================ Start Lecture #12 ================
Remarks (sent to mailing list on thurs):
This looks trivial. Since we know n, we can find n+1 and hence the reference to node z in O(1) time. But there is a problem; the result might not be a heap since the new key inserted at z might be less than the key stored at u the parent of z. Reminiscent of bubble sort, we need to bubble the value in z up to the correct location.
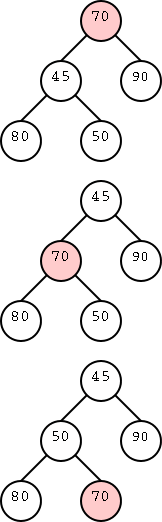
We compare key(z) with key(u) and swap the items if necessary. In the diagram on the right we added 45 and then had to swap it with 70. But now 45 is still less than its parent so we need to swap again. At worst we need to go all the way up to the root. But that is only Θ(n) as desired. Let's slow down and see that this really works.
Great. It works (i.e., is a heap) and there can only be O(log(n)) swaps because that is the height of the tree.
But wait! What I showed is that it only takes O(n) steps. Is each step O(1)?
Comparing is clearly O(1) and swapping two fixed elements is also O(1). Finding the parent of a node is easy (integer divide the vector index by 2). Finally, it is trivial to find the new index for the insertion point (just increase the insertion point by 1).
Remark: It is not as trivial to find the new insertion point using a linked implementation.
Homework: Show the steps for inserting an element
with key 2 in the heap of Figure 2.41.
Trivial, right? Just remove the root since that must contain an
element with minimum key. Also decrease n by one.
Wrong!
What remains is TWO trees.
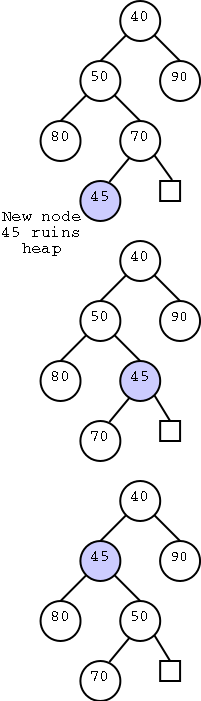
We do want the element stored at the root but we must put some other element in the root. The one we choose is our friend the last node.
But the last node is likely not to be a valid root, i.e. it will destroy the heap property since it will likely be bigger than one of its new children. So we have to bubble this one down. It is shown in pale red on the right and the procedure explained below. We also need to find a new last node, but that really is trivial: It is the node stored at the new value of n.
If the new root is the only internal node then we are done.
If only one child of the root is internal (it must be the left child) compare its key with the key of the root and swap if needed.
If both children of the root are internal, choose the child with the smaller key and swap with the root if needed.
The original last node, became the root, and now has been bubbled down to level 1. But it might still be bigger than a child so we keep bubbling. At worst we need Θ(h) bubbling steps, which is again logarithmic in n as desired.
Homework: R-2.16
| Operation | Time |
|---|---|
| size, isEmpty | O(1) |
| minElement, minKey | O(1) |
| insertItem | Θ(log n) |
| removeMin | Θ(log n) |
The table on the right gives the performance of the heap implementation of a priority queue. As desired, the main operations have logarithmic time complexity. It is for this reason that heap sort is fast.
The goal is to sort a sequence S. We return to the PQ-sort where we insert the elements of S into a priority queue and then use removeMin to obtain the sorted version. When we use a heap to implement the priority queue, each insertion and removal takes O(log(n)) so the entire algorithm takes O(nlog(n)). The heap implementation of PQ-sort is called heap-sort and we have shown
Theorem: The heap-sort algorithm sorts a sequence of n comparable elements in O(nlog(n)) time.
 In place means that we use the space occupied by the input.
More precisely, it means that the space required is just the input +
O(1) additional memory. The algorithm above required Θ(n)
addition space to store the heap.
In place means that we use the space occupied by the input.
More precisely, it means that the space required is just the input +
O(1) additional memory. The algorithm above required Θ(n)
addition space to store the heap.
The in place heap-sort of S assumes that S is implemented as an array and proceeds as follows (This presentation, beyond the definition of ``in place'' is unofficial; i.e., it will not appear on problem sets or exams)
If you are given at the beginning all n elements that are to be inserted, the total insertion time for all inserts can be reduced to O(n) from O(nlog(n)). The basic idea assuming n=2n-1 is
Sometimes we wish to extend the priority queue ADT to include a locater that always points to the same element even when the element moves around. So if x is in a priority queue and another item is inserted, x may move during the up-heap bubbling, but the locater of x continues to refer to x.
Method | Unsorted Sequence | Sorted Sequence | Heap |
|---|---|---|---|
| size, isEmpty | O(1) | O(1) | O(1) |
| minElement, minKey | O(n) | O(1) | O(1) |
| insertItem | O(1) | O(n) | O(log(n)) |
| removeMin | O(n) | O(1) | O(log(n)) |
Dictionaries, as the name implies are used to contain data that may later be retrieved. Associated with each element is the key used for retrieval.
For example consider an element to be one student's NYU transcript and the key would be the student id number. So given the key (id number) the dictionary would return the entire element (the transcript).
A dictionary stores items, which are key-element (k,e) pairs.
We will study ordered dictionaries in the next chapter when we consider searching. Here we consider unordered dictionaries. So, for example, we do not support findSmallestKey. the methods we do support are
Just store the items in a sequence.