Operating Systems
================ Start Lecture #5 ================
2.4.2: The Readers and Writers Problem
- Two classes of processes.
- Readers, which can work concurrently.
- Writers, which need exclusive access.
- Must prevent 2 writers from being concurrent.
- Must prevent a reader and a writer from being concurrent.
- Must permit readers to be concurrent when no writer is active.
- Perhaps want fairness (e.g., freedom from starvation).
- Variants
- Writer-priority readers/writers.
- Reader-priority readers/writers.
Quite useful in multiprocessor operating systems and database systems.
The “easy way
out” is to treat all processes as writers in which case the problem
reduces to mutual exclusion (P and V). The disadvantage of the easy
way out is that you give up reader concurrency.
Again for more information see the web page referenced above.
2.4.3: The Sleeping Barber Problem
Skipped.
2.4A: Summary of 2.3 and 2.4
We began with a problem (wrong answer for x++ and x==) and used it to
motivate the Critical Section Problem for which we provided a
(software) solution.
We then defined (binary) Semaphores and showed that a
Semaphore easily solves the critical section problem and doesn't
require knowledge of how many processes are competing for the critical
section. We gave an implementation using Test-and-Set.
We then gave an operational definition of Semaphore (which is
not an implementation) and morphed this definition to obtain a
Counting (or Generalized) Semaphore, for which we gave
NO implementation. I asserted that a counting
semaphore can be implemented using 2 binary semaphores and gave a
reference.
We defined the Readers/Writers (or Bounded Buffer) Problem
and showed that it can be solved using counting semaphores (and binary
semaphores, which are a special case).
Finally we briefly discussed some classical problem, but did not
give (full) solutions.
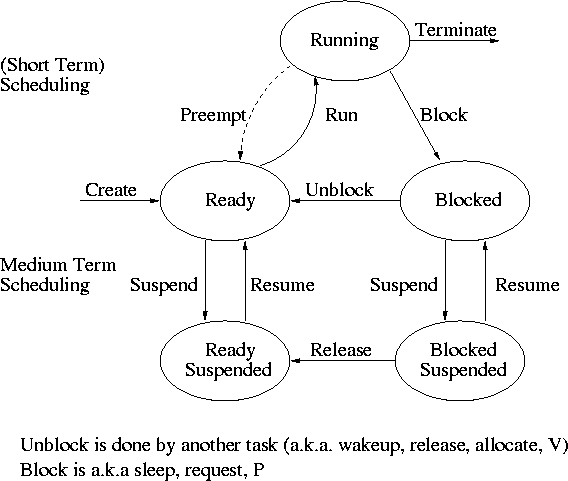
2.5: Process Scheduling
Scheduling processes on the processor is often called “process
scheduling” or simply “scheduling”.
The objectives of a good scheduling policy include
- Fairness.
- Efficiency.
- Low response time (important for interactive jobs).
- Low turnaround time (important for batch jobs).
- High throughput [the above are from Tanenbaum].
- More “important” processes are favored.
- Interactive processes are favored.
- Repeatability. Dartmouth (DTSS) “wasted cycles” and limited
logins for repeatability.
- Fair across projects.
- “Cheating” in unix by using multiple processes.
- TOPS-10.
- Fair share research project.
- Degrade gracefully under load.
Recall the basic diagram describing process states
For now we are discussing short-term scheduling, i.e., the arcs
connecting running <--> ready.
Medium term scheduling is discussed later.
Preemption
It is important to distinguish preemptive from non-preemptive
scheduling algorithms.
- Preemption means the operating system moves a process from running
to ready without the process requesting it.
- Without preemption, the system implements “run to completion (or
yield or block)”.
- The “preempt” arc in the diagram.
- We do not consider yield (a solid arrow from running to ready).
- Preemption needs a clock interrupt (or equivalent).
- Preemption is needed to guarantee fairness.
- Preemption is found in all modern general purpose operating systems.
- Even non preemptive systems can be multiprogrammed (e.g., when processes
block for I/O).
Deadline scheduling
This is used for real time systems. The objective of the scheduler is
to find a schedule for all the tasks (there are a fixed set of tasks)
so that each meets its deadline. The run time of each task is known
in advance.
Actually it is more complicated.
- Periodic tasks
- What if we can't schedule all task so that each meets its deadline
(i.e., what should be the penalty function)?
- What if the run-time is not constant but has a known probability
distribution?
We do not cover deadline scheduling in this course.
The name game
There is an amazing inconsistency in naming the different
(short-term) scheduling algorithms. Over the years I have used
primarily 4 books: In chronological order they are Finkel, Deitel,
Silberschatz, and Tanenbaum. The table just below illustrates the
name game for these four books. After the table we discuss each
scheduling policy in turn.
Finkel Deitel Silbershatz Tanenbaum
-------------------------------------
FCFS FIFO FCFS FCFS
RR RR RR RR
PS ** PS PS
SRR ** SRR ** not in tanenbaum
SPN SJF SJF SJF
PSPN SRT PSJF/SRTF -- unnamed in tanenbaum
HPRN HRN ** ** not in tanenbaum
** ** MLQ ** only in silbershatz
FB MLFQ MLFQ MQ
Remark: For an alternate organization of the
scheduling algorithms (due to Eric Freudenthal and presented by him
Fall 2002) click here.
First Come First Served (FCFS, FIFO, FCFS, --)
If the OS “doesn't” schedule, it still needs to store the list of
ready processes in some manner. If it is a queue you get FCFS. If it
is a stack (strange), you get LCFS. Perhaps you could get some sort
of random policy as well.
-
Only FCFS is considered.
-
Non-preemptive.
-
The simplist scheduling policy.
-
In some sense the fairest since it is first come first served.
But perhaps that is not so fair--Consider a 1 hour job submitted
one second before a 3 second job.
-
The most efficient usage of cpu since the scheduler is very fast.
Round Robin (RR, RR, RR, RR)
-
An important preemptive policy.
-
Essentially the preemptive version of FCFS.
-
Note that RR works well if you have a 1 hr job and then a 3 second
job.
-
The key parameter is the quantum size q.
-
When a process is put into the running state a timer is set to q.
-
If the timer goes off and the process is still running, the OS
preempts the process.
-
This process is moved to the ready state (the
preempt arc in the diagram), where it is placed at the
rear of the ready list.
-
The process at the front of the ready list is removed from
the ready list and run (i.e., moves to state running).
-
Note that the ready list is being treated as a queue.
Indeed it is sometimes called the ready queue, but not by me
since for other scheduling algorithms it is not accessed in a
FIFO manner.
-
When a process is created, it is placed at the rear of the ready list.
-
As q gets large, RR approaches FCFS.
Indeed if q is larger that the longest time a process can run
before terminating or blocking, then RR IS FCFS.
A good way to see this is to look at my favorite diagram and note
the three arcs leaving running.
They are “triggered” by three conditions: process
terminating, process blocking, and process preempted.
If the first condition to trigger is never preemption, we can
erase the arc and then RR becomes FCFS.
-
As q gets small, RR approaches PS (Processor Sharing, described next)
-
What value of q should we choose?
-
Trade-off
-
Small q makes system more responsive, a long compute-bound job
cannot starve a short job.
-
Large q makes system more efficient since less process switching.
-
A reasonable time for q is about 1ms (millisecond = 1/1000
second).
This means each other job can delay your job by at most 1ms
(plus the context switch time CS, which is much less than 1ms).
Also the overhead is CS/(CS+q), which is small.
Homework: 26, 35, 38.
Homework: Give an argument favoring a large
quantum; give an argument favoring a small quantum.
| Process | CPU Time | Creation Time |
|---|
| P1 | 20 | 0 |
| P2 | 3 | 3 |
| P3 | 2 | 5 |
Homework:
(Remind me to discuss this last one in class next time):
Consider the set of processes in the table below.
When does each process finish if RR scheduling is used with q=1, if
q=2, if q=3, if q=100. First assume (unrealistically) that context
switch time is zero. Then assume it is .1.
Each process performs no
I/O (i.e., no process ever blocks). All times are in milliseconds.
The CPU time is the total time required for the process (excluding any
context switch time). The creation
time is the time when the process is created. So P1 is created when
the problem begins and P3 is created 5 milliseconds later.
If two processes have equal priority (in RR this means if thy both
enter the ready state at the same cycle), we give priority (in RR this
means place first on the queue) to the process with the earliest
creation time.
If they also have the same creation time, then we give priority to the
process with the lower number.
Note: Do the homework problem assigned at the end of last
lecture.
Processor Sharing (PS, **, PS, PS)
Merge the ready and running states and permit all ready jobs to be run
at once. However, the processor slows down so that when n jobs are
running at once, each progresses at a speed 1/n as fast as it would if
it were running alone.
-
Clearly impossible as stated due to the overhead of process
switching.
-
Of theoretical interest (easy to analyze).
-
Approximated by RR when the quantum is small. Make
sure you understand this last point. For example,
consider the last homework assignment (with zero context switch time)
and consider q=1, q=.1, q=.01, etc.
-
Show what happens for 3 processes, A, B, C, each requiring 3
seconds of CPU time. A starts at time 0, B at 1 second, C at 2.
-
Also do three processes all starting at 0. One requires 1ms, one
100ms and one 10 seconds.
Redo this for FCFS and RR with quantum 1 ms and 10 ms.
Note that this depends on the order the processes happen to be
processed in.
The effect is huge for FCFS, modest for RR with modest quantum,
and non-existent for PS.
Remember to compare this when doing SJF.
Homework: 34.
Variants of Round Robin
- State dependent RR
- Same as RR but q is varied dynamically depending on the state
of the system.
- Favor processes holding important resources.
- For example, non-swappable memory.
- Perhaps this should be considered medium term scheduling
since you probably do not recalculate q each time.
-
External priorities: RR but a user can pay more and get
bigger q. That is one process can be given a higher priority than
another. But this is not an absolute priority: the lower priority
(i.e., less important) process does get to run, but not as much as
the higher priority process.
Priority Scheduling
Each job is assigned a priority (externally, perhaps by charging
more for higher priority) and the highest priority ready job is run.
-
Similar to “External priorities” above
-
If many processes have the highest priority, use RR among them.
-
Can easily starve processes (see aging below for fix).
-
Can have the priorities changed dynamically to favor processes
holding important resources (similar to state dependent RR).
-
Many policies can be thought of as priority scheduling in which we
run the job with the highest priority (with different notions of
priority for different policies).
For example, FIFO and RR are priority scheduling where the
priority is the time spent on the ready list/queue.
Priority aging
As a job is waiting, raise its priority so eventually it will have the
maximum priority.
- This prevents starvation (assuming all jobs terminate or the
policy is preemptive).
-
Starvation means that some process is never run, because it
never has the highest priority. It is also starvation, if process
A runs for a while, but then is never able to run again, even
though it is ready.
The formal way to say this is “No job can remain in the ready
state forever”.
-
There may be many processes with the maximum priority.
-
If so, can use FIFO among those with max priority (risks
starvation if a job doesn't terminate) or can use RR.
-
Can apply priority aging to many policies, in particular to priority
scheduling described above.
Selfish RR (SRR, **, SRR, **)
-
Preemptive.
-
Perhaps it should be called “snobbish RR”.
-
“Accepted processes” run RR.
-
Accepted process have their priority increase at rate b>
=0.
-
A new process starts at priority 0; its priority increases at rate a>=0.
-
A new process becomes an accepted process when its priority
reaches that of an accepted process (or when there are no accepted
processes).
-
Once a process is accepted it remains accepted until it terminates.
-
Note that at any time all accepted processes have same priority.
-
If b>=a, get FCFS.
-
If b=0, get RR.
-
If a>b>0, it is interesting.
-
If b>a=0, you get RR in "batches". This is similar to
n-step scan for disk I/O.
Shortest Job First (SPN, SJF, SJF, SJF)
Sort jobs by total execution time needed and run the shortest first.
-
Nonpreemptive
-
First consider a static situation where all jobs are available in
the beginning and we know how long each one takes to run. For
simplicity lets consider “run-to-completion”, also called
“uniprogrammed” (i.e., we don't even switch to another process
on I/O). In this situation, uniprogrammed SJF has the shortest
average waiting time.
-
Assume you have a schedule with a long job right before a
short job.
-
Consider swapping the two jobs.
-
This decreases the wait for
the short by the length of the long job and increases the wait of the
long job by the length of the short job.
-
This decreases the total waiting time for these two.
-
Hence decreases the total waiting for all jobs and hence decreases
the average waiting time as well.
-
Hence, whenever a long job is right before a short job, we can
swap them and decrease the average waiting time.
-
Thus the lowest average waiting time occurs when there are no
short jobs right before long jobs.
-
This is uniprogrammed SJF.
-
In the more realistic case of true SJF where the scheduler
switches to a new process when the currently running process
blocks (say for I/O), we should call the policy shortest
next-CPU-burst first.
-
The difficulty is predicting the future (i.e., knowing in advance
the time required for the job or next-CPU-burst).
-
This is an example of priority scheduling.
Homework: 39, 40 (note that when he says RR with
each process getting its fair share, he means PS).
Preemptive Shortest Job First (PSPN, SRT, PSJF/SRTF, --)
Preemptive version of above
- Permit a process that enters the ready list to preempt the running
process if the time for the new process (or for its next burst) is
less than the remaining time for the running process (or for
its current burst).
- It will never happen that a process in the ready list
will require less time than the remaining time for the currently
running process. Why?
Ans: When the process joined the ready list it would have started
running if the current process had more time remaining. Since
that didn't happen the current job had less time remaining and now
it has even less.
- Can starve processs that require a long burst.
- This is fixed by the standard technique.
- What is that technique?
Ans: Priority aging.
- Another example of priority scheduling.
Highest Penalty Ratio Next (HPRN, HRN, **, **)
Run the process that has been “hurt” the most.
-
For each process, let r = T/t; where T is the wall clock time this
process has been in system and t is the running time of the
process to date.
-
If r=2.5, that means the job has been running 1/2.5 = 40% of the
time it has been in the system.
-
We call r the penalty ratio and run the process having
the highest r value.
-
We must worry about a process that just enters the system
since t=o and hence the ratio is undefined.
Define t to be the max of 1 and the running time to date.
Since now t is at least 1, the ratio is always defined.
-
HPRN is normally defined to be non-preemptive (i.e., the system
only checks r when a burst ends), but there is an preemptive analogue
- When putting process into the run state compute the time at
which it will no longer have the highest ratio and set a timer.
- When a process is moved into the ready state, compute its ratio
and preempt if needed.
- HRN stands for highest response ratio next and means the same thing.
- This policy is yet another example of priority scheduling
Multilevel Queues (**, **, MLQ, **)
Put different classes of processs in different queues
- Processs do not move from one queue to another.
- Can have different policies on the different queues.
For example, might have a background (batch) queue that is FCFS and one or
more foreground queues that are RR.
- Must also have a policy among the queues.
For example, might have two queues, foreground and background, and give
the first absolute priority over the second
- Might apply aging to prevent background starvation.
- But might not, i.e., no guarantee of service for background
processes. View a background process as a “cycle soaker”.
- Might have 3 queues, foreground, background, cycle soaker.
Multilevel Feedback Queues (FB, MFQ, MLFBQ, MQ)
As with multilevel queues above we have many queues, but now processs
move from queue to queue in an attempt to
dynamically separate “batch-like” from interactive processs so that
we can favor the latter.
- Run processs from the highest priority nonempty queue in a RR manner.
- When a process uses its full quanta (looks a like batch process),
move it to a lower priority queue.
- When a process doesn't use a full quanta (looks like an interactive
process), move it to a higher priority queue.
- A long process with frequent (perhaps spurious) I/O will remain
in the upper queues.
- Might have the bottom queue FCFS.
- Many variants.
For example, might let process stay in top queue 1 quantum, next queue 2
quanta, next queue 4 quanta (i.e. return a process to the rear of the
same queue it was in if the quantum expires).
Theoretical Issues
Considerable theory has been developed.
- NP completeness results abound.
- Much work in queuing theory to predict performance.
- Not covered in this course.
Medium-Term Scheduling
In addition to the short-term scheduling we have discussed, we add
medium-term scheduling in which
decisions are made at a coarser time scale.
- Called memory scheduling by Tanenbaum (part of three level scheduling).
- Suspend (swap out) some process if memory is over-committed.
- Criteria for choosing a victim.
- How long since previously suspended.
- How much CPU time used recently.
- How much memory does it use.
- External priority (pay more, get swapped out less).
- We will discuss medium term scheduling again when we study memory
management.
Long Term Scheduling
- “Job scheduling”. Decide when to start jobs, i.e., do not
necessarily start them when submitted.
- Force user to log out and/or block logins if over-committed.
- CTSS (an early time sharing system at MIT) did this to insure
decent interactive response time.
- Unix does this if out of processes (i.e., out of PTEs).
- “LEM jobs during the day” (Grumman).
- Called admission scheduling by Tanenbaum (part of three level scheduling).
- Many supercomputer sites.
2.5.4: Scheduling in Real Time Systems
Skipped
2.5.5: Policy versus Mechanism
Skipped.
2.5.6: Thread Scheduling
Skipped.
Research on Processes and Threads
Skipped.