================ Start Lecture #14 ================
Problem Set 3, Problem 1 Write the algorithm closestKeyBefore. It uses the same idea as BinarySearch.
When you do question 1 you will see that the complexity is Θ(log(n)). Proving this is not hard but is not part of the problem set.
When you do question 1 you will see that closestElemBefore, closestKeyAfter, and closestElemAfter are all very similar to closestKeyBefore. Hence they are all logarithmic algorithms. Proving this is not hard but is not part of the problem set.
| Method | Log File | Lookup Table |
|---|---|---|
| findElement | Θ(n) | Θ(log n) |
| insertItem | Θ(1) | Θ(n) |
| removeElement | Θ(n) | Θ(n) |
| closestKeyBefore | Θ(n) | Θ(log n) |
| closestElemBefore | Θ(n) | Θ(log n) |
| closestKeyAfter | Θ(n) | Θ(log n) |
| closestElemAfter | Θ(n) | Θ(log n) |
Our goal now is to find a better implementation so that all the complexities are logarithmic. This will require us to shift from vectors to trees.
This section gives a simple tree-based implementation, which alas fails to achieve the logarithmic bounds we seek. But it is a good start and motivates the AVL trees we study in 3.2 that do achieve the desired bounds.
Definition: A binary search tree is a tree in which each internal node v stores an item such that the keys stored in every node in the left subtree of v are less than or equal to the key at v which is less than or equal to every key stored in the right subtree.
From the definition we see easily that an inorder traversal of the tree visits the internal nodes in nondecreasing order of the keys they store.
You search by starting at the root and going left or right if the desired key is smaller or larger respectively than the key at the current node. If the key at the current node is the key you seek, you are done. If you reach a leaf the desired key is not present.
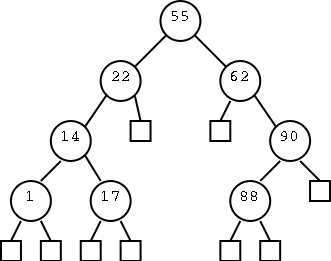
Do some examples using the tree on the right. E.g. search for 17, 80, 55, and 65.
Homework: R-3.1 and R-3.2
Here is the formal algorithm described above.
Algorithm TreeSearch(k,v)
Input: A search key k and a node v of a binary search tree.
Output: A node w in the subtree routed at v such that either
w is internal and k is stored at w or
w is a leaf where k would be stored if it existed
if v is a leaf then
return v
if k=k(v) then
return v
if k<k(v) then
return TreeSearch(k,T.leftChild(v))
if k>k(v) then
return TreeSearch(k,T.rightChild(v))
Draw a tree on the board and illustrate both finding a k and no such key exists.
It is easy to see that only a couple of operations are done per recursive call and that each call goes down a level in the tree. Hence the complexity is O(height).
So the question becomes "How high is a tree with n nodes?". As we saw last chapter the answer is "It depends.".
Next section we will learn a technique for keeping trees low.
To insert an item with key k, first execute w←TreeSearch(k,T.root()). Recall that if w is internal, k is already in w, and if w is a leaf, k "belongs" in w. So we proceed as follows.
Draw examples on the board showing both cases (leaf and internal returned).
Once again we perform a constant amount of work per level of the tree implying that the complexity is O(height).
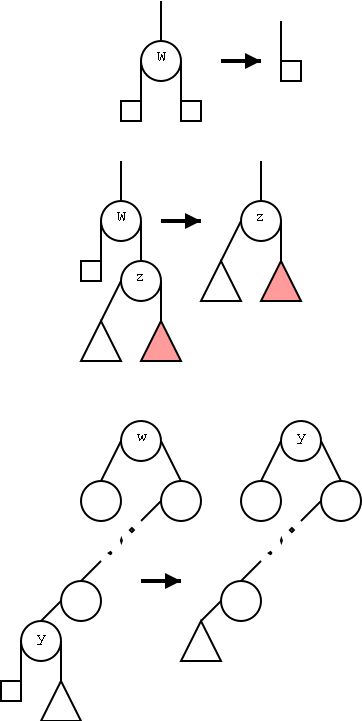
This is the trickiest part, especially in one case as we describe below. The key concern is that we cannot simply remove an item from an internal node and leave a hole as this would make future searches fail. The beginning of the removal technique is familiar: w=TreeSearch(k,T.root()). If w is a leaf, k is not present, which we signal.
If w is internal, we have found k, but now the fun begins.
Returning the element with key k is easy, it is the element
stored in w.
We need to actually remove w, but we cannot leave a hole.
There are three cases.
| Method | Time |
|---|---|
| size, isEmpty | O(1) |
| findElement, insertItem, removeElement | O(h) |
| findAllElements, removeAllElements | O(h+s) |
We have seen that findElement, insertItem, and removeElement have complexity O(height). It is also true, but we will not show it, that one can implement findAllElements and removeAllElements in time O(height+numberOfElements). You might think removeAllElements should be constant time since the resulting tree is just a root so we can make it in constant time. But removeAllElements must also return an iterator that when invoked must generate each of the elements removed.
In a sense that we will not make precise, binary search trees have logarithmic performance since `most' trees have logarithmic height.
Nonetheless we know that there are trees with height Θ(n). You produced several of them for problem set 2. For these trees binary search takes linear time, i.e., is slow. Our goal now is to fancy up the implementation so that the trees are never very high. We can do this since the trees are not handed to us. Instead they are build up using our insertItem method.