Operating Systems
================ Start Lecture #3 ================
Notes
-
I will accept solutions to homework 1 (but not homework 2)
next time.
This is because a few students joined the class late.
-
Show password homework solutions.
1.7: OS Structure
I must note that Tanenbaum is a big advocate of the so called
microkernel approach in which as much as possible is moved out of the
(supervisor mode) kernel into separate processes. The (hopefully
small) portion left in supervisor mode is called a microkernel.
In the early 90s this was popular. Digital Unix (now called True64)
and Windows NT/2000/XP are examples. Digital Unix is based on Mach, a
research OS from Carnegie Mellon university. Lately, the growing
popularity of Linux has called into question the belief that “all new
operating systems will be microkernel based”.
1.7.1: Monolithic approach
The previous picture: one big program
The system switches from user mode to kernel mode during the poof and
then back when the OS does a “return” (an RTI or return from interrupt).
But of course we can structure the system better, which brings us to.
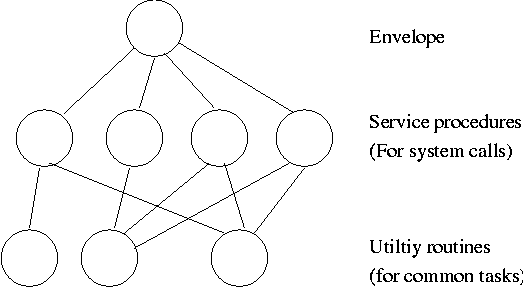
1.7.2: Layered Systems
Some systems have more layers and are more strictly structured.
An early layered system was “THE” operating system by Dijkstra. The
layers were.
- The operator
- User programs
- I/O mgt
- Operator-process communication
- Memory and drum management
The layering was done by convention, i.e. there was no enforcement by
hardware and the entire OS is linked together as one program. This is
true of many modern OS systems as well (e.g., linux).
The multics system was layered in a more formal manner. The hardware
provided several protection layers and the OS used them. That is,
arbitrary code could not jump to or access data in a more protected layer.
1.7.3: Virtual Machines
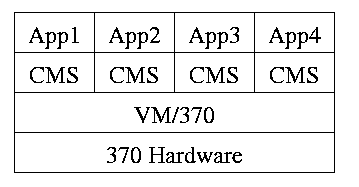
Use a “hypervisor” (beyond supervisor, i.e. beyond a normal OS) to
switch between multiple Operating Systems. Made popular by
IBM's VM/CMS
-
Each App/CMS runs on a virtual 370.
-
CMS is a single user OS.
-
A system call in an App (application) traps to the corresponding CMS.
-
CMS believes it is running on the machine so issues I/O.
instructions but ...
-
... I/O instructions in CMS trap to VM/370.
-
This idea is still used.
A modern version (used to “produce” a multiprocessor from many
uniprocessors) is “Cellular Disco”, ACM TOCS, Aug. 2000.
- Another modern usage is JVM the “Java Virtual Machine”.
1.7.4: Exokernels (unofficial)
Similar to VM/CMS but the virtual machines have disjoint resources
(e.g., distinct disk blocks) so less remapping is needed.
1.7.5: Client-Server

When implemented on one computer, a client-server OS uses the
microkernel approach in which the microkernel just handles
communication between clients and servers, and the main OS functions
are provided by a number of separate processes.
This does have advantages. For example an error in the file server
cannot corrupt memory in the process server. This makes errors easier
to track down.
But it does mean that when a (real) user process makes a system call
there are more processes switches. These are
not free.
A distributed system can be thought of as an extension of the
client server concept where the servers are remote.
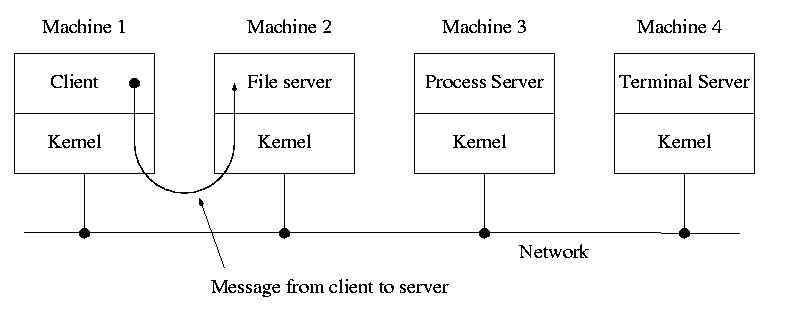
Today with plentiful memory, each machine would have all the
different servers. So the only reason a message would go to another
computer is if the originating process wished to communicate with a
specific process on that computer (for example wanted to access a
remote disk).
Homework: 23
Microkernels Not So Different In Practice
Dennis Ritchie, the inventor of the C programming language and
co-inventor, with Ken Thompson, of Unix was interviewed in February
2003. The following is from that interview.
What's your opinion on microkernels vs. monolithic?
Dennis Ritchie: They're not all that different when you actually
use them. "Micro" kernels tend to be pretty large these days, and
"monolithic" kernels with loadable device drivers are taking up more
of the advantages claimed for microkernels.
Chapter 2: Process and Thread Management
Tanenbaum's chapter title is “Processes and Threads”.
I prefer to add the word management. The subject matter is processes,
threads, scheduling, interrupt handling, and IPC (InterProcess
Communication--and Coordination).
2.1: Processes
Definition: A process is a
program in execution.
-
We are assuming a multiprogramming OS that
can switch from one process to another.
-
Sometimes this is
called pseudoparallelism since one has the illusion of a
parallel processor.
-
The other possibility is real
parallelism in which two or more processes are actually running
at once because the computer system is a parallel processor, i.e., has
more than one processor.
-
We do not study real parallelism (parallel
processing, distributed systems, multiprocessors, etc) in this course.
2.1.1: The Process Model
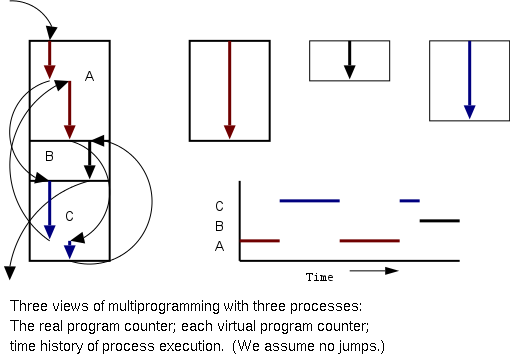
Even though in actuality there are many processes running at once, the
OS gives each process the illusion that it is running alone.
-
Virtual time: The time used by just this
processes. Virtual time progresses at
a rate independent of other processes. Actually, this is false, the
virtual time is
typically incremented a little during systems calls used for process
switching; so if there are more other processors more “overhead”
virtual time occurs.
-
Virtual memory:
The memory as viewed by the
process. Each process typically believes it has a contiguous chunk of
memory starting at location zero. Of course this can't be true of all
processes (or they would be using the same memory) and in modern
systems it is actually true of no processes (the memory assigned is
not contiguous and does not include location zero).
Think of the individual modules that are input to the linker.
Each numbers its addresses from zero;
the linker eventually translates these relative addresses into
absolute addresses.
That is the linker provides to the assembler a virtual memory in which
addresses start at zero.
Virtual time and virtual memory are examples of abstractions
provided by the operating system to the user processes so that the
latter “sees” a more pleasant virtual machine than actually exists.
2.1.2: Process Creation
From the users or external viewpoint there are several mechanisms
for creating a process.
-
System initialization, including daemon (see below) processes.
-
Execution of a process creation system call by a running process.
-
A user request to create a new process.
-
Initiation of a batch job.
But looked at internally, from the system's viewpoint, the second
method dominates. Indeed in unix only one process is created at
system initialization (the process is called init); all the
others are children of this first process.
Why have init? That is why not have all processes created via
method 2?
Ans: Because without init there would be no running process to create
any others.
Definition of daemon
Many systems have daemon process lurking around to perform
tasks when they are needed.
I was pretty sure the terminology was
related to mythology, but didn't have a reference until
a student found
“The {Searchable} Jargon Lexicon”
at http://developer.syndetic.org/query_jargon.pl?term=demon
daemon: /day'mn/ or /dee'mn/ n. [from the mythological meaning, later
rationalized as the acronym `Disk And Execution MONitor'] A program
that is not invoked explicitly, but lies dormant waiting for some
condition(s) to occur. The idea is that the perpetrator of the
condition need not be aware that a daemon is lurking (though often a
program will commit an action only because it knows that it will
implicitly invoke a daemon). For example, under {ITS}, writing a file
on the LPT spooler's directory would invoke the spooling daemon, which
would then print the file. The advantage is that programs wanting (in
this example) files printed need neither compete for access to nor
understand any idiosyncrasies of the LPT. They simply enter their
implicit requests and let the daemon decide what to do with
them. Daemons are usually spawned automatically by the system, and may
either live forever or be regenerated at intervals. Daemon and demon
are often used interchangeably, but seem to have distinct
connotations. The term `daemon' was introduced to computing by CTSS
people (who pronounced it /dee'mon/) and used it to refer to what ITS
called a dragon; the prototype was a program called DAEMON that
automatically made tape backups of the file system. Although the
meaning and the pronunciation have drifted, we think this glossary
reflects current (2000) usage.
2.1.3: Process Termination
Again from the outside there appear to be several termination
mechanism.
-
Normal exit (voluntary).
-
Error exit (voluntary).
-
Fatal error (involuntary).
-
Killed by another process (involuntary).
And again, internally the situation is simpler. In Unix
terminology, there are two system calls kill and
exit that are used. Kill (poorly named in my view) sends a
signal to another process. If this signal is not caught (via the
signal system call) the process is terminated. There
is also an “uncatchable” signal. Exit is used for self termination
and can indicate success or failure.
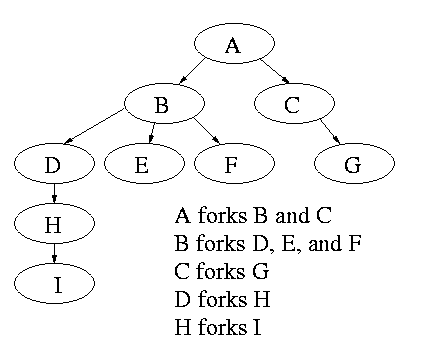
2.1.4: Process Hierarchies
Modern general purpose operating systems permit a user to create and
destroy processes.
-
In unix this is done by the fork
system call, which creates a child process, and the
exit system call, which terminates the current
process.
-
After a fork both parent and child keep running (indeed they
have the same program text) and each can fork off other
processes.
-
A process tree results. The root of the tree is a special
process created by the OS during startup.
-
A process can choose to wait for children to terminate.
For example, if C issued a wait() system call it would block until G
finished.
Old or primitive operating system like MS-DOS are not fully
multiprogrammed, so when one process starts another, the first process
is automatically blocked and waits until the second is
finished.
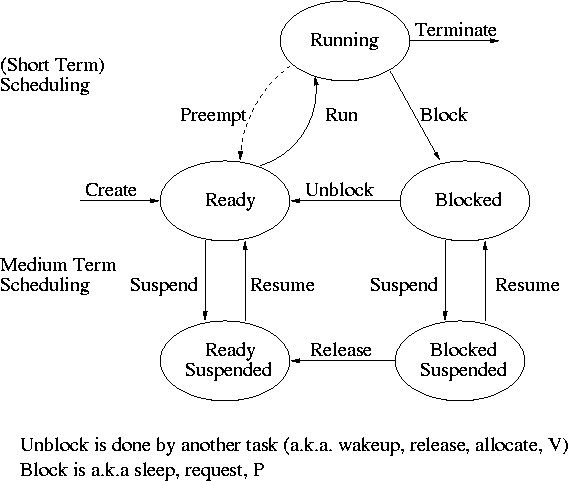
2.1.5: Process States and Transitions
The diagram on the right contains much information.
-
Consider a running process P that issues an I/O request
-
The process blocks
-
At some later point, a disk interrupt occurs and the driver
detects that P's request is satisfied.
-
P is unblocked, i.e. is moved from blocked to ready
-
At some later time the operating system scheduler looks for a
ready job to run and picks P.
-
A preemptive scheduler has the dotted line preempt;
A non-preemptive scheduler doesn't.
-
The number of processes changes only for two arcs: create and
terminate.
-
Suspend and resume are medium term scheduling
-
Done on a longer time scale.
-
Involves memory management as well.
As a result we study it later.
-
Sometimes called two level scheduling.
Homework: 1.
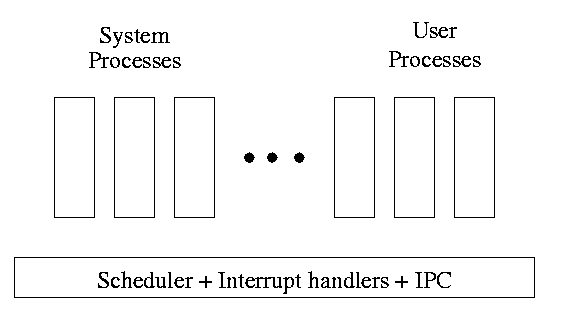 One can organize an OS around the scheduler.
One can organize an OS around the scheduler.
-
Write a minimal “kernel” (a micro-kernel) consisting of the
scheduler, interrupt handlers, and IPC (interprocess
communication).
-
The rest of the OS consists of kernel processes (e.g. memory,
filesystem) that act as servers for the user processes (which of
course act as clients).
-
The system processes also act as clients (of other system processes).
-
The above is called the client-server model and is one Tanenbaum likes.
His “Minix” operating system works this way.
-
Indeed, there was reason to believe that the client-server model
would dominate OS design.
But that hasn't happened.
-
Such an OS is sometimes called server based.
-
Systems like traditional unix or linux would then be
called self-service since the user process serves itself.
-
That is, the user process switches to kernel mode and performs
the system call.
-
To repeat: the same process changes back and forth from/to
user<-->system mode and services itself.
2.1.6: Implementation of Processes
The OS organizes the data about each process in a table naturally
called the process table.
Each entry in this table is called a
process table entry (PTE) or
process control block.
-
One entry per process.
-
The central data structure for process management.
-
A process state transition (e.g., moving from blocked to ready) is
reflected by a change in the value of one or more
fields in the PTE.
-
We have converted an active entity (process) into a data structure
(PTE). Finkel calls this the level principle “an active
entity becomes a data structure when looked at from a lower level”.
-
The PTE contains a great deal of information about the process.
For example,
-
Saved value of registers when process not running
-
Program counter (i.e., the address of the next instruction)
-
Stack pointer
-
CPU time used
-
Process id (PID)
-
Process id of parent (PPID)
-
User id (uid and euid)
-
Group id (gid and egid)
-
Pointer to text segment (memory for the program text)
-
Pointer to data segment
-
Pointer to stack segment
-
UMASK (default permissions for new files)
-
Current working directory
-
Many others
2.1.6A: An addendum on Interrupts
This should be compared with the addendum on
transfer of control.
In a well defined location in memory (specified by the hardware) the
OS stores an interrupt vector, which contains the
address of the (first level) interrupt handler.
-
Tanenbaum calls the interrupt handler the interrupt service routine.
-
Actually one can have different priorities of interrupts and the
interrupt vector contains one pointer for each level. This is why
it is called a vector.
Assume a process P is running and a disk interrupt occurs for the
completion of a disk read previously issued by process Q, which is
currently blocked.
Note that disk interrupts are unlikely to be for the currently running
process (because the process that initiated the disk access is likely
blocked).
Actions by P prior to the interrupt:
-
Who knows??
This is the difficulty of debugging code depending on interrupts,
the interrupt can occur (almost) anywhere. Thus, we do not
know what happened just before the interrupt.
Executing the interrupt itself:
-
The hardware saves the program counter and some other registers
(or switches to using another set of registers, the exact mechanism is
machine dependent).
-
Hardware loads new program counter from the interrupt vector.
-
Loading the program counter causes a jump.
-
Steps 2 and 3 are similar to a procedure call.
But the interrupt is asynchronous.
-
As with a trap, the hardware automatically switches the system
into privileged mode.
(It might have been in supervisor mode already, that is an
interrupt can occur in supervisor mode).
Actions by the interrupt handler (et al) upon being activated
-
An assembly language routine saves registers.
-
The assembly routine sets up new stack.
(These last two steps are often called setting up the C environment.)
-
The assembly routine calls a procedure in a high level language,
often the C language (Tanenbaum forgot this step).
-
The C procedure does the real work.
-
Determines what caused the interrupt (in this case a disk
completed an I/O)
- How does it figure out the cause?
-
It might know the priority of the interrupt being activated.
-
The controller might write information in memory
before the interrupt
-
The OS can read registers in the controller
- Mark process Q as ready to run.
-
That is move Q to the ready list (note that again
we are viewing Q as a data structure).
-
The state of Q is now ready (it was blocked before).
-
The code that Q needs to run initially is likely to be OS
code. For example, Q probably needs to copy the data just
read from a kernel buffer into user space.
-
Now we have at least two processes ready to run, namely P and
Q.
There may be arbitrarily many others.
-
The scheduler decides which process to run (P or Q or
something else).
This loosely corresponds to g calling other procedures in the
simple f calls g case we discussed previously.
Eventually the scheduler decides to run P.
Actions by P when control returns
-
The C procedure (that did the real work in the interrupt
processing) continues and returns to the assembly code.
-
Assembly language restores P's state (e.g., registers) and starts
P at the point it was when the interrupt occurred.
Properties of interrupts
-
Phew.
-
Unpredictable (to an extent).
We cannot tell what was executed just before the interrupt
occurred.
That is, the control transfer is asynchronous; it is difficult to
ensure that everything is always prepared for the transfer.
-
The user code is unaware of the difficulty and cannot
(easily) detect that it occurred.
This is another example of the OS presenting the user with a
virtual machine environment that is more pleasant than reality (in
this case synchronous rather asynchronous behavior).
-
Interrupts can also occur when the OS itself is executing.
This can cause difficulties since both the main line code
and the interrupt handling code are from the same
“program”, namely the OS, and hence might well be
using the same variables.
We will soon see how this can cause great problems even in what
appear to be trivial cases.
-
The interprocess control transfer is neither stack-like
nor queue-like.
That is if first P was running, then Q was running, then R was
running, then S was running, the next process to be run might be
any of P, Q, or R (or some other process).
-
The system might have been in user-mode or supervisor mode when
the interrupt occurred.
The interrupt processing starts in supervisor mode.
2.2: Threads
| Per process items | Per thread items
|
|---|
| Address space | Program counter
|
| Global variables | Machine registers
|
| Open files | Stack
|
| Child processes
|
| Pending alarms
|
| Signals and signal handlers
|
| Accounting information
|
The idea is to have separate threads of control (hence the name)
running in the same address space.
An address space is a memory management concept.
For now think of an address space as the memory in which a process
runs and the mapping from the virtual addresses (addresses in the
program) to the physical addresses (addresses in the machine).
Each thread is somewhat like a
process (e.g., it is scheduled to run) but contains less state
(e.g., the address space belongs to the process in which the thread
runs.
2.2.1: The Thread Model
A process contains a number of resources such as address space,
open files, accounting information, etc. In addition to these
resources, a process has a thread of control, e.g., program counter,
register contents, stack. The idea of threads is to permit multiple
threads of control to execute within one process. This is often
called multithreading and threads are often called
lightweight processes. Because threads in the same
process share so much state, switching between them is much less
expensive than switching between separate processes.
Individual threads within the same process are not completely
independent. For example there is no memory protection between them.
This is typically not a security problem as the threads are
cooperating and all are from the same user (indeed the same process).
However, the shared resources do make debugging harder. For example
one thread can easily overwrite data needed by another and if one thread
closes a file other threads can't read from it.