======== START LECTURE #24
========
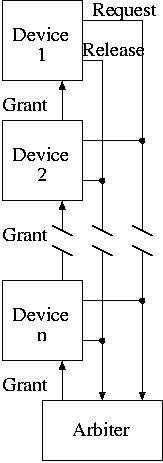
Obtaining bus access
- The simplest scheme is to permit only one bus
master.
- That is, on each bus only one device is permited to
initiate a bus transaction.
- The other devices are slaves that only
respond to requests.
- With a single master, there is no issue of arbitrating
among multiple requests.
- One can have multiple masters with daisy
chaining of the grant line.
- Any device can assert the request line, indicating that it
wishes to use the bus.
- This is not trivial: uses ``open collector drivers''.
- If no output drives the line, it will be ``pulled up'' to
5v, i.e., a logical true.
- If one or more outputs drive the line to 0v it will go to
0v (a logical false).
- So if a device wishes to make a request it drives the line
to 0v; if it does not wish to make a request it does nothing.
- This is (another example of) active low logic. The
request line is asserted by driving it low.
- When the arbiter sees the request line asserted (and the
previous grantee has issued a release), the arbiter raises the
grant line.
- The grant signal is passed from one device to another if the
first device is not requesting the bus. Hence
devices near the arbiter have priority and can starve the ones
further away.
- The device whose request is granted asserts the release line
when done.
- Simple, but not fair and not of high performance.
- Centralized parallel arbiter: Separate request lines from each
device and separate grant lines. The arbiter decides which device
should be granted the bus.
- Distributed arbitration by self-selection: Requesting
processes identify themselves on the bus and decide individually
(and consistently) which one gets the grant.
- Distributed arbitration by collision detection: Each device
transmits whenever it wants, but detects collisions and retries.
Ethernet uses this scheme (but modern switched ethernets do not).
| Option | High performance | Low cost |
|---|
| bus width | separate addr and data lines |
multiplex addr and data lines |
| data width | wide | narrow |
| transfer size | multiple bus loads | single bus loads |
| bus masters | multiple | single |
| clocking | synchronous | asynchronous |
Do on the board the example on pages 665-666
- Memory and bus support two widths of data transfer: 4 words and 16
words
- 64-bit synchronous bus; 200MHz; 1 clock for addr; 1 for data.
- Two clocks of ``rest'' between bus accesses
- Memory access times: 4 words in 200ns; additional 4 word blocks in
20ns per block.
- Can overlap transferring data with reading next data.
- Find
- Sustained bandwidth and latency for reading 256 words using
both size transfers
- How many bus transactions per sec for each (1 trans is addr+data).
- Four word blocks
- 1 clock to send addr
- 40 clocks read mem
- 2 clocks to send data
- 2 idle clocks
- 45 total clocks
- 256/4=64 transactions needed so latency is 64*45*5ns=14.4us
- 64 trans per 14.4us = 64/14.4 trans per 1us = 4.44M trans per
sec
- Bandwidth = 1024 bytes per 14.4us = 1024/14.4 B/us = 71.11MB/sec
- Sixteen word blocks
- 1 clock for addr
- 40 clocks for reading first 4 words
- 2 clocks to send
- 2 clocks idle
- 4 clocks to read next 4 words. But this is free! Why?
Because it is done during the send and idle of previous block.
- So we only pay for the long initial read
- Total = 1 + 40 + 4*(2+2) = 57 clocks.
- 16 transactions need; latency = 57*16*5ns=4.56ms, which is
much better than with 4 word blocks.
- 16 transactions per 4.56us = 3.51M transactions/sec
- Bandwidth = 1024B per 4.56ms = 224.56MB/sec
8.5: Interfacing I/O Devices
Giving commands to I/O Devices
This is really an OS issue. Must write/read to/from device
registers, i.e. must communicate commands to the controller. Note
that a controller normally contains a microprocessor, but when we say
the processor, we mean the central processor not the one on the
controller.
- The controler has a few registers that can be read and/or written
by the processor, similar to how the processor reads and writes
memory. These registers are also read and written by the controller.
- Nearly every controler contains
- A data register, which is readable (by the processor) for an
input device (e.g., a simple keyboard), writable for an output
device (e.g., a simple printer), and both readable and writable
for input/output devices (e.g., disks).
- A control register for giving commands to the device.
- A readable status register for reporting errors and announcing
when the device is ready for the next action (e.g., for a keyboard
telling when the data register is valid, and for a printer telling
when the character to be printed has be successfully retrieved
from the data register). Remember the communication protocol we
studied where ack was used.
- Many controllers have more registers
Communicating with the Processor
Should we check periodically or be told when there is something to
do? Better yet can we get someone else to do it since we are not
needed for the job?
- We get mail at home once a day.
- At some business offices mail arrives a few times per day.
- No problem checking once an hour for mail.
- If email wasn't buffered, you would have to check several times
per minute (second?, milisecond?).
- Checking email this often is too much of a burden and most of the
time when you check you find there is none so the check was wasted.
Polling
Processor continually checks the device status to see if action is
required.
- Like the mail example above.
- For a general purpose OS, one needs a timer to tell the processor
it is time to check (OS issue).
- For an embedded system (microwave) make the checking part of the
main control loop, which is guaranteed to be executed at a minimum
frequency (application software issue).
- For a keyboard or mouse, which have very low data rates, the
system can afford to have the main CPU check.
We do an example just below.
- It is a little better for slave-like output devices such as a
simple printer.
Then the processor only has to poll after a request
has been made until the request has been satisfied.
Do on the board the example on pages 676-677
- Cost of a poll is 400 clocks.
- CPU is 500MHz.
- How much of the CPU is needed to poll
- A mouse that requires 30 polls per sec?
- A floppy that sends 2 bytes at a time and achieves 50KB/sec?
- A hard disk that sends 16 bytes at a time and achieves 4MB/sec?
- For the mouse, we use 12,000 clock cycles each second sec for
polling. The CPU runs at 500*106 cycles/sec. So
polling the mouse requires 12/500*10-3 =
2.4*10-5 of the CPU. A very small penalty.
- The floppy delivers 25,000 (two byte) data packets per second so
we must poll at that rate not to miss one. CPU cycles needed each
second is (400)(25,000)=107. This represents
107 / 500*106 = 2% of the CPU
- To keep up with the disk requires 250K polls/sec or 108
clock cycles or 20% of the CPU.
- The system need not poll the floppy and disk until the
CPU had issues a request. But then it must keep polling until the
request is satisfied.
Interrupt driven I/O
Processor is told by the device when to look. The processor is
interrupted by the device.
- Dedicated lines (i.e. wires) on the bus are assigned for
interrupts.
- When a device wants to send an interrupt it asserts the
corresponding line.
- The processor checks for interrupts after each instruction. This
requires ``zero time'' as it is done in parallel with the
instruction execution.
- If an interrupt is pending (i.e., if a line is asserted) the
processor (this is mostly an OS issue, covered in 202).
- Saves the PC and perhaps some registers.
- Switches to kernel (i.e., privileged) mode.
- Jumps to a location specified in the hardware (the
interrupt handler).
At this point the OS takes over.
- What if we have several different devices and want to do different
things depending on what caused the interrupt?
- Use vectored interrupts.
- Instead of jumping to a single fixed location, the system
defines a set of locations.
- The system might have several interrupt lines. If line 1 is
asserted, jump to location 100, if line 2 is aserted jump to
location 200, etc.
- Alternatively, the system could have just one line
and have the device send the address to jump to.
- There are other issues with interrupts that are taught
in OS. For example, what happens if an interrupt occurs while an
interrupt is being processed. For another example, what if one
interrupt is more important than another. These are OS issues and are
not covered in this course.
- The time for processing an interrupt is typically longer than the
type for a poll. But interrupts are not generated when the
device is idle, a big advantage.
Do on the board the example on pages 681-682.
- Same hard disk and processor as above.
- Cost of servicing an interrrupt is 500 cycles.
- The disk is active only 5% of the time.
- What percent of the processor would be used to service the
interrupts?
- Cycles/sec needed for processing interrupts while the disk is
active is 125 million.
- This represents 25% of the processor cycles available.
- But the true cost is only 1.25%, since the disk is active only 5%
of the time.
- Note that the disk is not active (i.e., actively generating
interrupts) right after the request is made. Interrupts are not
generated during the seek and
rotational latency. They are generated only during the
transfer itself.
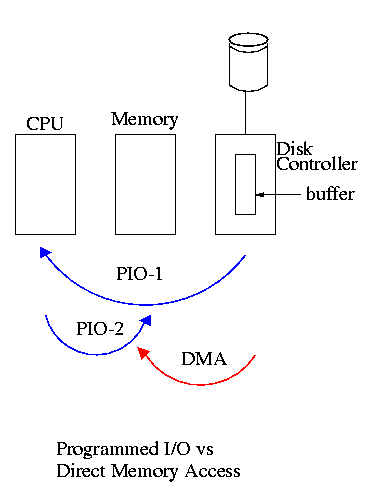
Direct Memory Access (DMA)
The processor initiates the I/O operation then ``something else''
takes care of it and notifies the processor when it is done (or if an
error occurs).
- Have a DMA engine (a small processor) on the controller.
- The processor initiates the DMA by writing the command into data
registers on the controller (e.g., read sector 5, head 4, cylinder
123 into memory location 34500)
- For commands that are longer than the size of the data register(s), a
protocol must be used to transmit the information.
- (I/O done by the processor as in the previous methods is called
programmed I/O, PIO).
- The controller collects data from the device and then sends it on
the bus to the memory without bothering the CPU.
- So we have a multimaster bus and need some sort of
arbitration.
- Normally the I/O devices are given higher priority than the CPU.
- Freeing the CPU from this task is good but isn't as wonderful
as it seems since the memory is busy (but cache hits can be
processed).
- A big gain is that only one bus transaction is needed per bus
load. With PIO, two transactions are needed: controller to
processor and then processor to memory.
- This was for an input operation (the controller writes to
memory). A similar situation occurs for output where the controller
reads from the memory). Once again one bus transaction per bus
load.
- When the controller detects that the I/O is complete or if an
error occurs, it sets the status register accordingly and sends an
interrupt to the processor to notify the latter that the I/O is complete.