================ Start Lecture #7 ================
Remarks:
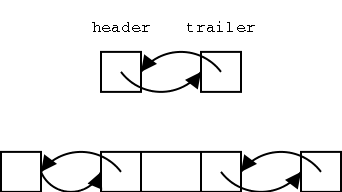
It is convenient to add two special nodes, a header and trailer. The header has just a next component, which links to the first node and the trailer has just a prev component, which links to the last node. For an empty list, the header and trailer link to each other and for a list of size 1, they both link to the only normal node.
In order to proceed from the top (empty) list to the bottom list (with one element), one would need to execute one of the insert methods. Ignoring the abbreviations, this means either insertBefore(p,e) or inserAfter(p,e). But this means that header and/or trailer must be an example of a position, one for which there is no element.
This observation explains the authors' comment above that insertBefore(p,e) cannot be applied if p is the first position. What they mean is that when we permit header and trailer to be positions, then we cannot insertBefore the first position, since that position is the header and the header has no prev. Similarly we cannot insertAfter the final position since that position is the trailer and the trailer has no next. Clearly not the authors' finest hour.
A list object contains three components, the header, the trailer, and the size of the list. Note that the book forgets to update the size for inserts and deletes.
Implementation Comment I have not done the implementation. It is probably easiest to have header and trailer have the same three components as a normal node, but have the prev of header and the next of trailer be some special value (say NULL) that can be tested for.
The position p can be header, but cannot be trailer.
Algorithm insertAfter(p,e): If p is trailer then signal an error size←size+1 // missing in book Create a new node v v.element←e v.prev←p v.next←p.next (p.next).prev←v p.next← v return v
Do on the board the pointer updates for two cases: Adding a node after an ordinary node and after header. Note that they are the same. Indeed, that is what makes having the header and trailer so convenient.
Homework: Write pseudo code for insertBefore(p,e).
Note that insertAfter(header,e) and insertBefore(trailer,e) appear to be the only way to insert an element into an empty list. In particular, insertFirst(e) fails for an empty list since it performs insertBefore(first()) and first() generates an error for an empty list.
We cannot remove the header or trailer. Notice that removing the only element of a one-element list correctly produces an empty list.
Algorithm remove(p) if p is either header or trailer signal an error size←size-1 // missing in book t←p.element (p.prev).next←p.next (p.next).prev←p.prev p.prev←NULL // for security or debugging p.next←NULL return t
| Operation | Array | List |
|---|---|---|
| size, isEmpty | O(1) | O(1) |
| atRank, rankOf, elemAtRank | O(1) | O(n) |
| first, last, before, after | O(1) | O(1) |
| replaceElement, swapElements | O(1) | O(1) |
| replaceAtRank | O(1) | O(n) |
| insertAtRank, removeAtRank | O(n) | O(n) |
| insertFirst, insertLast | O(1) | O(1) |
| insertAfter, insertBefore | O(n) | O(1) |
| remove | O(n) | O(1)
|
Define a sequence ADT that includes all the methods of both vector and list ADTs as well as
Sequences can be implemented as either circular arrays, as we did
for vectors, or doubly linked lists, as we did for lists. Neither
clearly dominates the other. Instead it depends on the relative
frequency of the various operations. Circular arrays are faster for
some and doubly liked lists are faster for others as the table to the
right illustrates.
An ADT for looping through a sequence one element at a time. It has two methods.
When you create the iterator it has all the elements of the sequence. So a typical usage pattern would be
create iterator I for sequence S while I.hasNext process.nextObject
The tree ADT stores elements hierarchically. There is a distinguished root node. All other nodes have a parent of which they are a child. We use nodes and positions interchangeably for trees.
The definition above precludes an empty tree. This is a matter of taste some authors permit empty trees, others do not.
Some more definitions.
We order the children of a binary tree so that the left child comes before the right child.
There are many examples of trees. You learned or will learn tree-structured file systems in 202. However, despite what the book says, for Unix/Linux at least, the file system does not form a tree (due to hard and symbolic links).
These notes can be thought of as a tree with nodes corresponding to the chapters, sections, subsections, etc.
Games like chess are analyzed in terms of trees. The root is the current position. For each node its children are the positions resulting from the possible moves. Chess playing programs often limit the depth so that the number of examined moves is not too large.
The leaves are constants or variables and the internal nodes are binary arithmetic operations (+,-,*,/). The tree is a proper ordered binary tree (since we are considering binary operators). The value of a leaf is the value of the constant or variable. The value of an internal node is obtained by applying the operator to the values of the children (in order).
Evaluate an arithmetic expression tree on the board.
Homework: R-2.2, but made easier by replacing 21 by 10. If you wish you can do the problem in the book instead (I think it is harder).
We have three accessor methods (i.e., methods that permit us to access the nodes of the tree.
We have four query methods that test status.
Finally generic methods that are useful but not related to the tree structure.
Traversing a tree is a systematic method for accessing or "visiting" each node. We will see and analyze three tree traversal algorithms, inorder, preorder, and postorder. They differ in when we visit an internal node relative to its children. In preorder we visit the node first, in postorder we visit it last, and in inorder, which is only defined for binary trees, we visit the node between visiting the left and right children.
Recursion will be a very big deal in traversing trees!!
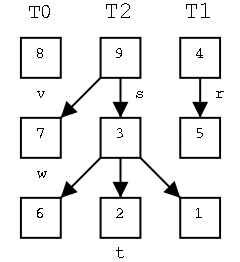
On the right are three trees. The left one just has a root, the right has a root with one leaf as a child, and the middle one has six nodes. For each node, the element in that node is shown inside the box. All three roots are labeled and 2 other nodes are also labeled. That is, we give a name to the position, e.g. the left most root is position v. We write the name of the position under the box. We call the left tree T0 to remind us it has height zero. Similarly the other two are labeled T2 and T1 respectively.
Our goal in this motivation is to calculate the sum the elements in all the nodes of each tree. The answers are, from left to right, 8, 28, and 9.
For a start, lets write an algorithm called treeSum0 that calculates the sum for trees of height zero. In fact the algorithm, will contain two parameters, the tree and a node (position) in that tree, and our algorithm will calculate the sum in the subtree rooted at the given position assuming the position is at height 0. Note this is trivial: since the node has height zero, it has no children and the sum desired is simply the element in this node. So legal invocations would include treeSum0(T0,s) and treeSum0(T2,t). Illegal invocations would include treeSum0(T0,t) and treeSum0(T1,r).
Algorithm treeSum0(T,v) Inputs: T a tree; v a height 0 node of T Output: The sum of the elements of the subtree routed at v Sum←v.element() return Sum
Now lets write treeSum1(T,v), which calculates the sum for a node at height 1. It will use treeSum0 to calculate the sum for each child.
Algorithm treeSum1(T,v)
Inputs: T a tree; v a height 1 node of T
Output: the sum of the elements of the subtree routed at v
Sum←v.element()
for each child c of v
Sum←Sum+treeSum0(T,c)
return Sum
OK. How about height 2?
Algorithm treeSum2(T,v)
Inputs: T a tree; v a height 2 node of T
Output: the sum of the elements of the subtree routed at v
Sum←v.element()
for each child c of v
Sum←Sum+treeSum1(T,c)
return Sum
So all we have to do is to write treeSum3, treSum4, ... , where treSum3 invokes treeSum2, treeSum4 invokes treeSum3, ... .
That would be, literally, an infinite amount of work.
Do a diff of treeSum1 and treeSum2.
What do you find are the differences.
In the Algorithm line and in the first comment a 1 becomes a 2.
In the subroutine call a 0 becomes a 1.
Why can't we write treeSumI and let I vary?
Because it is illegal to have a varying name for an algorithm.
The solution is to make the I a parameter and write
Algorithm treeSum(i,T,v)
Inputs: i≥0; T a tree; v a height i node of T
Output: the sum of the elements of the subtree routed at v
Sum←v.element()
for each child c of v
Sum←Sum+treeSum(i-1,T,c)
return Sum
This is wrong, why?
Because treeSum(0,T,v) invokes treeSum(-1,c,v), which doesn't
exist because i<0
But treeSum(0,T,v) doesn't have to call anything since v can't have any children (the height of v is 0). So we get
Algorithm treeSum(i,T,v)
Inputs: i≥0; T a tree; v a height i node of T
Output: the sum of the elements of the subtree routed at v
Sum←v.element()
if i>0 then
for each child c of v
Sum←Sum+treeSum(i-1,T,c)
return Sum
The last two algorithms are recursive; they call themselves. Note that when treeSum(3,T,v) calls treeSum(2,T,c), the new treeSum has new variables Sum and c.
We are pretty happy with our treeSum routine, but ...
The algorithm is wrong! Why?
The children of a height i node need not all be of height i-1.
For example s is hight 2, but its left child w is height 0.
(A corresponding error also existed in treeSum2(T,v)
But the only real use we are making of i is to prevent us from recursing when we are at a leaf (the i>0 test). But we can use isInternal instead, giving our final algorithm
Algorithm treeSum(T,v)
Inputs: T a tree; v a node of T
Output: the sum of the elements of the subtree routed at v
Sum←v.element()
if T.isInternal(v) then
for each child c of v
Sum←Sum+treeSum(T,c)
return Sum