Operating Systems
================ Start Lecture #1 ================
G22.2250 Operating Systems
2004-05 Fall
Allan Gottlieb
Tuesday 5-6:50pm Rm 109 Ciww
Chapter -1: Administrivia
I start at -1 so that when we get to chapter 1, the numbering will
agree with the text.
(-1).1: Contact Information
- gottlieb@nyu.edu (best method)
- http://cs.nyu.edu/~gottlieb
- 715 Broadway, Room 712
-
212 998 3344
(-1).2: Course Web Page
There is a web site for the course. You can find it from my home
page, which is http://cs.nyu.edu/~gottlieb
-
You can also find these lecture notes on the course home page.
Please let me know if you can't find it.
-
The notes are updated as bugs are found or improvements made.
-
I will also produce a separate page for each lecture after the
lecture is given. These individual pages
might not get updated as quickly as the large page.
(-1).3: Textbook
The course text is Tanenbaum, "Modern Operating Systems", 2nd Edition
-
The first edition is not adequate as there have been many
changes.
-
Available in bookstore.
-
We will cover nearly all of the first 7 chapters.
(-1).4: Computer Accounts and Mailman Mailing List
-
You are entitled to a computer account, please get it asap.
-
Sign up for the Mailman mailing list for the course.
You can do so by clicking
here
-
If you want to send mail just to me, use gottlieb@nyu.edu not
the mailing list.
-
Questions on the labs should go to the mailing list.
You may answer questions posed on the list as well.
Note that replies are sent to the list.
-
I will respond to all questions; if another student has answered the
question before I get to it, I will confirm if the answer given is
correct.
-
Please use proper mailing list etiquette.
-
Use Reply to contribute to the current thread, but NOT
to start another topic.
-
If quoting a previous message, trim off irrelevant parts.
-
Use a descriptive Subject: field when starting a new topic.
-
Do not use one message to ask two unrelated questions.
(-1).5: Grades
Grades will computed as
40%*LabAverage + 60%*FinalExam (but see homeworks below).
(-1).6: The Upper Left Board
I use the upper left board for lab/homework assignments and
announcements. I should never erase that board.
Viewed as a file it is group readable (the group is those in the
room), appendable by just me, and (re-)writable by no one.
If you see me start to erase an announcement, let me know.
I try very hard to remember to write all announcements on the upper
left board and I am normally successful. If, during class, you see
that I have forgotten to record something, please let me know.
HOWEVER, if I forgot and no one reminds me, the
assignment has still been given.
(-1).7: Homeworks and Labs
I make a distinction between homeworks and labs.
Labs are
- Required.
- Due several lectures later (date given on assignment).
- Graded and form part of your final grade.
- Penalized for lateness.
- Computer programs you must write.
Homeworks are
- Optional.
- Due the beginning of Next lecture.
- Not accepted late.
- Mostly from the book.
- Collected and returned.
- Able to help, but not hurt, your grade.
(-1).7.1: Homework Numbering
Homeworks are numbered by the class in which they are assigned. So
any homework given today is homework #1. Even if I do not give homework today,
the homework assigned next class will be homework #2. Unless I
explicitly state otherwise, all homeworks assignments can be found in
the class notes. So the homework present in the notes for lecture #n
is homework #n (even if I inadvertently forgot to write it to the
upper left board).
(-1).7.2: Doing Labs on non-NYU Systems
You may solve lab assignments on any system you wish, but ...
- You are responsible for any non-nyu machine.
I extend deadlines if the nyu machines are down, not if yours are.
- Be sure to upload your assignments to the
nyu systems.
-
In an ideal world, a program written in a high level language
like Java, C, or C++ that works on your system would also work
on the NYU system used by the grader.
Sadly this ideal is not always achieved despite marketing
claims that it is achieved.
So, although you may develop you lab on any system,
you must ensure that it runs on the nyu system assigned to the
course.
-
If somehow your assignment is misplaced by me and/or a grader,
we need a to have a copy ON AN NYU SYSTEM
that can be used to verify the date the lab was completed.
-
When you complete a lab (and have it on an nyu system), do
not edit those files. Indeed, put the lab in a separate
directory and keep out of the directory. You do not want to
alter the dates.
(-1).7.3: Obtaining Help with the Labs
Good methods for obtaining help include
- Asking me during office hours (see web page for my hours).
- Asking the mailing list.
- Asking another student, but ...
Your lab must be your own.
That is, each student must submit a unique lab.
Naturally, simply changing comments, variable names, etc. does
not produce a unique lab.
(-1).7.4: Computer Language Used for Labs
You may write your lab in Java, C, or C++.
(-1).8: A Grade of “Incomplete”
It is university policy that a student's request for an incomplete
be granted only in exceptional circumstances and only if applied for
in advance. Naturally, the application must be before the final exam.
(-1).9: An Introductory Course
This is an introductory course.
I do not assume you have had an OS course as an undergraduate,
and I do not assume you have had extensive experience working
with an operating system.
(Of course, I do assume you are far from a beginner and
that you are very comfortable programming.)
If you have already had an operating systems course,
this course is probably not appropriate.
For example, if you can explain the following concepts/terms,
the course is probably too elementary for you.
-
Process Scheduling
-
Round Robbin Scheduling
-
Shortest Job First
-
Context Switching
-
Demand Paging
-
Segmentation
-
Page Fault
-
Memory Management Unit
-
Processes and Threads
-
Virtual Machine
-
Virtual Memory
-
Least Recently Used (page replacement)
-
Device Driver
-
Direct Memory Access (DMA)
-
Interrupt
-
Seek Time / Rotational Latency / (Disk) Transfer Rate
Chapter 0: Interlude on Linkers
Originally called a linkage editor by IBM.
A linker is an example of a utility program included with an
operating system distribution. Like a compiler, the linker is not
part of the operating system per se, i.e. it does not run in supervisor mode.
Unlike a compiler it is OS dependent (what object/load file format is
used) and is not (normally) language dependent.
0.1: What does a Linker Do?
Link of course.
When the compiler and assembler have finished processing a module,
they produce an object module
that is almost runnable.
There are two remaining tasks to be accomplished before object modules
can be run.
Both are involved with linking (that word, again) together multiple
object modules.
The tasks are relocating relative addresses
and resolving external references.
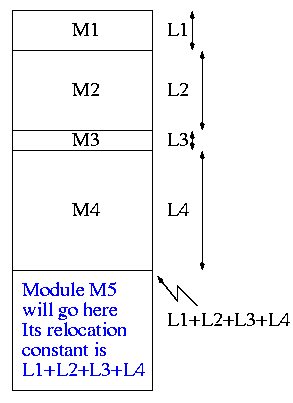
0.1.1: Relocating Relative Addresses
- Each module is (mistakenly) treated as if it will be loaded at
location zero.
- For example, the machine instruction
jump 100
is used to indicate a jump to location 100 of
the current module.
- To convert this relative address to an
absolute address,
the linker adds the base address of the module
to the relative address.
The base address is the address at which
this module will be loaded.
- Example: Module A is to be loaded starting at location 2300 and
contains the instruction
jump 120
The linker changes this instruction to
jump 2420
- How does the linker know that Module M5 is to be loaded starting at
location 2300?
- It processes the modules one at a time. The first module is
to be loaded at location zero.
So relocating the first module is trivial (adding zero).
We say that the relocation constant is zero.
- After processing the first module, the linker knows its length
(say that length is L1).
- Hence the next module is to be loaded starting at L1, i.e.,
the relocation constant is L1.
- In general the linker keeps the sum of the lengths of
all the modules it has already processed; this sum is the
relocation constant for the next module.
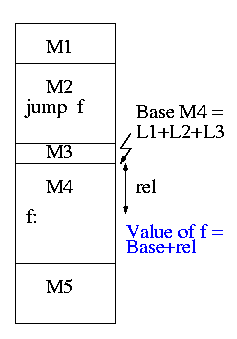
0.1.2: Resolving External Reverences
- If a C (or Java, or Pascal) program contains a function call
f(x)
to a function f() that is compiled separately, the resulting
object module must contain some kind of jump to the beginning of
f.
-
But this is impossible!
-
When the C program is compiled. the compiler and assembler
do not know the location of f() so there is no
way they can supply the starting address.
-
Instead a dummy address is supplied and a notation made that
this address needs to be filled in with the location of
f(). This is called a use of
f.
-
The object module containing the definition
of f() contains a notation that f is being
defined and gives the relative address of the definition, which
the linker converts to an absolute address (as above).
-
The linker then changes all uses of f() to the correct absolute address.
The output of a linker is called a load module
because it is now ready to be loaded and run.
To see how a linker works lets consider the following example,
which is the first dataset from lab #1. The description in lab1 is
more detailed.
The target machine is word addressable and has a memory of 250
words, each consisting of 4 decimal digits. The first (leftmost)
digit is the opcode and the remaining three digits form an address.
Each object module contains three parts, a definition list, a use
list, and the program text itself. Each definition is a pair (sym,
loc). Each entry in the use list is a symbol and a list of uses of
that symbol.
The program text consists of a count N followed by N pairs (type, word),
where word is a 4-digit instruction described above and type is a
single character indicating if the address in the word is
Immediate,
Absolute,
Relative, or
External.
Input set #1
1 xy 2
2 z xy
5 R 1004 I 5678 E 2000 R 8002 E 7001
0
1 z
6 R 8001 E 1000 E 1000 E 3000 R 1002 A 1010
0
1 z
2 R 5001 E 4000
1 z 2
2 xy z
3 A 8000 E 1001 E 2000
The first pass simply finds the base address of each module and
produces the symbol table giving the values for xy and z (2 and 15
respectively). The second pass does the real work using the symbol
table and base addresses produced in pass one.
Symbol Table
xy=2
z=15
Memory Map
+0
0: R 1004 1004+0 = 1004
1: I 5678 5678
2: xy: E 2000 ->z 2015
3: R 8002 8002+0 = 8002
4: E 7001 ->xy 7002
+5
0 R 8001 8001+5 = 8006
1 E 1000 ->z 1015
2 E 1000 ->z 1015
3 E 3000 ->z 3015
4 R 1002 1002+5 = 1007
5 A 1010 1010
+11
0 R 5001 5001+11= 5012
1 E 4000 ->z 4015
+13
0 A 8000 8000
1 E 1001 ->z 1015
2 z: E 2000 ->xy 2002
The output above is more complex than I expect you to produce
it is there to help me explain what the linker is doing. All I would
expect from you is the symbol table and the rightmost column of the
memory map.
You must process each module separately, i.e. except for the symbol
table and memory map your space requirements should be proportional to the
largest module not to the sum of the modules.
This does NOT make the lab harder.
(Unofficial) Remark:
It is faster (less I/O) to do a one pass approach, but is harder
since you need “fix-up code” whenever a use occurs in a module that
precedes the module with the definition.
The linker on unix was mistakenly called ld (for loader), which is
unfortunate since it links but does not load.
Historical remark: Unix was originally
developed at Bell Labs; the seventh edition of unix was made
publicly available (perhaps earlier ones were somewhat available).
The 7th ed man page for ld begins (see http://cm.bell-labs.com/7thEdMan).
.TH LD 1
.SH NAME
ld \- loader
.SH SYNOPSIS
.B ld
[ option ] file ...
.SH DESCRIPTION
.I Ld
combines several
object programs into one, resolves external
references, and searches libraries.
By the mid 80s the Berkeley version (4.3BSD) man page referred to ld as
"link editor" and this more accurate name is now standard in unix/linux
distributions.
During the 2004-05 fall semester a student wrote to me
“BTW - I have meant to tell you that I know the lady who
wrote ld. She told me that they called it loader, because they just
really didn't
have a good idea of what it was going to be at the time.”
Lab #1:
Implement a two-pass linker. The specific assignment is detailed on
the class home page.
End of Interlude on Linkers
Chapter 1: Introduction
Homework: Read Chapter 1 (Introduction)
Levels of abstraction (virtual machines)
-
Software (and hardware, but that is not this course) is often
implemented in layers.
-
The higher layers use the facilities provided by lower layers.
-
Alternatively said, the upper layers are written using a more
powerful and more abstract virtual machine than the lower layers.
-
Alternatively said, each layer is written as though it runs on the
virtual machine supplied by the lower layer and in turn provides a
more abstract (pleasant) virtual machine for the higher layer to
run on.
-
Using a broad brush, the layers are.
- Applications and utilities
- Compilers, Editors, Command Interpreter (shell, DOS prompt)
- Libraries
- The OS proper (the kernel, runs in
privileged/kernel/supervisor mode)
- Hardware
-
Compilers, editors, shell, linkers. etc run in user mode.
-
The kernel itself is itself normally layered, e.g.
- Filesystems
- Machine independent I/O
- Machine dependent device drivers
-
The machine independent I/O part is written assuming “virtual
(i.e. idealized) hardware”. For example, the machine independent
I/O portion simply reads a block from a “disk”. But in reality
one must deal with the specific disk controller.
-
Often the machine independent part is more than one layer.
-
The term OS is not well defined. Is it just the kernel? How
about the libraries? The utilities? All these are certainly
system software but not clear how much is part of
the OS.
1.1: What is an operating system?
The kernel itself raises the level of abstraction and hides details.
For example a user (of the kernel) can write to a file (a concept not
present in hardware) and ignore whether the file resides on a floppy,
a CD-ROM, or a hard disk.
The user can also ignore issues such as whether the file is stored
contiguously or is broken into blocks.
The kernel is a resource manager (so users don't
conflict).
How is an OS fundamentally different from a compiler (say)?
Answer: Concurrency! Per Brinch Hansen in Operating Systems
Principles (Prentice Hall, 1973) writes.
The main difficulty of multiprogramming is that concurrent activities
can interact in a time-dependent manner, which makes it practically
impossibly to locate programming errors by systematic testing.
Perhaps, more than anything else, this explains the difficulty of
making operating systems reliable.
Homework: 1, 2. (unless otherwise stated, problems
numbers are from the end of the chapter in Tanenbaum.)
1.2 History of Operating Systems
- Single user (no OS).
- Batch, uniprogrammed, run to completion.
- The OS now must be protected from the user program so that it is
capable of starting (and assisting) the next program in the batch.
- Multiprogrammed
- The purpose was to overlap CPU and I/O
-
Multiple batches
- IBM OS/MFT (Multiprogramming with a Fixed number of Tasks)
- OS for IBM system 360.
- The (real) memory is partitioned and a batch is
assigned to a fixed partition.
- The memory assigned to a
partition does not change.
- Jobs were spooled from cards into the
memory by a separate processor (an IBM 1401).
Similarly output was
spooled from the memory to a printer (a 1403) by the 1401.
- IBM OS/MVT (Multiprogramming with a Variable number of Tasks)
(then other names)
- Each job gets just the amount of memory it needs. That
is, the partitioning of memory changes as jobs enter and leave
- MVT is a more “efficient” user of resources, but is
more difficult.
- When we study memory management, we will see that, with
varying size partitions, questions like compaction and
“holes” arise.
-
Time sharing
-
This is multiprogramming with rapid switching between jobs
(processes). Deciding when to switch and which process to
switch to is called scheduling.
-
We will study scheduling when we do processor management
-
Personal Computers
-
Serious PC Operating systems such as linux, Windows NT/2000/XP
and (the newest) MacOS are multiprogrammed OSes.
-
GUIs have become important. Debate as to whether it should be
part of the kernel.
-
Early PC operating systems were uniprogrammed and their direct
descendants in some sense still are (e.g. Windows ME).
Homework: 3.
1.3: OS Zoo
There is not as much difference between mainframe, server,
multiprocessor, and PC OSes as Tannenbaum suggests. For example
Windows NT/2000/XP, Unix and Linux are used on all.
1.3.1: Mainframe Operating Systems
Used in data centers, these systems ofter tremendous I/O
capabilities and extensive fault tolerance.
1.3.2: Server Operating Systems
Perhaps the most important servers today are web servers.
Again I/O (and network) performance are critical.
1.3.3: Multiprocessor Operating systems
These existed almost from the beginning of the computer
age, but now are not exotic.
1.3.4: PC Operating Systems (client machines)
Some OSes (e.g. Windows ME) are tailored for this application. One
could also say they are restricted to this application.
1.3.5: Real-time Operating Systems
- Often are Embedded Systems.
- Soft vs hard real time. In the latter missing a deadline is a
fatal error--sometimes literally.
- Very important commercially, but not covered much in this course.
1.3.6: Embedded Operating Systems
- The OS is “part of” the device. For example, PDAs,
microwave ovens, cardiac monitors.
- Often are real-time systems.
- Very important commercially, but not covered much in this course.
1.3.7: Smart Card Operating Systems
Very limited in power (both meanings of the word).
Multiple computers
- Network OS: Make use of the multiple PCs/workstations on a LAN.
- Distributed OS: A “seamless” version of above.
- Not part of this course (but often in G22.2251).
Homework: 5.