================ Start Lecture #2 ================
Remark: I had a bad link to the mailing list. It was fixed on wed about 1:45pm. If you signed up before then you might have joined last year's list. Sorry.
Homework: Read chapter 2.
The goal of this chapter is to implement a very
simple compiler
.
Really we are just going as far as the intermediate code, i.e., the
front end.
Nonetheless, the output, i.e. the intermediate code, does look
somewhat like assembly language
We will be looking at the front end, i.e., the analysis portion of a compiler.
The syntax describes the form of a program in a given language, while the semantics describes the meaning of that program. We will use the standard context-free grammar or BNF (Backus-Naur Form) to describe the syntax
We will learn syntax-directed translation, where the grammar does more than specify the syntax. We augment the grammar with attributes and use this to guide the entire front end.
The front end discussed in this chapter has as source language
infix expressions consisting of digits, +, and -.
The target language is
postfix expressions with the same components.
The compiler will convert
7+4-5 to 74+5-.
Actually, our simple compiler will handle a few other operators as well.
We will tokenize
the input (i.e., write a scanner), model
the syntax of the source, and let this syntax direct the translation
all the way to three-address code
, our intermediate language.
This will be “done right” in the next two chapters.
A context-free grammar (CFG) consists of
Example:
Terminals: 0 1 2 3 4 5 6 7 8 9 + -
Nonterminals: list digit
Productions: list → list + digit
list → list - digit
list → digit
digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Start symbol: list
If no start symbol is specifically designated, the LHS of the first production is the start symbol.
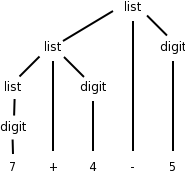
Watch how we can generate the input 7+4-5 starting with the start symbol, applying productions, and stopping when no productions are possible (we have only terminals).
list → list - digit
→ list - 5
→ list + digit - 5
→ list + 4 - 5
→ digit + 4 - 5
→ 7 + 4 - 5
This process of applying productions, starting with the start symbol and ending when only terminals are present is called a derivation and we say that the final string has been derived from the initial string (in this case the start symbol).
The set of all strings derivable from the start symbol is the language generated by the CFG
Given a grammar, parsing a string consists of determining if the string is in the language generated by the grammar. If it is in the language, parsing produces a derivation. If it is not, parsing reports an error.
The opposite of derivation is reduction. Given a production, the LHS produces the RHS (a derivation) and the RHS is reduced to the LHS (a derivation).
Homework: 1a, 1c, 2a-c (don't worry about
justifying
your answers).
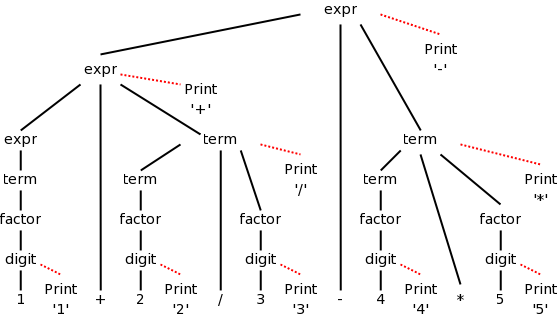
While deriving 7+4-5, one could produce the Parse Tree shown on the right.
You can read off the productions from the tree. For any internal (i.e., non-leaf) tree node, its children give the right hand side (RHS) of a production having the node itself as the LHS.
The leaves of the tree, read from left to right, is called the yield of the tree. We call the tree a derivation of its yield from its root. The tree on the right is a derivation of 7+4-5 from list.
Homework: 1b
An ambiguous grammar is one in which there are two or more parse trees yielding the same final string. We wish to avoid such grammars.
The grammar above is not ambiguous. For example 1+2+3 can be parsed only one way; the arithmetic must be done left to right. Note that I am not giving a rule of arithmetic, just of this grammar. If you reduced 2+3 to list you would be stuck since it is impossible to further reduce 1+list (said another way it is not possible to derive 1+list from the start symbol).
Homework: 3 (applied only to parts a, b, and c of 2)
Our grammar gives left associativity. That is, if you traverse the parse tree in postorder and perform the indicated arithmetic you will evaluate the string left to right. Thus 8-8-8 would evaluate to -8. If you wished to generate right associativity (normally exponentiation is right associative, so 2**3**2 gives 512 not 64), you would change the first two productions to
list → digit + list list → digit - list
Produce in class the parse tree for 7+4-5 with this new grammar.
We normally want * to have higher precedence than +. We do this by using an additional nonterminal to indicate the items that have been multiplied. The example below gives the four basic arithmetic operations their normal precedence unless overridden by parentheses. Redundant parentheses are permitted. Equal precedence operations are performed left to right.
expr → expr + term | expr - term | term term → term * factor | term / factor | factor factor → digit | ( expr ) digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
We use | to indicate that a nonterminal has multiple possible right hand side. So
A → B | Cis simply shorthand for
A → B A → C
Do the examples 1+2/3-4*5 and (1+2)/3-4*5 on the board.
Note how the precedence is enforced by the grammar; slick!
Keywords are very helpful for distinguishing statements from one another.
stmt → id := expr
| if expr then stmt
| if expr then stmt else stmt
| while expr do stmt
| begin opt-stmts end
opt-stmts → stmt-list | ε
stmt-list → stmt-list ; stmt | stmt
Remarks:
optional statements. The begin-end block can be empty in some languages.
epsilon productionswill add complications.
nullstatement, which does nothing when executed, for this purpose.
if x then if y then z=1 else z=2?
The idea is to specify the translation of a source language construct in terms of attributes of its syntactic components. The basic idea is use the productions to specify a (typically recursive) procedure for translation. For example, consider the production
stmt-list → stmt-list ; stmt
To process the left stmt-list, we
To avoid having to say the right stmt-list
we write the
production as
stmt-list → stmt-list1 ; stmt
where the subscript is used to distinguish the two instances of
stmt-list.

This notation is called postfix because the rule
is operator after operand(s)
.
Parentheses are not needed.
The notation we normally use is called infix.
If you start with an infix expression, the following algorithm will
give you the equivalent postfix expression.
One question is, given say 1+2-3, what is E, F and op? Does E=1+2, F=3, and op=+? Or does E=1, F=2-3 and op=+? This is the issue of precedence mentioned above. To simplify the present discussion we will start with fully parenthesized infix expressions.
Example: 1+2/3-4*5
Example: Now do (1+2)/3-4*5
We want to decorate
the parse trees we construct with
annotations
that give the value of certain attributes
of the corresponding node of the tree.
We will do the example of
translating infix to postfix with 1+2/3-4*5.
We use the following grammar, which follows the normal arithmetic
terminology where one multiplies and divides factors to obtain
terms, which in turn are added and subtracted to form expressions.
expr → expr + term | expr - term | term term → term * factor | term / factor | factor factor → digit | ( expr ) digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
This grammar supports parentheses, although our example does not
use them.
On the right is a movie
in which the parse tree is
build from this example.
The attribute we will associate with the nodes is the postfix form of the string in the leaves below the node. In particular, the value of this attribute at the root is the postfix form of the entire source.
The book does a simpler grammar (no *, /, or parentheses) for a simpler example. You might find that one easier.
Definition: A syntax-directed definition is a grammar together with semantic rules associated with the productions. These rules are used to compute attribute values. A parse tree augmented with the attribute values at each node is called an annotated parse tree.
For the bottom-up approach I will illustrate now, we annotate a node after having annotated its children. Thus the attribute values at a node can depend on the children of the node but not the parent of the node. We call these synthesized attributes, since they are formed by synthesizing the attributes of the children.
In chapter 5, when we study top-down annotations as well, we will
introduce inherited
attributes that are passed down from
parents to children.
We specify how to synthesize attributes by giving the semantic rules together with the grammar. That is we give the syntax directed definition.
| Production | Semantic Rule |
|---|---|
| expr → expr1 + term | expr.t := expr1.t || term.t || '+' |
| expr → expr1 - term | expr.t := expr1.t || term.t || '-' |
| expr → term | expr.t := term.t |
| term → term1 * factor | term.t := term1.t || factor.t || '*' |
| term → term1 / factor | term.t := term1.t || factor.t || '/' |
| term → factor | term.t := factor.t |
| factor → digit | factor.t := digit.t |
| factor → ( expr ) | factor.t := expr.t |
| digit → 0 | digit.t := '0' |
| digit → 1 | digit.t := '1' |
| digit → 2 | digit.t := '2' |
| digit → 3 | digit.t := '3' |
| digit → 4 | digit.t := '4' |
| digit → 5 | digit.t := '5' |
| digit → 6 | digit.t := '6' |
| digit → 7 | digit.t := '7' |
| digit → 8 | digit.t := '8' |
| digit → 9 | digit.t := '9' |
We apply these rules bottom-up (starting with the geographically lowest productions, i.e., the lowest lines on the page) and get the annotated graph shown on the right. The annotation are drawn in green.
Homework: Draw the annotated graph for (1+2)/3-4*5.
If the semantic rules of a syntax-directed definition all have the property that the new annotation for the left hand side (LHS) of the production is just the concatenation of the annotations for the nonterminals on the RHS in the same order as the nonterminals appear in the production, we call the syntax-directed definition simple. It is still called simple if new strings are interleaved with the original annotations. So the example just done is a simple syntax-directed definition.
Remark: SDD's feature semantic rules. We will soon learn about Translation Schemes, which feature a related concept called semantic actions. When one has a simple SDD, the corresponding translation scheme can be done without constructing the parse tree. That is, while doing the parse, when you get to the point where you would construct the node, you just do the actions. In the corresponding translation scheme for present example, the action at a node is just to print the new strings at the appropriate points.
When traversing a tree, there are several choices as to when to visit a given node. The traversal can visit the node
I do not like the book's code as I feel the names chosen confuses the traversal with visiting the nodes. I prefer the following pseudocode, which also illustrates traversals that are not depth first. Comments are introduced by -- and terminate at the end of the line.
procedure traverse (n: node)
-- visit(n); before children
if (n is a leaf) return;
c = first child;
traverse (c);
while more children
-- visit (n); between children
c = next child;
traverse (c);
end while;
-- visit (n); after children
end traverse;
In general, SDDs do not impose an evaluation order for the attributes of the parse tree. The only requirement is that each attribute is evaluated after all those that it depends on. This general case is quite difficult and sometimes no such order is possible. Since, at this point in the course, we are considering only synthesized attributes, a depth-first (postorder) traversal will always yield a correct evaluation order for the attributes. This is so since synthesized attributes depend only on attributes of child nodes and a depth-first (postorder) traversal visits a node only after all the children have been visited (and hence all the child node attributes have been evaluated).
The bottom-up annotation scheme just described generates the final result as the annotation of the root. In our infix → postfix example we get the result desired by printing the root annotation. Now we consider another technique that produces its results incrementally.
Instead of giving semantic rules for each production (and thereby generating annotations) we can embed program fragments called semantic actions within the productions themselves.
When drawn in diagrams (e.g., see the diagram below), the semantic action is connected to its node with a distinctive, often dotted, line. The placement of the actions determine the order they are performed. Specifically, one executes the actions in the order they are encountered in a postorder traversal of the tree.
Definition: A syntax-directed translation scheme is a context-free grammar with embedded semantic actions.
In the SDD for our infix → postfix translator, the parent
either just passes on the attribute of its (only) child or
concatenates them left to right and adds something at the end.
The equivalent semantic actions is to either print nothing or
print the new item.
Here are the semantic actions corresponding to a few of the rows of the table above. Note that the actions are enclosed in {}.
expr → expr + term { print('+') }
expr → expr - term { print('-') }
term → term / factor { print('/') }
term → factor { null }
digit → 3 { print('3') }
The diagram for 1+2/3-4*5 with attached semantic actions is shown on the right.
Given an input, e.g. our favorite 1+2/3-4*5, we just do a depth first (postorder) traversal of the corresponding diagram and perform the semantic actions as they occur. When these actions are print statements as above, we can be said to be emitting the translation.
Do a depth first traversal of the diagram on the board, performing the semantic actions as they occur, and confirm that the translation emitted is in fact 123/+45*-, the postfix version of 1+2/3-4*5
Homework: Produce the corresponding diagram for (1+2)/3-4*5.
When we produced postfix, all the prints came at the end (so that
the children were already printed
.
The { actions } do not need to come at the end.
We illustrate this by producing infix arithmetic (ordinary) notation
from a prefix source.
 In prefix notation the operator comes first so +1-23 evaluates to
zero and +-123 evaluates to 2.
Consider the following grammar, which generates the simple language
of prefix expressions consisting of addition and subtraction of
digits between 1 and 3 without parentheses (prefix notation and
postfix notation do not use parentheses).
In prefix notation the operator comes first so +1-23 evaluates to
zero and +-123 evaluates to 2.
Consider the following grammar, which generates the simple language
of prefix expressions consisting of addition and subtraction of
digits between 1 and 3 without parentheses (prefix notation and
postfix notation do not use parentheses).
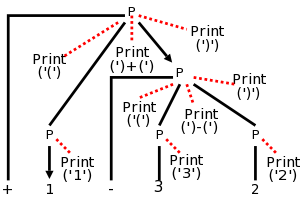
P → + P P | - P P | 1 | 2 | 3
The table below shows both the semantic actions and rules used by the translator. Normally, one does not use both actions and rules.
The resulting parse tree for +1-23 with the semantic actions
attached is shown on the right.
Note that the output language (infix notation) has
parentheses.
| Production with Semantic Action | Semantic Rule |
|---|---|
| P → + { print('(') } P1 { print(')+(') } P2 { print(')') } | P.t := '(' || P1.t || ')+(' || P.t || ')' |
| P → - { print('(') } P1 { print(')-(') } P2 { print(')') } | P.t := '(' || P1.t || ')-(' || P.t || ')' |
| P → 1 { print('1') } | P.t := '1' |
| P → 2 { print('2') } | P.t := '2' |
| P → 3 { print('3') } | P.t := '3' |
Homework: 2.
Objective: Given a string of tokens and a grammar, produce a parse tree yielding that string (or at least determine if such a tree exists).
We will learn both top-down (begin with the start symbol, i.e. the root of the tree) and bottom up (begin with the leaves) techniques.
In the remainder of this chapter we just do top down, which is easier to implement by hand, but is less general. Chapter 4 covers both approaches.
Tools (so called parser generators
) often use bottom-up
techniques.
In this section we assume that the lexical analyzer has already
scanned the source input and converted it into a sequence of tokens.

Consider the following simple language, which derives a subset of the types found in the (now somewhat dated) programming language Pascal. I do not assume you know pascal.
We have two nonterminals, type, which is the start symbol, and
simple, which represents the simple
types.
There are 8 terminals, which are tokens produced by the lexer and correspond closely with constructs in pascal itself. Specifically, we have.
The productions are
type → simple
type → ↑ id
type → array [ simple ] of type
simple → integer
simple → char
simple → num dotdot num
Parsing is easy in principle and for certain grammars (e.g., the one above) it actually is easy. We start at the root since this is top-down parsing and apply the two fundamental steps.
matchesthe input at this point. Make the RHS the children of this node (one child per RHS symbol).
When programmed this becomes a procedure for each nonterminal that
chooses a production for the node and calls procedures for each
nonterminal in the RHS.
Thus it is recursive in nature and descends the parse tree.
We call these parsers recursive descent
.
The big problem is what to do if the current node is the LHS of
more than one production.
The small problem is what do we mean by the next
node needing
a subtree.
The easiest solution to the big problem would be to assume that there is only one production having a given terminal as LHS. There are two possibilities
expr → term + term - 9
term → factor / factor
factor → digit
digit → 7
But this is very boring. The only possible sentence
is 7/7+7/7-9
expr → term + term
term → factor / factor
factor → ( expr )
This is even worse; there are no (finite) sentences. Only an
infinite sentence beginning (((((((((.
So this won't work. We need to have multiple productions with the same LHS.
How about trying them all? We could do this! If we get stuck where the current tree cannot match the input we are trying to parse, we would backtrack.
Instead, we will look ahead one token in the input and only choose productions that can yield a result starting with this token. Furthermore, we will (in this section) restrict ourselves to predictive parsing in which there is only production that can yield a result starting with a given token. This solution to the big problem also solves the small problem. Since we are trying to match the next token in the input, we must choose the leftmost (nonterminal) node to give children to.
Let's return to pascal array type grammar and consider the three
productions having type as LHS. Even when I write the short
form
type → simple | ↑ id | array [ simple ] of type
I view it as three productions.
For each production P we wish to consider the set FIRST(P)
consisting of those tokens that can appear as the first symbol of a
string derived from the RHS of P.
FIRST is actually defined on strings not productions.
When I write FIRST(P), I really mean FIRST(RHS).
Similarly, I often say
the first set of the production P
when I should really say
the first set of the RHS of the production P
.
Definition: Let r be the RHS of a production P. FIRST(r) is the set of tokens that can appear as the first symbol in a string derived from r.
To use predictive parsing, we make the following
Assumption: Let P and Q be two productions with the same LHS, Then FIRST(P) and FIRST(Q) are disjoint. Thus, if we know both the LHS and the token that must be first, there is (at most) one production we can apply. BINGO!
This table gives the FIRST sets for our pascal array type example.
| Production | FIRST |
|---|---|
| type → simple | { integer, char, num } |
| type → ↑ id | { ↑ } |
| type → array [ simple ] of type | { array } |
| simple → integer | { integer } |
| simple → char | { char } |
| simple → num dotdot num | { num } |
The three productions with type as LHS have disjoint FIRST sets. Similarly the three productions with simple as LHS have disjoint FIRST sets. Thus predictive parsing can be used. We process the input left to right and call the current token lookahead since it is how far we are looking ahead in the input to determine the production to use. The movie on the right shows the process in action.
Homework:
A. Construct the corresponding table for
rest → + term rest | - term rest | term term → 1 | 2 | 3B. Can predictive parsing be used?
End of Homework:.