Operating System
================ Start Lecture #12 ================
4.6.3: Page size
- Page size ``must'' be a multiple of the disk block size. Why?
Answer: When copying out a page if you have a partial disk block, you
must do a read/modify/write (i.e., 2 I/Os).
- Important property of I/O that we will learn later this term is
that eight I/Os each 1KB takes considerably longer than one 8KB I/O
- Characteristics of a large page size.
- Good for user I/O.
- If I/O done using physical addresses, then I/O crossing a
page boundary is not contiguous and hence requires multiple
I/Os
- If I/O uses virtual addresses, then page size doesn't effect
this aspect of I/O. That is the addresses are contiguous
in virtual address and hence one I/O is done.
- Good for demand paging I/O.
- Better to swap in/out one big page than several small
pages.
- But if page is too big you will be swapping in data that is
really not local and hence might well not be used.
- Large internal fragmentation (1/2 page size).
- Small page table.
- A very large page size leads to very few pages. Process will
have many faults if using demand
paging and the process frequently references more regions than
frames.
- A small page size has the opposite characteristics.
4.6.4: Separate Instruction and Data (I and D) Spaces
Skipped.
4.6.5: Shared pages
Permit several processes to each have a page loaded in the same
frame.
Of course this can only be done if the processes are using the same
program and/or data.
- Really should share segments.
- Must keep reference counts or something so that when a process
terminates, pages (even dirty pages) it shares with another process
are not automatically discarded.
- Similarly, a reference count would make a widely shared page (correctly)
look like a poor choice for a victim.
- A good place to store the reference count would be in a structure
pointed to by both PTEs. If stored in the PTEs, must keep them
consistent between processes.
4.6.6: Cleaning Policy (Paging Daemons)
Done earlier
4.6.7: Virtual Memory Interface
Skipped.
4.7: Implementation Issues
4.7.1: Operating System Involvement with Paging
4.7.2: Page Fault Handling
What happens when a process, say process A, gets a page fault?
- The hardware detects the fault and traps to the kernel (switches
to supervisor mode and saves state).
- Some assembly language code save more state, establishes the
C-language (or another programming language) environment, and
``calls'' the OS.
- The OS determines that a page fault occurred and which page was
referenced.
- If the virtual address is invalid, process A is killed.
If the virtual address is valid, the OS must find a free frame.
If there is no free frames, the OS selects a victim frame.
Call the process owning the victim frame, process B.
(If the page replacement algorithm is local, the victim is process A.)
- The PTE of the victim page is updated to show that the page is no
longer resident.
- If the victim page is dirty, the OS schedules an I/O write to
copy the frame to disk and blocks A waiting for this I/O to occur.
- Since process A is blocked, the scheduler is invoked to perform a
context switch.
- Tanenbaum ``forgot'' some here.
- The process selected by the scheduler (say process C) runs.
- Perhaps C is preempted for D or perhaps C blocks and D runs
and then perhaps D is blocked and E runs, etc.
- When the I/O to write the victim frame completes, a Disk
interrupt occurs. Assume processes C is running at the time.
- Hardware trap / assembly code / OS determines I/O done.
- The scheduler picks a process to run, maybe A, maybe B, maybe
C, maybe another processes.
- At some point the scheduler does pick process A to run.
Recall that at this point A is still executing OS code.
- Now the O/S has a clean frame (this may be much later in wall clock
time if a victim frame had to be written).
The O/S schedules an I/O to read the desired page into this clean
frame.
Process A is blocked (perhaps for the second time) and hence the
process scheduler is invoked to perform a context switch.
- A Disk interrupt occurs when the I/O completes (trap / asm / OS
determines I/O done). The PTE in process A is updated to indicate
that the page is in memory.
- The O/S may need to fix up process A (e.g. reset the program
counter to re-execute the instruction that caused the page fault).
- Process A is placed on the ready list and eventually is chosen by
the scheduler to run.
Recall that process A is executing O/S code.
- The OS returns to the first assembly language routine.
- The assembly language routine restores registers, etc. and
``returns'' to user mode.
The user's program running as process A is unaware
that all this happened (except for the time delay).
4.7.3: Instruction Backup
A cute horror story. The 68000 was so bad in this regard that
early demand paging systems for the 68000, used two processors one
running one instruction behind. If the first got a page fault, there
wasn't always enough information to figure out what to do so the
system switched to the second processor after it did the page fault.
Don't worry about instruction backup. Very machine dependent and
modern implementations tend to get it right. The next generation
machine, 68010, provided extra information on the stack so the
horrible 2-processor kludge was no longer necessary.
4.7.4: Locking (Pinning) Pages in Memory
We discussed pinning jobs already. The
same (mostly I/O) considerations apply to pages.
4.7.5: Backing Store
The issue is where on disk do we put pages.
- For program text, which is presumably read only, a good choice is
the file itself.
- What if we decide to keep the data and stack each contiguous on
the backing store.
Data and stack grow so we must be prepared to grow the space on
disk, which leads to the same issues and problems as we saw with
MVT.
- If those issues/problems are painful, we can scatter the pages on
the disk.
- That is we employ paging!
- This is NOT demand paging.
- Need a table to say where the backing space for each page is
located.
- This corresponds to the page table used to tell where in
real memory a page is located.
- The format of the ``memory page table'' is determined by
the hardware since the hardware modifies/accesses it.
- The format of the ``disk page table'' is decided by the OS
designers and is machine independent.
- If the format of the memory page table was flexible, then
we might well keep the disk information in it as well.
- What if we felt disk space was too expensive and wanted to put some of
these disk pages on say tape?
Ans: We have demand paging of the disk blocks!
4.7.6: Separation of Policy and Mechanism
Skipped.
4.8: Segmentation
Up to now, the virtual address space has been contiguous.
- Among other issues this makes memory management difficult when
there are more that two dynamically growing regions.
- With two regions you start them on opposite sides of the virtual
space as we did before.
- Better is to have many virtual address spaces each starting at
zero.
- This split up is user visible.
- Without segmentation (equivalently said with just one segment) all
procedures are packed together so if one changes in size all the virtual
addresses following are changed and the program must be re-linked.
- Eases flexible protection and sharing (share a segment). For
example, can have a shared library.
Homework: 37.
** Two Segments
Late PDP-10s and TOPS-10
- One shared text segment, that can also contain shared
(normally read only) data.
- One (private) writable data segment.
- Permission bits on each segment.
- Which kind of segment is better to evict?
- Swap out shared segment hurts many tasks.
- The shared segment is read only (probably) so no writeback
is needed.
- ``One segment'' is OS/MVT done above.
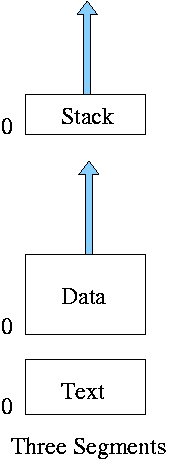
** Three Segments
Traditional (early) Unix shown at right.
- Shared text marked execute only.
- Data segment (global and static variables).
- Stack segment (automatic variables).
- In reality, since the text doesn't grow, this was sometimes
treated as 2 segments by combining text and data into one segment
** Four Segments
Just kidding.
** General (not necessarily demand) Segmentation
- Permits fine grained sharing and protection. For a simple example
can share the text segment in early unix.
- Visible division of program.
- Variable size segments.
- Virtual Address = (seg#, offset).
- Does not mandate how stored in memory.
- One possibility is that the entire program must be in memory
in order to run it.
Use whole process swapping.
Very early versions of Unix did this.
- Can also implement demand segmentation.
- Can combine with demand paging (done below).
- Requires a segment table with a base and limit value for each
segment. Similar to a page table. Why is there no limit value in a
page table?
Ans: All pages are the same size so the limit is obvious.
- Entries are called STEs, Segment Table Entries.
- (seg#, offset) --> if (offset<limit) base+offset else error.
- Segmentation exhibits external fragmentation, just as whole program
swapping.
Since segments are smaller than programs (several segments make up one
program), the external fragmentation is not as bad.
** Demand Segmentation
Same idea as demand paging applied to segments.
- If a segment is loaded, base and limit are stored in the STE and
the valid bit is set in the PTE.
- The PTE is accessed for each memory reference (not really, TLB).
- If the segment is not loaded, the valid bit is unset.
The base and limit as well as the disk
address of the segment is stored in the an OS table.
- A reference to a non-loaded segment generate a segment fault
(analogous to page fault).
- To load a segment, we must solve both the placement question and the
replacement question (for demand paging, there is no placement question).
- I believe demand segmentation was once implemented by Burroughs,
but am not sure.
It is not used in modern systems.
The following table mostly from Tanenbaum compares demand
paging with demand segmentation.
| Consideration |
Demand
Paging | Demand
Segmentation |
|---|
| Programmer aware |
No | Yes |
| How many addr spaces |
1 | Many |
| VA size > PA size |
Yes | Yes |
Protect individual
procedures separately |
No | Yes |
Accommodate elements
with changing sizes |
No | Yes |
| Ease user sharing |
No | Yes |
| Why invented |
let the VA size
exceed the PA size |
Sharing, Protection,
independent addr spaces |
|
| Internal fragmentation |
Yes | No, in principle |
| External fragmentation |
No | Yes |
| Placement question |
No | Yes |
| Replacement question |
Yes | Yes |
** 4.8.2 and 4.8.3: Segmentation With Paging
(Tanenbaum gives two sections to explain the differences between
Multics and the Intel Pentium. These notes cover what is common to
all segmentation).
Combines both segmentation and paging to get advantages of both at
a cost in complexity. This is very common now.
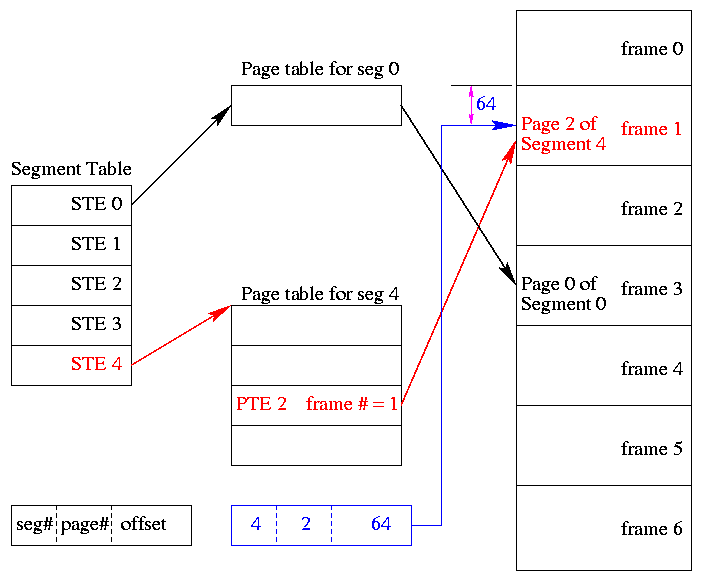
- A virtual address becomes a triple: (seg#, page#, offset).
- Each segment table entry (STE) points to the page table for that
segment.
Compare this with a
multilevel page table.
- The size of each segment is a multiple of the page size (since the
segment consists of pages). Perhaps not. Can keep the exact size in
the STE (limit value) and shoot the process if it referenced beyond
the limit. In this case the last page of each segment is partially valid.
- The page# field in the address gives the entry in the chosen page
table and the offset gives the offset in the page.
- From the limit field, one can easily compute the size of the
segment in pages (which equals the size of the corresponding page
table in PTEs). Implementations may require the size of a segment to
be a multiple of the page size in which case the STE would store the
number of pages in the segment.
- A straightforward implementation of segmentation with paging
would requires 3 memory references (STE, PTE, referenced word) so a
TLB is crucial.
- Some books carelessly say that segments are of fixed size.
This is wrong.
They are of variable size with a fixed maximum and possibly with the
requirement that the size of a segment is a multiple of the page size.
- The first example of segmentation with paging was Multics.
- Keep protection and sharing information on segments.
This works well for a number of reasons.
- A segment is variable size.
- Segments and their boundaries are user (i.e., linker) visible.
- Segments are shared by sharing their page tables. This
eliminates the problem mentioned above with
shared pages.
- Do replacement on pages so there is no placement question and
no external fragmentation.
- Do fetch-on-demand with pages (i.e., do demand paging).
- In general, segmentation with demand paging works well and is
widely used. The only problems are the complexity and the resulting 3
memory references for each user memory reference. The complexity is
real, but can be managed. The three memory references would be fatal
were it not for TLBs, which considerably ameliorate the problem. TLBs
have high hit rates and for a TLB hit there is essentially no penalty.
Homework: 38.
4.9: Research on Memory Management
Skipped
4.10: Summary
Read
Some Last Words on Memory Management
- Segmentation / Paging / Demand Loading (fetch-on-demand)
- Each is a yes or no alternative.
- Gives 8 possibilities.
- Placement and Replacement.
- Internal and External Fragmentation.
- Page Size and locality of reference.
- Multiprogramming level and medium term scheduling.