================ Start Lecture #21 ================
We have seen that the fastest comparison-based sorting algorithms run in time Θ(Nlog(N)), where N is the number of items to sort. In this section we are going to develop faster algorithms. Hence they must not be comparison-based algorithms.
We make a key assumption, we are sorting items whose keys are integers in a bounded range [0, R-1].
Question: Let's start with a special case R=N so we are sorting N items with integer keys from 0 to N-1. As usual we assume there are no duplicate keys. Also as usual we remark that it is easy to lift this restriction. How should we do this sort?
Answer: That was a trick question. You don't even have to look at the input. If you tell me to sort 10 integers in the range 0...9 and there are no duplicates, I know the answer is {0,1,2,3,4,5,6,7,8,9}. Why? Because, if there are no duplicates, the input must consist of one copy of each integer from 0 to 10.
OK, let's drop the assumption that R=N. So we have N items (k,e),
with each k an integer, no duplicate ks, and 0≤k<R. The trick is
that we can use k to decide where to (temporarily) store e.
Algorithm preBucketSort(S)
input: A sequence S of N items with integer keys in range [0,N)
output: Sequence S sorted in increasing order of the keys.
let B be a vector of R elements,
each initially a special marker indicating empty
while (not S.isEmpty())
(k,e) ← S.remove(S.first())
B[k] ← e <==== the key idea (not a comparison)
for i ← 0 to R-1 do
if (B[i] not special marker) then
S.insertLast((i,B[i])
To convert this algorithm into bucket sort we drop the artificial
assumption that there are not duplicates. Now instead of a vector of
items we need a vector of buckets, where a bucket is a sequence of
items.
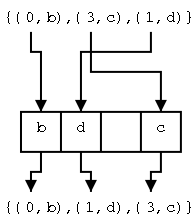
Algorithm BucketSort(S)
input: A sequence S of N items with integer keys in range [0,N)
output: Sequence S sorted in increasing order of the keys.
let B be a vector of R sequences of items
each initially empty
while (not S.isEmpty())
(k,e) ← S.remove(S.first())
B[k].insertLast(e) <==== the key idea
for i ← 0 to R-1 do
while (not B[i].isEmpty())
S.insertLast((i,B[i].remove(B[i].first())))
The first loop has N iterations each of which run in time Θ(1), so the loop requires time Θ(N). The for loop has R iterations so the while statement is executed R times. Each while statement requires time Θ(1) (excluding the body of the while) so all of them require time Θ(N) The total number of iterations of all the inner while loops is again N and each again requires time Θ(1), so the time for all inner iterations is Θ(N).
The previous paragraph shows that the complexity is Θ(N)+Θ(R) = Θ(N+R).
So bucket-sort is a winner if R is not too big. For example if R=O(N), then bucket-sort requires time only Θ(N). Indeed if R=o(Nlog(N)), bucket-sort is (asymptotically) faster than any comparison based sorting algorithm (using worst case analysis).
Definition: We call a sort stable if equal elements remain in the same relative position. Stated more formally: for any two items (ki,ei) and (kj,ej) such that item (ki,ei) precedes item (kj,ej) in S (i.e., i<j), then item (ki,ei) precedes item (kj,ej) after sorting as well.
Stability is often convenient as we shall see in the next section on radix-sort. We note that bucket-sort is stable since we treated each bucket in a fifo manner inserting at the rear and removing from the front.
Let's extend our sorting study from keys that are integers to keys that are pairs of integers. The first question to ask is, given two keys (k,m) and (k',m'), which is larger? Note that (k,m) is just the key; an item would be written ((k,m),e).
Definition: The lexicographical (dictionary) ordering on pairs of integers is defined by declaring (k,m) < (k',m') if either
Note that this really is dictionary order:
canary < eagle < egret < heron
10 < 11 < 12 < 2
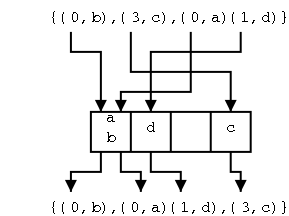
Algorithm radix-sort-on-pairs
input: A sequence S of N items with keys
pairs of integers in the range [0,N)
Write elements of S as ((k,m),e)
output: Sequence S lexicographically sorted on the keys
bucket-sort(S) using m as the key
bucket-sort(S) using k as the key
Do an example of radix sorting on pairs.
Do an incorrect sort but starting with the most significant element of the pair.
Do an incorrect sort by using an individual sort that is not stable.
What if the keys are triples or in general d-tuples?
The answer is ...
Homework: R-4.15
Theorem: Let S be a sequence of N items each of which has a key (k1,k2,...kd), where each ki is in integer in the range [0,R). We can sort S lexicographically in time O(n(N+R)) using radix-sort.
Insertion sort or bubble sort are not suitable for general sorting of large problems because their running time is quadratic in N, the number of items. For small problems, when time is not an issue, these are attractive because they are so simple. Also if the input is almost sorted, insertion sort is fast since it can be implemented in a way that is O(N+A), where A is the number of inversions, (i.e., the number of pairs out of order).
Heap-sort is a fine general-purpose sort with complexity Θ(Nlog(N)), which is optimal for comparison-based sorting. Also heap-sort can be executed in place (i.e., without much extra memory beyond the data to be sorted). (The coverage of in-place sorting was ``unofficial'' in this course.) If the in-place version of heap-sort fits in memory (i.e., if the data is less than the size of memory), heap-sort is very good.
Merge-sort is another optimal Θ(Nlog(N)) sort. It is not easy to do in place so is inferior for problems that can fit in memory. However, it is quite good when the problem is too large to fit in memory and must be done ``out-of-core''. We didn't discuss this issue, but the merges can be done with two input and one output file (this is not trivial to do well, you want to utilize the available memory in the most efficient manner).
Quick-sort is hard to evaluate. The version with the fast median algorithm is fine theoretically (worst case again Θ(Nlog(N)) but not used because of large constant factors in the fast median. Randomized quick-sort has a low expected time but a poor worst-case time. It can be done in place and is quite fast in that case, often the fastest. But the quadratic worst case is a fear (and a non-starter for many real-time applications).
Bucket and radix sort are wonderful when they apply, i.e., when the keys are integers in a modest range (R a small multiple of N). For radix sort with d-tuples the complexity is Θ(d(N+R)) so if d(N+R) is o(Nlog(N)), radix sort is asymptotically faster than any comparison based sort (e.g., heap-, insertion-, merge-, or quick-sort).