Operating Systems
================ Start Lecture #8 ================
Lab3 (banker's algorithm) assigned
Chapter 4: Memory Management
Also called storage management or
space management.
Memory management must deal with the storage
hierarchy present in modern machines.
- Registers, cache, central memory, disk, tape (backup)
- Move data from level to level of the hierarchy.
- How should we decide when to move data up to a higher level?
- Fetch on demand (e.g. demand paging, which is dominant now).
- Prefetch
- Read-ahead for file I/O.
- Large cache lines and pages.
- Extreme example. Entire job present whenever running.
We will see in the next few weeks that there are three independent
decision:
- Segmentation (or no segmentation)
- Paging (or no paging)
- Fetch on demand (or no fetching on demand)
Memory management implements address translation.
- Convert virtual addresses to physical addresses
- Also called logical to real address translation.
- A virtual address is the address expressed in
the program.
- A physical address is the address understood
by the computer hardware.
- The translation from virtual to physical addresses is performed by
the Memory Management Unit or (MMU).
- Another example of address translation is the conversion of
relative addresses to absolute addresses
by the linker.
- The translation might be trivial (e.g., the identity) but not in a modern
general purpose OS.
- The translation might be difficult (i.e., slow).
- Often includes addition/shifts/mask--not too bad.
- Often includes memory references.
- VERY serious.
- Solution is to cache translations in a Translation
Lookaside Buffer (TLB). Sometimes called a
translation buffer (TB).
Homework: 6.
When is address translation performed?
- At compile time
- Compiler generates physical addresses.
- Requires knowledge of where the compilation unit will be loaded.
- No linker.
- Loader is trivial.
- Primitive.
- Rarely used (MSDOS .COM files).
- At link-edit time (the “linker lab”)
- Compiler
-
Generates relative (a.k.a. relocatable) addresses for each
compilation unit.
-
References external addresses.
- Linkage editor
- Converts the relocatable addr to absolute.
- Resolves external references.
-
Misnamed ld by unix.
-
Must also converts virtual to physical addresses by
knowing where the linked program will be loaded. Linker
lab “does” this, but it is trivial since we
assume the linked program will be loaded at 0.
-
Loader is still trivial.
-
Hardware requirements are small.
-
A program can be loaded only where specified and
cannot move once loaded.
-
Not used much any more.
- At load time
-
Similar to at link-edit time, but do not fix
the starting address.
-
Program can be loaded anywhere.
-
Program can move but cannot be split.
-
Need modest hardware: base/limit registers.
-
Loader sets the base/limit registers.
-
No longer common.
- At execution time
- Addresses translated dynamically during execution.
- Hardware needed to perform the virtual to physical address
translation quickly.
- Currently dominates.
- Much more information later.
Extensions
- Dynamic Loading
- When executing a call, check if module is loaded.
- If not loaded, call linking loader to load it and update
tables.
- Slows down calls (indirection) unless you rewrite code dynamically.
- Not used much.
- Dynamic Linking
- The traditional linking described above is today often called
static linking.
- With dynamic linking, frequently used routines are not linked
into the program. Instead, just a stub is linked.
- When the routine is called, the stub checks to see if the
real routine is loaded (it may have been loaded by
another program).
- If not loaded, load it.
- If already loaded, share it. This needs some OS
help so that different jobs sharing the library don't
overwrite each other's private memory.
- Advantages of dynamic linking.
- Saves space: Routine only in memory once even when used
many times.
- Bug fix to dynamically linked library fixes all applications
that use that library, without having to
relink the application.
- Disadvantages of dynamic linking.
- New bugs in dynamically linked library infect all
applications.
- Applications “change” even when they haven't changed.
Note: I will place ** before each memory management
scheme.
4.1: Basic Memory Management (Without Swapping or Paging)
Entire process remains in memory from start to finish and does not move.
The sum of the memory requirements of all jobs in the system cannot
exceed the size of physical memory.
** 4.1.1: Monoprogramming without swapping or paging (Single User)
The “good old days” when everything was easy.
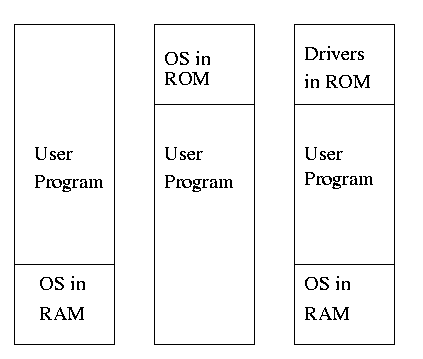
- No address translation done by the OS (i.e., address translation is
not performed dynamically during execution).
- Either reload the OS for each job (or don't have an OS, which is almost
the same), or protect the OS from the job.
- One way to protect (part of) the OS is to have it in ROM.
- Of course, must have the OS (read-write) data in ram.
- Can have a separate OS address space only accessible in
supervisor mode.
- Might just put some drivers in ROM (BIOS).
- The user employs overlays if the memory needed
by a job exceeds the size of physical memory.
- Programmer breaks program into pieces.
- A “root” piece is always memory resident.
- The root contains calls to load and unload various pieces.
- Programmer's responsibility to ensure that a piece is already
loaded when it is called.
- No longer used, but we couldn't have gotten to the moon in the
60s without it (I think).
- Overlays have been replaced by dynamic address translation and
other features (e.g., demand paging) that have the system support
logical address sizes greater than physical address sizes.
- Fred Brooks (leader of IBM's OS/360 project and author of “The
mythical man month”) remarked that the OS/360 linkage editor was
terrific, especially in its support for overlays, but by the time
it came out, overlays were no longer used.
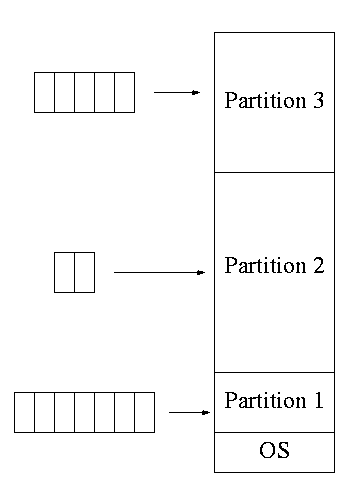
**4.1.2: Multiprogramming with fixed partitions
Two goals of multiprogramming are to improve CPU utilization, by
overlapping CPU and I/O, and to permit short jobs to finish quickly.
- This scheme was used by IBM for system 360 OS/MFT
(multiprogramming with a fixed number of tasks).
- Can have a single input queue instead of one for each partition.
- So that if there are no big jobs can use big partition for
little jobs.
- But I don't think IBM did this.
- Can think of the input queue(s) as the ready list(s) with a
scheduling policy of FCFS in each partition.
-
Each partition was monoprogrammed, the
multiprogramming occurred across partitions.
-
The partition boundaries are not movable (must reboot to
move a job).
- MFT can have large internal fragmentation,
i.e., wasted space inside a region
- Each process has a single “segment” (we will discuss segments later)
- No sharing between process.
- No dynamic address translation.
- At load time must “establish addressability”.
- i.e. must set a base register to the location at which the
process was loaded (the bottom of the partition).
- The base register is part of the programmer visible register set.
- This is an example of address translation during load time.
- Also called relocation.
- Storage keys are adequate for protection (IBM method).
- Alternative protection method is base/limit registers.
- An advantage of base/limit is that it is easier to move a job.
- But MFT didn't move jobs so this disadvantage of storage keys is moot.
- Tanenbaum says a job was “run until it terminates. This must be
wrong as that would mean monoprogramming.
- He probably means that jobs not swapped out and each queue is FCFS
without preemption.
4.1.3: Modeling Multiprogramming
- Consider a job that is unable to compute (i.e., it is waiting for
I/O) a fraction p of the time.
- Then, with monoprogramming, the CPU utilization is 1-p.
- Note that p is often > .5 so CPU utilization is poor.
- But, if the probability that a
job is waiting for I/O is p and n jobs are in memory, then the
probability that all n are waiting for I/O is approximately pn.
- So, with a multiprogramming level (MPL) of n,
the CPU utilization is approximately 1-pn.
- If p=.5 and n=4, then 1-pn = 15/16, which is much better than
1/2, which would occur for monoprogramming (n=1).
- This is a crude model, but it is correct that increasing MPL does
increase CPU utilization up to a point.
- The limitation is memory, which is why we discuss it here
instead of process management. That is, we must have many jobs
loaded at once, which means we must have enough memory for them.
There are other issues as well and we will discuss them.
- Some of the CPU utilization is time spent in the OS executing
context switches so the gains are not a great as the crude model predicts.
Homework: 1, 2 (typo in book; figure 4.21 seems
irrelevant).
4.1.4: Analysis of Multiprogramming System Performance
Skipped
4.1.5: Relocation and Protection
Relocation was discussed as part of linker lab and at the
beginning of this chapter.
When done dynamically, a simple method is to have a
base register whose value is added to every address by the
hardware.
Similarly a limit register is checked by the
hardware to be sure that the address (before the base register is
added) is not bigger than the size of the program.
The base and limit register are set by the OS when the job starts.
4.2: Swapping
Moving the entire processes between disk and memory is called
swapping.
Multiprogramming with Variable Partitions
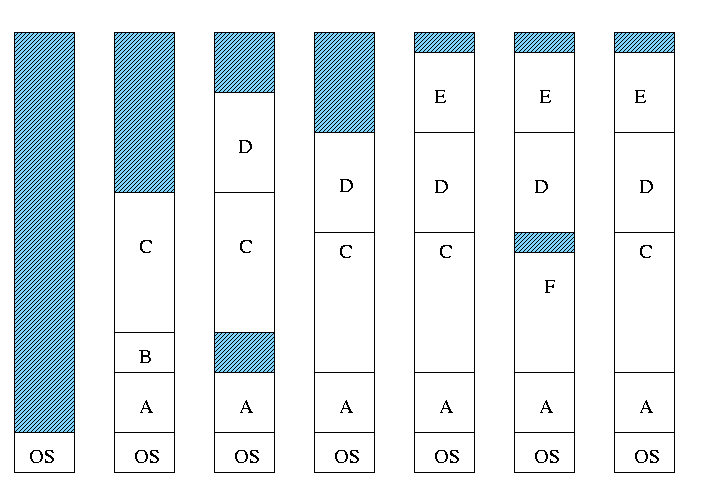 Both the number and size of the partitions change with time.
Both the number and size of the partitions change with time.
-
IBM OS/MVT (multiprogramming with a varying number of tasks).
-
Also early PDP-10 OS.
-
Job still has only one segment (as with MFT). That is, the
virtual address is contiguous.
-
The physical address is also contiguous, that is, the process is
stored as one piece in memory.
-
The job can be of any
size up to the size of the machine and the job size can change
with time.
-
A single ready list.
-
A job can move (might be swapped back in a different place).
-
This is dynamic address translation (during run time).
-
Must perform an addition on every memory reference (i.e. on every
address translation) to add the start address of the partition.
-
Called a DAT (dynamic address translation) box by IBM.
-
Eliminates internal fragmentation.
-
Find a region the exact right size (leave a hole for the
remainder).
-
Not quite true, can't get a piece with 10A755 bytes. Would
get say 10A760. But internal fragmentation is much
reduced compared to MFT. Indeed, we say that internal
fragmentation has been eliminated.
-
Introduces external fragmentation, i.e., holes
outside any region.
-
What do you do if no hole is big enough for the request?
- Can compactify
-
Transition from bar 3 to bar 4 in diagram below.
-
This is expensive.
-
Not suitable for real time (MIT ping pong).
- Can swap out one process to bring in another, e.g., bars 5-6
and 6-7 in the diagram.
- There are more processes than holes. Why?
-
Because next to a process there might be a process or a hole
but next to a hole there must be a process
-
So can have “runs” of processes but not of holes
-
If after a process one is equally likely to have a process or
a hole, you get about twice as many processes as holes.
- Base and limit registers are used.
-
Storage keys not good since compactifying or moving would require
changing many keys.
-
Storage keys might need a fine granularity to permit the
boundaries to move by small amounts (to reduce internal
fragmentation). Hence many keys would need to be changed.
Homework: 3
MVT Introduces the “Placement Question”
That is, which hole (partition) should one choose?
- Best fit, worst fit, first fit, circular first fit, quick fit, Buddy
-
Best fit doesn't waste big holes, but does leave slivers and
is expensive to run.
-
Worst fit avoids slivers, but eliminates all big holes so a
big job will require compaction. Even more expensive than best
fit (best fit stops if it finds a perfect fit).
-
Quick fit keeps lists of some common sizes (but has other
problems, see Tanenbaum).
-
Buddy system
-
Round request to next highest power of two (causes
internal fragmentation).
-
Look in list of blocks this size (as with quick fit).
-
If list empty, go higher and split into buddies.
-
When returning coalesce with buddy.
-
Do splitting and coalescing recursively, i.e. keep
coalescing until can't and keep splitting until successful.
-
See Tanenbaum for more details (or an algorithms book).
- A current favorite is circular first fit, also known as next fit.
-
Use the first hole that is big enough (first fit) but start
looking where you left off last time.
-
Doesn't waste time constantly trying to use small holes that
have failed before, but does tend to use many of the big holes,
which can be a problem.
- Buddy comes with its own implementation. How about the others?
Homework: 5.
4.2.1: Memory Management with Bitmaps
Divide memory into blocks and associate a bit with each block, used
to indicate if the corresponding block is free or allocated. To find
a chunk of size N blocks need to find N consecutive bits
indicating a free block.
The only design question is how much memory does one bit represent.
- Big: Serious internal fragmentation.
- Small: Many bits to store and process.
4.2.2: Memory Management with Linked Lists
- Each item on list gives the length and starting location of the
corresponding region of memory and says whether it is a Hole or Process.
- The items on the list are not taken from the memory to be
used by processes.
- Keep in order of starting address.
- Merge adjacent holes
- Singly linked
Memory Management using Boundary Tags
-
Use the same memory for list items as for processes
-
Don't need an entry in linked list for blocks in use, just
the avail blocks are linked.
-
The avail blocks are in fact doubly linked since a deletion can
occur from the middle (when one block is returned and will merge
with an already avail block).
-
For the blocks currently in use, just need a hole/process bit at
each end and the length. Keep this in the block itself.
- See Knuth, The Art of Computer Programming vol 1.
MVT also introduces the “Replacement Question”
That is, which victim should we swap out?
Note that this is an example of the suspend arc mentioned in process
scheduling.
We will study this question more when we discuss
demand paging in which case
we swap out part of a process.
Considerations in choosing a victim
- Cannot replace a job that is pinned,
i.e. whose memory is tied down. For example, if Direct Memory
Access (DMA) I/O is scheduled for this process, the job is pinned
until the DMA is complete.
- Victim selection is a medium term scheduling decision
- A job that has been in a wait state for a long time is a good
candidate.
- Often choose as a victim a job that has been in memory for a long
time.
- Another question is how long should it stay swapped out.
- For demand paging, where swaping out a page is not as drastic as
swapping out a job, choosing the victim is an important memory
management decision and we shall study several policies,