================ Start Lecture #4 ================
Remark: If you find a particular homework question challenging, ask on the mailing list and an answer will be produced.
Remark: I forgot to assign homework for section 3.6. I have added one problem spread into three parts. It is not assigned but it is a question I believe you should be able to do.
(This is item #3 above and is done in section 3.6 in the first edition.)
The book gives a detailed proof; I am just trying to motivate the ideas.
Let N be an NFA, we construct a DFA D that accepts the same strings
as N does.
Call a state of N an N-state, and call a state of D a D-state.
The idea is that D-state corresponds to a set of N-states and hence
this is called the subset algorithm.
Specifically for each string X of symbols we consider all the
N-states that can result when N processes X.
This set of N-states is a D-state.
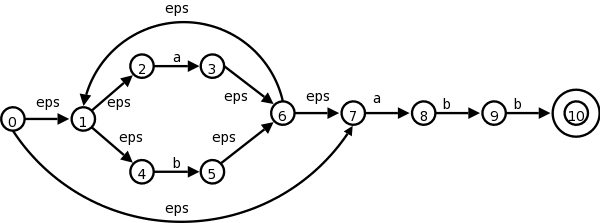
Let us consider the transition graph on the right, which is an NFA
that accepts strings satisfying the regular expression
(a|b)*abb.
| NFA states | DFA state | a | b |
|---|---|---|---|
| {0,1,2,4,7} | D0 | D1 | D2 |
| {1,2,3,4,6,7,8} | D1 | D1 | D3 |
| {1,2,4,5,6,7} | D2 | D1 | D2 |
| {1,2,4,5,6,7,9} | D3 | D1 | D4 |
| {1,2,3,5,6,7,10} | D4 | D1 | D2 |
The start state of D is the set of N-states that can result when N processes the empty string ε. This is called the ε-closure of the start state s0 of N, and consists of those N-states that can be reached from s0 by following edges labeled with ε. Specifically it is the set {0,1,2,4,7} of N-states. We call this state D0 and enter it in the transition table we are building for D on the right.
Next we want the a-successor of D0, i.e., the D-state
that occurs when we start at D0 and move along an edge
labeled a.
We call this successor D1.
Since D0 consists of the N-states corresponding to
ε, D1 is the N-states corresponding
to εa
=a
.
We compute the a-successor of all the N-states in D0 and
then form the ε-closure.
Next we compute the b-successor of D0 the same way and call it D2.
We continue forming a- and b-successors of all the D-states until no new D-states result (there is only a finite number of subsets of all the N-states so this process does indeed stop).
This gives the table on the right. D4 is the only D-accepting state as it is the only D-state containing the (only) N-accepting state 10.
Theoretically, this algorithm is awful since for a set with k elements, there are 2k subsets. Fortunately, normally only a small fraction of the possible subsets occur in practice.
Homework: Convert the NFA from the homework for section 3.6 to a DFA.
Instead of producing the DFA, we can run the subset algorithm as a simulation itself. This is item #2 in my list of techniques
S = ε-closure(s0);
c = nextChar();
while ( c != eof ) {
S = ε-closure(move(S,c));
c = nextChar();
}
if ( S ∩ F != φ ) return yes
; // F is accepting states
else return no
;
Slick implementation.
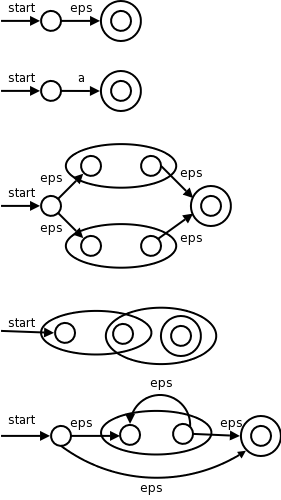
I give a pictorial proof by induction. This is item #1 from my list of techniques.
The pictures on the right illustrate the base and inductive cases.
Remarks:
Do the NFA for (a|b)*abb and see that we get the same diagram that we had before.
Do the steps in the normal leftmost, innermost order (or draw a normal parse tree and follow it).
Homework: 3.16 a,b,c
(This is on page 127 of the first edition.) Skipped.
How lexer-generators like Lex work.
We have seen simulators for DFAs and NFAs.
The remaining large question is how is the lex input converted into one of these automatons.
Also
In this section we will use transition graphs, lexer-generators do not draw pictures; instead they use the equivalent transition tables.
Recall that the regular definitions in Lex are mere conveniences
that can easily be converted to REs and hence we need only convert
REs into an FSA.
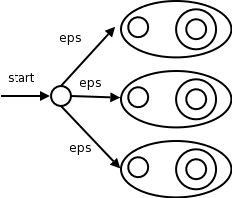
We already know how to convert a single RE into an NFA. But lex input will contain several REs (since it wishes to recognize several different tokens). The solution is to
At each of the accepting states (one for each NFA in step 1), the simulator executes the actions specified in the lex program for the corresponding pattern.
We use the algorithm for simulating NFAs presented in 3.7.2.
The simulator starts reading characters and calculates the set of states it is at.
At some point the input character does not lead to any state or we have reached the eof. Since we wish to find the longest lexeme matching the pattern we proceed backwards from the current point (where there was no state) until we reach an accepting state (i.e., the set of NFA states, N-states, contains an accepting N-state). Each accepting N-state corresponds to a matched pattern. The lex rule is that if a lexeme matches multiple patterns we choose the pattern listed first in the lex-program.
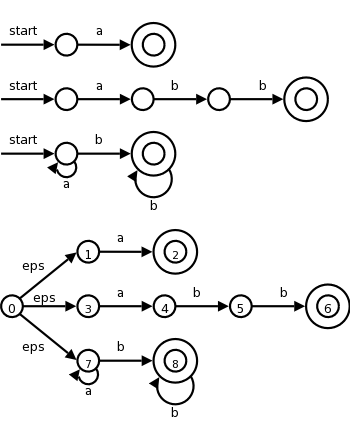
| Pattern | Action to perform |
|---|---|
| a | Action1 |
| abb | Action2 |
| a*b+ | Action3 |
Consider the example on the right with three patterns and their
associated actions and consider processing the input aaba.
optimization.
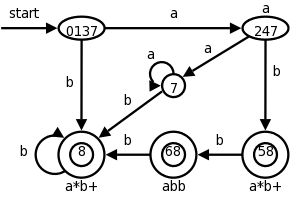
We label the accepting states with the pattern matched. If multiple patterns are matched (because the accepting D-state contains multiple accepting N-states), we use the first pattern listed (assuming we are using lex conventions).
Technical point. For a DFA, there must be a outgoing edge from each D-state for each possible character. In the diagram, when there is no NFA state possible, we do not show the edge. Technically we should show these edges, all of which lead to the same D-state, called the dead state, and corresponds to the empty subset of N-states.
This has some tricky points. Recall that this lookahead operator is for when you must look further down the input but the extra characters matched are not part of the lexeme. We write the pattern r1/r2. In the NFA we match r1 then treat the / as an ε and then match s1. It would be fairly easy to describe the situation when the NFA has only ε-transition at the state where r1 is matched. But it is tricky when there are more than one such transition.
Skipped
Skipped
Skipped
Skipped
Skipped
Homework: Read Chapter 4.
Conceptually, the parser accepts a sequence of tokens and produces a parse tree.
As we saw in the previous chapter the parser calls the lexer to obtain the next token. In practice this might not occur.
There are three classes for grammar-based parsers.
The universal parsers are not used in practice as they are inefficient.
As expected, top-down parsers start from the root of the tree and proceed downward; whereas, bottom-up parsers start from the leaves and proceed upward.
The commonly used top-down and bottom parsers are not universal. That is, there are grammars that cannot be used with them.
The LL and LR parsers are important in practice. Hand written parsers are often LL. Specifically, the predictive parsers we looked at in chapter two are for LL grammars.
The LR grammars form a larger class. Parsers for this class are usually constructed with the aid of automatic tools.
Expressions with + and *
E → E + T | T
T → T * F | F
F → ( E ) | id
This takes care of precedence, but as we saw before, gives us trouble since it is left-recursive and we did top-down parsing. So we use the following non-left-recursive grammar that generates the same language.
E → T E'
E' → + T E' | ε
T → F T'
T' → * F T' | ε
F → ( E ) | id
The following ambiguous grammar will be used for illustration, but in general we try to avoid ambiguity. This grammar does not enforce precedence.
E → E + E | E * E | ( E ) | id
There are different levels
of errors.
off by oneusage of < instead of <=.
The goals are clear, but difficult.
Print an error message when parsing cannot continue and then terminate parsing.
The first level improvement. The parser discards input until it encounters a synchronizing token. These tokens are chosen so that the parser can make a fresh beginning. Good examples are ; and }.
Locally replace some prefix of the remaining input by some string. Simple cases are exchanging ; with , and = with ==. Difficulty is when real error occurred long before the error was detected.
Include productions for common errors
.
Change the input I to the closest
correct input I' and
produce the parse tree for I'.
I don't use these without saying so.
This is mostly (very useful) notation.
Assume we have a production A → α.
We would then say that A derives α and write
A ⇒ α
We generalize this.
If, in addition, β and γ are strings, we say that
βAγ derives βαγ and write
βAγ ⇒ βαγ
We generalize further.
If x derives y and y derives z, we say x derives z and write
x ⇒* z.
The notation used is ⇒ with a * over it (I don't see it in
html).
This should be read derives in zero or more steps
.
Formally,
Definition: If S is the start symbol and S ⇒* x, we say x is a sentential form of the grammar.
A sentential form may contain nonterminals and terminals. If it contains only terminals it is a sentence of the grammar and the language generated by a grammar G, written L(G), is the set of sentences.
Definition: A language generated by a (context-free) grammar is called a context free language.
Definition: Two grammars generating the same language are called equivalent.
Examples: Recall the ambiguous grammar above
E → E + E | E * E | ( E ) | id
We see that id + id is a sentence.
Indeed it can be derived in two ways from the start symbol E
E ⇒ E + E ⇒ id + E ⇒ id + id
E ⇒ E + E ⇒ E + id ⇒ id + id
In the first derivation, we replaced the leftmost nonterminal by the body of a production having the nonterminal as head. This is called a leftmost derivation. Similarly the second derivation in which the rightmost nonterminal is replaced is called a rightmost derivation or a canonical derivation.
When one wishes to emphasize that a (one step) derivation is leftmost they write an lm under the ⇒. To emphasize that a (general) derivation is leftmost, one writes an lm under the ⇒*. Similarly one writes rm to indicate that a derivation is rightmost. I won't do this in the notes but will on the board.
Definition: If x can be derived using a leftmost derivation, we call x a left-sentential form. Similarly for right-sentential form.