Operating Systems
================ Start Lecture #14 ================
Why don't we mimic the idea of paging and have a table giving for
each block of the file, where on the disk that file block is stored?
In other words a ``file block table'' mapping its file block to its
corresponding disk block.
This is the idea of (the first part of) the unix inode solution, which
we study next.
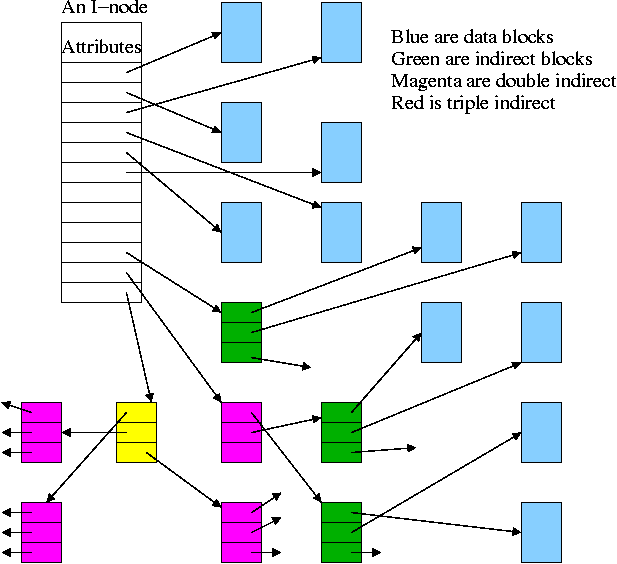
I-Nodes
-
Used by unix/linux.
-
Directory entry points to i-node (index-node).
-
I-Node points to first few data blocks, often called direct blocks.
-
I-Node also points to an indirect block, which points to disk blocks.
-
I-Node also points to a double indirect, which points an indirect ...
-
For some implementations there are triple indirect as well.
-
The i-node is in memory for open files.
So references to direct blocks take just one I/O.
-
For big files most references require two I/Os (indirect + data).
-
For huge files most references require three I/Os (double
indirect, indirect, and data).
Algorithm to retrieve a block
Let's say that you want to find block N
(N=0 is the "first" block) and that
There are D direct pointers in the inode numbered 0..(D-1)
There are K pointers in each indirect block numbered 0..K-1
If N < D // This is a direct block in the i-node
use direct pointer N in the i-node
else if N < D + K // This is one of the K blocks pointed to by indirect blk
use pointer D in the inode to get the indirect block
use pointer N-D in the indirect block to get block N
else // This is one of the K*K blocks obtained via the double indirect block
use pointer D+1 in the inode to get the double indirect block
let P = (N-(D+K)) DIV K // Which single indirect block to use
use pointer P to get the indirect block B
let Q = (N-(D+K)) MOD K // Which pointer in B to use
use pointer Q in B to get block N
6.3.3: Implementing Directories
Recall that a directory is a mapping that converts file (or
subdirectory) names to the files (or subdirectories) themselves.
Trivial File System (CP/M)
-
Only one directory in the system.
-
Directory entry contains pointers to disk blocks.
-
If need more blocks, get another directory entry.
MS-DOS and Windows (FAT)
-
Subdirectories supported.
-
Directory entry contains metatdata such as date and size
as well as pointer to first block.
-
The FAT has the pointers to the remaining blocks.
Unix/linux
-
Each entry contains a name and a pointer to the corresponding i-node.
-
Metadata is in the i-node.
-
Early unix had limit of 14 character names.
-
Name field now is varying length.
-
To go down a level in directory takes two steps: get i-node, get
file (or subdirectory).
-
This shows how important it is not to parse filenames for each I/O
operation, i.e., why the open() system call is important.
-
Do on the blackboard the steps for
/a/b/X
Homework: 27
6.3.4: Shared files (links)
- “Shared” files is Tanenbaum's terminology.
-
More descriptive would be “multinamed files”.
-
If a file exists, one can create another name for it (quite
possibly in another directory).
-
This is often called creating a (or another) link to the file.
-
Unix has two flavor of links, hard links and
symbolic links or symlinks.
-
Dos/windows has symlinks, but I don't believe it has hard links.
-
These links often cause confusion, but I really believe that the
diagrams I created make it all clear.
Hard Links
- Symmetric multinamed files.
-
When a hard like is created another name is created for
the same file.
-
The two names have equal status.
-
It is not, I repeat NOT, true that one
name is the “real name” and the other one is “just a link”.
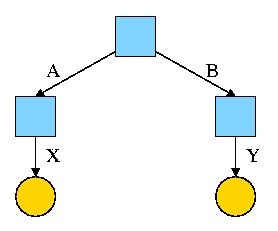
Start with an empty file system (i.e., just the root directory) and
then execute:
cd /
mkdir /A; mkdir /B
touch /A/X; touch /B/Y
We have the situation shown on the right.
-
Circles represent ordinary files.
-
Squares represent directories.
-
One name for the left circle is /A/X.
-
I have written the names on the edges.
- This is not customary, normally they are written in the
circles or squares.
- When there are no multi-named files, it doesn't matter if they
are written in the node or edge.
- We will see that when files can have multiple names it is much
better to write the name on the edge.
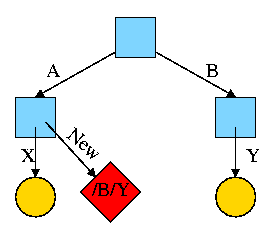
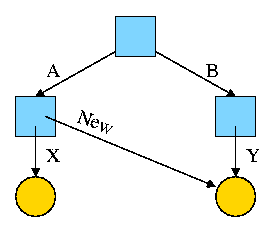 Now execute
Now execute
ln /B/Y /A/New
This gives the new diagram to the right.
At this point there are two equally valid name for the right hand
yellow file, /B/Y and /A/New. The fact that /B/Y was created first is
NOT detectable.
-
Both point to the same i-node.
-
Only one owner (the one who created the file initially).
-
One date, one set of permissions, one ... .
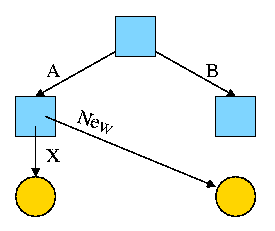
Assume Bob created /B and /B/Y and Alice created /A, /A/X, and /A/New.
Later Bob tires of /B/Y and removes it by executing
rm /B/Y
The file /A/New is still fine (see third diagram on the right).
But it is owned by Bob, who can't find it! If the system enforces
quotas bob will likely be charged (as the owner), but he can neither
find nor delete the file (since bob cannot unlink, i.e. remove, files
from /A)
Since hard links are only permitted to files (not directories) the
resulting file system is a dag (directed acyclic graph). That is, there
are no directed cycles. We will now proceed to give away this useful
property by studying symlinks, which can point to directories.
Symlinks
- Asymmetric multinamed files.
-
When a symlink is created another file is created.
The contents of the new file is the name
of the original file.
-
A hard link in contrast points to the original
file.
-
The examples will make this clear.
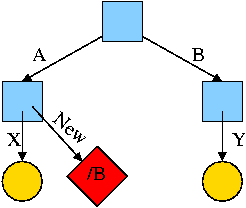
Again start with an empty file system and this time execute
cd /
mkdir /A; mkdir /B
touch /A/X; touch /B/Y
ln -s /B/Y /A/New
We now have an additional file /A/New, which is a symlink to /B/Y.
-
The file named /A/New has the name /B/Y as its data
(not metadata).
-
The system notices that A/New is a diamond (symlink) so reading
/A/New will return the contents of /B/Y (assuming the reader has read
permission for /B/Y).
-
If /B/Y is removed /A/New becomes invalid.
-
If a new /B/Y is created, A/New is once again valid.
-
Removing /A/New has no effect of /B/Y.
-
If a user has write permission for /B/Y, then writing /A/New is possible
and writes /B/Y.
The bottom line is that, with a hard link, a new name is created
for the file.
This new name has equal status with the original name.
This can cause some
surprises (e.g., you create a link but I own the file).
With a symbolic link a new file is created (owned by the
creator naturally) that contains the name of the original file.
We often say the new file points to the original file.
Question: Consider the hard link setup above. If Bob removes /B/Y
and then creates another /B/Y, what happens to /A/New?
Answer: Nothing. /A/New is still a file with the same contents as the
original /B/Y.
Question: What about with a symlink?
Answer: /A/New becomes invalid and then valid again, this time pointing
to the new /B/Y.
(It can't point to the old /B/Y as that is completely gone.)
Note:
Shortcuts in windows contain more that symlinks in unix. In addition
to the file name of the original file, they can contain arguments to
pass to the file if it is executable. So a shortcut to
netscape.exe
can specify
netscape.exe //allan.ultra.nyu.edu/~gottlieb/courses/os/class-notes.html
End of Note
What about symlinking a directory?
cd /
mkdir /A; mkdir /B
touch /A/X; touch /B/Y
ln -s /B /A/New
Is there a file named /A/New/Y ?
Yes.
What happens if you execute cd /A/New/.. ?
-
Answer: Not clear!
-
Clearly you are changing directory to the parent directory of
/A/New. But is that /A or /?
-
The command interpreter I use offers both possibilities.
- cd -L /A/New/.. takes you to A (L for logical).
- cd -P /A/New/.. takes you to / (P for physical).
- cd /A/New/.. takes you to A (logical is the default).
What did I mean when I said the pictures made it all clear?
Answer: From the file system perspective it is clear.
It is not always so clear what programs will do.
6.3.5: Disk space management
All general purpose systems use a (non-demand) paging
algorithm for file storage. Files are broken into fixed size pieces,
called blocks that can be scattered over the disk.
Note that although this is paging, it is never called paging.
The file is completely stored on the disk, i.e., it is not
demand paging.
Actually, it is more complicated
-
Various optimizations are
performed to try to have consecutive blocks of a single file stored
consecutively on the disk. Discussed
below
.
-
One can imagine systems that store only parts of the file on disk
with the rest on tertiary storage (some kind of tape).
-
This would be just like demand paging.
-
Perhaps NASA does this with their huge datasets.
-
Caching (as done for example in microprocessors) is also the same
as demand paging.
-
We unify these concepts in the computer architecture course.
Choice of block size
We discussed this last chapter
Storing free blocks
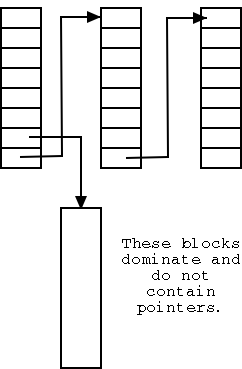
There are basically two possibilities
-
An in-memory bit map.
- One bit per block
- If block size is 4KB = 32K bits, 1 bit per 32K bits
- So 32GB disk (potentially all free) needs 1MB ram.
- Variation is to demand page the bit map. This saves space
(RAM) at the cost of I/O.
-
Linked list with each free block pointing to next.
- Thus you must do a read for each request.
- But reading a free block is a wasted I/O.
- Instead some free blocks contain pointers to other free
blocks. This has much less wasted I/O, but is more complicated.
- When read a block of pointers store them in memory.
- See diagram on right.
6.3.6: File System reliability
Bad blocks on disks
Not so much of a problem now. Disks are more reliable and, more
importantly, disks take care of the bad blocks themselves. That is,
there is no OS support needed to map out bad blocks. But if a block
goes bad, the data is lost (not always).
Backups
All modern systems support full and
incremental dumps.
-
A level 0 dump is a called a full dump (i.e., dumps everything).
-
A level n dump (n>0) is called an incremental dump and the
standard unix utility dumps
all files that have changed since the previous level n-1 dump.
-
Other dump utilities dump all files that have changed since the
last level n dump.
-
Keep on the disk the dates of the most recent level i dumps
for all i. In Unix this is traditionally in /etc/dumpdates.
-
What about the nodump attribute?
- Default policy (for Linux at least) is to dump such files
anyway when doing a full dump, but not dump them for incremental
dumps.
- Another way to say this is the nodump attribute is honored for
level n dumps if n>1.
- The dump command has an option to override the default policy
(can specify k so that nodump is honored for level n dumps if n>k).
Consistency
-
Fsck (file system check) and chkdsk (check disk)
- If the system crashed, it is possible that not all metadata was
written to disk. As a result the file system may be inconsistent.
These programs check, and often correct, inconsistencies.
- Scan all i-nodes (or fat) to check that each block is in exactly
one file, or on the free list, but not both.
- Also check that the number of links to each file (part of the
metadata in the file's i-node) is correct (by
looking at all directories).
- Other checks as well.
- Offers to “fix” the errors found (for most errors).
- “Journaling” file systems
- An idea from database theory (transaction logs).
- Vastly reduces the need for fsck.
- NTFS has had journaling from day 1.
- Many Unix systems have it. IBM's AIX converted to journaling
in the early 90s.
- Linux distributions now have journaling (2001-2002).
- FAT does not have journaling.
6.3.7 File System Performance
Buffer cache or block cache
An in-memory cache of disk blocks.
-
Demand paging again!
-
Clearly good for reads as it is much faster to read memory than to
read a disk.
-
What about writes?
- Must update the buffer cache (otherwise subsequent reads will
return the old value).
- The major question is whether the system should also update
the disk block.
- The simplest alternative is write through
in which each write is performed at the disk before it declared
complete.
- Since floppy disk drivers adopt a write through policy,
one can remove a floppy as soon as an operation is complete.
- Write through results in heavy I/O write traffic.
- If a block is written many times all the writes are
sent the disk. Only the last one was “needed”.
- If a temporary file is created, written, read, and
deleted, all the disk writes were wasted.
- DOS uses write-through
- The other alternative is write back in which
the disk is not updated until the in-memory copy is
evicted (i.e., at replacement time).
- Much less write traffic than write through.
- Trouble if a crash occurs.
- Used by Unix and others for hard disks.
- Can write dirty blocks periodically, say every minute.
This limits the possible damage, but also the possible gain.
- Ordered writes. Do not write a block containing pointers
until the block pointed to has been written. Especially if
the block pointed to contains pointers since the version of
these pointers on disk may be wrong and you are giving a file
pointers to some random blocks.--unofficial for 202
Homework: 29.
Block Read Ahead
When the access pattern “looks” sequential read ahead is employed.
This means that after completing a read() request for block n of a file.
The system guesses that a read() request for block n+1 will shortly be
issued so it automatically fetches block n+1.
-
How do you decide that the access pattern looks sequential?
- If a seek system call is issued, the access pattern is not
sequential.
- If a process issues consecutive read() system calls for block
n-1 and then n, the access patters is
guessed to be sequential.
-
What if block n+1 is already in the block cache?
Ans: Don't issue the read ahead.
-
Would it be reasonable to read ahead two or three blocks?
Ans: Yes.
-
Would it be reasonable to read ahead the entire file?
Ans: No, it could easily pollute the cache evicting needed blocks and
could waste considerable disk bandwidth.
Reducing Disk Arm Motion
Try to place near each other blocks that are going to be read in
succession.
-
If the system uses a bitmap for the free list, it can
allocate a new block for a file close to the previous block
(guessing that the file will be accessed sequentially).
-
The system can perform allocations in “super-blocks”, consisting
of several contiguous blocks.
-
Block cache and I/O requests are still in blocks.
-
If the file is accessed sequentially, consecutive blocks of a
super-block will be accessed in sequence and these are
contiguous on the disk.
-
For a unix-like file system, the i-nodes can be placed in the
middle of the disk, instead of at one end, to reduce the seek time
to access an i-node followed by a block of the file.
-
Can divide the disk into cylinder groups, each
of which is a consecutive group of cylinders.
-
Each cylinder group has its own free list and, for a unix-like
file system, its own space for i-nodes.
-
If possible, the blocks for a file are allocated in the same
cylinder group as is the i-node.
-
This reduces seek time if consecutive accesses are for the
same file.
6.3.8: Log-Structured File Systems (unofficial)
A file system that tries to make all writes sequential.
That is, writes are treated as if going to a log file.
The original research project worked with a unix-like file system,
i.e. was i-node based.
-
Assumption is that large block caches will eliminate most disk
reads so we need to improve writes.
-
Buffer writes until have (say) 1MB to write.
-
When the buffer is full, write it to the end of the disk (treating
the disk as a log).
-
Thus writes are sequential and hence fast
-
The 1MB units on the disk are called (unfortunately) segments.
I will refer to the buffer as the segment buffer.
-
A segment can have i-nodes, direct blocks, indirect blocks,
blocks forming part of a file, blocks forming part of a directory.
In short a segment contains the most recently modified (or
created) 1MB of blocks.
-
Note that modified blocks are not reclaimed!
-
The system keeps a map of where the most recent version of each
i-node is located. The map is on disk (but the heavily accessed
parts will be in the block cache.
-
So the (most up to date) i-node of a file can be found and from
that the entire file can be found.
-
But the disk will fill with garbage since modified blocks are not
reclaimed.
-
A “cleaner” process runs in the background and examines
segments starting from the beginning.
It removes overwritten blocks and then adds the remaining blocks
to the segment buffer. (This is not trivial.)
-
Thus the disk is compacted and is treated like a circular array of
segments.
6.4: Example File Systems
6.4.1: CD-ROM File Systems (skipped)
6.4.2: The CP/M File System
This was done above.
6.4.3: The MS-DOS File System
This was done above.
6.4.4: The windows 98 File System
Two changes were made: Long file names were supported and the
allocation table was switched from FAT-16 to FAT-32.
-
The only hard part was to keep compatibility with the old 8.3
naming rule. This is called “backwards compatibility”.
A file has two name a long one and an 8.3. If the long name fits
the 8.3 format, only one name is kept. If the long name does not
fit the 8+3, an 8+3 version is produce via an algorithm, that
works but the names produced are not lovely.
-
FAT-32 used 32 bit words for the block numbers so the fat table
could be huge. Windows 98 kept only a portion of the FAT-32 table
in memory at a time. (I do not know the replacement policy,
number of blocks kept in memory, etc).
6.4.5: The Unix V7 File System
This was done above.
6.5: Research on File Systems (skipped)
6.6 Summary (read)
The End: Good luck on the final