Operating Systems
================ Start Lecture #5 ================
1.6A: Addendum on Transfer of Control
The transfer of control between user processes and the operating
system kernel can be quite complicated, especially in the case of
blocking system calls, hardware interrupts, and page faults.
Before tackling these issues later, we begin
with a more familiar situation, a procedure call within a user-mode
process, i.e., a review of material from 101 and 201.
An important OS objective is that, even in the more complicated
cases of page faults and blocking system calls requiring device
interrupts, simple procedure call semantics are observed
from a user process viewpoint.
The complexity is hidden inside the kernel itself, yet another example
of the operating system providing a more abstract, i.e., simpler,
virtual machine to the user processes.
More details will be added when we study memory management (and know
officially about page faults)
and more again when we study I/O (and know officially about device
interrupts).
A number of the points below are far from standardized.
Such items as where are parameters placed, which routine saves the
registers, exact semantics of trap, etc, vary as one changes
language/compiler/OS.
Indeed some of these are referred to as ``calling conventions'',
i.e. their implementation is a matter of convention rather than
logical requirement.
The presentation below is, we hope, reasonable, but must be viewed as
a generic description of what could happen instead of an exact
description of what does happen with, say, C compiled by the Microsoft
compiler running on Windows NT.
1.6A.1: User-mode procedure calls
Procedure f calls g(a,b,c) in process P.
Actions by f prior to the call:
- Complete all previous instructions in f.
- Save the registers by pushing them onto the stack (in some
implementations this is done by g instead of f).
- Push arguments c,b,a onto P's stack.
Note: Stacks usually
grow downward from the top of P's segment, so pushing
an item onto the stack actually involves decrementing the stack
pointer, SP.
Executing the call itself
- Execute PUSHJ <start-address of g>.
This instruction
pushes the program counter PC onto the stack, and then jumps to
the start address of g.
The value pushed is actually the updated program counter, i.e.,
the location of the next instruction (the instruction to be
executed by f when g returns).
Actions by g upon being called:
- Allocate space for g's local variables by suitably decrementing SP.
- Start execution from the beginning of the program, referencing the
parameters as needed.
The execution may involve calling other procedures, possibly
including recursive calls to f and/or g.
Actions by g when returning to f:
- If g is to return a value, store it in the conventional place.
- Undo step 5: Deallocate local variables by incrementing SP.
- Undo step 4: Execute POPJ, i.e., pop the stack and set PC to the
value popped, which is the return address pushed in step 4.
Actions by f upon the return from g:
- We are now at the step in f immediately following the call to g.
Undo step 3: Remove the arguments from the stack by incrementing
SP.
- (Sort of) undo step 2: Restore the registers by popping the
stack.
- Continue the execution of f, referencing the returned value of g,
if any.
Properties of (user-mode) procedure calls:
- Predictable (often called synchronous) behavior: The author of f
knows where and hence when the call to g will occur. There are no
surprises, so it is relatively easy for the programmer to ensure
that f is prepared for the transfer of control.
- LIFO structure of control transfer: we can be sure that control
will return to f when this call to g exits.
The above statement holds even if, via recursion, g calls f.
(We are ignoring language features such as ``throwing'' and ``catching''
exceptions, and the use of unstructured assembly coding, in the
latter case all bets are off.)
- Entirely in user mode and user space.
1.6A.2: Kernel-mode procedure calls
We mean on procedure running in kernel mode calling another
procedure, which will also be run in kernel mode. Later, we will
discuss switching from user to kernel mode and back.
There is not much difference between the actions taken during a
kernel-mode procedure call and during a user-mode procedure call. The
procedures executing in kernel-mode are permitted to issue privileged
instructions, but the instructions used for transferring control are
all unprivileged so there is no change in that respect.
One difference is that a different stack is used in kernel
mode, but that simply means that the stack pointer must be set to the
kernel stack when switching from user to kernel mode. But we are
not switching modes in this section; the stack pointer already points
to the kernel stack.
1.6A.3: The Trap instruction
The trap instruction, like a procedure call, is a synchronous
transfer of control:
We can see where, and hence when, it is executed; there are no
surprises.
Although not surprising, the trap instruction does have an
unusual effect, processor execution is switched from user-mode to
kernel-mode. That is, the trap instruction itself is executed in
user-mode (it is naturally an UNprivileged instruction) but
the next instruction executed (which is NOT the instruction
written after the trap) is executed in kernel-mode.
Process P, running in unprivileged (user) mode, executes a trap
The code being executed was written in assembler since there are no
high level languages that generate a trap instruction.
There is no need to name the function that is executing.
Compare the following example to the explanation of ``f calls g''
given above.
Actions by P prior to the trap
- Complete all previous instructions in P.
- Save the registers by pushing them onto the stack.
- Store any arguments that are to be passed.
The stack is not normally used to store these arguments since the
kernel has a different stack.
Often registers are used.
Executing the trap itself
- Execute TRAP <trap-number>.
Switch the processor to kernel (privileged) mode, jumps to a
location in the OS determined by trap-number, and saves the return
address.
For example, the processor may be designed so that the next
instruction executed after a trap is at physical address 8 times the
trap-number.
The trap-number should be thought of as the ``name'' of the
code-sequence to which the processor will jump rather than as an
argument to trap.
Indeed arguments to trap, are established before the trap is executed.
Actions by the OS upon being TRAPped into
- Jump to the real code.
Recall that trap instructions with different trap numbers jump to
locations very close to each other.
There is not enough room between them for the real trap handler.
Indeed one can think of the trap as having an extra level of
indirection; it jumps to a location that then jumps to the real
start address. If you learned about writing jump tables in
assembler, this is very similar.
-
Check all arguments passed. The kernel must be paranoid and
assume that the user mode program is evil and written by a
bad guy.
-
Allocate space by decrementing the kernel stack pointer.
The kernel and user stacks are separate.
- Start execution from the jumped-to location, referencing the
parameters as needed.
Actions by the OS when returning to user mode
- Undo step 7: Deallocate space by incrementing the kernel stack
pointer.
- Undo step 4: Execute (in assembler) another special instruction,
RTI or ReTurn from Interrupt, which returns the processor to user
mode and transfers
Actions by P upon the return from the OS
- We are now in at the instruction right after the trap
Undo step 2: Restore the registers by popping the stack.
- Continue the execution of P, referencing the returned value(s) of
the trap, if any.
Properties of TRAP/RTI:
- Synchronous) behavior: The author of the assembly code in P
knows where and hence when the trap will occur. There are no
surprises, so it is relatively easy for the programmer to prepare
for the transfer of control.
- Trivial control transfer when viewed from P:
The next instruction of P that will be executed is the
one following the trap.
As we shall see later, other processes may execute between P's
trap and the next P instructions.
- Starts and ends in user mode and user space, but executed in
kernel mode and kernel space in the middle.
1.7: OS Structure
I must note that Tanenbaum is a big advocate of the so called
microkernel approach in which as much as possible is moved out of the
(supervisor mode) kernel into separate processes. The (hopefully
small) portion left in supervisor mode is called a microkernel.
In the early 90s this was popular. Digital Unix (now called True64)
and Windows NT are examples. Digital Unix is based on Mach, a
research OS from Carnegie Mellon university. Lately, the growing
popularity of Linux has called into question the belief that ``all new
operating systems will be microkernel based''.
1.7.1: Monolithic approach
The previous picture: one big program
The system switches from user mode to kernel mode during the poof and
then back when the OS does a ``return''.
But of course we can structure the system better, which brings us to.
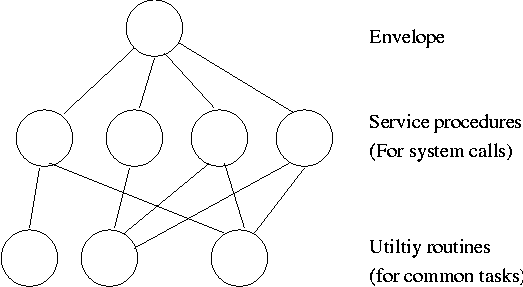
1.7.2: Layered Systems
Some systems have more layers and are more strictly structured.
An early layered system was ``THE'' operating system by Dijkstra. The
layers were.
- The operator
- User programs
- I/O mgt
- Operator-process communication
- Memory and drum management
The layering was done by convention, i.e. there was no enforcement by
hardware and the entire OS is linked together as one program. This is
true of many modern OS systems as well (e.g., linux).
The multics system was layered in a more formal manner. The hardware
provided several protection layers and the OS used them. That is,
arbitrary code could not jump to or access data in a more protected layer.
1.7.3: Virtual Machines
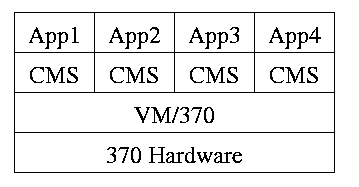
Use a ``hypervisor'' (beyond supervisor, i.e. beyond a normal OS) to
switch between multiple Operating Systems. Made popular by
IBM's VM/CMS
-
Each App/CMS runs on a virtual 370.
-
CMS is a single user OS.
-
A system call in an App traps to the corresponding CMS.
-
CMS believes it is running on the machine so issues I/O.
instructions but ...
-
... I/O instructions in CMS trap to VM/370.
-
This idea is still used.
A modern version (used to ``produce'' a multiprocessor from many
uniprocessors) is ``Cellular Disco'', ACM TOCS, Aug. 2000.
- Another modern usage is JVM the ``Java Virtual Machine''.
1.7.4: Exokernels
Similar to VM/CMS but the virtual machines have disjoint resources
(e.g., distinct disk blocks) so less remapping is needed.
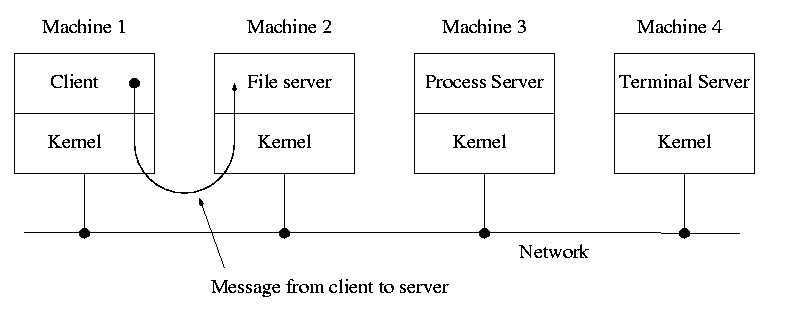
1.7.5: Client Server

When implemented on one computer, a client server OS is using the
microkernel approach in which the microkernel just supplies
interprocess communication and the main OS functions are provided by a
number of separate processes.
This does have advantages. For example an error in the file server
cannot corrupt memory in the process server. This makes errors easier
to track down.
But it does mean that when a (real) user process makes a system call
there are more processes switches. These are
not free.
A distributed system can be thought of as an extension of the
client server concept where the servers are remote.
Homework: 23
Microkernels Not So Different In Practice
Dennis Ritchie, the inventor of the C programming language and
co-inventor, with Ken Thompson, of Unix was interviewed in February
2003. The following is from that interview.
What's your opinion on microkernels vs. monolithic?
Dennis Ritchie: They're not all that different when you actually
use them. "Micro" kernels tend to be pretty large these days, and
"monolithic" with loadable device drivers are taking up more of the
advantages claimed for microkernels.