-stmt → while ( expr ) stmt ;
The parse tree would have a node while-stmt with 6 children: while,
(, expr, ), stmt, and ;.
Many of these are simply syntactic constructs with no real meaning.
The essence of the while statement is that the system repeatedly
executes stmt until expr is false.
Thus, the (abstract) syntax tree has a node (most likely labeled
while) with two children, the syntax trees for expr and stmt.
For this while node, we execute
new While(x,y)
where x and y are the already constructed
(synthesized attributes!) nodes for expr and stmt
The book has a translation scheme (p. 94) for several statements.
The part for while reads
stmt → while ( expr ) stmt1
{ stmt.n = new While(expr.n, stmt1.n); }
The n
attribute gives the syntax tree node.
Fairly easy
stmt → block { stmt.n = block.n }
block → { stmts } { block.n = stmts.n }
Together these two just use the syntax tree for the statements
constituting the block as the syntax tree for the block when it is
used as a statement.
So
while ( x == 5 ) {
blah
blah
more
}
would give the while node of the abstract syntax tree two children
as always:
blah blah more.
When parsing we need to distinguish between + and * to insure that
3+4*5 is parsed correctly, reflecting the higher precedence of *.
However, once parsed, the precedence is reflected in the tree itself
(the node for + has the node for * as a child).
The rest of the compiler treats + and * largely the same so it is
common to use the same node label, say OP, for both of them.
So we see
term → term1 * factor
{ term.n = new Op('*', term1.n, factor.n); }
Static checking refers to checks performed during compilation; whereas, dynamic checking refers to those performed at run time. Examples of static checks include
Consider Q = Z; or A[f(x)+B*D] = g(B+C*h(x,y));. I am using [] for array reference and () for function call).
From a macroscopic view, we have three tasks.
Note the differences between L-values, quantities that can appear on the LHS of an assignment, and and R-values, quantities that can appear only on the RHS.
Static checking is used to insure that R-values do not appear on the LHS.
These checks assure that the type of the operands are expected by the operator. In addition to flagging errors, this activity includes
These are primitive instructions that have one operator and (up to) three operands, all of which are addresses. One address is the destination, which receives the result of the operation; the other two addresses are the sources of the values to be operated on.
Perhaps the clearest way to illustrate the (up to) three address nature of the instructions is to write them as quadruples or quads.
ADD x y z
MULT a b c
ARRAY_L q r s
ARRAY_R e f g
ifTrueGoto x L
COPY r s
But we normally write them in a more familiar form.
x = y + z
a = b * c
q[r] = s
e = f[g]
ifTrue x goto L
r = s
We do this and the next section much slower and in much more detail later in the course.
Here is the example from the book, somewhat Java intensive.
class If extends Stmt {
Expr E; Stmt S;
public If(Expr x, Stmt y) { E = x; S = y; after = newlabel(); }
public void gen() {
Expr n = E.rvalue();
emit ("ifFalse" + n.toString() + "goto " + after);
S.gen();
emit(after + ":");
}
}
I am just illustrating the simplest case
Expr rvalue(x : Expr) {
if (x is an Id or Constant node) return x;
else if (x is an Op(op, y, z) node) {
t = new temporary;
emit string for t = rvalue(y) op rvalue(z);
return a new node for t;
else read book for other cases
So called optimization
(the result is far from optimal) is a
huge subject that we barely touch.
Here are a few very simple examples.
We will cover these since they are local optimizations
,
that is they occur within a single basic block
(a sequence of
statements that execute without any jumps).
temp = x + 1
x = temp
The can be combined into the three-address instruction
x = x + 1, providing there are no further uses of the temporary.
One reason is that much was deliberately simplified. Specifically note that
Also, I presented the material way too fast to expect full understanding.
Homework: Read chapter 3.
Two methods to construct a scanner (lexical analyzer).
Note that the speed (of the lexer not of the code generated by the compiler) and error reporting/correction are typically much better for a handwritten lexer. As a result most production-level compiler projects write their own lexers
The lexer is called by the parser when the latter is ready to process another token.
The lexer also might do some housekeeping such as eliminating whitespace and comments. Some call these tasks scanning, but others user the term scanner for the entire lexical analyzer.
After the lexer, individual characters are no longer examined by the compiler; instead tokens (the output of the lexer) are used.
Why separate lexical analysis from parsing? The reasons are basically software engineering concerns.
Note the circularity of the definitions for lexeme and pattern.
Common token classes.
We saw an example of attributes in the last chapter.
For tokens corresponding to keywords, attributes are not needed since the name of the token tells everything. But consider the token corresponding to integer constants. Just knowing that the we have a constant is not enough, subsequent stages of the compiler need to know the value of the constant. Similarly for the token identifier we need to distinguish one identifier from another. The normal method is for the attribute to specify the symbol table entry for this identifier.
We really shouldn't say symbol table. As mentioned above if the language has scoping (nested blocks) the lexer can't construct the symbol table, but just makes a table of <lexeme,token> pairs.
Homework: 1.
We saw in this movie an example where parsing got “stuck” because we reduced the wrong part of the input string. We also learned about FIRST sets that enabled us to determine which production to apply when we are operating left to right on the input. For predictive parsers the FIRST sets for a given nonterminal are disjoint and so we know which production to apply. In general the FIRST sets might not be disjoint so we have to try all the productions whose FIRST set contains the lookahead symbol.
All the above assumed that the input was error free, i.e. that the source was a sentence in the language. What should we do when the input is erroneous and we get to a point where no production can be applied?
In many cases this is up to the parser to detect/repair.
Sometimes the lexer is stuck
because there are no patterns
that match the input at this point.
The simplest solution is to abort the compilation stating that the program is wrong, perhaps giving the line number and location where the lexer and/or parser could not proceed.
We would like to do better and at least find other errors. We could perhaps skip input up to a point where we can begin anew (e.g. after a statement ending semicolon), or perhaps make a small change to the input around lookahead so that we can proceed.
Determining the next lexeme often requires reading the input beyond the end of that lexeme. For example, to determine the end of an identifier normally requires reading the first whitespace character after it. Also just reading > does not determine the lexeme as it could also be >=. When you determine the current lexeme, the characters you read beyond it may need to be read again to determine the next lexeme.
The book illustrates the standard programming technique of using two (sizable) buffers to solve this problem.
A useful programming improvement to combine testing for the end of a buffer with determining the character read.
The chapter turns formal and, in some sense, the course begins.
The book is fairly careful about finite vs infinite sets and also uses
(without a definition!) the notion of a countable set.
(A countable set is either a finite set or one whose elements can be
put into one to one correspondence with the positive integers.
That is, it is a set whose elements can be counted.
The set of rational numbers, i.e., fractions in lowest terms, is
countable;
the set of real numbers is uncountable, because it is strictly
bigger, i.e., it cannot be counted.)
We should be careful to distinguish the empty set φ from the
empty string ε.
Formal language theory is a beautiful subject, but I shall suppress
my urge to do it right
and try to go easy on the formalism.
We will need a bunch of definitions.
Definition: An alphabet is a finite set of symbols.
Example: {0,1}, presumably φ (uninteresting), ascii, unicode, ebcdic, latin-1.
Definition: A string over an alphabet is a finite sequence of symbols from that alphabet. Strings are often called words or sentences.
Example: Strings over {0,1}: ε, 0, 1, 111010. Strings over ascii: ε, sysy, the string consisting of 3 blanks.
Definition: The length of a string is the number of symbols (counting duplicates) in the string.
Example: The length of allan, written |allan|, is 5.
Definition: A language over an alphabet is a countable set of strings over the alphabet.
Example: All grammatical English sentences with five, eight, or twelve words is a language over ascii. It is also a language over unicode.
Definition: The concatenation of strings s and t is the string formed by appending the string t to s. It is written st.
Example: εs = sε = s for any string s.
We view concatenation as a product (see Monoid in wikipedia http://en.wikipedia.org/wiki/Monoid). It is thus natural to define s0=ε and si+1=sis.
Example: s1=s, s4=ssss.
A prefix of a string is a portion starting from the beginning and a suffix is a portion ending at the end. More formally,
Definitions: A prefix of s is any string obtained from s by removing (possibly zero) characters from the end of s.
A suffix is defined analogously and a substring of s is obtained by deleting a prefix and a suffix.
Example: If s is 123abc, then
(1) s itself and ε are each a prefix, suffix, and a substring.
(2) 12 are 123a are prefixes.
(3) 3abc is a suffix.
(4) 23a is a substring.
Definitions: A proper prefix of s is a prefix of s other than ε and s itself. Similarly, proper suffixes and proper substrings of s do not include ε and s.
Definition: A subsequence of s is formed by deleting (possibly zero) positions from s. We say positions rather than characters since s may for example contain 5 occurrences of the character Q and we only want to delete a certain 3 of them.
Example: issssii is a subsequence of Mississippi.
Homework: 3(a,b,c).
Definition: The union of L1 and L2 is simply the set-theoretic union, i.e., it consists of all words (strings) in either L1 or L2.
Example: The union of {Grammatical English sentences with one, three, or five words} with {Grammatical English sentences with two or four words} is {Grammatical English sentences with five or fewer words}.
Definition: The concatenation of L1 and L2 is the set of all strings st, where s is a string of L1 and t is a string of L2.
We again view concatenation as a product and write LM for the concatenation of L and M.
Examples:: The concatenation of {a,b,c} and {1,2} is {a1,a2,b1,b2,c1,c2}. The concatenation of {a,b,c} and {1,2,ε} is {a1,a2,b1,b2,c1,c2,a,b,c}.
Definition: As with strings, it is natural to
define powers of a language L.
L0={ε}, which is not φ.
Li+1=LiL.
Definition: The (Kleene) closure of L,
denoted L* is
L0 ∪ L1 ∪ L2 ...
Definition: The positive closure of L,
denoted L+ is
L1 ∪ L2 ...
Example: {0,1,2,3,4,5,6,7,8,9}+ gives
all unsigned integers, but with some ugly versions.
It has 3, 03, 000003.
{0} ∪ ( {1,2,3,4,5,6,7,8,9} ({0,1,2,3,4,5,6,7,8,9,0}* ) )
seems better.
In these notes I may write * for * and + for +, but that is strictly speaking wrong and I will not do it on the board or on exams or on lab assignments.
Example: {a,b}* is
{ε,a,b,aa,ab,ba,bb,aaa,aab,aba,abb,baa,bab,bba,bbb,...}.
{a,b}+ is {a,b,aa,ab,ba,bb,aaa,aab,aba,abb,baa,bab,bba,bbb,...}.
{ε,a,b}* is {ε,a,b,aa,ab,ba,bb,...}.
{ε,a,b}+ is the same as {ε,a,b}*.
The book gives other examples based on L={letters} and D={digits}, which you should read..
The idea is that the regular expressions over an alphabet consist
of
ε, the alphabet, and expressions using union,
concatenation, and *,
but it takes more words to say it right.
For example, I didn't include ().
Note that (A ∪ B)* is definitely not A* ∪ B* (* does not
distribute over ∪) so we need the parentheses.
The book's definition includes many () and is more complicated than I think is necessary. However, it has the crucial advantages of being correct and precise.
The wikipedia entry doesn't seem to be as precise.
I will try a slightly different approach, but note again that there is nothing wrong with the book's approach (which appears in both first and second editions, essentially unchanged).
Definition: The regular expressions and associated languages over an alphabet consist of
Parentheses, if present, control the order of operations. Without parentheses the following precedence rules apply.
The postfix unary operator * has the highest precedence. The book mentions that it is left associative. (I don't see how a postfix unary operator can be right associative or how a prefix unary operator such as unary - could be left associative.)
Concatenation has the second highest precedence and is left associative.
| has the lowest precedence and is left associative.
The book gives various algebraic laws (e.g., associativity) concerning these operators.
The reason we don't include the positive closure is that for any RE
r+ = rr*.
Homework: 2(a-d), 4.