Operating Systems
================ Start Lecture #26 ================
6.1.4: File access
There are basically two possibilities, sequential access and random
access (a.k.a. direct access).
Previously, files were declared to be sequential or random.
Modern systems do not do this.
Instead all files are random and optimizations are applied when the
system dynamically determines that a file is (probably) being accessed
sequentially.
-
With Sequential access the bytes (or records)
are accessed in order (i.e., n-1, n, n+1, ...).
Sequential access is the most common and
gives the highest performance.
For some devices (e.g. tapes) access “must” be sequential.
-
With random access, the bytes are accessed in any
order. Thus each access must specify which bytes are desired.
6.1.5: File attributes
A laundry list of properties that can be specified for a file
For example:
-
hidden
-
do not dump
-
owner
-
key length (for keyed files)
6.1.6: File operations
-
Create:
Essential if a system is to add files. Need not be a separate system
call (can be merged with open).
-
Delete:
Essential if a system is to delete files.
-
Open:
Not essential. An optimization in which the translation from file name to
disk locations is perform only once per file rather than once per access.
-
Close:
Not essential. Free resources.
-
Read:
Essential. Must specify filename, file location, number of bytes,
and a buffer into which the data is to be placed.
Several of these parameters can be set by other
system calls and in many OS's they are.
-
Write:
Essential if updates are to be supported. See read for parameters.
-
Seek:
Not essential (could be in read/write). Specify the
offset of the next (read or write) access to this file.
-
Get attributes:
Essential if attributes are to be used.
-
Set attributes:
Essential if attributes are to be user settable.
-
Rename:
Tanenbaum has strange words. Copy and delete is not acceptable for
big files. Moreover copy-delete is not atomic. Indeed link-delete is
not atomic so even if link (discussed below)
is provided, renaming a file adds functionality.
Homework: 6, 7.
6.1.7: An Example Program Using File System Calls
Homework: Read and understand “copyfile”.
Notes on copyfile
-
Normally in unix one wouldn't call read and write directly.
-
Indeed, for copyfile, getchar() and putchar() would be nice since
they take care of the buffering (standard I/O, stdio).
-
If you compare copyfile from the 1st to 2nd edition, you can see
the addition of error checks.
6.1.8: Memory mapped files (Unofficial)
Conceptually simple and elegant. Associate a segment with each
file and then normal memory operations take the place of I/O.
Thus copyfile does not have fgetc/fputc (or read/write). Instead it is
just like memcopy
while ( *(dest++) = *(src++) );
The implementation is via segmentation with demand paging but
the backing store for the pages is the file itself.
This all sounds great but ...
-
How do you tell the length of a newly created file? You know
which pages were written but not what words in those pages. So a file
with one byte or 10, looks like a page.
-
What if same file is accessed by both I/O and memory mapping.
-
What if the file is bigger than the size of virtual memory (will
not be a problem for systems built 3 years from now as all will have
enormous virtual memory sizes).
6.2: Directories
Unit of organization.
6.2.1-6.2.3: Single-level, Two-level, and Hierarchical directory systems
Possibilities
-
One directory in the system (Single-level)
-
One per user and a root above these (Two-level)
-
One tree
-
One tree per user
-
One forest
-
One forest per user
These are not as wildly different as they sound.
-
If the system only has one directory, but allows the character /
in a file name. Then one could fake a tree by having a file named
/allan/gottlieb/courses/arch/class-notes.html
rather than a
directory allan, a subdirectory gottlieb, ..., a file
class-notes.html.
-
Dos (windows) is a forest, unix a tree. In dos there is no common
parent of a:\ and c:\.
-
But windows explorer makes the dos forest look quite a bit like a
tree.
-
You can get an effect similar to (but not the same as) one X per
user by having just one X in the system and having permissions
that permits each user to visit only a subset. Of course if the
system doesn't have permissions, this is not possible.
-
Today's systems have a tree per system or a forest per system.
6.2.4: Path Names
You can specify the location of a file in the file hierarchy by
using either an absolute or a
Relative path to the file
-
An absolute path starts at the (or “one of the”, if we have a
forest) root(s).
-
A relative path starts at the current
(a.k.a working) directory.
-
The special directories . and .. represent the current directory
and the parent of the current directory respectively.
Homework: 1, 9.
6.2.5: Directory operations
-
Create: Produces an “empty” directory.
Normally the directory created actually contains . and .., so is not
really empty
-
Delete: Requires the directory to be empty (i.e., to just contain
. and ..). Commands are normally written that will first empty the
directory (except for . and ..) and then delete it. These commands
make use of file and directory delete system calls.
-
Opendir: Same as for files (creates a “handle”)
-
Closedir: Same as for files
-
Readdir: In the old days (of unix) one could read directories as files
so there was no special readdir (or opendir/closedir). It was
believed that the uniform treatment would make programming (or at
least system understanding) easier as there was less to learn.
However, experience has taught that this was not a good idea since
the structure of directories then becomes exposed. Early unix had a
simple structure (and there was only one type of structure for all
implementations).
Modern systems have more sophisticated structures and more
importantly they are not fixed across implementations.
So if programs just used read() to read directories, the programs
would have to be changed whenever the structure of a directory
changed.
Now we have a readdir() system call that knows the structure of
directories.
Therefore if the structure is changed only readdir() need be changed.
changed.
-
Rename: As with files.
-
Link: Add a second name for a file; discussed
below.
-
Unlink: Remove a directory entry.
This is how a file is deleted.
But if there are many links and just one is unlinked, the file
remains.
Discussed in more detail below.
6.3: File System Implementation
6.3.1: File System Layout
-
One disk starts with a Master Boot Record (MBR).
-
Each disk has a partition table.
-
Each partition holds one file system.
-
Each partition typically contains some parameters (e.g., size),
free blocks, and blocks in use. The details vary.
-
In unix some of the in use blocks contains I-nodes each of which
describes a file or directory and is described below.
-
During boot the MBR is read and executed.
It transfers control to the boot block of the
active partition.
6.3.2: Implementing Files
-
A disk cannot read or write a single word.
Instead it can read or write a sector, which is
often 512 bytes.
-
Disks are written in blocks whose size is a multiple of the sector
size.
Contiguous allocation
-
This is like OS/MVT.
-
The entire file is stored as one piece.
-
Simple and fast for access, but ...
-
Problem with growing files
-
Must either evict the file itself or the file it is bumping
into.
-
Same problem with an OS/MVT kind of system if jobs grow.
-
Problem with external fragmentation.
-
No longer used for general purpose rewritable file systems.
-
Ideal for file systems where files do not change size.
-
Used for CD-ROM file systems.
Homework: 12.
Linked allocation
-
The directory entry contains a pointer to the first block of the file.
-
Each block contains a pointer to the next.
-
Horrible for random access.
-
Not used.
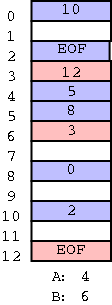
FAT (file allocation table)
-
Used by dos and windows (but NT/2000/XP also support the superior
NTFS).
-
Directory entry points to first block (i.e. specifies the block
number).
-
A FAT is maintained in memory having one (word) entry for each
disk block.
The entry for block N contains the block number of the
next block in the same file as N.
-
This is linked but the links are stored separately.
-
Time to access a random block is still is linear in size of file
but now all the references are to this one table which is in memory.
So it is bad for random accesses, but not nearly as horrible as
plain linked allocation.
-
Size of table is one word per disk block.
If blocks are of size 4K and the FAT uses 4-byte words, the table
is one megabyte for each disk gigabyte.
Large but perhaps not prohibitive.
-
If blocks are of size 512 bytes (the sector size of most disks)
then the table is 8 megs per gig, which is probably prohibitive.
Why don't we mimic the idea of paging and have a table giving for
each block of the file, where on the disk that file block is stored?
In other words a ``file block table'' mapping its file block to its
corresponding disk block.
This is the idea of (the first part of) the unix inode solution, which
we study next.
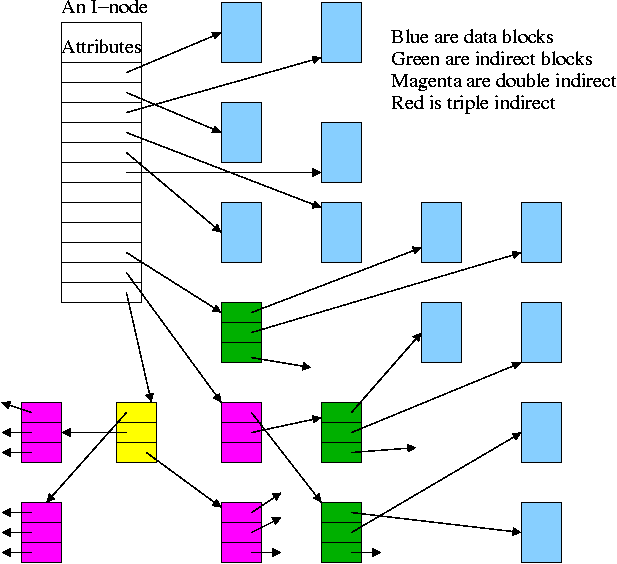
I-Nodes
-
Used by unix/linux.
-
Directory entry points to i-node (index-node).
-
I-Node points to first few data blocks, often called direct blocks.
-
I-Node also points to an indirect block, which points to disk blocks.
-
I-Node also points to a double indirect, which points an indirect ...
-
For some implementations there are triple indirect as well.
-
The i-node is in memory for open files.
So references to direct blocks take just one I/O.
-
For big files most references require two I/Os (indirect + data).
-
For huge files most references require three I/Os (double
indirect, indirect, and data).
Algorithm to retrieve a block
Let's say that you want to find block N
(N=0 is the "first" block) and that
There are D direct pointers in the inode numbered 0..(D-1)
There are K pointers in each indirect block numbered 0..K-1
If N < D // This is a direct block in the i-node
use direct pointer N in the i-node
else if N < D + K // This is one of the K blocks pointed to by indirect blk
use pointer D in the inode to get the indirect block
use pointer N-D in the indirect block to get block N
else // This is one of the K*K blocks obtained via the double indirect block
use pointer D+1 in the inode to get the double indirect block
let P = (N-(D+K)) DIV K // Which single indirect block to use
use pointer P to get the indirect block B
let Q = (N-(D+K)) MOD K // Which pointer in B to use
use pointer Q in B to get block N