================ Start Lecture #19 ================
NOTEs:
Might come back to this if time permits.
We already did a sorting technique in chapter 2. Namely we inserted items into a priority queue and then removed the minimum each time. When we use a heap to implement the priority, the resulting sort is called heap-sort and is asymptotically optimal. That is, its complexity of O(Nlog(N)) is as fast as possible if we only use comparisons (proved in 4.2 below)
The idea is that if you divide an enemy into small pieces, each piece, and hence the enemy, can be conquered. When applied to computer problems divide-and-conquer involves three steps.
In order to prevent an infinite sequence of recursions, we need to define a stopping condition, i.e., a predicate that informs us when to stop dividing (because the problem is small enough to solve directly).
This turns out to be so easy that it is perhaps surprising that it is asymptotically optimal. The key observation is that merging two sorted lists is fast (the time is linear in the size of the lists).
The steps are
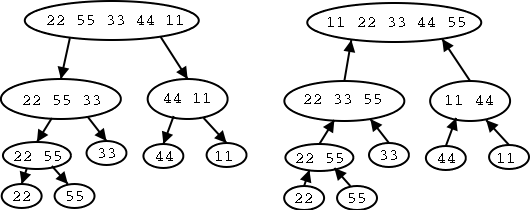
Example:: Sort {22, 55, 33, 44, 11}.
Expanding the recursion one level gives.
Expanding again gives
Finally there still is one recursion to do so we get.
Hopefully there is a better way to describe this action. How about the following picture. The left tree shows the dividing. The right shows the result of the merging.
Definition: We call the above tree the merge-sort-tree.
Homework: Draw the merge sort tree for {55, 33, 11, 22, 44}.
In a merge-sort tree the left and right children of a node with A elements have ⌈A/2⌉ and ⌊A/2⌋ elements respectively.
Theorem: Let n be the size of the sequence to be sorted. If n is a power of 2, say n=2k, then the height of the merge-sort tree is log(n)=k. In general n = ⌈log(n)⌉.
Proof: The power of 2 case is part of problem set 4. I will do n=2k+1. When we divide the sequence into 2, the larger is ⌈n/2⌉=2k-1+1: To see this write 2k+1 in binary. When we keep dividing and look at the larger piece (i.e., go down the leftmost branch of the tree) we will eventually get to 3=21+1. We have divided by 2 k-1 times so are at depth k-1. But we have to go two more times (getting 2 and then 1) to get one element. So the depth is of this element is k+1 and hence the height is at least k+1. The other leaves are all at height no more than k+1 (in fact they are all k). Thus the height of the tree is exactly k+1.
The rest is part of problem set 2. Here is the idea. If you increase the number of elements in the root, you do not decrease the height. If n is not a power of 2, it is between two powers of 2 and hence the height is between the heights for these powers of two. My calculation for 1 more than a power of 2, tells you what the height must be.
Problem Set 4, problem 1. Prove the theorem when n is a power of 2. Prove the theorem for n not a power of 2 either by finishing my argument or coming up with a new one.
The reason we need the theorem is that we will show that merge-sort spends time O(n) at each level of the tree and hence spends time O(n*height) in total. The theorem shows that this is O(nlog(n)).
This is quite clear. View each sequence as a deck of cards face up. Look at the top of each deck and take the smaller card. Keep going. When one deck runs out take all the cards from the other. This is clearly constant time per card and hence linear in the number of cards Θ(#cards).
Unfortunately this doesn't look quite so clear in pseudo code when we write it in terms of the ADT for sequences. Here is the algorithm essentially copied from the book. At least the comments are clear.
Algorithm merge(S1, S2, S):
Input: Sequences S1 and S2 sorted in nondecreasing order,
and an empty sequence S
Output: Sequence S contains the elements previously in S1 and S2
sorted in nondecreasing order. S1 and S2 now empty.
{Keep taking smaller first element until one sequence is empty}
while (not(S1.isEmpty() or S2.isEmpty()) do
if S1.first().element()<S2.first().element() then
{move first element of S1 to end of S}
S.insertLast(S1.remove(S1.first())
else
{move first element of S2 to end of S}
S.insertLast(S2.remove(S2.first())
{Now take the rest of the nonempty sequence.}
{We simply take the rest of each sequence.}
{Move the remaining elements of S1 to S
while (not S1.isEmpty()) do
S.insertLast(S1.remove(S1.first())
{Move the remaining elements of S2 to S
while (not S2.isEmpty()) do
S.insertLast(S2.remove(S2.first())
Homework: R-4.2
Examining the code we see that each iteration of each loop removes an element from either S1 or S2. Hence the total number of iterations is S1.size()+S2.size(). Since each iteration requires constant time we get the following theorem.
Theorem: Merging two sorted sequences takes time
Θ(n+m), where n and m are the sizes of the two sequences.
The Running Time of Merge-Sort
We characterize the time in terms of the merge-sort tree. We assign to each node of the tree the time to do the divide and merge associated with that node and to invoke (but not to execute) the recursive calls. So we are essentially charging the node for the divide and combine steps, but not the solve recursively.
This does indeed account for all the time. Illustrate this with the example tree I drew at the beginning.
For the remainder of the analysis we assume that the size of the sequence to be sorted is n, which is a power of 2. It is easy to extend this to arbitrary n as we did for the theorem that is a part of problem set 4.
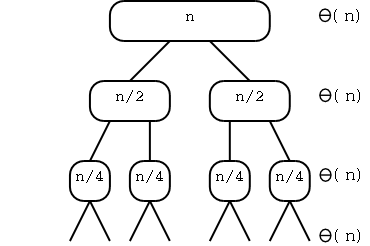 Now much time is charged to the root? The divide step takes time
proportional to the number of elements in S, which is n. The combine
step takes time proportional to the sum of the number of elements in
S1 and the number of elements in S1. But this is again n. So the
root node is charged Θ(n).
Now much time is charged to the root? The divide step takes time
proportional to the number of elements in S, which is n. The combine
step takes time proportional to the sum of the number of elements in
S1 and the number of elements in S1. But this is again n. So the
root node is charged Θ(n).
The same argument shows that any node is charged Θ(A), where A is the number of items in the node.
How much time is charged to a child of the root? Remember that we are assuming n is a power of 2. So each child has n/2 elements and is charged a constant times n/2. Since there are two children the entire level is charged Θ(n).
In this way we see that each level is Θ(n). Another way to see this is that the total number of elements in a level is always n and a constant amount of work is done on each.
Now we use the theorem saying that the height is log(n) to conclude that the total time is Θ(nlog(n)). So we have the following theorem.
Theorem: Merge-sort runs in Θ(nlog(n)).
Here is yet another way to see that the complexity is Θ(nlog(n)).
Let t(n) be the worst-case running time for merge-sort on n elements.
Remark: The worst case and the best case just differ by a multiplicative constant. There is no especially easy or hard case for merge-sort.
For simplicity assume n is a power of two. Then we have for some constants B and C
t(1) = B t(n) = 2t(n/2)+Cn if n>1The first line is obvious the second just notes that to solve a problem we must solve 2 half-sized problems and then do work (merge) that is proportional to the size of the original problem.
If we apply the second line to itself we get
t(n) = 2t(n/2)+Cn = 2[2t(n/4)+C(n/2)]+Cn =
22t(n/22)+2Cn
If we apply this i times we get
t(n) = 2it(n/2i)+iCn
When should we stop?
Ans: when we get to the base case t(1). This occurs when
2i=n, i.e. when i=log(n).
t(n) = 2log(n)t(n/2log(n)) + log(n)Cn
= nt(n/n) + log(n)Cn since 2log(n)=n
= nt(1) + log(n)Cn
= nB + Cnlog(n)
which again shows that t(n) is Θ(nlog(n)).