Operating Systems
================ Start Lecture #24 ================
RAID (Redundant Array of Inexpensive Disks)
- The name RAID is from Berkeley.
-
IBM changed the name to Redundant Array of Independent
Disks. I wonder why?
-
A simple form is mirroring, where two disks contain the
same data.
-
Another simple form is striping (interleaving) where consecutive
blocks are spread across multiple disks. This helps bandwidth, but is
not redundant. Thus it shouldn't be called RAID, but it sometimes is.
-
One of the normal RAID methods is to have N (say 4) data disks and one
parity disk. Data is striped across the data disks and the bitwise
parity of these sectors is written in the corresponding sector of the
parity disk.
-
On a read if the block is bad (e.g., if the entire disk is bad or
even missing), the system automatically reads the other blocks in the
stripe and the parity block in the stripe. Then the missing block is
just the bitwise exclusive or of all these blocks.
-
For reads this is very good. The failure free case has no penalty
(beyond the space overhead of the parity disk). The error case
requires N+1 (say 5) reads.
-
A serious concern is the small write problem. Writing a sector
requires 4 I/O. Read the old data sector, compute the change, read
the parity, compute the new parity, write the new parity and the new
data sector. Hence one sector I/O became 4, which is a 300% penalty.
-
Writing a full stripe is not bad. Compute the parity of the N
(say 4) data sectors to be written and then write the data sectors and
the parity sector. Thus 4 sector I/Os become 5, which is only a 25%
penalty and is smaller for larger N, i.e., larger stripes.
-
A variation is to rotate the parity. That is, for some stripes
disk 1 has the parity, for others disk 2, etc. The purpose is to not
have a single parity disk since that disk is needed for all small
writes and could become a point of contention.
5.4.2: Disk Formatting
Skipped.
5.4.3: Disk Arm Scheduling Algorithms
There are three components to disk response time: seek, rotational
latency, and transfer time. Disk arm scheduling is concerned with
minimizing seek time by reordering the requests.
These algorithms are relevant only if there are several I/O
requests pending. For many PCs this is not the case. For most
commercial applications, I/O is crucial and there are often many
requests pending.
- FCFS (First Come First Served): Simple but has long delays.
-
Pick: Same as FCFS but pick up requests for cylinders that are
passed on the way to the next FCFS request.
-
SSTF or SSF (Shortest Seek (Time) First): Greedy algorithm. Can
starve requests for outer cylinders and almost always favors middle
requests.
- Scan (Look, Elevator): The method used by an old fashioned
jukebox (remember “Happy Days”) and by elevators. The disk arm
proceeds in one direction picking up all requests until there are no
more requests in this direction at which point it goes back the other
direction. This favors requests in the middle, but can't starve any
requests.
-
C-Scan (C-look, Circular Scan/Look): Similar to Scan but only
service requests when moving in one direction. When going in the
other direction, go directly to the furthest away request. This
doesn't favor any spot on the disk. Indeed, it treats the cylinders
as though they were a clock, i.e. after the highest numbered cylinder
comes cylinder 0.
- N-step Scan: This is what the natural implementation of Scan
gives.
- While the disk is servicing a Scan direction, the controller
gathers up new requests and sorts them.
- At the end of the current sweep, the new list becomes the next
sweep.
Minimizing Rotational Latency
Use Scan based on sector numbers not cylinder number. For
rotational latency Scan is the same as C-Scan. Why?
Ans: Because the disk only rotates in one direction.
Homework: 24, 25
5.4.4: Error Handling
Disks error rates have dropped in recent years. Moreover, bad
block forwarding is normally done by the controller (or disk electronics) so
this topic is no longer as important for OS.
5.5: Clocks
Also called timers.
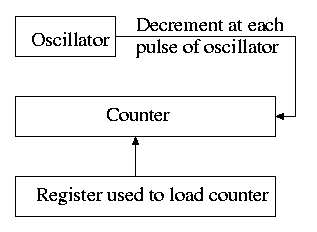
5.5.1: Clock Hardware
- Generates an interrupt when timer goes to zero
- Counter reload can be automatic or under software (OS) control.
- If done automatically, the interrupt occurs periodically and thus
is perfect for generating a clock interrupt at a fixed period.
5.5.2: Clock Software
-
Time of day (TOD): Bump a counter each tick (clock interupt). If
counter is only 32 bits must worry about overflow so keep two
counters: low order and high order.
-
Time quantum for RR: Decrement a counter at each tick. The quantum
expires when counter is zero. Load this counter when the scheduler
runs a process. This is presumably what you did for the (processor)
scheduling lab.
-
Accounting: At each tick, bump a counter in the process table
entry for the currently running process.
-
Alarm system call and system alarms:
-
Users can request an alarm at some future time.
-
The system also on occasion needs to schedule some of its own
activities to occur at specific times in the future (e.g. turn off
the floppy motor).
-
The conceptually simplest solution is to have one timer for
each event.
-
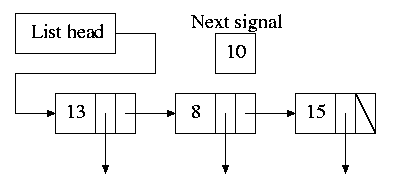
Instead, we simulate many timers with just one.
-
The data structure on the right works well. There is one node
for each event.
-
The first entry in each node is the time after the
preceding event that this event's alarm is to ring.
-
For example, if the time is zero, this event occurs at the
same time as the previous event.
-
The second entry in the node is a pointer to the action to perform.
-
At each tick, decrement next-signal.
-
When next-signal goes to zero,
process the first entry on the list and any others following
immediately after with a time of zero (which means they are to be
simultaneous with this alarm). Then set next-signal to the value
in the next alarm.
- Profiling
- Want a histogram giving how much time was spent in each 1KB
(say) block of code.
- At each tick check the PC and bump the appropriate counter.
- A user-mode program can determine the software module
associated with each 1K block.
- If we use finer granularity (say 10B instead of 1KB), we get
increased accuracy but more memory overhead.
Homework: 27