Operating Systems
================ Start Lecture #13 ================
Choice of block size
-
We discussed a similar question before when studying page size.
-
Current commodity disk characteristics (not for laptops) result in
about 15ms to transfer the first byte and 10K bytes per ms for
subsequent bytes (if contiguous).
-
Rotation rate often 5400 or 7200 RPM with 10k, 15k and (just
now) 20k available.
-
Recall that 6000 RPM is 100 rev/sec or one rev
per 10ms. So half a rev (the average time to rotate to a
given point) is 5ms.
-
Transfer rates around 10MB/sec = 10KB/ms.
-
Seek time around 10ms.
-
This analysis suggests large blocks, 100KB or more.
-
But the internal fragmentation would be severe since many files
are small.
-
Typical block sizes are 4KB-8KB.
-
Multiple block sizes have been tried (e.g. blocks are 8K but a
file can also have “fragments” that are a fraction of
a block, say 1K)
-
Some systems employ techniques to force consecutive blocks of a
given file near each other,
preferably contiguous. Also some
systems try to cluster “related” files (e.g., files in the
same directory).
Homework:
Consider a disk with an average seek time of 10ms, an average
rotational latency of 5ms, and a transfer rate of 10MB/sec.
-
If the block size is 1KB, how long would it take to read a block?
-
If the block size is 100KB, how long would it take to read a
block?
-
If the goal is to read 1K, a 1KB block size is better as the
remaining 99KB are wasted. If the goal is to read 100KB, the
100KB block size is better since the 1KB block size needs 100
seeks and 100 rotational latencies. What is the minimum size
request for which a disk with a 100KB block size would complete
faster than one with a 1KB block size?
RAID (Redundant Array of Inexpensive Disks)
- The name RAID is from Berkeley.
-
IBM changed the name to Redundant Array of Independent
Disks. I wonder why?
-
A simple form is mirroring, where two disks contain the
same data.
-
Another simple form is striping (interleaving) where consecutive
blocks are spread across multiple disks. This helps bandwidth, but is
not redundant. Thus it shouldn't be called RAID, but it sometimes is.
-
One of the normal RAID methods is to have N (say 4) data disks and one
parity disk. Data is striped across the data disks and the bitwise
parity of these sectors is written in the corresponding sector of the
parity disk.
-
On a read if the block is bad (e.g., if the entire disk is bad or
even missing), the system automatically reads the other blocks in the
stripe and the parity block in the stripe. Then the missing block is
just the bitwise exclusive or of all these blocks.
-
For reads this is very good. The failure free case has no penalty
(beyond the space overhead of the parity disk). The error case
requires N-1+1=N (say 5) reads.
-
A serious concern is the small write problem. Writing a sector
requires 4 I/O. Read the old data sector, compute the change, read
the parity, compute the new parity, write the new parity and the new
data sector. Hence one sector I/O became 4, which is a 300% penalty.
-
Writing a full stripe is not bad. Compute the parity of the N
(say 4) data sectors to be written and then write the data sectors and
the parity sector. Thus 4 sector I/Os become 5, which is only a 25%
penalty and is smaller for larger N, i.e., larger stripes.
-
A variation is to rotate the parity. That is, for some stripes
disk 1 has the parity, for others disk 2, etc. The purpose is to not
have a single parity disk since that disk is needed for all small
writes and could become a point of contention.
5.4.2: Disk Formatting
Skipped.
5.4.3: Disk Arm Scheduling Algorithms
There are three components to disk response time: seek, rotational
latency, and transfer time. Disk arm scheduling is concerned with
minimizing seek time by reordering the requests.
These algorithms are relevant only if there are several I/O
requests pending. For many PCs this is not the case. For most
commercial applications, I/O is crucial and there are often many
requests pending.
- FCFS (First Come First Served): Simple but has long delays.
-
Pick: Same as FCFS but pick up requests for cylinders that are
passed on the way to the next FCFS request.
-
SSTF or SSF (Shortest Seek (Time) First): Greedy algorithm. Can
starve requests for outer cylinders and almost always favors middle
requests.
- Scan (Look, Elevator): The method used by an old fashioned
jukebox (remember “Happy Days”) and by elevators. The disk arm
proceeds in one direction picking up all requests until there are no
more requests in this direction at which point it goes back the other
direction. This favors requests in the middle, but can't starve any
requests.
-
C-Scan (C-look, Circular Scan/Look): Similar to Scan but only
service requests when moving in one direction. When going in the
other direction, go directly to the furthest away request. This
doesn't favor any spot on the disk. Indeed, it treats the cylinders
as though they were a clock, i.e. after the highest numbered cylinder
comes cylinder 0.
- N-step Scan: This is what the natural implementation of Scan
gives.
- While the disk is servicing a Scan direction, the controller
gathers up new requests and sorts them.
- At the end of the current sweep, the new list becomes the next
sweep.
Minimizing Rotational Latency
Use Scan based on sector numbers not cylinder number. For
rotational latency Scan is the same as C-Scan. Why?
Ans: Because the disk only rotates in one direction.
Homework: 24, 25
5.4.4: Error Handling
Disks error rates have dropped in recent years. Moreover, bad
block forwarding is normally done by the controller (or disk electronics) so
this topic is no longer as important for OS.
5.5: Clocks
Also called timers.
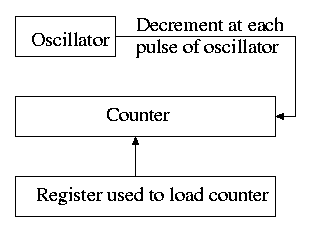
5.5.1: Clock Hardware
- Generates an interrupt when timer goes to zero
- Counter reload can be automatic or under software (OS) control.
- If done automatically, the interrupt occurs periodically and thus
is perfect for generating a clock interrupt at a fixed period.
5.5.2: Clock Software
-
Time of day (TOD): Bump a counter each tick (clock interupt). If
counter is only 32 bits must worry about overflow so keep two
counters: low order and high order.
-
Time quantum for RR: Decrement a counter at each tick. The quantum
expires when counter is zero. Load this counter when the scheduler
runs a process. This is presumably what you did for the (processor)
scheduling lab.
-
Accounting: At each tick, bump a counter in the process table
entry for the currently running process.
-
Alarm system call and system alarms:
-
Users can request an alarm at some future time.
-
The system also on occasion needs to schedule some of its own
activities to occur at specific times in the future (e.g. turn off
the floppy motor).
-
The conceptually simplest solution is to have one timer for
each event.
-
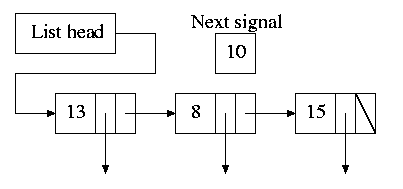
Instead, we simulate many timers with just one.
-
The data structure on the right works well. There is one node
for each event.
-
The first entry in each node is the time after the
preceding event that this event's alarm is to ring.
-
For example, if the time is zero, this event occurs at the
same time as the previous event.
-
The second entry in the node is a pointer to the action to perform.
-
At each tick, decrement next-signal.
-
When next-signal goes to zero,
process the first entry on the list and any others following
immediately after with a time of zero (which means they are to be
simultaneous with this alarm). Then set next-signal to the value
in the next alarm.
- Profiling
- Want a histogram giving how much time was spent in each 1KB
(say) block of code.
- At each tick check the PC and bump the appropriate counter.
- A user-mode program can determine the software module
associated with each 1K block.
- If we use finer granularity (say 10B instead of 1KB), we get
increased accuracy but more memory overhead.
Homework: 27
5.6: Character-Oriented Terminals
5.6.1: RS-232 Terminal Hardware
Quite dated. It is true that modern systems can communicate to a
hardwired ascii terminal, but most don't. Serial ports are used, but
they are normally connected to modems and then some protocol (SLIP,
PPP) is used not just a stream of ascii characters. So skip this
section.
Memory-Mapped Terminals
Not as dated as the previous section but it still discusses the
character not graphics interface.
-
Today, software writes into video memory
the bits that are to be put on the screen and then the graphics
controller
converts these bits to analog signals for the monitor (actually laptop
displays and some modern monitors are digital).
-
But it is much more complicated than this. The graphics
controllers can do a great deal of video themselves (like filling).
-
This is a subject that would take many lectures to do well.
-
I believe some of this is covered in 201.
Keyboards
Tanenbaum description of keyboards is correct.
- At each key press and key release a code is written into the
keyboard controller and the computer is interrupted.
- By remembering which keys have been depressed and not released
the software can determine Cntl-A, Shift-B, etc.
5.6.2: Input Software
- We are just looking at keyboard input. Once again graphics is too
involved to be treated well.
- There are two fundamental modes of input, sometimes called
raw and cooked.
- In raw mode the application sees every “character” the user
types. Indeed, raw mode is character oriented.
-
All the OS does is convert the keyboard “scan
codes” to “characters” and and pass these
characters to the application.
- Some examples
-
down-cntl down-x up-x up-cntl is converted to cntl-x
- down-cntl up-cntl down-x up-x is converted to x
- down-cntl down-x up-cntl up-x is converted to cntl-x (I just
tried it to be sure).
- down-x down-cntl up-x up-cntl is converted to x
- Full screen editors use this mode.
- Cooked mode is line oriented. The OS delivers lines to the
application program.
-
Special characters are interpreted as editing characters
(erase-previous-character, erase-previous-word, kill-line, etc).
-
Erased characters are not seen by the application but are
erased by the keyboard driver.
-
Need an escape character so that the editing characters can be
passed to the application if desired.
-
The cooked characters must be echoed (what should one do if the
application is also generating output at this time?)
-
The (possibly cooked) characters must be buffered until the
application issues a read (and an end-of-line EOL has been
received for cooked mode).
5.6.3: Output Software
Again too dated and the truth is too complicated to deal with in a
few minutes.
5.7: Graphical User Interfaces (GUIs)
Skipped.
5.8: Network Terminals
Skipped.
5.9: Power Management
Skipped.
5.10: Research on Input/Output
Skipped.
5.11: Summary
Read.
Chapter 6: File Systems
Requirements
-
Size: Store very large amounts of data.
-
Persistence: Data survives the creating process.
-
Access: Multiple processes can access the data concurrently.
Solution: Store data in files that together form a file system.
6.1: Files
6.1.1: File Naming
Very important. A major function of the file system.
- Does each file have a unique name?
Answer: Often no. We will discuss this below when we study
links.
-
Extensions, e.g. the “html” in “class-notes.html”.
- Conventions just for humans: letter.teq (my convention).
- Conventions giving default behavior for some programs.
-
The emacs editor thinks .html files should be edited in
html mode but
can edit them in any mode and can edit any file
in html mode.
-
Netscape thinks .html means an html file, but
<html> ... </html> works as well
-
Gzip thinks .gz means a compressed file but accepts a
--suffix flag
- Default behavior for Operating system or window manager or
desktop environment.
-
Click on .xls file in windows and excel is started.
-
Click on .xls file in nautilus under linux and open office
is started.
- Required extensions for programs
-
The gnu C compiler (and probably others) requires C
programs be named *.c and assembler programs be named *.s
- Required extensions by operating systems
-
MS-DOS treats .com files specially
-
Windows 95 requires (as far as I could tell) shortcuts to
end in .lnk.
- Case sensitive?
Unix: yes. Windows: no.
6.1.2: File structure
A file is a
- Byte stream
-
Unix, dos, windows (I think).
-
Maximum flexibility.
-
Minimum structure.
- (fixed size) Record stream: Out of date
-
80-character records for card images.
-
133-character records for line printer files. Column 1 was
for control (e.g., new page) Remaining 132 characters were
printed.
- Varied and complicated beast.
-
Indexed sequential.
-
B-trees.
-
Supports rapidly finding a record with a specific
key.
-
Supports retrieving (varying size) records in key order.
-
Treated in depth in database courses.
6.1.3: File types
Examples
- (Regular) files.
- Directories: studied below.
- Special files (for devices).
Uses the naming power of files to unify many actions.
dir # prints on screen
dir > file # result put in a file
dir > /dev/tape # results written to tape
-
“Symbolic” Links (similar to “shortcuts”): Also studied
below.
“Magic number”: Identifies an executable file.
-
There can be several different magic numbers for different types
of executables.
- unix: #!/usr/bin/perl
Strongly typed files:
-
The type of the file determines what you can do with the
file.
-
This make the easy and (hopefully) common case easier and, more
importantly, safer.
-
It tends to make the unusual case harder. For example, you have a
program that turns out data (.dat) files. But you want to use it to
turn out a java file but the type of the output is data and cannot be
easily converted to type java.
6.1.4: File access
There are basically two possibilities, sequential access and random
access (a.k.a. direct access).
Previously, files were declared to be sequential or random.
Modern systems do not do this.
Instead all files are random and optimizations are applied when the
system dynamically determines that a file is (probably) being accessed
sequentially.
- With Sequential access the bytes (or records)
are accessed in order (i.e., n-1, n, n+1, ...).
Sequential access is the most common and
gives the highest performance.
For some devices (e.g. tapes) access “must” be sequential.
- With random access, the bytes are accessed in any
order. Thus each access must specify which bytes are desired.