Operating Systems
================ Start Lecture #13 ================
Minimizing Rotational Latency
Use Scan based on sector numbers not cylinder number. For
rotational latency Scan is the same as C-Scan. Why?
Ans: Because the disk only rotates in one direction.
Homework: 24, 25
5.4.4: Error Handling
Disks error rates have dropped in recent years. Moreover, bad
block forwarding is normally done by the controller (or disk electronics) so
this topic is no longer as important for OS.
5.5: Clocks
Also called timers.
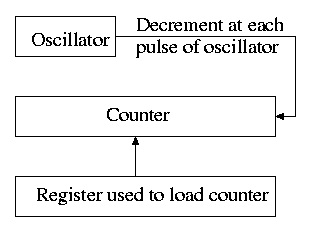
5.5.1: Clock Hardware
-
Generates an interrupt when timer goes to zero
-
Counter reload can be automatic or under software (OS) control.
-
If done automatically, the interrupt occurs periodically and thus
is perfect for generating a clock interrupt at a fixed period.
5.5.2: Clock Software
-
Time of day (TOD): Bump a counter each tick (clock interupt). If
counter is only 32 bits must worry about overflow so keep two
counters: low order and high order.
-
Time quantum for RR: Decrement a counter at each tick. The quantum
expires when counter is zero. Load this counter when the scheduler
runs a process (i.e., changes the state of the process from ready to
running).
This is presumably what you did for the (processor) scheduling
lab.
-
Accounting: At each tick, bump a counter in the process table
entry for the currently running process.
-
 Alarm system call and system alarms:
Alarm system call and system alarms:
-
Users can request an alarm at some future time.
-
The system also on occasion needs to schedule some of its own
activities to occur at specific times in the future (e.g. turn off
the floppy motor).
-
The conceptually simplest solution is to have one timer for
each event.
-
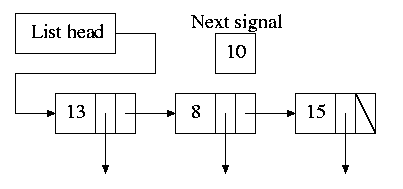
Instead, we simulate many timers with just one.
-
The data structure on the right works well. There is one node
for each event.
-
The first entry in each node is the time after the
preceding event that this event's alarm is to ring.
-
For example, if the time is zero, this event occurs at the
same time as the previous event.
-
The second entry in the node is a pointer to the action to perform.
-
At each tick, decrement next-signal.
-
When next-signal goes to zero,
process the first entry on the list and any others following
immediately following with a time of zero (which means they
are to be simultaneous with this alarm).
Then set next-signal to the value
in the next alarm.
-
Profiling
-
Want a histogram giving how much time was spent in each 1KB
(say) block of code.
-
At each tick check the PC and bump the appropriate counter.
-
A user-mode program can determine the software module
associated with each 1K block.
-
If we use finer granularity (say 10B instead of 1KB), we get
increased accuracy but more memory overhead.
Homework: 27
5.6: Character-Oriented Terminals
5.6.1: RS-232 Terminal Hardware
Quite dated. It is true that modern systems can communicate to a
hardwired ascii terminal, but most don't. Serial ports are used, but
they are normally connected to modems and then some protocol (SLIP,
PPP) is used not just a stream of ascii characters. So skip this
section.
Memory-Mapped Terminals
Not as dated as the previous section but it still discusses the
character not graphics interface.
-
Today, software writes into video memory
the bits that are to be put on the screen and then the graphics
controller
converts these bits to analog signals for the monitor (actually laptop
displays and some modern monitors are digital).
-
But it is much more complicated than this. The graphics
controllers can do a great deal of video themselves (like filling).
-
This is a subject that would take many lectures to do well.
Keyboards
Tanenbaum description of keyboards is correct.
-
At each key press and key release a code is written into the
keyboard controller and the computer is interrupted.
-
By remembering which keys have been depressed and not released
the software can determine Cntl-A, Shift-B, etc.
5.6.2: Input Software
-
We are just looking at keyboard input. Once again graphics is too
involved to be treated well.
-
There are two fundamental modes of input, sometimes called
raw and cooked.
-
In raw mode the application sees every “character” the user
types. Indeed, raw mode is character oriented.
-
All the OS does is convert the keyboard “scan
codes” to “characters” and and pass these
characters to the application.
-
Some examples
-
down-cntl down-x up-x up-cntl is converted to cntl-x
-
down-cntl up-cntl down-x up-x is converted to x
-
down-cntl down-x up-cntl up-x is converted to cntl-x (I just
tried it to be sure).
-
down-x down-cntl up-x up-cntl is converted to x
-
Full screen editors use this mode.
-
Cooked mode is line oriented. The OS delivers lines to the
application program.
-
Special characters are interpreted as editing characters
(erase-previous-character, erase-previous-word, kill-line, etc).
-
Erased characters are not seen by the application but are
erased by the keyboard driver.
-
Need an escape character so that the editing characters can be
passed to the application if desired.
-
The cooked characters must be echoed (what should one do if the
application is also generating output at this time?)
-
The (possibly cooked) characters must be buffered until the
application issues a read (and an end-of-line EOL has been
received for cooked mode).
5.6.3: Output Software
Again too dated and the truth is too complicated to deal with in a
few minutes.
5.7: Graphical User Interfaces (GUIs)
Skipped.
5.8: Network Terminals
Skipped.
5.9: Power Management
Skipped.
5.10: Research on Input/Output
Skipped.
5.11: Summary
Read.
Chapter 6: File Systems
Requirements
-
Size: Store very large amounts of data.
-
Persistence: Data survives the creating process.
-
Access: Multiple processes can access the data concurrently.
Solution: Store data in files that together form a file system.
6.1: Files
6.1.1: File Naming
Very important. A major function of the file system.
-
Does each file have a unique name?
Answer: Often no. We will discuss this below when we study
links.
-
Extensions, e.g. the “html” in
“class-notes.html”.
Depending on the system, these can have little or great
significance.
The extensions can be
-
Conventions just for humans: letter.teq (my convention).
-
Conventions giving default behavior for some programs.
-
The emacs editor thinks .html files should be edited in
html mode but
can edit them in any mode and can edit any file
in html mode.
-
Firefox thinks .html means an html file, but
<html> ... </html> works as well
-
Gzip thinks .gz means a compressed file but accepts a
--suffix flag
-
Default behavior for Operating system or window manager or
desktop environment.
-
Click on .xls file in windows and excel is started.
-
Click on .xls file in nautilus under linux and open office
is started.
-
Required extensions for programs
-
The gnu C compiler (and probably others) requires C
programs be named *.c and assembler programs be named *.s
-
Required extensions by operating systems
-
MS-DOS treats .com files specially
-
Windows 95 requires (as far as I could tell) shortcuts to
end in .lnk.
-
Case sensitive?
Unix: yes. Windows: no.
6.1.2: File structure
A file is a
-
Byte stream
-
Unix, dos, windows.
-
Maximum flexibility.
-
Minimum structure.
- (fixed size) Record stream: Out of date
-
80-character records for card images.
-
133-character records for line printer files. Column 1 was
for control (e.g., new page) Remaining 132 characters were
printed.
-
Varied and complicated beast.
-
Indexed sequential.
-
B-trees.
-
Supports rapidly finding a record with a specific
key.
-
Supports retrieving (varying size) records in key order.
-
Treated in depth in database courses.
6.1.3: File types
Examples
- (Regular) files.
-
Directories: studied below.
-
Special files (for devices).
Uses the naming power of files to unify many actions.
dir # prints on screen
dir > file # result put in a file
dir > /dev/tape # results written to tape
-
“Symbolic” Links (similar to “shortcuts”): Also studied
below.
“Magic number”: Identifies an executable file.
-
There can be several different magic numbers for different types
of executables.
- unix: #!/usr/bin/perl
Strongly typed files:
-
The type of the file determines what you can do with the
file.
-
This make the easy and (hopefully) common case easier and, more
importantly, safer.
-
It tends to make the unusual case harder. For example, you have a
program that turns out data (.dat) files. But you want to use it to
turn out a java file but the type of the output is data and cannot be
easily converted to type java.
6.1.4: File access
There are basically two possibilities, sequential access and random
access (a.k.a. direct access).
Previously, files were declared to be sequential or random.
Modern systems do not do this.
Instead all files are random and optimizations are applied when the
system dynamically determines that a file is (probably) being accessed
sequentially.
-
With Sequential access the bytes (or records)
are accessed in order (i.e., n-1, n, n+1, ...).
Sequential access is the most common and
gives the highest performance.
For some devices (e.g. tapes) access “must” be sequential.
-
With random access, the bytes are accessed in any
order. Thus each access must specify which bytes are desired.
6.1.5: File attributes
A laundry list of properties that can be specified for a file
For example:
-
hidden
-
do not dump
-
owner
-
key length (for keyed files)
6.1.6: File operations
-
Create:
Essential if a system is to add files. Need not be a separate system
call (can be merged with open).
-
Delete:
Essential if a system is to delete files.
-
Open:
Not essential. An optimization in which the translation from file name to
disk locations is perform only once per file rather than once per access.
-
Close:
Not essential. Free resources.
-
Read:
Essential. Must specify filename, file location, number of bytes,
and a buffer into which the data is to be placed.
Several of these parameters can be set by other
system calls and in many OS's they are.
-
Write:
Essential if updates are to be supported. See read for parameters.
-
Seek:
Not essential (could be in read/write). Specify the
offset of the next (read or write) access to this file.
-
Get attributes:
Essential if attributes are to be used.
-
Set attributes:
Essential if attributes are to be user settable.
-
Rename:
Tanenbaum has strange words. Copy and delete is not acceptable for
big files. Moreover copy-delete is not atomic. Indeed link-delete is
not atomic so even if link (discussed below)
is provided, renaming a file adds functionality.
Homework: 6, 7.
6.1.7: An Example Program Using File System Calls
Homework: Read and understand “copyfile”.
Notes on copyfile
-
Normally in unix one wouldn't call read and write directly.
-
Indeed, for copyfile, getchar() and putchar() would be nice since
they take care of the buffering (standard I/O, stdio).
-
If you compare copyfile from the 1st to 2nd edition, you can see
the addition of error checks.
6.1.8: Memory mapped files (Unofficial)
Conceptually simple and elegant. Associate a segment with each
file and then normal memory operations take the place of I/O.
Thus copyfile does not have fgetc/fputc (or read/write). Instead it is
just like memcopy
while ( *(dest++) = *(src++) );
The implementation is via segmentation with demand paging but
the backing store for the pages is the file itself.
This all sounds great but ...
-
How do you tell the length of a newly created file? You know
which pages were written but not what words in those pages. So a file
with one byte or 10, looks like a page.
-
What if same file is accessed by both I/O and memory mapping.
-
What if the file is bigger than the size of virtual memory (will
not be a problem for systems built 3 years from now as all will have
enormous virtual memory sizes).
6.2: Directories
Unit of organization.
6.2.1-6.2.3: Single-level, Two-level, and Hierarchical directory systems
Possibilities
-
One directory in the system (Single-level)
-
One per user and a root above these (Two-level)
-
One tree
-
One tree per user
-
One forest
-
One forest per user
These are not as wildly different as they sound.
-
If the system only has one directory, but allows the character /
in a file name. Then one could fake a tree by having a file named
/allan/gottlieb/courses/arch/class-notes.html
rather than a
directory allan, a subdirectory gottlieb, ..., a file
class-notes.html.
-
Dos (windows) is a forest, unix a tree. In dos there is no common
parent of a:\ and c:\.
-
But windows explorer makes the dos forest look quite a bit like a
tree.
-
You can get an effect similar to (but not the same as) one X per
user by having just one X in the system and having permissions
that permits each user to visit only a subset. Of course if the
system doesn't have permissions, this is not possible.
-
Today's systems have a tree per system or a forest per system.
6.2.4: Path Names
You can specify the location of a file in the file hierarchy by
using either an absolute or a
Relative path to the file
-
An absolute path starts at the (or “one of the”, if we have a
forest) root(s).
-
A relative path starts at the
current (a.k.a working) directory.
-
The special directories . and .. represent the current directory
and the parent of the current directory respectively.
Homework: 1, 9.
6.2.5: Directory operations
-
Create: Produces an “empty” directory.
Normally the directory created actually contains . and .., so is not
really empty
-
Delete: Requires the directory to be empty (i.e., to just contain
. and ..). Commands are normally written that will first empty the
directory (except for . and ..) and then delete it. These commands
make use of file and directory delete system calls.
-
Opendir: Same as for files (creates a “handle”)
-
Closedir: Same as for files
-
Readdir: In the old days (of unix) one could read directories as files
so there was no special readdir (or opendir/closedir). It was
believed that the uniform treatment would make programming (or at
least system understanding) easier as there was less to learn.
However, experience has taught that this was not a good idea since
the structure of directories then becomes exposed. Early unix had a
simple structure (and there was only one type of structure for all
implementations).
Modern systems have more
sophisticated structures and more importantly they are not fixed
across implementations.
-
Rename: As with files
-
Link: Add a second name for a file; discussed
below.
-
Unlink: Remove a directory entry. This is how a file is deleted.
But if there are many links and just one is unlinked, the file
remains. Discussed in more
detail below.
6.3: File System Implementation
6.3.1: File System Layout
-
One disk starts with a Master Boot Record (MBR).
-
Each disk has a partition table.
-
Each partition holds one file system.
-
Each partition typically contains some parameters (e.g., size),
free blocks, and blocks in use. The details vary.
-
In unix some of the in use blocks contains I-nodes each of which
describes a file or directory and is described below.
-
During boot the MBR is read and executed. It transfers control to
the boot block of the active partition.
6.3.2: Implementing Files
-
A disk cannot read or write a single word. Instead it can read or
write a sector, which is often 512 bytes.
-
Disks are written in blocks whose size is a multiple of the sector
size.
Contiguous allocation
-
This is like OS/MVT.
-
The entire file is stored as one piece.
-
Simple and fast for access, but ...
-
Problem with growing files
- Must either evict the file itself or the file it is bumping
into.
- Same problem with an OS/MVT kind of system if jobs grow.
-
Problem with external fragmentation.
-
No longer used for general purpose rewritable file systems.
-
Ideal for file systems where files do not change size.
-
Used for CD-ROM file systems.
Homework: 12.
Linked allocation
-
The directory entry contains a pointer to the first block of the file.
-
Each block contains a pointer to the next.
-
Horrible for random access.
-
Not used.
FAT (file allocation table)
-
Used by dos and windows (but NT/2000/XP also support the superior NTFS)
-
Directory entry points to first block (i.e. specifies the block
number).
-
A FAT is maintained in memory having one (word) entry for each
disk block. The entry for block N contains the block number of the
next block in the same file as N.
-
This is linked but the links are stored separately.
-
Time to access a random block is still is linear in size of file
but now all the references are to this one table which is in memory.
So it is bad but not horrible for random access.
-
Size of table is one word per disk block. If blocks are of size
4K and the FAT uses 4-byte words, the table is one megabyte for
each disk gigabyte. Large but perhaps not prohibitive.
-
If blocks are of size 512 bytes (the sector size of most disks)
then the table is 8 megs per gig, which is probably prohibitive.